背景
農業x深層学習のアプリケーションが作りたい!
という動機のもと、例えば作物の画像を入力してその健康状態を診断するようなアプリが作れるんじゃないかと考えてます。
病気を判定できるすごいモデルのせたアプリを作ったとして、ユーザが対象の作物の画像を正しく入力してくれるかどうかは、そのアプリの信頼性を担保する上で重要な問題になります。
例えば、上記の稲の病気を診断してくれるアプリを作ったとして、ユーザが雑草の画像を入力したとしてもそれっぽい結果を出力してしまえば、そのアプリの診断結果自体が疑わしいものになってしまいます。
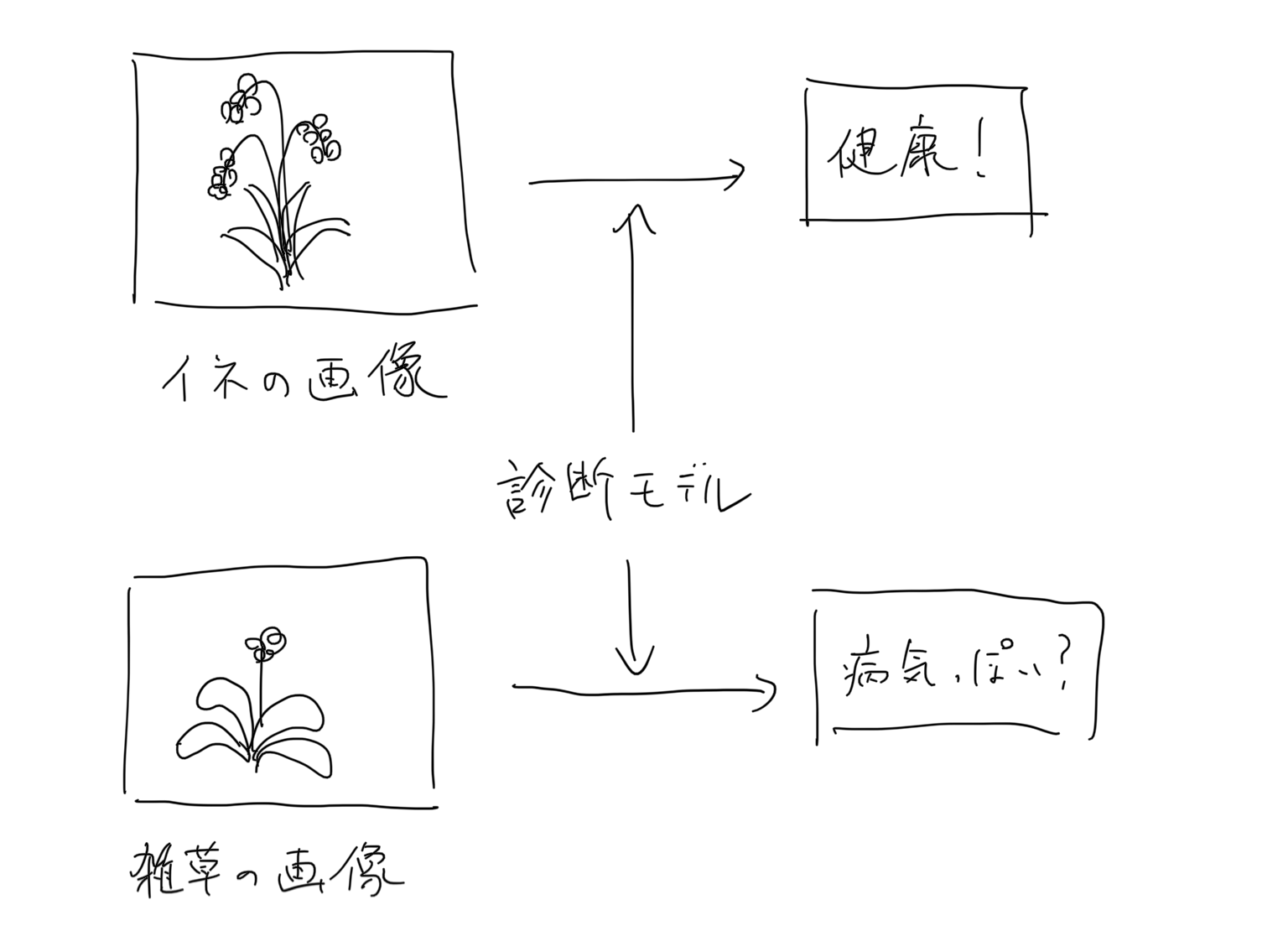
この問題に対処するため、メインとなるモデルの前段に入力画像の異常画像検知モデルを置いておけばよいのでは、と考えました。
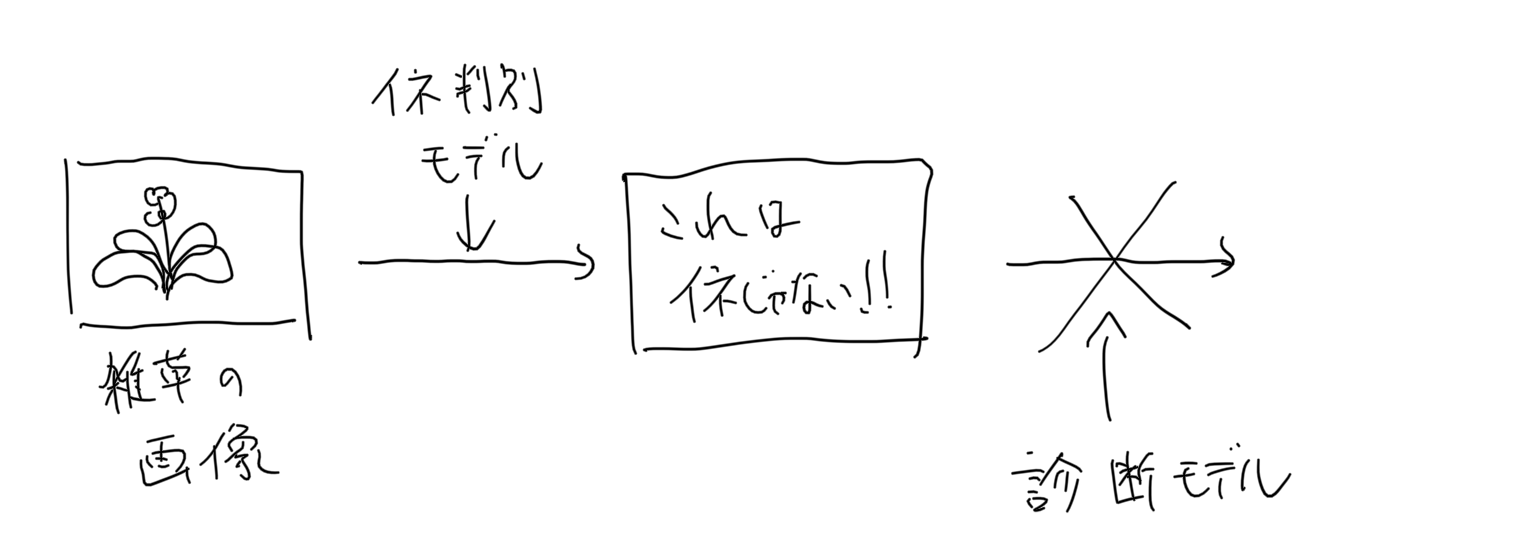
異常検知モデルにおいて正常と判定された画像のみをメインモデルに渡せば、信頼性の高い結果を出力することができそうです。
できたもの
3年前に購入した iPhoneXにアプリをインストールして、稲と雑草の画像を手元のラップトップに表示し、それを撮影してみました。
右上の円型のゲージに注目していただくと、稲と雑草をなんとなく識別している様子がわかると思います。

以下で、どんなことをやったのかをつらつらと書いていきます。
メトリックラーニング
メトリックラーニングは、ある画像のペアが同一かどうかを判別するモデルを作成するために用いられる手法です。今回の要件にあたっては、入力した画像が学習させた正常画像と同じかどうかを判別するためにこの手法を利用しました。
以下の記事を参考にさせていただきました。
https://qiita.com/shinmura0/items/06d81c72601c7578c6d3
モデル
モデルの作成にはPytorchを使いました。
スマホに載せることを目標としているので、軽量なMobileNetV2を特徴抽出器として利用します。
MobileNetV2はtorchvisionにデフォルトで用意されています。
今回は画像サイズを128x128としました。featuresレイヤーの出力をいい感じに整形して、最終出力を512次元のベクトルにします。
from torchvision.models import MobileNetV2
class MobileNetFeatures(nn.Module):
def __init__(self):
super(MobileNetFeatures, self).__init__()
self.head = MobileNetV2().features
self.pool = nn.AvgPool2d(4, 4)
self.flat = nn.Flatten()
self.fc = nn.Linear(1280, 512)
def forward(self, x):
x = self.head(x)
x = self.pool(x)
x = self.flat(x)
x = self.fc(x)
return x
学習
データセット
学習データとして、正常画像と同時にランダムな異常画像を与える必要があります。
そこで、オープンデータセットであるCOCOデータセットから、正常画像と同じ数だけランダムに抽出し、これを異常画像の集合としました。
Loss関数
割と新しいLoss関数である Arcface を使いました。
Arcfaceの説明としては下記の記事がめちゃくちゃわかりやすかったです。
https://qiita.com/yu4u/items/078054dfb5592cbb80cc
また、以下のレポジトリではこういったメトリックラーニングの最新の論文実装がライブラリとして提供されているため、こちらを利用させていただきました。
https://github.com/KevinMusgrave/pytorch-metric-learning
異常度の測定
学習させたモデルの出力は512次元のベクトル(embedding)です。
入力した画像が異常かどうかを判別するには、正常画像から得られるembeddingとのコサイン類似度をとる必要があります。
そのため、学習フェーズではモデルの保存と同時にバリデーションデータのembeddingの平均ベクトルを保存しておくようにします。
そして推論時にはこれを読み込んで、入力した画像とのコサイン類似度をとることで、異常かどうかの判別を行うことができます。
if save_interval > 0 and epoch_id % save_interval == 0:
model.eval()
# 正常画像と異常画像のコサイン類似度をそれぞれ測定する.
positive_dist = []
negative_dist = []
for batch in valid_loader:
images = batch[0].to(device)
labels = batch[1].numpy().tolist()
labels = [bool(i) for i in labels]
with torch.no_grad():
embeddings = model(images).cpu().numpy()
positive_embeddings = embeddings[labels]
negative_embeddings = embeddings[[not i for i in labels]]
mean_embedding = np.mean(positive_embeddings, axis=0)
for pe in positive_embeddings:
cos_sim = np.dot(mean_embedding, pe) / (np.linalg.norm(mean_embedding, ord=2) * np.linalg.norm(pe, ord=2))
positive_dist.append(cos_sim)
for ne in negative_embeddings:
cos_sim = np.dot(mean_embedding, ne) / (np.linalg.norm(mean_embedding, ord=2) * np.linalg.norm(ne, ord=2))
negative_dist.append(cos_sim)
mean_positive_dist = sum(positive_dist) / len(positive_dist)
mean_negative_dist = sum(negative_dist) / len(negative_dist)
print(f"epoch{epoch_id}: {mean_positive_dist} {mean_negative_dist}")
model.train()
# embeddingを保存する
features_save_path = f"../saved_features/embedding.txt"
np.savetxt(features_save_path, mean_embedding, delimiter=",")
スマホモデルへの変換
今回はiOSに載せることを想定し、coreMLを利用しました。
PytorchモデルからcoreMLへの変換のために、一度ONNX形式への変換を経由します。
(coremltoolsの最新版ではONNXを経由せずに変換できるようですが、今回は調査不足のため旧いやり方に従います。)
以下のスクリプトを参照ください。
- Pytorch -> ONNX
- ONNX -> CoreML
注意としては、2020/11/14現在 Python3.8.2の環境ではProtocolBuffer関連のエラーが発生し、ONNX -> CoreML への変換が動作しませんでした。
これは3.7.7を利用することで解決できます。
あとは生成された .mlmodel を Swiftへ組み込めばOKです。
終わりに
プロジェクト全体は以下のリポジトリに置いてあります。
https://github.com/r1wtn/light_weight_annomaly_detection
実際にスマホで動作させてみて、MobileNetV2の速さを改めて実感しました。たぶん30fps以上は出てるんじゃないかな。。。
最近では精度も高く高速なモデルが次々にリリースされているので、今後もいろんなモデルをスマホモデルに変換して試してみようと思います。