サマリ
Kaggleで公開されているEコマースサイトのデータセットを用いて、ABテストの分析プロセスを一通り行いました。
SQLiteによるデータの前処理から、Tableauでの可視化(EDA)、Pythonによる統計的仮説検定(カイ二乗検定)を経て、最終的な考察と改善提案まで、実務を想定した流れで進めていきます。
目次
0.使用ツール
・python - jupyternotebook
・DBeaver - SQLiteを使い前処理
・Tableau - EDA可視化やダッシュボード作成に利用
・Github - コードの公開
・GoogleSLide - 最終レポート
データセット
https://www.kaggle.com/datasets/putdejudomthai/ecommerce-ab-testing-2022-dataset1/data
1.Phase1 目的
ABテストを行うのはKAGGLEのデータセット
・分析の目的
KPIを基に、下記項目を考えました。
| 項目 | 内容 |
|---|---|
| 目的 | 新しいランディングページ(new_page)が、従来のページ(old_page)よりもコンバージョン率(CVR)を向上させるか検証する。 |
| 対象 | ECサイトの全訪問ユーザー |
| 期間 | 2022年のいずれかの連続した60時間 |
| 主要評価指標 (KPI) | コンバージョン率 (CVR) 算出方法: コンバージョンしたユーザー数 / グループ全体のユーザー数 |
| 仮説 | 帰無仮説 (H₀): 新旧ページのCVRに差はない。 対立仮説 (H₁): 新ページのCVRは旧ページよりも高い。 |
| Control (A群) | landing_page が old_page のユーザー |
| Treatment (B群) | landing_page が new_page のユーザー |
| 成功基準 | 統計的検定において、有意水準5% (p < 0.05)で有意差が認められ、かつ新ページのCVRが旧ページを上回る。 |
2.Phase2 前処理
DBeaber(SQLite)での前処理
・データ全体を確認
・必要なデータを取り出し、結合
・データそのものの値を処理
欠損値、重複、timestamp、データ型の処理
を行いました。
処理後のデータ構造は以下のようになりました。

| カラム名 | 説明 |
|---|---|
user_id |
ユニークユーザーID |
timestamp |
タイムスタンプ |
group |
Control群かTreatment群か |
landing_page |
新旧どちらのページか |
converted |
コンバージョンしたか (1=Yes, 0=No) |
country |
国 |
前処理に使用した全コードは、こちらのGitHubリポジトリで公開しています。
▶ GitHubリポジトリへのリンクはこちら
3.Phase3 EDA(探索的データ分析)
次に、前処理したデータをTableauに接続し、データを可視化しながら傾向を掴むEDA(探索的データ分析)を行いました。
分析を進めるにあたり、まず「ビジネス上の問い(Business Question)」を設定し、その問いにダッシュボードで答えられるような設計を意識しました。
【ビジネス上の問いの例】
・全体のCVRはどのくらいか?
・新旧ページでCVRに差はありそうか?
・国ごとのユーザー数やCVRに特徴はあるか?
作成したダッシュボードがこちらです。
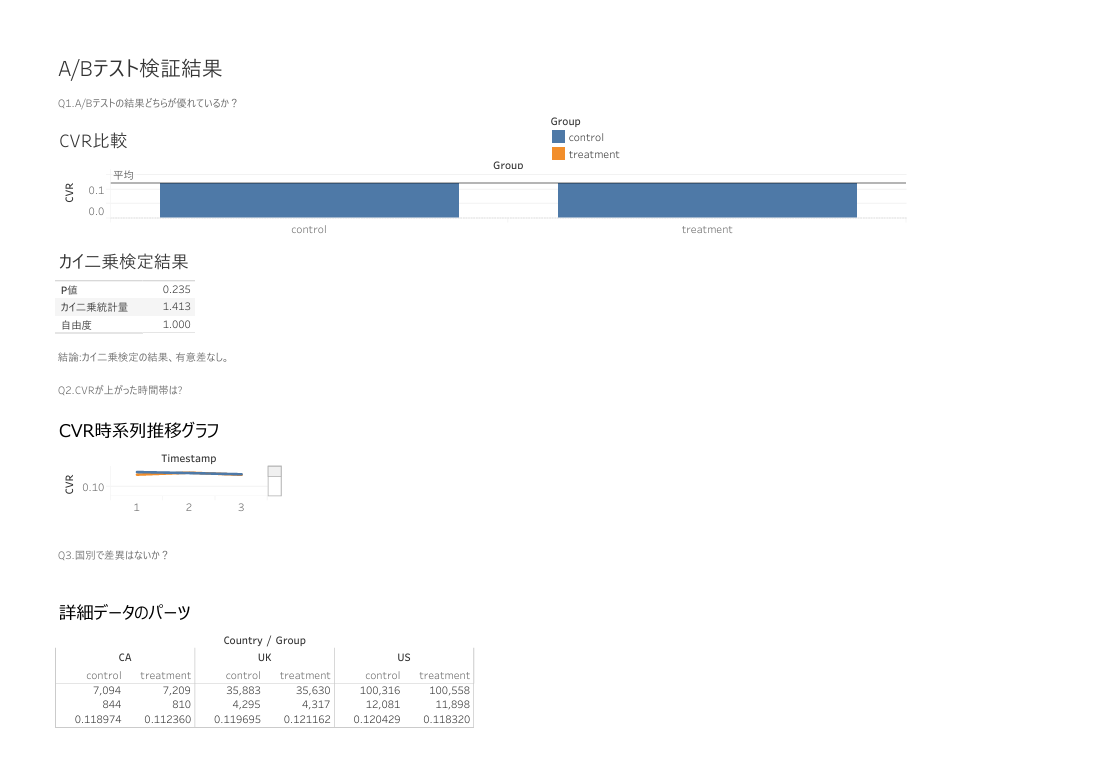
このダッシュボードから、新旧ページ間でCVRに大きな差は見られないことが視覚的に推測できました。
4.Phase4 カイ二乗検定
Pythonを用いて、カイ二乗検定を行いました。
新旧ページがCVRに影響するかクロス集計表を作成し計算する過程をPythonで行いました。
有意水準:0.05
H0(帰無仮説):新旧ページの違いがCVRに影響しない 片側検定
カイ二乗検定の結果: カイ二乗統計量: 1.4131 P値: 0.2345 自由度: 1
k=1(0.05) = 3.841>1.4131(統計量)
棄却域を示すカイ二乗分布を下回っているため、帰無仮説を採択します。
つまり、新旧ページの違いがCVRに影響しないということが統計的にも判明しました。
一般的に、p値が5%未満でない限り、「偶然とは考えにくい」とは言えません。
検定に使用したJupyter Notebookはこちらで公開しています。
▶ GitHubリポジトリへのリンクはこちら
5.Phase5 考察・提案など
今回のABテストでは、新デザインのページがCVRを向上させるという統計的に有意な差は認められませんでした。
この「差がなかった」という結果も重要な学びです。
以下に、レポートをまとめました。
失敗から学習し改善策を考えると、改善策自体の仮設設定、ABテストのバイアスを取り除く設計(曜日の影響を考慮して1週間実施)、ウェブサイト自体のヒートマップを割り出してどこで離脱しているのかを探るなどがあげられます。
また、統計的優位性があったとしても実務的な優位性・・・例えば、CVRが0.1%向上し差があったとして、実装コストに見合うか?といったように、そもそも成功する仮定自体の設計を考慮する必要があるのではないかと考えられます。
6.最後に
今回、シンプルなデータセットをもとにABテストがどのような流れになるか学習するという意図もあり、次回は上記要素も加味したデータセットを探し分析に挑戦しようと考えています。