はじめに
本記事は IJCAI-19 の Survey Track で発表された論文 "Automated Essay Scoring: A Survey of the State of the Art" の和訳です。
https://www.ijcai.org/proceedings/2019/879
本記事では、論文のサマリーと所感を述べたのち、論文の全訳を掲載します。
サマリー
- Automated Essay Scoring (AES) は、計算機を使ってエッセイをスコアリングするタスクの総称。
- AESはまず大きく holistic と dimension-specific に分かれる。
- holistic: エッセイ全体に単一のスコアをつける。
- dimension-specific: エッセイの質の特定の種類についてスコアをつける。例えば、簡単なものとしては「文法が間違っていないか」、難しいものとしては「説得力があるか」など。
- holistic のほうが研究的には進歩している。最近は、応用先としてエッセイの改善のフィードバックなどがアツいため、 dimension-specific なタスクも注目されてきてはいる。
- データセットは5つ挙げられている。全部英語。他言語のものもあるようだが、本論文で挙げられているのはスウェーデン語とドイツ語のものだけ。詳細は全訳の2章にて。
- The Cambridge Learner Corpus-First Certificate in English exam (CLC-FCE)
- The Automated Student Assessment Prize (ASAP)
- The TOEFL11 corpus
- the International Corpus of Learner English (ICLE)
- Argument Annotated Essays (AAE)
- 手法に関しては、NLPの流行りの技術をちょっと遅れで適用していっているようなイメージ。埋め込みを使ってみたり、ニューラルネットを使ってみたり、アテンションを導入したり、転移学習を導入したり。
- 先人の苦労から得られた feature engineering の知見はいろいろある。語彙特徴などの単純なものから、可読性、意味、談話表現に関する特徴など難しいものまでが紹介されている。詳細は全訳の3.3節にて。
- 手法の性能評価には Quadratic weighted Kappa (QWK) という基準がもっともよく用いられる。
所感
- コーパスの話といくつかの研究を見て土地勘を掴むにはいいサーベイだった。
- が、 essay scoring だから発展したいい手法があった!という感じは全くなかった。
- 自然言語処理や機械学習の手法を輸入して順当に進めてきた、という感じ。
- モデル (3.2 Approaches 参照) も別に essay scoring 特有のものではなく、一般的なものを使っている。
- データセットを眺めてみても、いくつか悪くないものはあっても、決定的ないいものは存在しないというように見えた。
- 英語でこれなので、当然日本語ではもっと進んでないんだろうな、という気になった。
- 当然のように、言語資源の話でも日本語のことは1ミリも出てこなかった。
全訳
Abstract
- 50年以上にわたって研究されてきたにもかかわらず、自動小論文採点タスクはその商業的および教育的価値、ならびに関連する研究課題のために、自然言語処理コミュニティで大きな注目を集め続けている。
- この研究では自動小論文採点の研究が開始されてからの主要なマイルストーンの概要を紹介する。
1. Introduction
- 自動小論文採点タスク (Automated Essay Scoring; AES) は、計算機技術を使ってテキストをスコアリングするタスクであり、教育業界における自然言語処理 (NLP) の最も重要なアプリケーションの一つ。
- この研究分野は、 Page [1966] の Project Essay Grader システムに関する先駆的な研究から始まり、それ以来盛んに活動が続けられている。
- AESの研究の大部分は、単一のスコアでエッセイの質を要約する holistic1 なスコアリングにフォーカスしている。これには少なくとも2つの理由がある。
- 手作業でアノテーションされた holistic なスコアのコーパス (corpora) が公開されていて、学習ベースの holistic なスコアリングエンジンの開発が促進されていること。
- holistic な採点技術には商業的な価値があること。例えば、SATやGREなどの標準化された適性検査のために書かれる毎年数百万件のエッセイの採点を自動化できることで、手作業による採点の労力を大幅に節約できる。
-
holistic な採点の技術は、適性検査のために書かれたエッセイの採点には役立つものの、教室での使用 (classroom setting) のためには十分とはいえない。
- 教室での使用においては、エッセイを改善する方法について学生にフィードバックを提供することが最も重要である。
- 具体的には、学生に低い holistic なスコアを返すだけでは、エッセイのどの側面が低スコアの原因になっていて、どのようにすれば改善できるのか、についてのフィードバックを学生に提供することができない。
-
この弱点を考慮して、研究者らは近年、エッセイの質の特定の次元 (dimension2) のスコアリングに取り組み始めている。特定の値とは、具体的には次のようなものがある:
- 一貫性について [Higgins et al., 2004; Somasundaran et al., 2014]
- 技術的問題、設問との関連性 [Louis and Higgins, 2010; Persing and Ng, 2014]
-
Criterion [Burstein et al., 2004] などの、エッセイの品質の複数の側面に沿って指導的なフィードバックを提供する自動システムも登場し始めている。
-
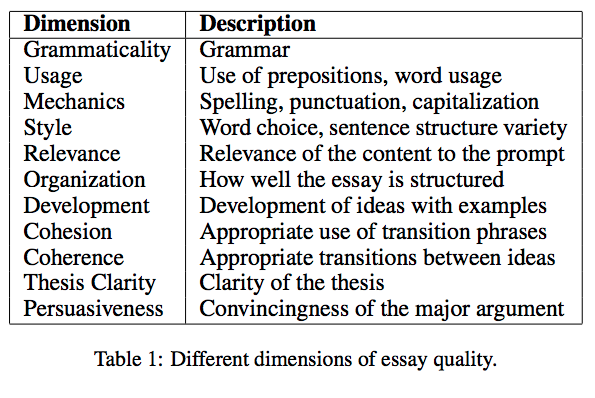
Table 1 に、 holistic なスコアに影響を与える可能性のあるエッセイの要素を列挙する。
-
エッセイの質のさまざまな側面に沿ってスコアを提供すると、著者(学生)はエッセイのどの側面を改善する必要があるかを特定するのに役立つ。
- 研究的な観点からみて、AESタスクの最も興味深い側面の一つは、難易度が異なる一連のNLPの問題を網羅していることである。
- Table 1 の品質の次元は、対応するスコア付けタスクの難易度が下に行くほど高くなるように大まかに並べられている。
- 例えば、(表で上のほうにある)文法的 (Grammaticality) および機械的 (Mechanics) なエラーの検出はすでに幅広く研究され、大きな成功を納めている。
- Table 1 の下の方を見ると、一貫性、論文の明瞭さ、説得力など、テキスト構造のさまざまな側面に関する計算モデリングを含む、(比較的研究されていないが、おそらく)かなり挑戦的な談話レベルの問題がいくつかある。
- これらの困難な次元の一部をモデリングするには、エッセイの内容を理解する必要まである。
- これは、最先端のエッセイスコアリングエンジンがカバーしている範囲を大きく超えている。
- この論文での目標は、50年以上前のAES研究の開始以来の主要なマイルストーンの概要を提供することである。
- いくつかの書籍 [Shermis and Burstein, 2003; Shermis and Burstein, 2013] と記事 [Zupanc and Bosnic, 2016] にこの分野の最新技術の概要が記載されているが、過去3年間に公開されたAES研究に関する有用なサーベイは存在しない。
- したがって、このタイムリーなサーベイはAI研究者に分野の最新の知識を提供できると考えている。
- 自動小論文採点の別の主要なサブエリアとして、エッセイのエラーを修正する問題は注目に値する。
- エラー修正はこのサーベイの対象範囲を超えているが、興味のある読者が概要を知るためには Leacock et al. [2014] が参考になる。
2. コーパス (Corpora)
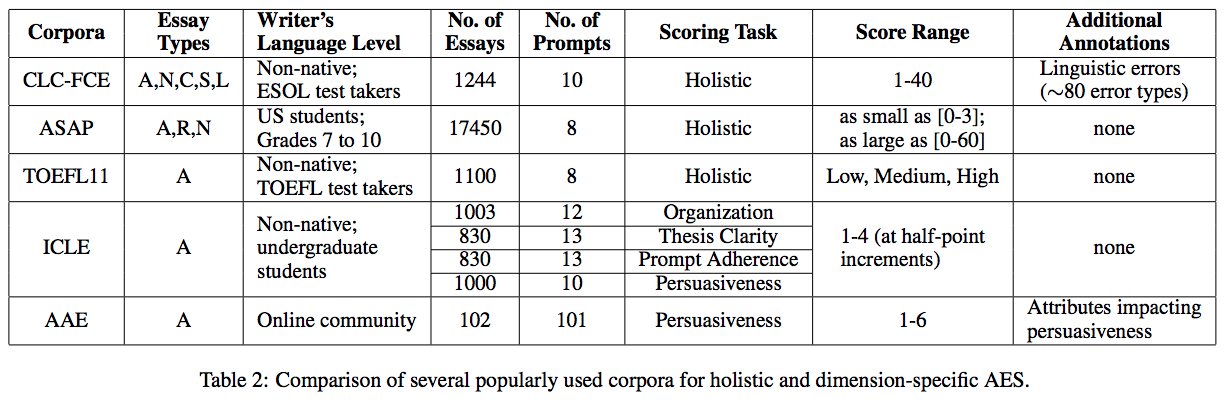
- このセクションでは、AESシステムの訓練と評価に広く使われている5つのコーパスを紹介する。
- Table 2 は、これらのコーパスを7つの次元に沿って評価したものである:
- コーパスに存在するエッセイの種類
- 論証 (A; argumentative)
- 応答 (R; response)
- 物語 (N; narrative)
- コメント (C; comment)
- 提案 (S; suggestion)
- 手紙 (L; letter)
- エッセイの書き手の言語レベル
- エッセイの数
- プロンプト (prompt3) の数
- スコアリングが holistic か dimension-specific か
- エッセイのスコアの範囲
- コーパスに関する追加の注釈
- コーパスに存在するエッセイの種類
The Cambridge Learner Corpus-First Certificate in English exam (CLC-FCE)
- [Yannakoudakis et al., 2011]
- 各エッセイに対して、 holistic なスコアと、エッセイに含まれる言語エラーの種類の両方を提供。
- 言語エラーは手動でタグ付けされたもの
- 言語エラーの例: 時制の誤り
- holistic なスコアリングだけでなく、文法的なエラーの検出と修正のためのシステムを構築するためにも使うことができるコーパスである。
- ただし、プロンプトごとのエッセイの数がかなり少ないため、プロンプト固有の高性能なシステム(= 同じプロンプトでトレーニングおよびテストされたシステム)を構築するのは難しい。
The Automated Student Assessment Prize (ASAP)
- 2012年にKaggleのコンペでリリースされて以来、holistic なスコアリングに広く使用されている。
- コーパスはエッセイの総数だけでなく、プロンプトごとのエッセイの数も大きい。
- 最大では3,000のエッセイをもつようなプロンプトがある。
- これにより、プロンプト固有の高性能なシステムの構築のためにも使える。
- ただし、その有用性を制限する可能性を孕む少なくとも2つの弱点がある:
- スコアの範囲がプロンプトごとに異なるため、複数のプロンプトを同時に使ってモデルをトレーニングすることが難しい。
- エッセイには段落の情報が含まれておらず、 name entity とその他の大文字の単語の両方を削除する aggressive な前処理プロセスを経ているため「オリジナルに忠実」ではない場合がある。
The TOEFL11 corpus
- [Blanchard et al., 2013]
- 実際の high-stakes exam であるTOEFLのエッセイが含まれている。
- エッセイは、その書き手が話す8つのプロンプトと11の母国語に均等に配分されている。
- コーパスはもともと、そのエッセイの書き手のネイティブ言語を識別するタスクのために構築されたものである、低中高のみで構成される粗いレベルの(英語の?)習熟度情報も添付されている。
- 一部の研究者は、これらの習熟度情報に関するラベルをエッセイの holistic なスコアとみなし、それらを用いてAESシステムをトレーニングしようとした。
- が、この問題設定には、「エッセイの品質は書き手の(英語の?)言語習熟度によって表すことができる」という根本的な仮定があり、これの正当性については疑問が残る。
- dimension-specific なエッセイスコアリング研究の進展を妨げる一つの原因は、 dimension-specific なスコアについて手動でアノテーションされたコーパスが不足していることである。
- dimension-specific なスコアリングを実行する目的で、 [Granger et al., 2009] は、エッセイの質のいくつかの dimension に沿って、 the International Corpus of Learner English というエッセイのサブセットをアノテーションした。
the International Corpus of Learner English (ICLE)
- コーパス自体の出典は [Granger et al., 2009]
- このコーパスでアノテーションした dimension は以下の通りである:
- 構成 (Organization): エッセイがどれだけうまく構成されている (well-organized) か [Persing et al., 2010]
- 論文の明瞭度 (Thesis Clarity): 著者がエッセイで取り上げた論文をどの程度明確に説明しているか [Persing and Ng, 2013]
- プロンプト遵守 (Prompt Adherence): エッセイのコンテンツが、それが書かれたプロンプトにどの程度関連しているか [Persing and Ng, 2014]
- 論証説得力 (Argument Persuasiveness): エッセイがその論文に対して行う論証の説得力 [Persing and Ng, 2015]
Argument Annotated Essays (AAE)
- [Stab and Gurevych, 2014]
- dimension-specific なスコアでアノテーションされた、ICLEとは別のコーパス。
- このコーパスには、テストのために説得力あるエッセイを書く能力を向上させたい学生にフィードバックを提供する essayforum2 から取得した402のエッセイが含まれる。
- 各エッセイには、その論証的な構造(= 主張や前提などの論証コンポーネントと、それらの間の関係 (e.g. support, attack)) がアノテーションされている。
- 近年、 Carlile et al. [2018] が説得力 (persuasiveness) 関してコーパスからランダムに選択された100のエッセイで議論 (argument) を採点した。
- Table 2 に示されているコーパスは全て英語のものである。
- 他の言語によるAESのコーパスも存在する:
- Ostling’s [2013]: スウェーデン語
- Horbach et al.’s [2017]: ドイツ語
3. Systems
- 続いて、既存のAESシステムを3つの視点から解説する:
- tasks: システムの開発に用いられたスコアリングタスク
- approaches: アプローチ
- features: 用いられた特徴量
3.1 Tasks
- 既存のAESシステムの大部分は holistic なスコアリング用に開発されたものである。
- dimension-specific なスコアリングは2004年まで始まらなかった。
- これまでいくつかの dimension が研究対象になってきた:
- organization [Persing et al., 2010]
- thesis clarity [Persing and Ng, 2013]
- argument persuasiveness [Persing and Ng, 2015; Ke et al., 2018]
- relevance to prompt [Louis and Higgins, 2010; Persing and Ng, 2014]
- coherence [Burstein et al., 2010; Somasundaran et al., 2014]
3.2 Approaches
- ほとんどすべての既存のAESシステムは学習ベースであり、教師あり学習、弱教師あり学習、強化学習のいずれを採用しているかに基づいて分類することができる。
- SotAなAESシステムはすべて教師ありのため、この節ではAESへの教師あり学習によるアプローチに焦点を当てる。
- AESへの弱教師あり学習の適用については Chen et al. [2010], 強化学習の適用については Wang et al. [2018] を紹介する。
- AESへの教師あり学習アプローチを採用している研究者は、タスクを以下の3つに再編した:
- a regression task: エッセイのスコアを予測することを目標とする。
- a classification task: エッセイを少数のクラス (e.g. 前述のTOEFL11コーパスのように質を低中高に分類する)のいずれかに属するものとして分類することを目標とする。
- a ranking task: 品質に基づいて2つ以上のエッセイをランクづけすることを目標とする。
- 典型的には、既存の (off-the-shelf) 学習アルゴリズムがモデルのトレーニングに使われる。
- 回帰の場合、一般に以下が用いられる:
- linear regression: [Page, 1966; Landauer et al., 2003; Miltsakaki and Kukich, 2004; Attali and Burstein, 2006; Klebanov et al., 2013; Faulkner, 2014; Crossley et al., 2015; Klebanov et al., 2016]
- SVR (support vector regression) : [Persing et al., 2010; Persing and Ng, 2013; Persing and Ng, 2014; Persing and Ng, 2015; Cozma et al., 2018]
- SMO (sequential minimal optimization; SVMのvariant): [Vajjala, 2018]
- 分類の場合、以下が用いられる:
- SMO [Vajjala, 2018]
- logistic regression [Farra et al., 2015; Nguyen and Litman, 2018]
- Bayesian network classification [Rudner and Liang, 2002]
- ランキングの場合、以下が用いられる:
- SVM ranking [Yannakoudakis et al., 2011; Yannakoudakis and Briscoe, 2012]
- LambdaMART [Chen and He, 2013]
Neural Approaches
- 最近の多くのAESシステムは neural-based である。
- 従来のAES研究において、多くの労力が features engineering に割かれているが、 neural approach のよく引用される利点は、 feature engineering の必要性をなくせること。
- AESの特徴量に関する詳細な議論は Section 3.3 を参照。
- holistic なエッセイスコアリングへの最初の neural approach は、 Taghipour and Ng [2016] (以下 T&N と書く) によって提案された。
- エッセイ内の単語の(one-hotベクトルの)シーケンスを入力として受け取って、モデルはまず convolution layer を使って n-gram レベルの特徴量を抽出する。
- n-gram内の単語間の local textual dependencies を捕捉したこれらの特徴量は、Long-Short Term Memory (LSTM) network [Hochreiter and Schmidhuber, 1997] で構成される recurrent layer に渡される。
- LSTMはエッセイ内の単語の long-distance dependencies を捕捉したベクトルを各タイムステップに関して出力する。
- 次に、異なるタイムステップからのベクトルを連結して、エッセイのスコアを予測するための dense laper への入力として機能するベクトルを作る。
- モデルがトレーニングされると、上記(?)のone-hotベクトルが更新される。
- 後続の neural AES models がすべてT&Nの拡張ではないが、それらはすべて次以降の節で説明されるような(T&Nの?)弱点のうち1つかそれ以上に対処しようとしている。
Learning Score-Specific Word Embeddings
- いくつかの単語には、良いエッセイと悪いエッセイを区別する力がほとんどない。
- こういった情報価値の低い単語を情報価値の高い単語と区別しないと、AESのパフォーマンスが低下する可能性がある。
- この問題を考慮して、Alikaniotis et al. [2016] は単語埋め込みをトレーニングした。
- 非形式的には、単語埋め込みは、意味的に類似する2つの単語が埋め込み空間で互いに近くなるように訓練できる、単語の低次元の実数値ベクトル表現である。
- 例えば、 king と queen は似たような場所に埋め込まれるべきだが、 king と table はそうではない。
- したがって、一般的に単語埋め込みはT&Nが使用するone-hot単語ベクトルよりも単語のsemanticsの表現として優れていると考えられている。
- 単語埋め込みは CW model [Collobert and Weston, 2008] として知られる単語埋め込み学習ニューラルネットワークアーキテクチャを利用して、巨大なunannotatedコーパスで学習することができるが、 Alikaniotis et al. は入力単語が出現するエッセイのスコアに対応する追加の出力で CW model をを拡張することによって、 task-specific な単語埋め込みを学習することを提案した。
- これらの score-specific word embeddings (SSWEs) は、エッセイの良し悪しの判定に有益な単語とそうでない単語をより適切に区別できると考えられており、 neuarl AES model をトレーニングするための特徴量として使われている。
Modeling Document Structure
- T&N と Alikaniotis et al. [2016] の両方は、文章を単語の線形なシーケンスとしてモデル化した。
- Dong and Zhang [2016] は、文書の階層構造をモデル化することで neural AES model を改善できるという仮説を立てた; 文書が次のように作られると仮定する:
- 単語を連結して文を作る
- 得られた文を連結して文書を作る
- その結果、彼らのモデルは、この2段階の階層構造に対応する2つの convolution layer, つまり単語レベルの convolution layer と文レベルの convolution layer を用いる。
- T&Nと同様に、単語レベルの convolution layer はone-hot単語ベクトルを入力として受け取り、他の文とは無関係に各文からn-gramレベルの特徴量を抽出する。
- pooling layer を追加したあと、各文から抽出されたn-gramレベルの特徴量は「文」ベクトルに圧縮される。
- 次に、エッセイの異なる文から生成された文ベクトルと文レベルの convolution layer が受け取り、異なる文からn-gramレベルの特徴量を抽出する。
Using Attention
- 上で述べられた通り、スコアリングを考える限り、エッセイの一部の文字、単語、および文は、他のそれらより重要であることがあるため、その重要なものにより注意を払う必要がある。
- ところが、 Dong and Zhang の two convolution layer neural network はこれに失敗する。
- 重要な文字、単語、文を自動的に識別するために、 Dong et al. [2017] は各層の後ろに max pooling や average pooling を挟むような単純なプーリングではなく、 attention pooling を使うことによって、 attention mechanism [Sutskever et al., 2014] をネットワークに組み込む。
- 具体的には、それぞれの attention pooling layer は対応する convolution layer の出力を入力として受け取り、トレーニング可能な weight matrix を用いて(?)、入力ベクトルの weighted combination であるベクトルを出力する。
Modeling Coherence
- Tay et al. [2018] は一貫性 (soherence) はエッセイの質に重要な dimension であるため、エッセイの一貫性スコアを計算して活用することにより、 holistic なスコアリングを改善することができると仮定した。
- 彼らは次のように一貫性をモデル化した:
- T&Nと同様に、ニューラルネットワークしてLSTMを採用。
- ただし、T&Nとは異なり、異なるタイムステップから収集されたLSTMの2つの positional output を入力として受け取り、そのような positional output の各ペアの類似性を計算する追加のレイヤーをニューラルモデルに使用する。
- その理由は直感的には、一貫性は類似性と正の相関を持つはずだからである。
- これらのニューラルコヒーレンス機能は、LSTMが出力するベクトル(= T&Nのように local and long-distance dependencies をエンコードするベクトル)を増強するために使用される。
- 最後に、彼らは、増強されたベクトルを使用して holistic なスコアを予測し、スコアリングプロセスの一貫性を効果的に活用する。
Transfer Learning
- 理想的には、トレーニングプロンプトとテスト(= ターゲット)プロンプトが同じであれば、我々は prompt-specific なAESシステムを訓練できる。
- これによりAESシステムがトレーニング用のエッセイから学習した prompt-specific な知識をさらにテスト用のエッセイをより正確に採点するために活用できるようになるため。
- ところが実際には、ターゲットプロンプトの十分な量のエッセイがトレーニングに利用できることは滅多にない。
- その結果、多くのAESシステムはプロンプトに依存しない方法でトレーニングされることになる。
- つまり、トレーニングには少数のターゲットプロンプトエッセイと、比較的多数の非ターゲットプロンプト (non-target-prompt) (= ソースプロンプト; source-prompt) エッセイが利用される、ということ。
- しかし(当然)、ソースプロンプトとターゲットプロンプトのエッセイで使用される語彙が一致しないことで prompt-independednce system のパフォーマンスが害される可能性がある。
- この問題に対処するため、研究者らはソースプロンプト/ソースドメインをターゲットプロンプト/ターゲットに劇用させるために、転移学習 (transfer learning) (= domain adaptation) 技術の利用可能性についての研究を進めた。
- EasyAdapt [Daumé III, 2007] は、シンプルだが効果的な transfer learning algorithm の1つ。
- ちょうど2つのドメイン(ソースドメインとターゲットドメイン)からのトレーニングデータを入力とする。
- 目標は、ターゲットドメインにおいてテストインスタンスを分類するときにいい感じに動作するようなモデルを学習すること。
- EasyAdaptの理解を深める:
- transfer learning を利用しないモデルは通常、ソースドメインとターゲットドメインの両方のインスタンスで共有される特徴空間を使用して学習される。
- EasyAdaptは空間内の各特徴を3回複製することでこの feature set を拡張する。
- 両方のドメインで共有される情報
- ソースドメインの情報
- ターゲットドメインの情報
- 拡張された特徴区間では、ターゲットドメイン情報がソースドメイン情報の2倍の重要性をもつように扱われるので、モデルがターゲットドメイン情報によりよく適応できるようになる(証明されている)。
- transfer learning をAESに適用する際には、プロンプトをドメインとして解釈することができる。
- 現実的なシナリオとしては、1つのターゲットプロンプトとトレーニングに使える複数のソースプロンプトがある。
- ただ、EasyAdaptは1つのターゲットドメインと1つのソースドメインしか処理できないため、EasyAdaptをAESに適用した研究者は、すべてのソースプロンプトを同じソースドメインに属するものとして扱った。
- 具体的な研究の例は以下:
- Phandi et al. [2015] がEasyAdaptを Correlated Bayesian Linear Ridge Regression として一般化し、(EasyAdaptのように2に固定するのではなく)ターゲットプロンプト情報に与えられる重みを学習できるようにした。
- Cummins et al. [2016] もまた transfer learning を実行し、EasyAdaptを使って特徴空間を拡張し、 pairwise ranker をトレーニングして、同じプロンプトからの制約を受ける2つのエッセイをランク付けした。
- 上記のシステムではターゲットプロンプトからの少数のエッセイがトレーニングに利用可能であると仮定しているが、 Jin et al. [2018] は2段階のフレームワークを介したトレーニングにターゲットプロンプトのエッセイを利用することができないという問題設定の下で transfer learning を実行した。
- Stage 1 では、テストセット内のターゲットプロンプトエッセイのうち極端な品質(= 非常に高いスコアあるいは非常に低いスコア)のものを識別することを目的とする。
- そのために、プロンプトに依存しない特徴量(e.g. 文法やスペルのエラーに基づく特徴量)を使用してソースプロンプトエッセイでモデルをトレーニングし、それを使用して(ターゲットドメイン)テストエッセイを採点する。
- これの裏にある根本的な仮定は、極端な品質のテストエッセイは、一般的な(つまり、プロンプトに依存しない)特徴量のみで識別できるということである。
- Stage 2 では、テストセット内の残りのエッセイ(= 極端な品質でないもの)を採点することを目的とする。
- そのために、 Stage 1 で0と1として識別された低品質なエッセイと高品質なエッセイに自動的にラベルをつける。
- その後、極端な品質でないエッセイの意味を適切に捉えるために prompt-specific な特徴が必要であるという仮定の下で、 prompt-specific な特徴を利用して、上でラベリングされたエッセイの予測器 (regressor) をトレーニングする。
- 最後に、学習して得られた regressor を使って残りのテストエッセイを採点する。
- 対象が極端な品質ではないことを考えると、その点数は0から1の間になると予想される。
- Stage 1 では、テストセット内のターゲットプロンプトエッセイのうち極端な品質(= 非常に高いスコアあるいは非常に低いスコア)のものを識別することを目的とする。
3.3 Features
- AESに関する大量の作業には feature development (engineering?) が含まれている。
- 最近開発されたAES用のニューラルモデルは特徴量設計の必要性を取り除くが、次の理由により、特徴量設計はAES研究において引き続き重要な役割を果たすと考えられる:
- ニューラルモデルを効果的にするには、大量のアノテート済みデータでトレーニングする必要がある。正確なAESモデルをトレーニングするのに十分なデータが、仮に英語にはあるとしても、大多数の他の自然言語には同じことが当てはまらない。これらの言語用のAESシステムを構築するための最も実用的な方法は、特徴量ベースのアプローチを採用することである。
- 英語であっても、 dimension 固有のAESシステムのトレーニングに使用できるデータの量はかなり限られている。アノテーション済みのコーパスが大きくなるまで、特徴量設計はdimension固有のAESシステムを構築するための重要なステップであり続ける。
- 多くの neural holistic scoring models がSotAを達成しているが、特徴量設計によって得られた手作りの (hand-crafred) 特徴を組み込みことで、これらのモデルをさらに改善できる可能性がある。
- 全体として、特徴量ベース (feature-based) のアプローチと neural なアプローチはそれぞれ競合しているわけではなく、補完的なものと見なされるべきだと考えられる。
- この節 (3.3) では、AESに使用されている特徴量について説明する。
Length-based features
- エッセイの長さは holistic なスコアと非常に強い正の相関があることがわかっているため、 length-based features はAESのもっと重要な特徴量タイプの一つである。
- これらの特徴は、エッセイの (文 and/or 単語 and/or 文字) の数の観点からエッセイの長さを特徴量にエンコードする。
Lexical features
- lexical features (語彙の特徴量) は2つのカテゴリに分類できる。
- エッセイに現れる単語の unigram, bigram, trigram.
- これらの単語 n-gram は、AESに役立つ可能性のある文法 (grammatical), 意味 (semantic), ディスコース (discourse) の情報をエンコードしているという観点で便利。
- 例:
- "people is" というbigramは、文法的でない (ungrammaticality) ことを示唆する。
- discourse connective (e.g. "moreover", "however") の利用は cohesion を示唆する。
- 特定のn-gramは、特定のプロンプトに関連する可能性のあるトピックの存在を示す。
- 特徴量としてn-gramを利用する主な利点は言語に依存しないことである。
- どの単語のn-gramが役立つかを学習するために通常多くの訓練データが必要になることが欠点。
- 単語n-gram, 特にunigramに基づいて計算された統計。
- 例えば、エッセイの特定の句読点の出現回数をエンコードする特徴などがある [Page, 1966; Chen and He, 2013; Phandi et al., 2015; Zesch et al., 2015] 。
Embeddings
- 埋め込み (embaddings) は、 n-gram特徴量のvariantと見做すことができ、おそらく単語n-gramよりも単語やフレーズの意味 (semantics) をより適切に表現したものである。
- AESには3種類の埋め込みベースの特徴量が使用されてきた:
- GLoVe [Pennington et al., 2014] などの大規模コーパスでpretrainされた埋め込みを使って計算された特徴量を使うもの。
- Cozma et al. [2018] は bag-of-super-word-embeddings を用いた。具体的には、k-meansを使ってpretrain済みの単語埋め込みをクラスタリングし、各単語が属するクラスタの重心を使って各単語を表現する。
- 前述の SSWEs [Alikaniotis et al., 2016] など、AES固有 (AES-specific) の埋め込みに基づいて計算された特徴量を使うもの。
- 元々は1つのone-hotベクトルである特徴量を使うが、これらの特徴量を使用するニューラルモデルがトレーニングされると更新されるようなもの [Taghipour and Ng, 2016; Dong and Zhang, 2016; Jin et al., 2018; Tay et al., 2018] 。
- GLoVe [Pennington et al., 2014] などの大規模コーパスでpretrainされた埋め込みを使って計算された特徴量を使うもの。
Word category features
- 単語カテゴリ特徴量 (word category featuers) は、単語リスト (wordlists) または辞書 (dictionaries) に基づいて計算される。
- これらはそれぞれ特定の語彙 (lexical), 構文 (syntactic), 意味 (semantic) のカテゴリに属する単語が含まれる(?)。
- 例えば、エッセイに特定のカテゴリの単語が存在すると、エッセイの著者の以下のような能力を明らかにすることができる:
- 自分のアイデアの整理
- まとまりがあり (cohendive) 首尾一貫した (coherent) プロンプトへの応答の作成
- 標準英語のマスター
- ので、特徴量は discourse connective, correctly spelled words, sentiment words, modals を含むリストに基づいて計算される [Yannakoudakis and Briscoe, 2012; Farra et al., 2015; McNamara et al., 2015; Cummins et al., 2016; Amorim et al., 2018]
- 例えば、エッセイに特定のカテゴリの単語が存在すると、エッセイの著者の以下のような能力を明らかにすることができる:
- 単語が8つのレベルの複雑さのカテゴリのどれに属するかをエンコードする単語リストも使われている [Breland et al., 1994] 。
- 直観的には、単語レベルが高いほどより高度な (sophisticated) 語彙を使うことを指し示す。
- 単語カテゴリ特徴量は、単語のn-gram特徴量を一般化するのを助け、訓練データが少量しか利用できない場合に特に役立つ。
Prompt-relevant features
- プロンプト関連性特徴量 (prompt-relevant features) は、エッセイとその問題文との関連性をエンコードするものである。
- 直観的に、プロンプトに準拠していないエッセイは高得点を獲得できない。
- エッセイとプロンプトの関連性を計算するために、異なる類似性の尺度が使用される:
- the number of word overlap and its variants [Louis and Higgins, 2010]
- word topicality [Klebanov et al., 2016]
- semantic similarity as measured by random indexing [Higgins et al., 2004]
Readability features
- 可読性特徴量 (readability features) は、エッセイの読みやすさをエンコードする。
- 読みやすさは単語のチョイスに大きく依存する。
- 優れたエッセイは過度に読みにくいものであってはならないが、同時に読みやすすぎてもいけない。
- 優れたエッセイでは、著者は幅広い語彙と様々な文構造を用いる必要がある。
- 通常、読みやすさは以下のような指標を使って計測される:
- Flesch-Kindcaid Reading Ease [Zesch et al., 2015] のような readability metrics
- the type-token ratio のような simple metrics
- ↑ エッセイ内の単語の総数に対する unique words の数の比
Syntactic features
- 構文特徴量 (syntactic features) は、エッセイの構文情報をエンコードする。
- 構文特徴量には、主に3つの種類がある。
- Part-of-speech (POS) tag sequences は単語n-gramの syntactic generalization を提供する。以下のような〜をエンコードするために使用される [Zesch et al., 2015]:
- 非文法性 (ungrammaticality): e.g. 複数形の名詞に単数形の動詞が続く
- スタイル: POSタグの比率を使用する
- Parse tree:
- 例えば、 parse tree の深さは、文の構文構造がどれほど複雑化をエンコードするために使われる [Chen and He, 2013]。
- Phrase structure rules は様々な文法構造の存在をエンコードするために使われる。
- grammatical/dependency relations はheadとその従属項の構文的な距離を計算するために使われる。
- 文法エラー率 (grammatical error rates)
- エッセイに出現する文法エラーの頻度をエンコードする特徴量を計算するために使われる。
- 言語モデルを使用するか、hand-annotated grammatical error type [Yannakoudakis et al., 2011; Yannakoudakis and Briscoe, 2012] から計算される。
- Part-of-speech (POS) tag sequences は単語n-gramの syntactic generalization を提供する。以下のような〜をエンコードするために使用される [Zesch et al., 2015]:
Argumentation features
- 論証特徴量 (argumentation features) は、エッセイの論証的構造に基づいて計算される。
- 結果として、これらの特徴量は説得力のある (persuasive) エッセイ(論証的な構造が存在するようなエッセイ)にのみ適用可能であり、エッセイで作られている議論の説得力を予測するためにしばしば使われている [Persing and Ng, 2015]。
- エッセイの論証的構造は、ノードが論証コンポーネント (e.g. 主張、前提) に対応し、エッジが2つの論証コンポーネント間の関係 (e.g. 1つのコンポーネントが他を support するか attack するか) に対応するようなツリー構造として表現される。
- 例えば、通常、エッセイには主要な主張 (major claim) が存在する。これはエッセイのトピックに対する著者のスタンスをエンコードするものである。
- 主要な主張は、1つ以上の主張(claim; さらなる証拠なくしては読者が容易に受け入れてはならないような、物議を醸す声明)によって support または attack され、またその主張はそれぞれなんらかの根拠や前提 (premise) によって support または attack される。
- 論証特徴量は、論証コンポーネントとそれらの関係(e.g. 段落内の claims と premisesの数)および論証ツリーの構造(e.g. ツリーの深さ)に基づいて計算される [Ghosh et al., 2016; Wachsmuth et al., 2016; Nguyen and Litman, 2018]。
Semantic features
- 意味特徴量 (semantic features) は、エッセイの異なる単語間の語彙の意味関係をエンコードする。
- 意味特徴量には主に以下の2種類がある:
- Histogram-based features [Klebanov and Flor, 2013]
- 次のように計算される
- 共起に基づいて2つの単語間の関連度を測定する自己相互情報量 (pointwise mutual information; PMI) を、エッセイの各単語のペアについて計算する。
- PMIの値を binning することでヒストグラムを作成する。 bin の値は、 bin 内に収まるPMIの値をもつ単語のペアの割合になる。
- ヒストグラムに基づいて特徴量を計算する。
- 直観的には、関連性の高い単語のペアの割合が大きいほど、エッセイ内でのトピックがよく発達していることを示し、関連性の低い単語のペアの割合が大きいほど、言語のより創造的なしようを示唆している可能性がある。
- 次のように計算される
- Frame-based features
- FrameNet [Baker et al., 1998] の semantic frame に基づいて計算される。
- 簡単に言えば、 frame は文で発生するイベントを記述するもので、 frame の event element は対応するイベントに参加する人またはオブジェクトに該当する。
- より具体的な例として、 “they said they do not believe that the prison system is outdated” (彼らは刑務所制度は時代遅れだとは思わないと言った)という文について考える。
- この文では、 "they" が発話者として参加する event が説明されているため、 statement frame が含まれているとみなされる。
- エッセイの明瞭度は著者の意見に基づいて測定されるべきであるため、この意見が著者以外にの誰かによって表明されたという事実を、エッセイの明瞭度の評価に役立てることができる[Persing and Ng, 2013]。
- Histogram-based features [Klebanov and Flor, 2013]
Discourse features
- 談話特徴量 (discourse features) は、エッセイの談話構造をエンコードする。
- 談話特徴量は以下の4つの要素から導かれる:
- entity grids
- Barzilay and Lapata [2008] によって設計された談話表現。
- Centering Theory [Grosz et al., 1995] に基づいてテキストの local coherence を捉え、 local coherence features [Yannakoudakis and Briscoe, 2012] を導くために用いられた。
- Rhetorical Structure Theory (RST) trees
- RST [Mann and Thompson, 1988] に基づいて構築された discourse parse trees (談話解析木) であり、テキストの改装談話構造をエンコードする。
- 例えば、1つの談話セグメントが他の談話セグメントの解説になっているのか、それとも他の談話セグメントと対比関係にあるのか、など。
- RST trees は、エッセイの local および global な一貫性 (coherence) を捉える特徴を導くために用いられる[Somasundaran et al., 2014]。
- RST [Mann and Thompson, 1988] に基づいて構築された discourse parse trees (談話解析木) であり、テキストの改装談話構造をエンコードする。
- lexical chains
- lexical chains (字句連鎖) は、文書内の関連する単語のシーケンスであり、テキストのまとまりの指標として用いられる[Morris and Hirst, 1991]。
- 直観的には、多くの lexical chains を含むエッセイ、特に chain の始まりと終わりがエッセイの大部分をカバーするものを含むようなエッセイは、より凝集したエッセイである傾向がある[Somasundaran et al., 2014]。
- discourse function labels
- discourse function labels (談話機能ラベル) は、特定のエッセイの談話機能を示す文または段落として定義される。
- 例えば、段落が序文なのか結論なのか、文がエッセイの命題なのかどうか、など。
- これらのラベルは、 organization をスコアリングするための特徴量を導くために用いられている[Persing et al., 2010]。
- entity grids
4. Evaluation
- この章では、AESシステムの評価に使われるmetricsとschemasについて説明する。
- 最も広く採用されている評価基準は Quadratic weighted Kappa (QWK) である。
- 基本的には0から1の値になるmetricだが、偶然に予想されるものよりも一致が少ない場合は値が負になる可能性がある。
- 詳細は https://www.kaggle.com/c/asap-aes#evaluation を参照。
- その他に広く使用されているmetricsとしては以下のようなものがある:
- Mean Absolute Error (MAE)
- Mean Square Error (MSE)
- correlation metrics:
- Pearson's Correlation Coefficient (PCC)
- Spearman's Correlation Coefficient (SCC)
- AESのこれらの測定基準やその他の測定基準の適切性に関する詳細な議論については Yannakoudakis and Cummins [2015] を参照。
- AESには2つの評価スキーマがある:
- in-domain evaluation: システムは同じプロンプトで訓練および評価され、全てのプロンプトでパフォーマンスを平均することによって全体的なパフォーマンスを測定する。
- cross-domain evaluation: システムはさまざまなプロンプトで訓練および評価される。
- 通常、この評価スキーマは transfer learning を実行するAESを評価するために使われる。
5. The State of the Art
- この章では、 Section 2 で説明した5つの評価コーパスでSotAを達成したシステムの概要を示す。
- QWK, PCC, MAE によって評価された結果を Table 3 に示す。
- ASAPでは in-domain および cross-domain の結果を利用できるため、その両方を記す。
- cross-domain の結果については、「プロンプトXで訓練しプロンプトYでテストした」ことを示す表記として "X → Y" を用いる。
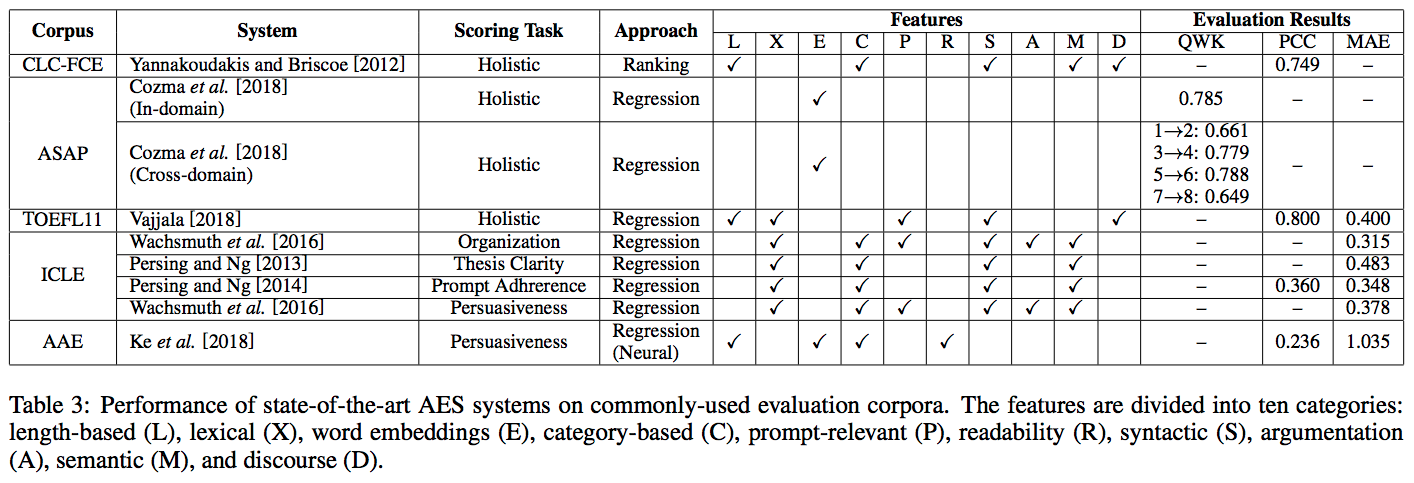
- holistic なスコアリング (CLC-FCE, ASAP, TOEFL11) の場合、QWKとPCCの両方が非常に高くなる。
- 例えば、 in-domain および cross-domain の両方が0.6を超えている。
- dimension-specific な手法をPCCで評価すると、 holistic なスコアリングよりも悪い。
- にもかかわらず、これらの結果は、少なくとも以下の2つの理由から、 holistic なスコアリングが domein-specific なスコアリングよりも簡単であることを示唆するものでは必ずしもない:
- これらの結果は異なるコーパスから得られているため、直接比較することができない。
- holistic な scorer を訓練するために使われるエッセイの数は、 domain-specific な scorer を訓練するために使われるエッセイの数よりも多くなる傾向がある。
- というところまで述べたが、結局のところこれらの結果が示唆しているのは、dimension-specific なスコアリングの問題が解決されるには程遠いということである。
6. Concluding Remarks
- 研究者らは困難にもかかわらずAESの継続的な進歩に貢献している。今後の有望な研究の方向性は何か?というのは自然な質問である。
- 学生へのフィードバックに関するもの。
- 先述したように、特定の質の dimension に沿ってエッセイを採点することによって、学生に提供されるフィードバックを改善する試みがある。これを用いると、学生のエッセイの holistic なスコアが低い場合、その学生は質のどの dimension を改善する必要があるのかを知ることができる。
- ただし、特定の dimension のスコアが低い生徒はそのスコアが低い理由を知らない可能性があるため、このフィードバックはまだ適切ではないということもできる。
- Ke et al. [2018] による最近の研究では、説得力スコアに影響を与える可能性のある議論の属性を識別するところからこの問題の調査を始めた。彼らが特定した属性のうちの2つは以下のものである:
- Specificity (特異性): 議論内の記述の具体性
- Evidence (証拠): 議論内で行われている主張を裏付ける主張の強さ
- 直観的には、説得力のある議論は具体的であり、主張を裏付ける強力な証拠を持つべきである。
- したがって、説得力に加えて議論のこれらの属性をスコアリングすると、学生に追加のフィードバックを提供することができる。
- 学生の議論の説得力スコアが低かった場合、学生は属性のスコアを調べることを通じて、議論のどの側面を改善するべきかを考える。
- 全体として、フィードバックは注目に値する分野であると我々は考えている。
- データのアノテーションに関するもの。
- 前述のように、 dimension-specific なスコアリングの研究の発展が妨げられている原因の一つは、モデルの訓練に必要なアノテーション済みコーパスが不足していることである。
- あまり強調されてない問題は、アノテーションするコーパスをどのように選ぶべきかということである。
- 長い目で見れば、AES研究は、異なる研究者が同じコーパスに対してアノテーションした場合にのみ実質的な進歩がもたらされると我々は考えている。
- 例えば、クオリティに関する複数の dimension に沿って採点されたエッセイのコーパスがあると、これらの dimension が相互にどのように作用して holistic なスコアを生み出しているのかを研究するのが容易になる。また、困難な dimension-specific なスコアリングタスクを可能にする、マルチタスク学習で互いに助け合うようなジョイントモデルを訓練することを可能にする。
- データの大規模なアノテーションには時間がかかるが、これはデータのアノテーションが完了するまでAESの研究を進めることができないことを意味するものではない。
- アノテーション済みの訓練データが大量にない場合にも堅牢なモデルを学習する方法を探ることができる。
- 例えば、様々なNLPタスクでSotAな結果を達成するために近年よく用いられている新しい language representation model である BERT [Devlin et al., 2019] を利用することもできる。
- アイデアは、最初にBERTを使って大量のラベルなしデータから deep bidirectional representations を事前に訓練しておき、次に1つの追加の出力レイヤー(この場合はスコアリング用のレイヤー)で結果のモデルを微調整することである。
- 別の可能性は、AESのニューラルモデルを訓練するときに、 hand-crafted features を用いた入力エッセイを増加させることである(?)。
- 異なる dimension 間の相互作用を調査することに加えて、 automated essay revision [Zhang et al., 2017] などのエッセイ評価に関する他の分野の研究(例えば、この研究は、エッセイの命題や議論をより強く修正することを目標としている)とAESがどのように相互作用するかを調査する価値があると我々は考えている。
- Automated essay revision は、議論の説得力のスコアを有効に利用することができる。
- 具体的には、議論をより強くするためにどのように修正するかを決定する最初のステップは、それがなぜ弱いかを理解することであり、前述の属性 Ke et al. [2018] は、議論を弱くするものを修正する方法についての洞察を提供することができる。
- 最後に、AESの技術を教室で使用できるようにするためには、AESシステムから得たフィードバックがライティングスキルの向上に役立つかどうかを学生が報告できるようにするユーザー調査を実施することが重要である。
-
"holistic" は直訳すると「全体論的な」という意味だが、本論文では「一貫性や設問との関連性といった、エッセイの特定の質に関して採点するタスク」と対比して、「エッセイ全体の良し悪しを評価するタスク」のことを指す目的で使われている。 ↩
-
holistic の対になる概念として dimension-specific という概念が使われている。 ↩
-
(Essay) prompt とは、トピックまたは問題に焦点を合わせた文で、その後に質問が続く。 エッセイプロンプトの目的は、作文、推論、および分析スキルをテストするエッセイの形で応答を促すことである。 https://www.quora.com/What-is-an-essay-prompt ↩