この記事は?
化学系企業に勤める平社員が、独学で学んだpythonと少しのhtmlの知識でWebアプリを開発し、社内に導入するまでの物語である。
記事の目的は以下の通りです。
- 自分が実装したことや工夫した点を整理すること。
- pythonを学習したけど、どうやって共有しようかと困っている人にヒントを与えること。
目次
背景
元々pythonを業務効率化のために勉強し、自分一人のために活用していましたが、それでは勿体ないと考え、社内の人達に利用してもらおうと思ったのがきっかけです。
作成したスクリプトのうち、社内で共有しようと思ったのがベイズ最適化でした。ベイズ最適化とは、ブラックボックス関数 (関数式が不明)の大域的最適解を求める手法です。実験によって得られた値からブラックボックス関数を予測し、良好な結果を与えるxを"ベイズ的に"提案します (詳細はこちら)。これを化学に落とし込むと、過去の実験から収率を最大化したり、純度を向上させたりするパラメータ条件を効率的かつ迅速に求めることに相当します。ベイズ最適化を利用することで、研究開発の速度向上や経験の浅い研究者でも簡単に反応の最適化が期待でき、これが実装できれば社内へのインパクトが最もあると判断し、ベイズ最適化を選定しました。
𝑓(𝑥) = 𝑎_1 \times 𝑥_1 + 𝑎_2 \times 𝑥_2 + 𝑎_3 \times 𝑥_3 + 𝑏\\
↓ 化学反応を関数と見立てると\\
𝑦𝑖𝑒𝑙𝑑 = 𝑎_1 \times 𝑙𝑖𝑔𝑎𝑛𝑑 + 𝑎_2 \times 𝑏𝑎𝑠𝑒 + 𝑎_3 \times 𝑡𝑒𝑚𝑝. + 𝑏
開発したWebアプリ
先に開発したWebアプリの全容を紹介します。
- Python version 3.7.5
- Requirements
- edbo 0.1.0
- pytorch 1.3.1
- django 3.2
- django-cleanup 6.0.0
- rdkit 2020.09.1.0
- sklearn 1.0.2
- pandas 1.3.5
- numpy 1.21.5
- matplotlib 3.5.1
- mordred 1.2.0
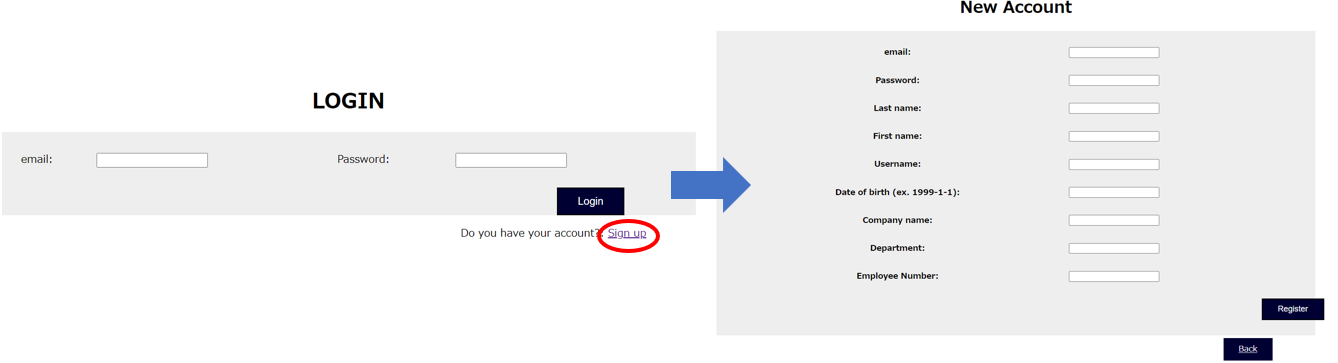
【ログイン画面】
メールアドレスやパスワード、基本情報を入力します。ログインの認証はメールアドレスとパスワードにカスタマイズしています。
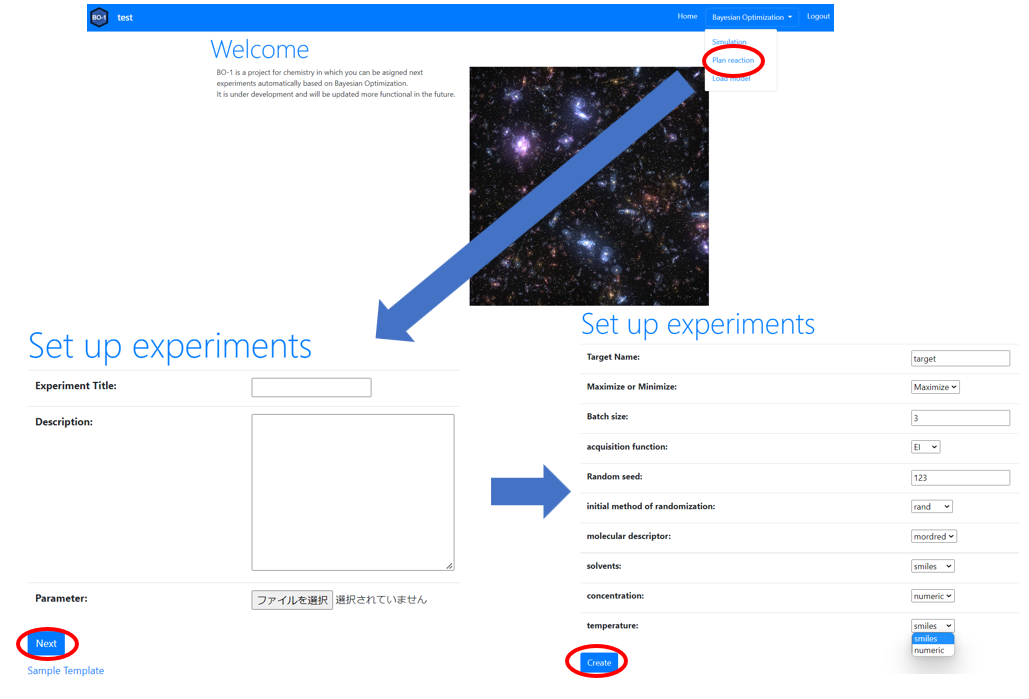
【プロジェクトの設計】
上部のナビゲーションバーからプロジェクトのタイトルや説明、反応パラメータを入力します。次の画面では、詳細な実験条件を設定します。
- ターゲットとする値の名前の設定
- ターゲットとする値を最大化したいのか、最小化したいのかの設定
- 一度に実施できる実験数の設定
- 獲得関数の選択
- ランダムシードの設定
- 初めに選ぶ実験パラメータの選び方の選択
- 分子記述子の選択
- 反応パラメータが化合物か数値かの設定
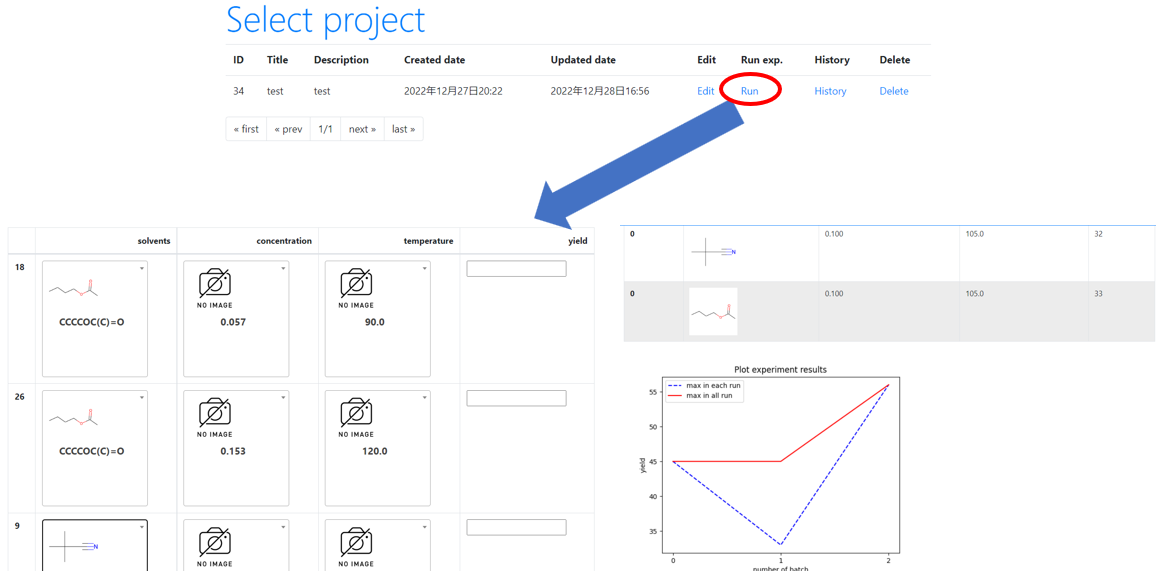
【実験結果の入力】
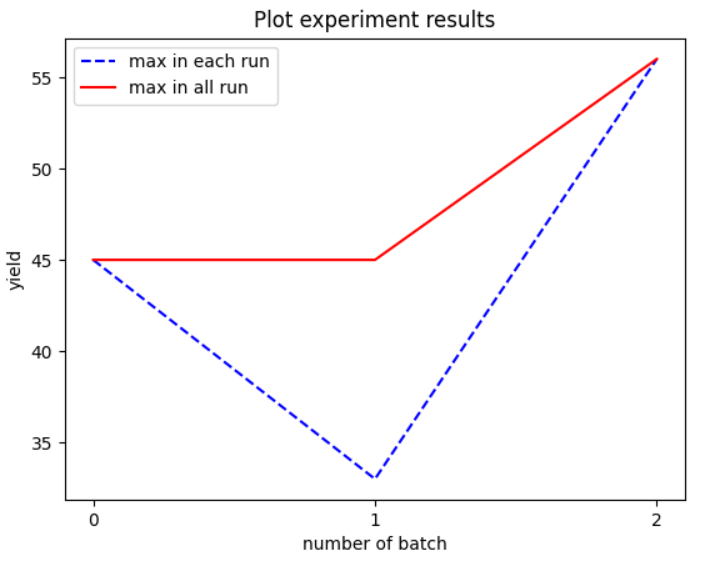
上部のナビゲーションバーからプロジェクトの選択をします。提案されている実験を実際に行い、その結果を入力します。提案されている実験は変更することもできます。実験結果は後から確認することができ、グラフ表示もさせています。プロジェクトは編集したり、削除したりすることができます。
構想
事前調査と予備知識から、以下のような実装計画を考案しました。
- ベイズ最適化を化学用に適応する → すでに化学用にライブラリを開発された方がおり、これを拝借する。
- 社内の人達に利用してもらう → Webアプリで共有 (Django)。
- Webアプリ用のサーバの立ち上げ → PythonAnywhereを利用する (後に代替法であるRaspberry piを紹介)。
実装
ここからは直面した課題とその解決策を時系列に沿って紹介していきます。なるべくニッチな課題について解説していきます。
社内の人達に利用してもらうにはどうすればよいか?
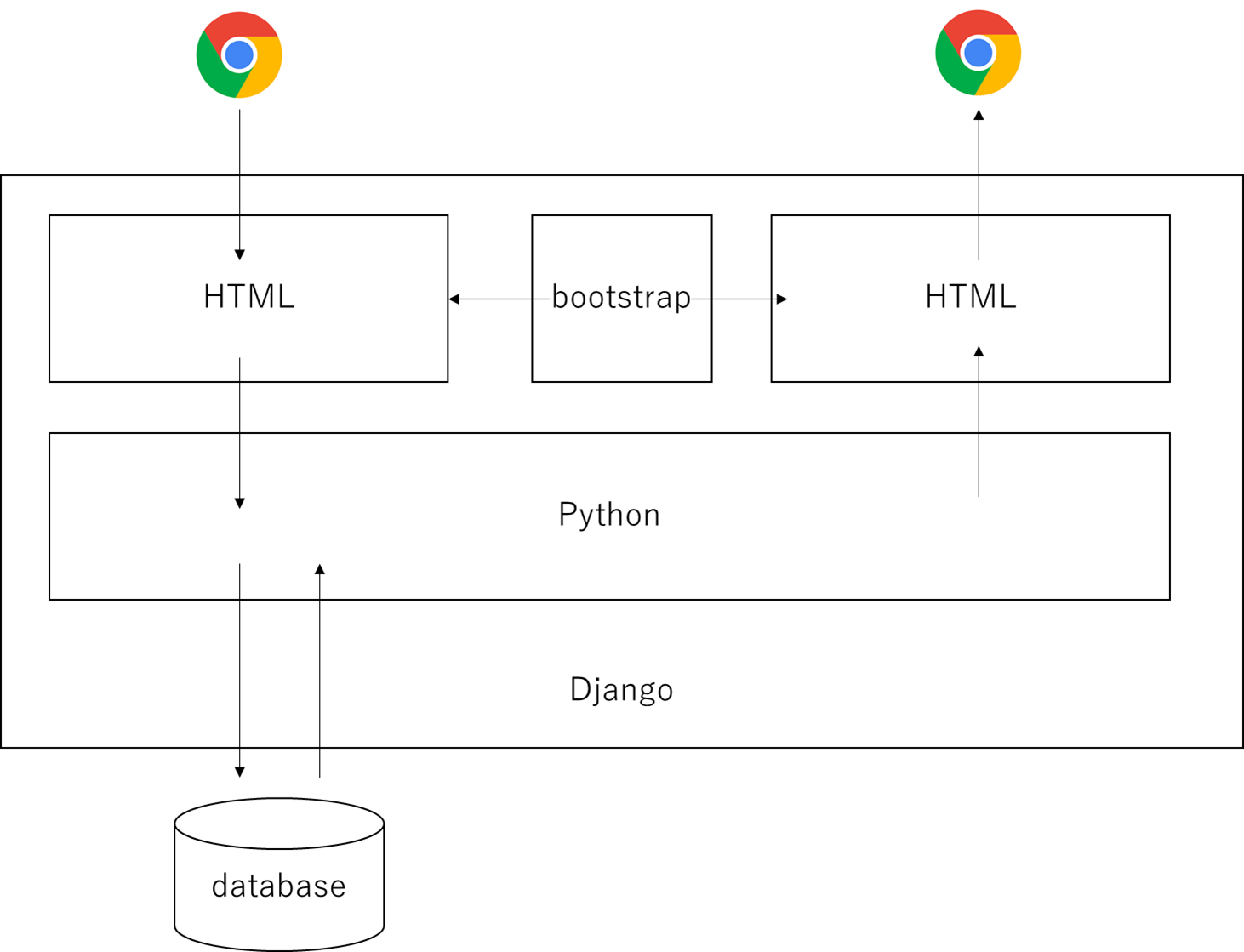
私自身はPython上でのベイズ最適化を実装することはできていましたが、化学系企業でプログラミングを扱える人はほとんどいませんでした。そこで、DjangoというPythonで実装されたWebアプリケーションフレームワークを利用しようとしました。Webアプリとは、一般的なコーポレートサイトやブログサイトなどとは異なり、高度な機能を持ったWEBサイトです。例えば、YoutubeやFacebookなどの裏では高度なプログラミングが実行されていますが、ユーザーは簡単な操作でWebサービスを受けることができます。ベイズ最適化をWebアプリに埋め込むことで、プログラミングができない人達にも実施できるようにしようと考えました。
かなり軽い気持ちでDjangoの学習を始めたのですが2点注意が必要です。
- Pythonで実装されたWebアプリケーションフレームワークといっても、HTMLやCSSを全く学習しなくて良いというわけではありません。イメージとしては、pythonで処理した情報をHTMLに埋め込んだり、HTMLから発信された情報をpythonで処理したりする感じです。
- Djangoを自由自在に扱えるようになるには結構な学習コストを要するので、小規模なプロジェクトなら、Flask (Djangoと同じくPythonで実装されたWebアプリケーションフレームワーク)が良いかもしれません。
さらに、見栄えを良くしようとすると、CSSやJavascriptがの知識が必要ですが、今回はBootstrapというHTMLおよびCSSベースのデザインテンプレートとして用意されているフリーソフトを使用しました。CSSとJavasriptの初級を学んで、基本概念やこれらで何ができるかを学習し、Bootstrapで楽に実装するのがよい学習スタイルだと思います。
ここからはpythonとDjangoをある程度学習した前提で話を進めていきます。
ユーザー認証をカスタマイズしたい
PythonAnywhereで公開するとなると、全世界に公開することになるので、デフォルトのユーザー認証ではなく、メールアドレスでログインするなどの設定し、なるべくセキュリティを強化する必要がありました。
そのためには、UserをAbstractBaseUserかAbstractUserを継承したクラスに変更する必要あります。Django公式でも初期Userをカスタマイズすることが推奨されています。正直、このあたりは私も勉強中なので、深くは解説できませんが、これとかこれを参考に切り貼りしながら作成しました。どうやら、ユーザーモデルを後から修正するのは非常に手間がかかるらしいので、必要なさそうなフォームでもとりあえず作成しておくのが吉だと思います。
from django.db import models
from django.contrib.auth.models import BaseUserManager, AbstractBaseUser, PermissionsMixin
#usernameでバリーデートするために入れときました(無くてもOK)
from django.core.validators import MinLengthValidator, RegexValidator
from django.db import models
from django.contrib.auth.models import BaseUserManager, AbstractBaseUser, PermissionsMixin
from django.core.validators import MinLengthValidator, RegexValidator
class MyUserManager(BaseUserManager):
def create_user(self, username, email, password=None):
if not username:
raise ValueError('Users must have an username')
if not email:
raise ValueError('Users must have an email address')
user = self.model(
username=username,
email=self.normalize_email(email),
)
user.set_password(password)
user.save(using=self._db)
return user
def create_superuser(self, username, email, password):
user = self.create_user(
username=username,
email=self.normalize_email(email),
password=password,
)
user.is_admin=True
user.is_staff=True
user.is_superuser=True
user.save(using=self._db)
return user
class MyUser(AbstractBaseUser, PermissionsMixin):
username = models.CharField(verbose_name='username', max_length=100, unique=False, validators=[MinLengthValidator(2,), RegexValidator(r'^[a-zA-Z0-9]*$',)])
email = models.EmailField(verbose_name='Email', max_length=200, unique=True)
last_name = models.CharField(verbose_name='last name', max_length=50, blank=False, null=False)
first_name = models.CharField(verbose_name='first name', max_length=50, blank=False, null=False)
company_name = models.CharField(verbose_name='company name', max_length=200, blank=False, null=False)
date_of_birth = models.DateField(verbose_name="date of birth", blank=True, null=True)
image = models.ImageField(verbose_name='profile image', upload_to="image/", blank=True, null=True)
url = models.URLField(verbose_name='URL', blank=True, null=True)
introduction = models.TextField(verbose_name='introduction', max_length=300, blank=True, null=True)
date_joined = models.DateTimeField(verbose_name='date joined', auto_now_add=True)
is_active = models.BooleanField(default=True)
is_administer = models.BooleanField(default=False)
is_staff = models.BooleanField(default=False)
is_admin = models.BooleanField(default=False)
#AbstractBaseUserにはMyUserManagerが必要
objects = MyUserManager()
#一意の識別子として使用されます
USERNAME_FIELD = 'email'
#ユーザーを作成するときにプロンプトに表示されるフィールド名のリストです。
REQUIRED_FIELDS = ['username']
def __str__(self):
return self.username
def get_full_name(self):
full_name = '{} {}'.format(self.last_name, self.first_name)
return full_name.strip()
そして、ログインのviews.pyは以下の通りです。とりあえずこれでユーザー認証は完成しました。
import email
from django.shortcuts import render
from django.views.generic import TemplateView #テンプレートタグ
from .forms import AccountForm #ユーザーアカウントフォーム
# ログイン・ログアウト処理に利用
from django.contrib.auth import authenticate, login, logout
from django.http import HttpResponseRedirect, HttpResponse
from django.urls import reverse
from django.contrib.auth.decorators import login_required
#ログイン
def Login(request):
# POST
if request.method == 'POST':
# フォーム入力のメールアドレス・パスワード取得
email = request.POST.get('email')
Pass = request.POST.get('password')
# Djangoの認証機能
user = authenticate(email=email, password=Pass)
# ユーザー認証
if user:
#ユーザーアクティベート判定
if user.is_active:
# ログイン
login(request,user)
# ホームページ遷移
return HttpResponseRedirect(reverse('bo_app:bo_index'))
else:
# アカウント利用不可
return HttpResponse("アカウントが有効ではありません")
# ユーザー認証失敗
else:
return HttpResponse("ログインIDまたはパスワードが間違っています")
# GET
else:
return render(request, 'users/login.html')
#ログアウト
@login_required
def Logout(request):
logout(request)
# ログイン画面遷移
return HttpResponseRedirect(reverse('users:Login'))
#ホーム
@login_required
def home(request):
params = {"username":request.user,}
return render(request, "users/home.html",context=params)
#新規登録
class AccountRegistration(TemplateView):
def __init__(self):
self.params = {
"AccountCreate":False,
"account_form": AccountForm(),
}
#Get処理
def get(self,request):
self.params["account_form"] = AccountForm()
self.params["AccountCreate"] = False
return render(request,"users/register.html",context=self.params)
#Post処理
def post(self,request):
self.params["account_form"] = AccountForm(data=request.POST)
#フォーム入力の有効検証
if self.params["account_form"].is_valid():
# アカウント情報をDB保存
account = self.params["account_form"].save()
# パスワードをハッシュ化
account.set_password(account.password)
# ハッシュ化パスワード更新
account.save()
self.params["AccountCreate"] = True
else:
# フォームが有効でない場合
print(self.params["account_form"].errors)
return render(request,"users/register.html",context=self.params)
ページが遷移してもデータを保存したい
formで一度データを送信して、そのデータを元に次のformを作成したい場合があります。今回の実装の場合ですと、反応パラメータのform入力からそれらが化合物なのか数値的なものなのかをユーザーに問いかけるformです。これにはrequest.sessionを使用します。
一つ注意したいのが、request.sessionはログインしている間は常にデータが保持されるという点です。妙な挙動をさせないためにも、GETの段階ではrequest.session=""などで空にしておくのが良いと思います。
# GET
request.session['form_data1'] = ""
# 何かしらの処理
request.session['form_data1'] = [request.POST, request.FILES] # データを保管する
# POST
# 上記のデータを取り出す。
session_form_data = request.session.get('form_data1')
title = session_form_data[0].get('title')
file = session_form_data[1].get('parameter')
コード上で生成したpklファイルやcsvファイルをモデルに保存したい
実装する上で、pklファイルやcsvファイルを生成してそれをDjangoのモデルに保存する工程がありました。一時的にディレクトリに保存して後で削除するのは面倒でした。
そこで、メモリ上にpklファイルやcsvファイルをバイナリデータとして扱うことで解決しました。このメモリ上にデータを書き込むという処理は非常に便利で、この後も度々登場しますので覚えておいて損はないです。
from io import BytesIO
import dill
from django.core.files import File
buffer = BytesIO() # メモリ上でバイナリデータを扱う
dill.dump(bo.__dict__, buffer, -1) # bo.__dict__は、boというインスタンスのデータを辞書形式で出力する。
buffer.seek(0) # ファイルポインタの位置
created_model.pickle.save("test.pkl", File(buffer)) # djangoのモデルをセーブする
pd.DataFrameをhtmlのテーブルに表示したい
実験のテーブルなどはpandas.DataFrameで扱っており、それをユーザーに表示させたいことが多々ありました。pandasには.to_html()という便利なメソッドがあり、これを使うことで簡単にhtml上にテーブルを表示することができました。更に、引数に値を渡すことで様々なオプションを実行できます。今回はテーブルの罫線表示 (table-bordered)と、マウスをテーブルに乗せるとハイライトされる (table-hover)ようにしました。.to_html()したものは<th>などのhtmlタグを含むので、htmlファイルでは{{変数 | safe}}と記述することで表示させることができます。
# new_dfはpd.DataFrameです。
table_html = new_df.to_html(classes=["table", "table-bordered", "table-hover"], escape=False)
self.params['table'] = table_html
{{table | safe}}
グラフを表示させたい
実験結果をグラフとして表示させたいと思いました。通常のpython環境なら、matplotlibのplt.show()でグラフを表示できますが、htmlファイルに渡すには少しコツが必要です。
まずpyplotの初期化をplt.clf()で行います。これを行わないと、ページにアクセスするたびにグラフが増殖してしまいます。次にいつも通りのグラフ表示の処理を行います。最後にOutput_Graph()という自作関数を呼び出してそれをパラメータに渡します。Output_Graph()は上述のファイル保存の流れと似ています。メモリ上にグラフを画像として保存し、base64でエンコードします。base64とは、データを文字や数字に変換する方式の一つです。Output_Graph()の返し値をhtml上の<img src= ???>に渡すことでグラフを表示することができました。
plt.clf() # reset pyplot.
# pltで表示する処理
# plt.plot(X,y)など
graph = Output_Graph()
self.params['Graph'] = graph
def Output_Graph():
buffer = BytesIO() #バイナリI/O(画像や音声データを取り扱う際に利用)
plt.savefig(buffer, format="png") #png形式の画像データを取り扱う
buffer.seek(0) #ストリーム先頭のoffset byteに変更
img = buffer.getvalue() #バッファの全内容を含むbytes
graph = base64.b64encode(img) #画像ファイルをbase64でエンコード
graph = graph.decode("utf-8") #デコードして文字列から画像に変換
buffer.close()
return "data:image/png;base64,"+graph
<img src="{{ Graph | safe }}">
化合物を表示させたい
化合物は基本的に図で表します。実験のパラメータを入力する際はsmilesという形式で化合物を1行の文字列で表現します (ベンゼンならc1ccccc1と表す)。これをrdkitという化合物を取り扱うライブラリでMolオブジェクトに変換します。ここから化合物の画像を出力することができます。以下のgetImage関数は、Molオブジェクトを受け取って、化合物の画像をbase64でエンコードされた値を返します。上述のグラフ表示と同様にhtml上の<img src= ???>に渡すことで化合物の画像を表示します。
def getImage(mol):
if not isinstance(mol, type(Chem.MolFromSmiles(""))):
return mol
image = Draw.MolToImage(mol)
buffer = BytesIO() # メモリ上への仮保管先を生成
image.save(buffer, format="PNG") # pillowのImage.saveメソッドで仮保管先へ保存
# 保存したデータをbase64encodeメソッド読み込み
# -> byte型からstr型に変換
# -> 余分な区切り文字( ' )を削除
base64Img = base64.b64encode(buffer.getvalue()).decode().replace("'", "")
return "data:image/png;base64,"+base64Img
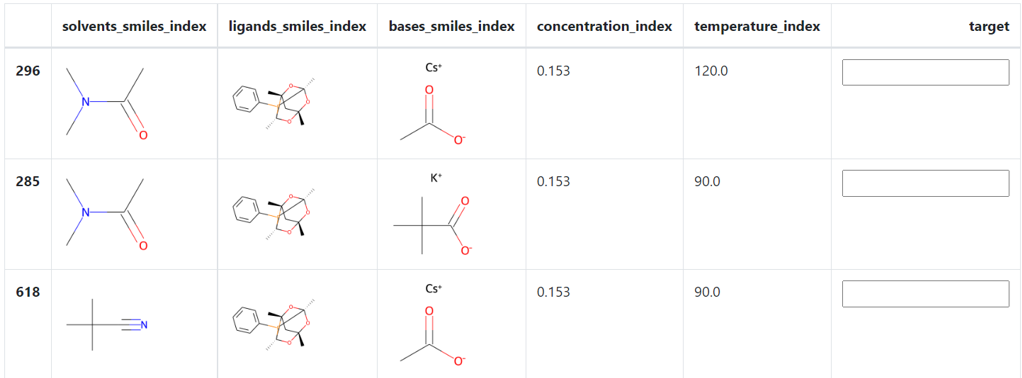
化合物の画像をプルダウンに表示させたい
反応パラメータを選択する上で、化合物をプルダウンで選びたいときがあります。そのためにプルダウン中に化合物の画像を表示させる必要がありましました。上述と似ていますが、プルダウンに画像を表示させるという技術は調べても中々ヒットしませんでした。誠意調査した結果、select2というJavasriptのライブラリを使うことで解決しました。pd.DataFrameに<select>や<option>などのプルダウンタグを入れ込んでテーブル形式のプルダウンを用意し、さらにdata-img_srcという属性にbase64でエンコードした化合物の画像を代入し、htmlに渡します。このとき、classをselect2_classに指定しておきます。このhtmlの<script>にselect2のライブラリをインストールして、関数を定義することで、プルダウンに画像を表示させることができました。
def rtn_form_table(df):
df_next_form= pd.DataFrame(columns = df.columns, index=range(5))
rows = 5
clms = df.shape[1]
for clm in range(clms):
ary = df[~df.iloc[:,clm].isna()].iloc[:,clm]
for row in range(rows):
select_tag = '<select name="{0}" id="id_{0}_{1}" class="select2_class" style="width: 200px">'.format(df.columns[clm], row)
for part in ary:
select_tag += '<option value="{0}" data-img_src={1}">{0}</option>'.format(part, smiles2img(part))
select_tag += '</select>'
df_next_form.iloc[row,clm] = select_tag
return df_next_form
<!-- これをheadに入れる -->
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/select2/4.0.5/css/select2.css" />
<body>
<!-- views.pyで得たrtn_form_tableの返り値を入れ込む -->
</body>
<!-- これをhtmlの最後に入れる -->
<script src="https://cdnjs.cloudflare.com/ajax/libs/jquery/3.3.1/jquery.min.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/select2/4.0.5/js/select2.js"></script>
<script type="text/javascript">
function custom_template(obj){
var data = $(obj.element).data();
var text = $(obj.element).text();
if(data && data['img_src']){
img_src = data['img_src'];
template = $("<div><img src=\"" + img_src + "\" style=\"width:100px;height:100px;\"/><p style=\"font-weight: 700;font-size:14pt;text-align:center;\">" + text + "</p></div>");
return template;
}
}
var options = {
'templateSelection': custom_template,
'templateResult': custom_template,
}
$('.select2_class').select2(options);
$('.select2-container--default .select2-selection--single').css({'height': '220px'});
function run_check(){
var checked = confirm("Are you sure that you run the experiments?");
if (checked==true){
return true;
}else{
return false;
}
}
</script>
<!-- JavaScript Bundle with Popper -->
<script src="https://cdn.jsdelivr.net/npm/bootstrap@5.0.2/dist/js/bootstrap.bundle.min.js" integrity="sha384-MrcW6ZMFYlzcLA8Nl+NtUVF0sA7MsXsP1UyJoMp4YLEuNSfAP+JcXn/tWtIaxVXM" crossorigin="anonymous"></script>

PythonAnywhereでは容量が不足する
ある程度開発ができたので、実際に公開するためにサーバを借りようと思いました。ホームページを作ったことのない私は、なるべく簡単かつPythonならではのサーバを探していました。調査の結果、PythonAnywhere という無料サーバを発見しました。使い方などは他のサイトに任せますが、とりあえず意気揚々とライブラリをインストールしていると、エラーが出ました。
「容量が足りない!!」
フリープランでは容量512MBが最大であり、pytorchだけで1GB強が必要なので、全く容量が足りていませんでした (当たり前ですね)。
月額料金を払うことで利用容量を拡張することができますが、有料で実装したいとは思っていなかったので、「今までの開発は無駄になるのか」と意気消沈していたところ、ふと電子工作で使用していたRaspberry piを思い出しました。Raspberry piでサーバを立ち上げることができると何かの記事で読んだのを思い出したのです。Raspberry piはいくつかのモデルがあり、現時点の最新モデルである4Bの価格は約3万円 (円安と半導体不足が価格が高騰...)で一度購入してしまえばそれ以上のコストは電気代のみです。また、一般的に32GBのメモリーカードを使用するので、ライブラリをダウンロードするには十分であると判断し、早速試しました。
Raspberry piで一部のライブラリがpip installできない
必要なライブラリをRaspberry piにガチャガチャとインストールしていたのですが、pytorchやrdkitがインストールできませんでした。minicondaやpip installなどのインストール形式を試しましたが、いずれもうまくいきませんでした。
色々と調べた結果、Raspberry piにインストールしたOSが32bitであったことが原因でした。pytorchやrdkitをインストールしたいなら64bitにする必要があります。Raspberry piの公式インストールガイドではデフォルトが32bitであり、ここは注意点です。64bitのOSをインストールし直してみると、無事にpytorchやrdkitをインストールすることができました。
Raspberry piでサーバを立ち上げ、アクセスしたい
本来はApacheなどをインストールしてサーバ立ち上げを行うのですが、この辺りまで勉強していたら途方もないので、実装速度を優先してDjangoの開発サーバ (runserver)でアクセスすることにしました。
基本的には、Raspberry piのIPアドレスにアクセスして行くことになるのですが、IPアドレスは電源を落とすと変化してしまいます (変化しない場合もある)。サーバ運用なので常に電源はつけたままですが、やはりIPアドレスが変化するのは厄介です。そこでIPアドレスの固定化を行いました。
IPアドレスの固定化は2種類存在します。GUIで行う方法とコマンドで行う方法です。私のような非プログラマーは分かりやすいGUIで行いがちなのですが、これではうまくいきませんでした。詳細な方法はこちらを参考にしてください。
固定化したRaspberry piのIPアドレスをsetting.pyのALLOWED_HOSTSのリストを入力する。
ALLOWED_HOSTS = ["xxx.xxx.xxx.xxx"] # IP address
アクセスするには、サーバ起動を以下の通りに行い、Raspberry piと同一LANで、ブラウザで http://xxx.xxx.xxx.xxx:8000 にアクセスします。
$ python manage.py runserver xxx.xxx.xxx.xxx:8000
このRaspberry piをサーバとして、Webアプリを公開する方法は様々な場面で役に立つと考えています。pythonを学習したけど、どうやって皆に共有しようか悩んでいる方は是非ご検討ください。
Raspberry piのネットセキュリティを強化したい
社内で実装するにあたって、セキュリティは言及されるポイントです。宇宙開発を行っているNASAですら、Raspberry piが原因で情報漏洩を起こしています (リンク)。ネットセキュリティに疎い私が上長を説得するために考えた対策を以下に示します。
- 初期のアカウントを削除し、新たなアカウントを作成する。
- SSHの使用を禁止する。
- ブラウザでの閲覧を禁止する。
1つ目はサーバ運用にかかわらずRaspberry piを購入したら必ずやるべきことです。Raspberry piは初期アカウントとして、ユーザー名pi、パスワードraspberryが存在し、この情報を知っていれば、外部からRaspberry piに不正アクセスされるリスクがあります。以前まではRaspberry piにOS導入した後に、コマンドを打って初期アカウントを削除して、新規アカウントを作成していましたが、現在ではOS導入するインストーラ (Imager)の段階でアカウントを作成できます。
2つ目は不要かと思いましたが、安全を期するという姿勢を見せるために行いました。SSH自体はiOSやAndroidでも使用される信頼できる通信技術ですが、さらにセキュリティリスクを抑えるという意味でSSHの使用を禁止しました。
3つ目は完全に私の良心次第ですが、ブラウジングを禁止しました。Raspberry piはGoogle Chromeのオープンソースソフトウェア版であるChromiumが搭載されており、ここからネットサーフィンできます。うっかりウイルスに感染しないためにブラウジングを禁止しました。
いざ社内実装へ!
まずは説明資料を用意して上長の説得を試みました。ベイズ最適化とは何なのか、どんな良いことがあるのか、本当に有効なのかを資料を用いて説明しました。有効性に関しては、こちらのサイトからグラフを引っ張り出して、反応最適化をヒトが行った場合と、ベイズ最適化が行った場合で、後者のほうが迅速に最適解に辿り着いているデータを説明しました。「それでも自分が最適化やった方が速い」という意見もありましたが、新しい技術は積極的に取り入れていこうということで、部内での承諾を得ることができました。
次のミッションは総務部にネット接続の許可をもらうことでした。上述のセキュリティ対策を説明したところ、拍子抜けするくらいアッサリとネット接続の許可を得ることができました (念入りに資料準備したことが功を奏したと信じています)。
続いてサーバであるRaspberry piの購入です。購入実績のない商品だったので、基盤を取り扱っていそうな商社に手当たり次第見積もりを依頼しました。その結果、何とかRaspberry pi 4B (ケースや給電ケーブル付き)を入手することができました。
後はRaspberry piをネットに接続し、スクリプトをgithubからダウンロードし、IPアドレスを固定してrunserverすれば、どのPCからも同一LAN内ならアクセスすることができました。Webアプリのリリースメールに使い方の資料を添付し、さらに説明会を開くことでWebアプリの公開を行いました。
反響
実装したばかりでまだ感想は頂いていませんが、何人かの人が興味を持ってアカウント登録してくれています。これからWebアプリでの実績が出てくれば、更に高度な機能を実装したいと考えています。
所感
平日の仕事終わりや休日にしか開発ができなかったことや初めてアプリ開発するということもあって、一つのアプリを作成するのに約1年ほどかかってしまいました。世の中に溢れているアプリやサービスは、多くの人達の努力の積み重ねで成り立っているということを痛感するとともに、本当に高度で複雑な技術が使われていると感じました。また、先人達が共有してくれたブログや記事のおかげで、実現したい機能を達成することができました。私の記事もまた誰かの助けになればと願うばかりです。
今後の予定
日常点検の電子化や電子実験ノートの作成を構想しています。今度はRaspberry piの電子工作の部分を活かして、IDカードをかざすと作業者を認識し、バーコードを読み取ると点検する機器を認識するようなIoTシステムを構築したいです。
最後まで読んでいただき、ありがとうございました。![]()