はじめに
今回、NoSQLの歴史について気になったので調べてみました。
1. 序論:RDBMS神話の崩壊と「3つのV」
長きにわたり、システム設計におけるデータ永続化の正解はただ一つ、「リレーショナルデータベース(RDBMS)」でした。エドガー・F・コッド博士が提唱したこのモデルは、整合性と信頼性を保証する堅牢な城塞として、IT業界に君臨してきました。
しかし、2000年代初頭のWeb 2.0の到来は、その前提を根底から揺るがしました。
爆発的に増加するデータ量(Volume)、凄まじい速度(Velocity)、そして非構造化データの多様性(Variety)。この「3つのV」に対し、単一の巨大なサーバーで稼働することを前提としたRDBMSは、物理的かつ経済的な限界を迎えつつありました。
なぜなのかを紐解いていきましょう。
2. NoSQLの起源:1998年の幻影と2009年の再定義
「NoSQL」という言葉には、実は二つの異なる歴史が存在することをご存知でしょうか。
1998年:Carlo Strozziの「No SQL」
歴史上初めてこの言葉が使われたのは1998年です。イタリアの開発者Carlo Strozziは、自身が開発したデータベースを「NoSQL」と名付けました。しかし、これは「リレーショナルモデルだが、SQL言語を使わずにシェルスクリプトで操作する」というもので、現代のNoSQLとは別物です。当時の意味は文字通り"No SQL"(SQLを使わない)でした。
最初はリレーショナルモデルだったんですね...
Strozzi自身は後に、2009年以降の非リレーショナルデータベース群に対して「NoSQL」という名称が使われている状況に対し、それらはリレーショナルモデル自体を放棄しているため、本来は「NoREL(No Relational)」と呼ぶべきであると指摘しているみたいです。
2009年:NoSQLの再定義
現代に繋がるムーブメントは、2009年にサンフランシスコで開催されたミートアップで爆発しました。Johan Oskarssonが主催したMeetupにおいて、Eric Evans(Rackspace社)が提案した名称、この時の「NoSQL」は、SQLへのアンチテーゼではなく、RDBMSの限界を突破するための分散データベース群を指していました。
参加者とアジェンダ
2009年6月11日に開催されたこのミートアップには、Voldemort, Cassandra, Dynomite, HBase, Hypertable, CouchDB, MongoDBといった、後に市場を席巻することになる主要なプロジェクトの開発者たちが一堂に会した 。彼らに共通していたのは、SQL言語への不満ではなく、「リレーショナルモデルのスケーラビリティの限界」と「スキーマの硬直性」からの解放という強烈な課題意識であった。
- Nosql Definition: meetupとNoSQL定義の記事
- NOSQL 2009: Eric Evansのmeetup参加前の記事
"Not Only SQL"への意味転換
当初はNo SQLという言葉が「反SQL」的なニュアンスで受け取られることもあったが、コミュニティはすぐにこの用語を「Not Only SQL(SQLだけではない)」というバクロニム(後付けの頭字語)として再定義した。これは、SQLデータベースを完全に否定するのではなく、ワークロードに応じてRDBMSとNoSQLを使い分ける「Polyglot Persistence」の思想を反映したものである。
Polyglot Persistenceとは?
日本語では**「多言語永続化」とも訳されますが、もっと直感的に言うと、データベースにおける「適材適所」の思想です。SQLを捨てるのではなく、適材適所でNoSQLも仲間に入れて一緒に使おう。
- Polyglot Persistence: PolyglotPersistenceについての記事
3. なぜNoSQLが必要だったのか:RDBMSが抱えた「構造的限界」
NoSQLの台頭は、単なる技術的な流行ではない。それは、インターネット規模のシステム構築においてRDBMSが直面した物理的・経済的・構造的な限界に対する、必然的な技術的回答であった。
それは単なる「サーバーが高い」という経済的な理由だけではありません。Webスケールの世界において、RDBMSが守り抜こうとした「正義(ACID)」が、システム全体を停止させる「足枷」へと変貌したからです。
3.1. 垂直スケーリング(Scale-Up)の経済的破綻
RDBMSは、その誕生から数十年にわたり、単一の強力なサーバー上で動作することを前提に設計されてきた。パフォーマンス不足に対する主要な解は「垂直スケーリング(Scale-Up)」、すなわちCPU、メモリ、ディスクI/Oの増強であった。
課題1. コストの限界
2000年代中盤、Webトラフィックの指数関数的な増大に対し、単一ノードの性能向上は限界を迎えつつあった。さらに、ハイエンドなサーバー機材の価格は性能に対して線形ではなく指数関数的に跳ね上がるため、GoogleやAmazonのようなハイパースケール事業者にとって、垂直スケーリングは経済合理性を欠く選択肢となっていました。
課題2. コモディティハードウェアへのシフト
コスト効率を追求するためには、安価な汎用サーバー(コモディティハードウェア)を数千台並列に稼働させる「水平スケーリング(Scale-Out)」が不可欠であった。しかし、伝統的なRDBMSは、ACID特性(特に強固な一貫性)を維持するために共有ディスクや集中管理を必要とし、水平分散環境での効率的な動作が極めて困難であった。
なぜ、水平分散環境での効率的な動作が極めて困難であったのかを紐解いていきましょう。
3.2 シャーディング(Sharding)の運用負荷とアンチパターン
RDBMSを無理やり水平スケーリングさせる手法として「シャーディング(水平分割)」が採用された。これは、アプリケーションロジック側でデータを特定のキー(ユーザーIDなど)に基づいて分割し、複数の独立したRDBMSインスタンスに保存する手法である。しかし、これは運用上の悪夢を生み出した。
課題1. アプリケーション層の肥大化
データベース自身が分散を認識していないため、データのルーティング、再配置、障害時のフェイルオーバーといった複雑なロジックをすべてアプリケーションコード内に実装する必要があった。これは、Amazonの「Distributed Computing Manifesto」で批判された「データ構造への密結合」なアーキテクチャそのものであり、開発速度を著しく低下させた。
課題2. RDBMSとしての機能不全(JOINとACIDの喪失)
異なるシャード(物理サーバー)にまたがるテーブルのJOINは、ネットワークレイテンシと複雑性の観点から実質的に禁止された。また、クロスシャード・トランザクション(2フェーズコミット)はパフォーマンスを著しく劣化させるため、結果整合性を受け入れざるを得なくなり、RDBMSを使う意味そのものが問われる事態となった。
- Database Sharding Disadvantages You Should Know: 知っておくべきShardingのデメリット
- Database Sharding: Strategies for Seamless Scaling and Performance Optimization: スケーリングとパフォーマンス最適化戦略の記事
課題3. 運用の硬直性とスケーリングの壁
特定のシャードだけ容量が溢れた場合(データホットスポット)、データを再配分するにはシステムを停止し、手動でデータを移行する必要があった。
「データが移動している最中に、新しい書き込みが来たらどうするの?」という問題(整合性の維持)が、物理的に解決困難だったからです。
詳しいロジックは、後ほど解説します。
3.3 インピーダンス・ミスマッチと開発アジリティの欠如
Web 2.0時代のアジャイル開発において、RDBMSの厳格なスキーマは開発スピードの足かせとなった。
課題1. オブジェクト-リレーショナル・インピーダンス・ミスマッチ
アプリケーションコード(Java, Pythonなど)はオブジェクト指向で、データをリストやネストされた構造(グラフやツリー)として扱う。一方、RDBMSはデータを平坦な行と列に分解して正規化する。この変換(O/Rマッピング)は、パフォーマンスのオーバーヘッドを生むだけでなく、開発者の認知負荷を高めた。
- インピーダンスミスマッチのWikipedia記事
- Object-Relational Mapping is the Vietnam of Computer Science: ORMの使用が、逃げ場のない泥沼化になることを提言している記事
- The Cultural Impedance Mismatch Between Data Professionals and Developers: 開発者とデータ専門家の「文化的インピーダンスミスマッチ」があることを提言している記事
課題2. スキーマ変更のコスト
稼働中の大規模なRDBMSに対して ALTER TABLE を実行してカラムを追加することは、数時間のロックやダウンタイムを意味した。頻繁な機能追加が求められるWebサービスにおいて、データベースのスキーマ変更はリリースのボトルネックとなり、柔軟なデータ構造(Schema-less または Schema-on-Read)への渇望が高まっていた。
4. パラダイムシフトの理論的支柱:CAP定理とBASE特性
NoSQLへの移行は、単なるツールの変更ではなく、分散システムにおける「整合性」に対する哲学的な転換であった。この転換を理論的に正当化したのが、Eric Brewerの「CAP定理」である。
4.1. CAP定理:分散システムのトリレンマ
2000年にEric Brewerが提唱したCAP定理は、分散データストアにおいて以下の3つの特性を同時にすべて満たすことは不可能であると定義した 。
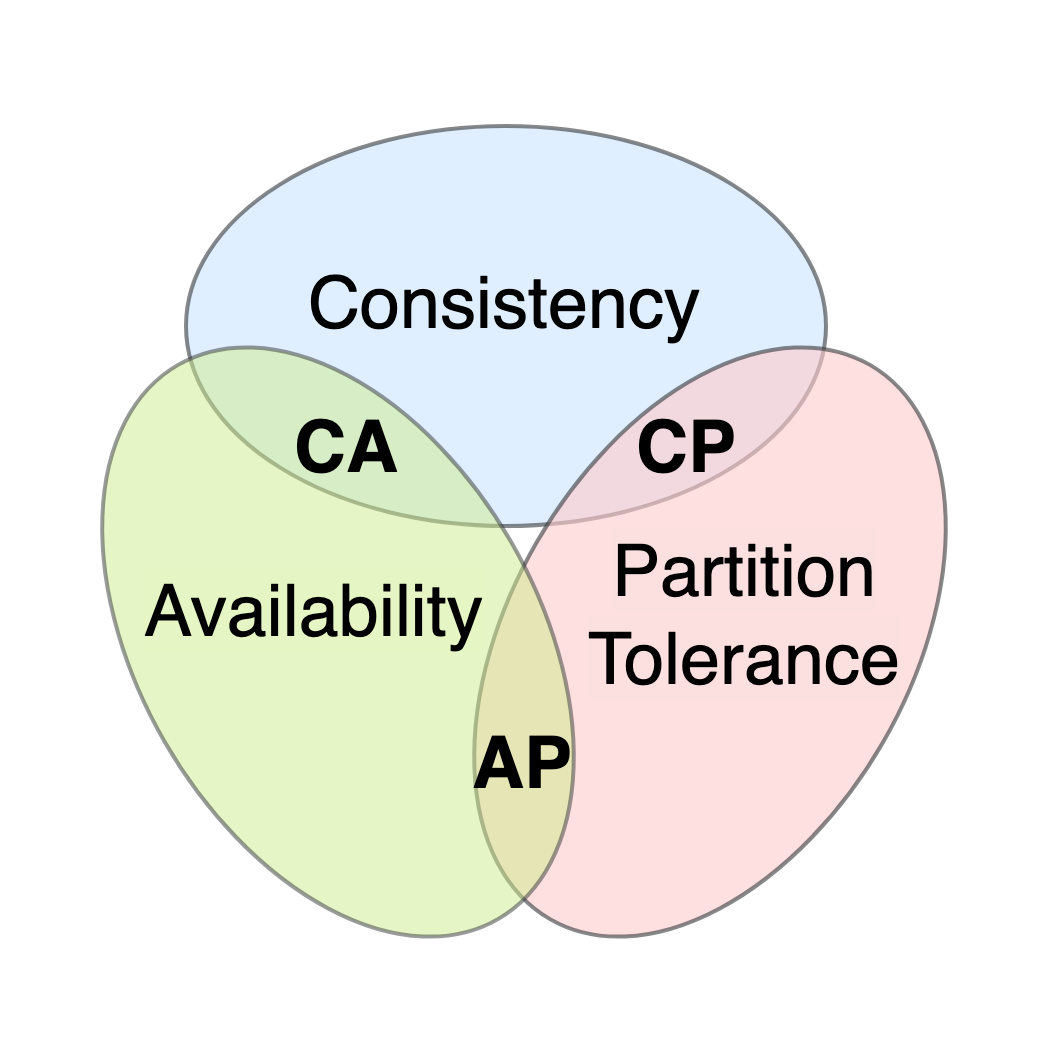
出典: CAP Theorem Euler Diagram by JamieMcCarthy, licensed under CC BY-SA 4.0
| 特性 | 定義 |
|---|---|
| Consistency (一貫性) | すべてのクライアントが同時に同じデータを見る(常に最新の書き込みを読む)。 |
| Availability (可用性) | 生きているすべてのノードが、エラーにならずに常に応答を返す(最新である保証はない)。 |
| Partition Tolerance (分断耐性) | ネットワーク障害によりノード間の通信が分断されても、システムが稼働し続ける。 |
AWSのようなグローバルな分散環境において、ネットワーク分断(P)は物理的に避けられない事象である。したがって、システム設計者は、分断発生時に「一貫性を維持するために可用性を犠牲にする(CPシステム。当時のRDBMS)」か、「可用性を維持するために一貫性を一時的に犠牲にする(APシステム。当時のNoSQL)」かの二者択一を迫られることとなる。
現在は、完全なトレードオフではなく、スペクトラム(連続体)として捉える考え方が主流です。
Eric Brewer博士自身が2012年に「CAP Twelve Years Later: How the "Rules" Have Changed」という記事で、「2つしか選べないというのは誤解を生む単純化だ(CPかAPかの0/1ではない)」と補足しています。
4.2. ACIDからBASEへの移行
伝統的なRDBMSは、ACID(Atomicity, Consistency, Isolation, Durability)特性を絶対視し、可用性を犠牲にしてでも一貫性を守る(CP型)設計であった。これに対し、初期のNoSQLデータベース(特にAmazon Dynamo系)は、BASE特性を受け入れることで、極限の可用性とスケーラビリティ(AP型)を実現した 。
- Basically Available (基本的に利用可能): 障害が発生しても、システムの一部は常に応答し続ける。
- Soft state (ソフト状態): システムの状態は、外部からの入力がなくても、ノード間のデータ同期などによって時間とともに変化しうる。
- Eventual Consistency (結果整合性): 即時の整合性は保証されないが、十分な時間が経過すれば、すべての更新が伝播し、最終的には全てのデータが整合した状態になる。
5. ビッグバンの着火点:AmazonとGoogleの決断
NoSQLムーブメントの実質的な起源は、オープンソースコミュニティではなく、AmazonとGoogleという巨大企業が自社の生存をかけて開発した内部システムにある。彼らが直面した課題と、その解決策として発表された論文が、世界中のエンジニアに衝撃を与えた。
5.1. Amazonの2004年のホリデーシーズンの障害
Amazonにとっての転換点は、2004年のホリデーショッピングシーズンのピーク時に発生した数々の障害であった。当時のAmazonのアーキテクチャは、Webサーバー群が中央の巨大なRDBMSクラスターに直接接続するモノリシックな構造であった。
- DynamoDBの歴史 Wikipedia
- Amazon DynamoDB – a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications: Werner VogelsによるDynamoDBの歴史記事
5.2. Google Bigtable論文 (2006)
2006年、Googleは「Bigtable: A Distributed Storage System for Structured Data」を発表した。
・ アーキテクチャ
数千台のコモディティサーバー上に、ペタバイト級の構造化データを保存する分散ストレージシステム。行キー、列キー、タイムスタンプによる多次元マップとしてデータを管理する「ワイドカラムストア」モデルを採用。
・ 影響
この論文は、後にHadoopエコシステムの中心となるApache HBaseや、Facebookが開発したCassandraのデータモデルに直接的な設計図を提供した。
Google Cloud: Google Cloud20周年記事
5.3. Amazon Dynamo論文 (2007)
2007年、Amazonは「Dynamo: Amazon’s Highly Available Key-Value Store」を発表した。これはNoSQLの歴史における記念碑的な論文である。
・ 目的
ショッピングカートのような、書き込みを決して拒否してはならない(高可用性・高書込性能)ワークロードのために設計された。
・ 技術的ブレイクスルー
-
コンシステント・ハッシング (Consistent Hashing):
- ノードの追加・削除時に発生するデータ移動を最小限に抑え、ハッシュテーブルの再構築を防ぐ分散手法。これにより、ダウンタイムなしでのリニアなスケーリングが可能になった。
-
ゴシッププロトコル (Gossip Protocol):
- 中央管理サーバーを置かず、ノード同士が噂話のように状態を交換し合うことでクラスタのメンバーシップを管理する自律的な仕組み。
-
ベクタークロック (Vector Clocks):
- 結果整合性環境において、複数のノードで同時に発生した更新の競合(コンフリクト)を検知し、因果関係を追跡するためのバージョン管理手法。
・ 影響
Dynamoの設計思想は、Riak, Voldemort, Apache Cassandra(分散モデル部分)といった主要なNoSQLプロダクトの基礎となった。
6. NoSQLのカンブリア爆発:主要なデータモデルと代表的プロダクト
2009年以降、特定の課題に特化したデータベースが次々と登場しました。
| カテゴリ | データモデル | 特徴とユースケース | 代表的プロダクト(起源) |
|---|---|---|---|
| Key-Value Store (KVS) | キーと値の単純なペア | 最もシンプルで高速。セッション管理、キャッシュ、カート情報などに最適。複雑なクエリは苦手。 |
Redis (2009) Riak (2009) Memcached (2003) |
| Document Store | JSON/XMLドキュメント | スキーマレスで柔軟。Webアプリのバックエンド、コンテンツ管理、カタログデータなどに適する。開発者フレンドリー。 |
MongoDB (2009) Apache CouchDB (2005) |
| Wide-Column Store | 列族(Column Family) | 大量の列を持つ巨大なテーブル。書き込み性能が高く、時系列データやログ解析、IoTデータに適する。Hadoopとの親和性が高い。 |
Apache HBase (2008) Apache Cassandra (2008) |
| Graph Database | ノードとエッジ(関係) | データ間の「関係性」を第一級市民として扱う。ソーシャルネットワーク、推奨エンジン、不正検知などに不可欠。 | Neo4j (2010) |
7. Amazon DynamoDBの誕生 (2012)
AWSは、Amazon.comが経験したスケーラビリティの課題と、そこから生まれたDynamo論文の知見を、一般の開発者が利用可能な「サービス」として提供することで、クラウドデータベースの市場を切り拓いた。
2012年1月、Amazon CTOのWerner Vogelsは、フルマネージドNoSQLデータベースサービス「Amazon DynamoDB」を発表した。これは、Amazon内部で使用されていたDynamoの原理をベースにしつつ、クラウドサービスとして使いやすく再設計されたものである。
7.1. 「Undifferentiated Heavy Lifting(差別化につながらない重労働)」の排除
従来のNoSQL(CassandraやHBase)は、セットアップ、クラスタ管理、パッチ適用、スケーリングといった運用作業が極めて重荷であった。DynamoDBはこれらをAWSが肩代わりする「サーバーレス」なモデルを提示した。開発者はスループット(Read/Write Capacity Units)を指定するだけで、後はAWSが自動的にパーティション分割とサーバー配置を行う。
7.2. 一貫したパフォーマンス
DynamoDBは、データ量が数ギガバイトであっても数ペタバイトであっても、一桁ミリ秒のレイテンシで応答するように設計されている。これは、ハッシュキーに基づく予測可能なアクセスパターンを強制することで実現されている。
7.3. 進化の継続
ローンチ当初はシンプルなKVSであったが、その後、グローバルセカンダリインデックス(GSI)、ACIDトランザクションのサポート、オンデマンドキャパシティモード、グローバルテーブル(マルチリージョンレプリケーション)などの機能が追加され、エンタープライズの基幹システムにも耐えうるプラットフォームへと進化した。
- Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service: 2022年にUSENIX(システム工学の国際会議)で発表された、現在のAmazon DynamoDBの内部アーキテクチャを解説した論文
-
Lessons learned from 10 years of DynamoDB: AWSがDynamoDB 10年間で学んだ教訓を書いている記事。
6.3. 進化の継続のロジックが気になる方は目を通してみてください! - Amazon DynamoDB Transactionsの仕組み
8. 現代のパラダイム:Polyglot Persistence
現在のクラウドネイティブ開発において、モノリシックな巨大RDBMSですべてをまかなう時代は終わりました。マイクロサービスアーキテクチャの普及に伴い、サービスごとに最適なDBを選ぶ**Polyglot Persistence(ポリグロット・パーシステンス)**が標準となっています。
AWSにおける選定マトリクス(例)
| ワークロードの特性 | 推奨されるAWSサービス | NoSQL/DBタイプ |
|---|---|---|
| リフト&シフト、複雑なJOIN、ACID必須 | Amazon Aurora / RDS | Relational |
| 超高速アクセス、スキーマレス、高スケーラビリティ | Amazon DynamoDB | Key-Value |
| ミリ秒未満のレイテンシ、キャッシュ、ランキング | Amazon ElastiCache / MemoryDB | In-Memory |
| JSONデータの柔軟なクエリ、MongoDB互換 | Amazon DocumentDB | Document |
| 関係性の探索(SNS、不正検知) | Amazon Neptune | Graph |
| 時系列データ(IoT、テレメトリ) | Amazon Timestream | Time Series |
| 台帳管理、変更履歴の完全な追跡 | Amazon QLDB | Ledger |
| ビッグデータ分析、Hadoop互換 | Amazon EMR (HBase) | Wide-Column |
9. 結論:歴史から学ぶアーキテクトの姿勢
NoSQLの歴史は、「SQL vs NoSQL」という対立の歴史ではありません。それは、物理的な限界に対し、「整合性を緩めてでも、可用性と拡張性を取る」というエンジニアたちの決断の歴史です。
現在では、Amazon Auroraのようにストレージ層を分散化させてスケーラビリティを獲得したRDBMSもあれば、トランザクション機能を実装したDynamoDBもあり、両者の境界は融合しつつあります。
我々アーキテクトに求められるのは、特定の技術への信仰ではなく、「解決したい課題(ワークロード)に対し、最適な道具(データベース)を科学的に選ぶ」という姿勢です。それこそが、Amazonの障害と挑戦の歴史から我々が学ぶべき最大の教訓なのです。
- A decade of database innovation: The Amazon Aurora story: Auroraのストーリーの記事
それぞれの詳しいロジックにつきましては、別の記事で投稿します。