はじめに
2025年はSora 2, Runway Gen-4やVeo 3など動画像生成AIも飛躍的な進歩をとげることになりました。物理法則の再現や長尺の動画生成など、従来の動画生成技術では難しかった点が大幅に改善されており、もはや世界のシミュレーターのようなところまできています。
一方、ローカル・オープンソースでも大きな進展が見られ、春頃から登場したFramePackは特徴的な圧縮手法やサンプリング手法により、従来よりも安価なリソースで高品質な動画を生成することができるようになりました。
個人的には動画生成AIをそこまで検証できていなかったため、今回は改めてこちらで少し検証と分析をしたいと思います。本記事では、FramePackで生成した動画の時間的品質を、定量的に評価してみます。またAttention Mapの可視化を試みた結果もお伝えします。
FramePackの手法の特徴
論文の情報をベースにすでに様々な記事で解説されているため、ここでは詳細は割愛しますが、
- Frame Context Packing:生成時点との時間的関係を考慮したフレームの圧縮手法
- Inverted Anti-drifting Sampling:すべての推論において常に最初のフレームを近似対象として扱うサンプリングの手法
の2点が非常に実用的な動画生成を可能にしています。
検証した項目
| 評価指標 | 分析手法 | 目的 |
|---|---|---|
| フリッカー | 輝度変化検出 | ちらつきの検出 |
| 周波数特性 | FFT分析 | フリッカーの周期性 |
| 構造的類似度 | SSIM時系列 | フレーム間の品質推移 |
今回は動きの自然さやプロンプトとの整合性などは定量的には見ていないため、その点はご容赦ください。
検証動画
- 入力画像: 荒野で乗馬する人物の画像

- 設定: TeaCache無し, steps 20, vGPU Inference Preserved Memory 6GB
- 動画A: 5秒(151フレーム)
- 動画B: 30秒(901フレーム)
動画AのGIF

環境
PyTorch: 2.4
CUDA: 12.4
1. フリッカー分析
フリッカーとは
動画生成AIにおいて「フリッカー」とは、フレーム間で輝度や色が急激に変化し、ちらつきとして知覚される現象です。品質の低い動画生成モデルでは顕著に現れます。
検出手法
フレーム間の平均輝度差を計算し、閾値を超えた変化を検出しました。
def detect_flicker(video_path, severe_threshold=15, mild_threshold=8):
"""フリッカー検出"""
cap = cv2.VideoCapture(video_path)
prev_brightness = None
flickers = []
frame_idx = 0
while True:
ret, frame = cap.read()
if not ret:
break
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
brightness = np.mean(gray)
if prev_brightness is not None:
diff = abs(brightness - prev_brightness)
if diff > severe_threshold:
flickers.append(('severe', frame_idx, diff))
elif diff > mild_threshold:
flickers.append(('mild', frame_idx, diff))
prev_brightness = brightness
frame_idx += 1
cap.release()
return flickers
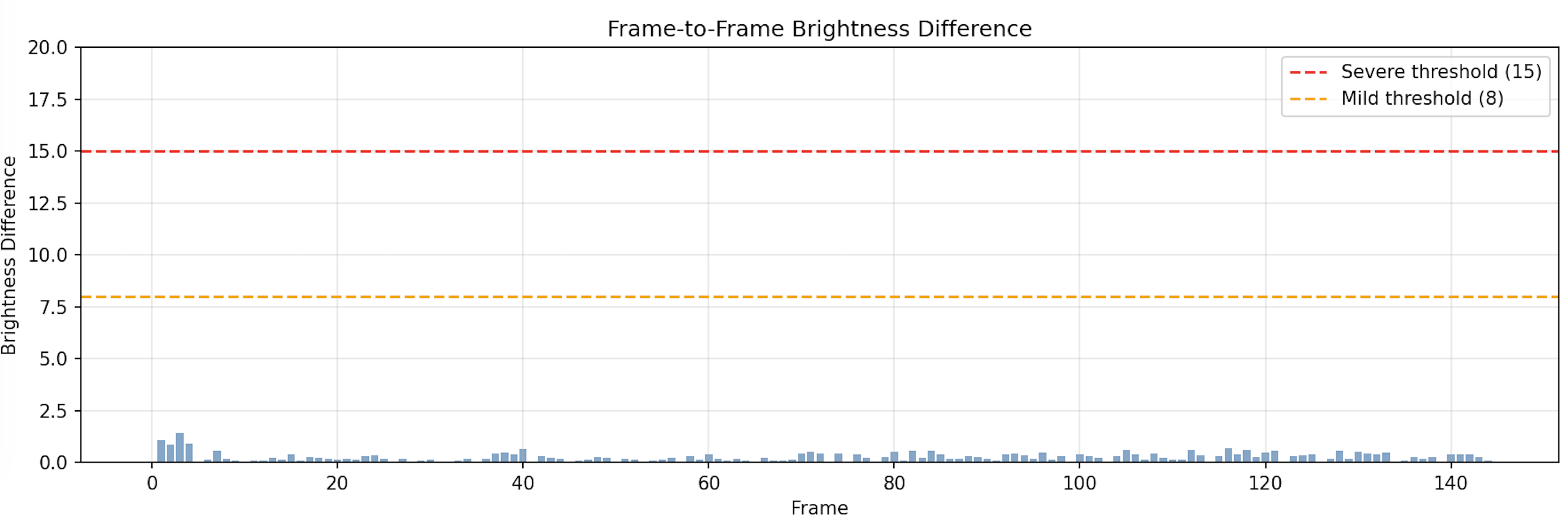
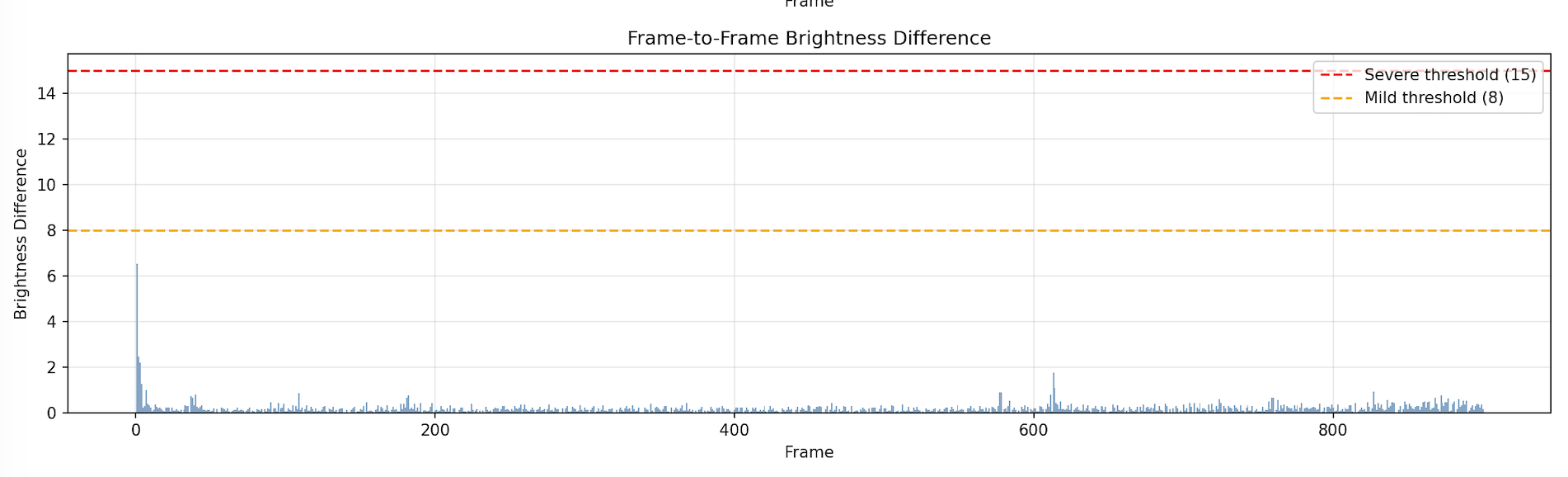
結果
| 動画 | 長さ | 重度フリッカー | 軽度フリッカー | 最大輝度変化 |
|---|---|---|---|---|
| 5秒版 | 145フレーム | 0 (0.0%) | 0 (0.0%) | 1.42 |
| 30秒版 | 901フレーム | 0 (0.0%) | 0 (0.0%) | 6.53 |
5秒版
30秒版
分析
長尺になってもフリッカーが発生せず、この観点では安定した品質の動画でした。
- 両動画とも最初の数フレームで輝度が急落
- 30秒版では輝度が前半で低く、後半で回復
最初の数フレームの影響はサンプリングが1つの理由と考えられますが、
この点を滑らかにするのは課題としてあるかもしれません。
2. 周波数分析(FFT)
目的
FramePackはlatent_window_size=9(推奨値)で固定ウィンドウ処理を行います。
手法
輝度時系列データにFFTを適用し、周期的なパターンを検出しました。
from scipy.fft import fft, fftfreq
from scipy.signal import find_peaks
def frequency_analysis(brightness_series):
"""FFTによる周波数分析"""
# トレンド除去
detrended = brightness_series - np.mean(brightness_series)
# FFT実行
fft_result = fft(detrended)
freqs = fftfreq(len(detrended))
power = np.abs(fft_result) ** 2
# ピーク検出
peaks, _ = find_peaks(power[:len(power)//2], height=np.max(power)*0.1)
return freqs, power, peaks
結果
| 動画 | 最強ピーク | 9フレーム周期 |
|---|---|---|
| 5秒版 | 12フレーム | 検出なし |
| 30秒版 | 450フレーム | 検出なし |
5秒版

30秒版
 !
!
結論
特に周期性などは感じさせずFramePackのウィンドウ処理は滑らかに実装されていました。
3. SSIM時系列分析
SSIMとは
SSIM(Structural Similarity Index)は、2つの画像の構造的類似度を0〜1で表す指標です。連続フレーム間のSSIMを追跡することで、品質の推移を可視化してみます。
結果
| 動画 | 平均SSIM | トレンド | 前半平均 | 後半平均 |
|---|---|---|---|---|
| 5秒版 | 0.8571 | degrading | 0.9010 | 0.8133 |
| 30秒版 | 0.9687 | degrading | 0.9909 | 0.9465 |
SSIMの時間変化

SSIMの分布
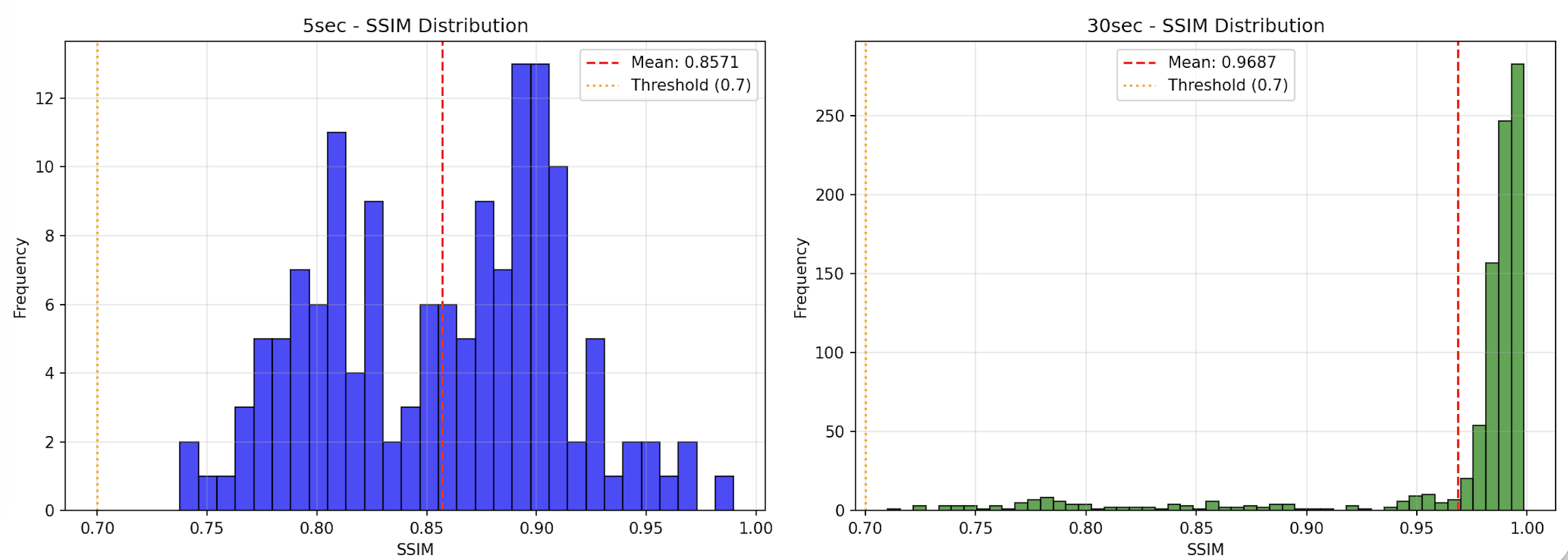
考察
グラフから後半のほうが動きについて大きいことがわかります(後半になると品質が劣化していると言うことではありません)
また定性的な評価にはなりますが、実際に動画の総時間を長くすると、
最初のフレームで歩く動きや背景の動きが小さくなり、最初のフレームとあまり変わらなくなってしまいました。プロンプトで動きがつくようにしたり、パラメータの調整などではそこまで改善されませんでした。
GitHub Issuesでもこの辺は議論になっていますが、最初のフレームは原画との差をうまないために制約が大きいのかもしれません。
4. Attention Mapで関心事をみてみる
動画自体の直接的な品質では無いのですが、内部で使われている
Diffusion Transformersの動画生成時における関心事を確認したいと思います。

FramePackのバックボーンアーキテクチャ
(※)https://learnopencv.com/framepack-video-diffusion/
から引用
Attention Mapの結果
single_streamの最初のblockと最後のblockのAttention Mapを見てみました。
QとKから再計算しています。
Attention Map
可視化ではkey 250までを表示
- block_0
Attention Scores(左): 規則的なグリッドパターン。Query位置 70, 130, 200 付近に暗い横線
Attention Weights(右): 右端(Key 250付近)に縦線 → 特定Keyに集中

- block_20
Attention Scores: グリッドパターン維持、Score最大約47
Attention Weights: 複数の縦線(Key 40, 110, 180付近) → Attentionが分散

- block_39
Attention Scores: 明確な縦の赤いバンド(Key 0-10, 70, 140, 210付近)
Attention Weights: 右端(Key 200付近)に強い黄色縦線

| Block | Top Key | Attention値 | Entropy |
|---|---|---|---|
| Block 0 | 12525 | 3741 | 4.02 |
| Block 20 | 101 | 1566 | 5.11 |
| Block 39 | 12525 | 4103 | 2.78 |
各々注目しているKeyが存在していました。
FramePackはHunyuanVideoベースにしており、Video tokens + Text tokensで構成されているようです。
Keyとしては末尾のkeyにAttentionが寄っていますが、
これはテキストの末尾のトークンだと思われます。
Single StreamにおけるVideo間のAttentionをもう少し強くなどすれば
もしかしたら動きに違いが出るのかもしれません(要検証になります)。
(参考)レイヤーごとの Top Key 一覧
クリックして展開
| Block | Top Key | Attention値 | Entropy |
|---|---|---|---|
| 0 | 12525 | 3741 | 4.02 |
| 1 | 12525 | 2355 | 4.51 |
| 2 | 12525 | 5114 | 4.40 |
| 3 | 12525 | 3949 | 5.20 |
| 4 | 12525 | 3796 | 5.10 |
| ・・・略・・・ | |||
| 12 | 12525 | 4395 | 4.95 |
| 13 | 12525 | 1829 | 4.45 |
| 14 | 173 | 2582 | 3.68 |
| 15 | 165 | 1905 | 4.68 |
| 16 | 101 | 1511 | 4.77 |
| 17 | 165 | 1836 | 4.14 |
| 18 | 12525 | 684 | 6.38 |
| 19 | 12525 | 1146 | 7.23 |
| 20 | 101 | 1566 | 5.11 |
| 21 | 12525 | 671 | 6.64 |
| ・・・略・・・ | |||
| 36 | 12525 | 4173 | 3.59 |
| 37 | 12525 | 5681 | 3.25 |
| 38 | 12525 | 1962 | 3.25 |
| 39 | 12525 | 4103 | 2.78 |
まとめ
FramePackの品質特性
フリッカーやFFT分析などからは非常に安定しており、
非常にリーズナブルなリソースでも高品質な動画を作成していることが今回の結果からもわかりました。
定性的に見ると歩き方がおかしく見えたり、また複雑な動きについては課題があるように見えました。
SSIMでは(特に長尺の場合)逆に最初のフレームに近づくほど動きがつかなくなる問題は課題であることがわかりました。
最後にSingle StreamのAttention Mapを簡単に見ましたが、テキストへのアテンションが思ったより大きいことが意外でした。
参考文献
- FramePack GitHub
- Frame Context Packing and Drift Prevention in Next-Frame-Prediction Video Diffusion Models
- TeaCache: Timestep-Aware Caching
おわりに
今回ローカルかつオープンな動画生成AIであるFramePackを動画の品質や内部の関心について、簡易的な検証をしました。FramePack自体にもまだ課題があり、その内部的なアーキテクチャや手法の改善方法についても考え、今後の動画生成技術もキャッチアップしたいと思います!