初めに
こちらのチュートリアルを参考に Kinesis Data Streams でストリームを作成し、Lambda と関連付けてみました。ただしこちらのチュートリアルは CLI を用いていましたが、この記事ではコンソールでの操作を書いています。
また、
EC2 → Kinesis Data Streams → Lambda → DynamoDB
という流れで Kinesis Data Streams に登録したレコードを DynamoDB に登録してみました。
チュートリアル
頻出用語はドキュメントを参考にまとめました。
| 用語 | 説明 |
|---|---|
| シャード | Amazon Kinesis データストリームの基本的なスループットの単位 |
| レコード | Amazon Kinesis データストリームに保存されるデータの単位。 シーケンス番号、パーティションキー、データ BLOB で構成されている。 |
| パーティションキー | ストリーム内のデータをシャード単位でグループ化するために使用される |
| データ BLOB | データ BLOB はデータプロデューサーがデータストリームに追加する、処理対象のデータ。最大サイズは、1 MB 。 |
| シーケンス番号 | 各レコードの一意の識別子。 |
1. ストリームを作成する
ストリームを作成します。

2. Lambda 関数を作成する
以下のサンプルコードを使用します。
import base64
def lambda_handler(event, context):
for record in event['Records']:
#Kinesis data is base64 encoded so decode here
payload = base64.b64decode(record["kinesis"]["data"])
print(payload.decode('utf-8'))
3. トリガーを設定する
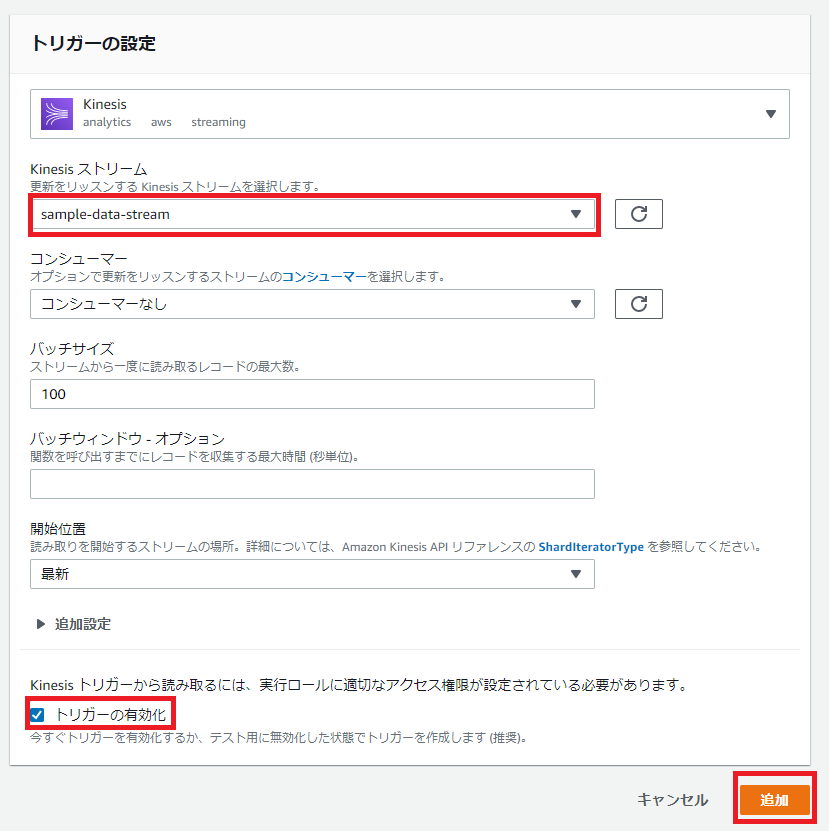
「トリガーを追加」をクリックします。

Kinesis を選択し、「Kinesis ストリーム」では作成したストリームを選択します。
それ以外はデフォルトの設定です。「トリガーの有効化」にチェックが入っていることを確認します。その後「追加」をクリックします。
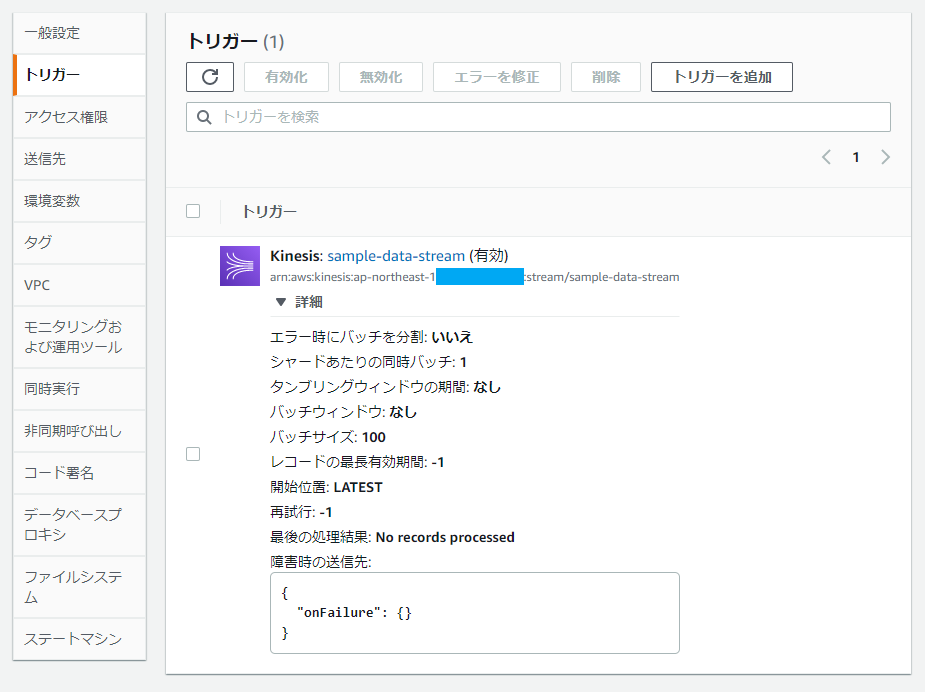
トリガー作成後、ステータスが有効になっていることを確認します。
4. レコードを登録する
aws kinesis put-record コマンドでレコードを登録します。
[ec2-user@ip-172-31-40-232 ~]$ aws kinesis put-record \
--stream-name sample-data-stream \
--partition-key 1 --data "sample 001"
{
"ShardId": "shardId-000000000000",
"SequenceNumber": "49618511843586135779402357080423908193282568717632274434"
}
5. Lambda 関数が呼び出されたかを確認する
Lambda のコンソール画面から以下の最新のログを選択します。
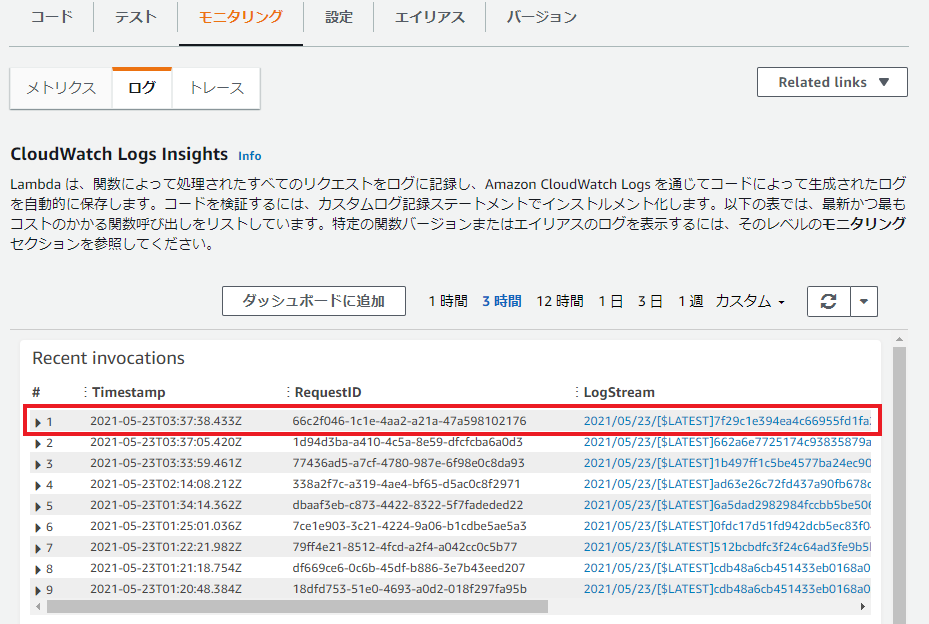
--data に渡した値が出力されていることを確認します。

EC2 → Kinesis Data Stream → Lambda → DynamoDB の手順
DynamoDBに登録するサンプルデータです。
テーブル名:Products
{
"Price": "800",
"ProductName": "carpet"
}
AWS SDK for Python でレコードを登録する
まず Lambda 関数を編集します。
import base64
import boto3
def lambda_handler(event, context):
data = {}
keys = ['table', 'product', 'price']
for i, record in enumerate(event['Records']):
payload = base64.b64decode(record["kinesis"]["data"])
data[keys[i]] = payload.decode('utf-8')
print('data: {}'.format(data))
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table(data['table'])
item = {
'ProductName': data['product'],
'Price': data['price']
}
response = table.put_item(Item=item)
print(response)
次にEC2 で以下のファイルを実行します。
put_records.py
import boto3
import sys
client = boto3.client('kinesis')
def put_records(stream_name, table, product, price):
response = client.put_records(
Records=[
{
'Data': table,
'PartitionKey': '1'
},
{
'Data': product,
'PartitionKey': '2'
},
{
'Data': price,
'PartitionKey': '3'
}
],
StreamName=stream_name
)
print(response)
if __name__ == '__main__':
args = sys.argv
put_records(args[1], args[2], args[3], args[4])
実行例
$ python3 put_records.py sample-data-stream Products carpet 800
出力(整形済み)
{
'FailedRecordCount': 0,
'Records': [{
'SequenceNumber': '49618511843586135779402357080457758116232117052824879106',
'ShardId': 'shardId-000000000000'
}, {
'SequenceNumber': '49618511843586135779402357080458967042051731681999585282',
'ShardId': 'shardId-000000000000'
}, {
'SequenceNumber': '49618511843586135779402357080460175967871346311174291458',
'ShardId': 'shardId-000000000000'
}],
'ResponseMetadata': {
'RequestId': 'abcd999-abcd-a999-a999-abcdefg123456',
'HTTPStatusCode': 200,
'HTTPHeaders': {
'x-amzn-requestid': 'abcd999-abcd-a999-a999-abcdefg123456',
'x-amz-id-2': 'abcdEFG123456',
'date': 'Sun, 23 May 2021 04:56:06 GMT',
'content-type': 'application/x-amz-json-1.1',
'content-length': '368'
},
'RetryAttempts': 0
}
}
AWS SDK for Python でレコードを取得する
この手順では必要ありませんが、レコードを取得するメソッドについて記載しておきます。
get_records.py
import boto3
import sys
client = boto3.client('kinesis')
def get_shard_iter(stream_name, shard_id, iter_type):
response = client.get_shard_iterator(
StreamName=stream_name,
ShardId=shard_id,
ShardIteratorType=iter_type
)
return response['ShardIterator']
def get_records(shard_iter):
response = client.get_records(
ShardIterator=shard_iter
)
for record in response['Records']:
print(record)
if __name__ == '__main__':
args = sys.argv
shard_iter = get_shard_iter(args[1], args[2], args[3])
get_records(shard_iter)
実行例
$ python3 get_records.py sample-data-stream shardId-000000000000 TRIM_HORIZON
出力
{'SequenceNumber': '49618511843586135779402357080457758116232117052824879106', 'ApproximateArrivalTimestamp': datetime.datetime(2021, 5, 23, 4, 56, 6, 52000, tzinfo=tzlocal()), 'Data': b'Products', 'PartitionKey': '1'}
{'SequenceNumber': '49618511843586135779402357080458967042051731681999585282', 'ApproximateArrivalTimestamp': datetime.datetime(2021, 5, 23, 4, 56, 6, 55000, tzinfo=tzlocal()), 'Data': b'carpet', 'PartitionKey': '2'}
{'SequenceNumber': '49618511843586135779402357080460175967871346311174291458', 'ApproximateArrivalTimestamp': datetime.datetime(2021, 5, 23, 4, 56, 6, 55000, tzinfo=tzlocal()), 'Data': b'800', 'PartitionKey': '3'}
参考記事