機械学習を勉強してから画像がハムケツか否かを識別するプログラム作成を試みたのですがなかなか上手くいきませんでした。
Tensorflowを使えばプログラミングレスでいい感じにできそうだったので、Tensorflowに入門(というか体験)してみました。
この記事ではTensorflowの画像分類チュートリアルに実際に取り組んだ内容を中心に紹介します。
How to Retrain an Image Classifier for New Categories
最後にこのプログラムを使ってハムケツ判定を行います。が、チュートリアルの学習画像を差し替えるだけです。
環境
- Python3.6.1(Anaconda 4.3.21)
- Tensorflow1.8
- Windows10
Tensorflowチュートリアル
公式チュートリアルは花の分類学習を行います。
環境づくり
AnacondaでTensorflow用のPython環境を作り、tensorflow、tensorflow-hubをインストールします。
$ conda create -n tensorflow python=3.6.1
$ activate tensorflow
(tensorflow)$ pip install tensorflow
(tensorflow)$ pip install tensorflow-hub
学習データ取得
以下のファイルをダウンロードして適当なディレクトリに解凍します。
カテゴリ分けされた花の画像が格納されています。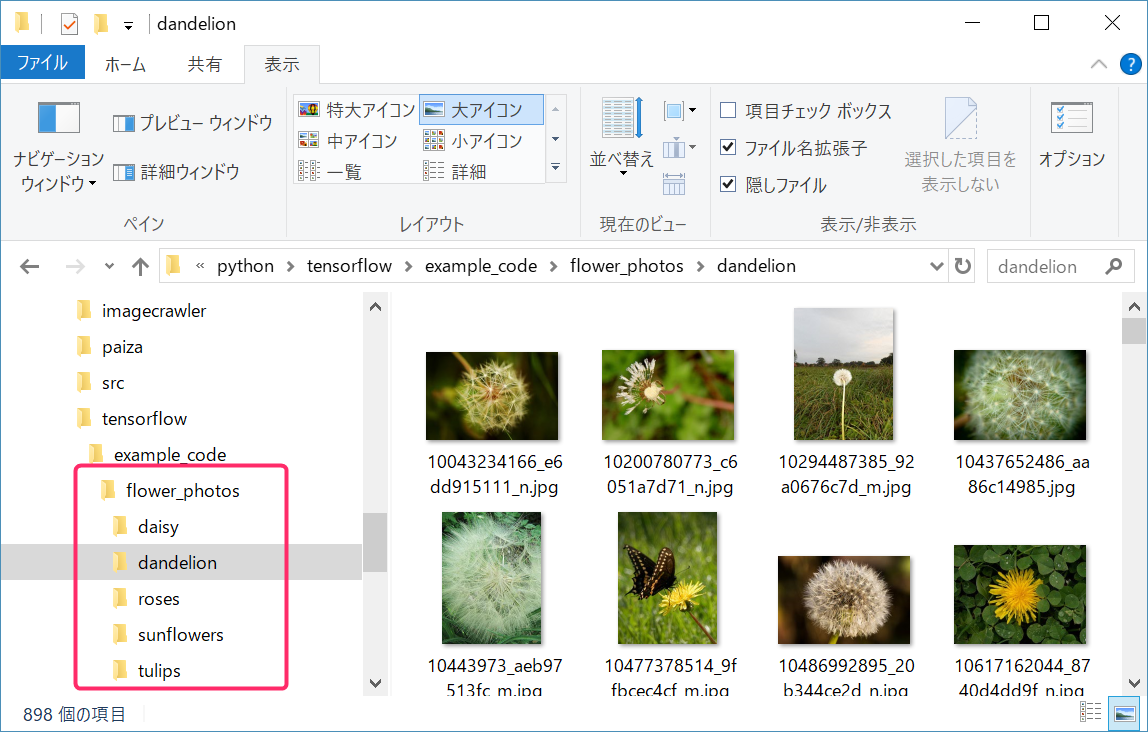
ソースコード取得
githubに公開されているretain.pyをダウンロードします。
実行
あとはプログラムを実行するだけです。--image_dirには先ほど解凍した学習データが格納されているフォルダを指定します。
(tensorflow)$ python retrain.py --image_dir ~/flower_photos
ここからボトルネック(画像の特徴点のようなもの?)の作成と、4,000ステップの学習が始まります。私の環境では終わるまでおおよそ1時間ほどかかりました。
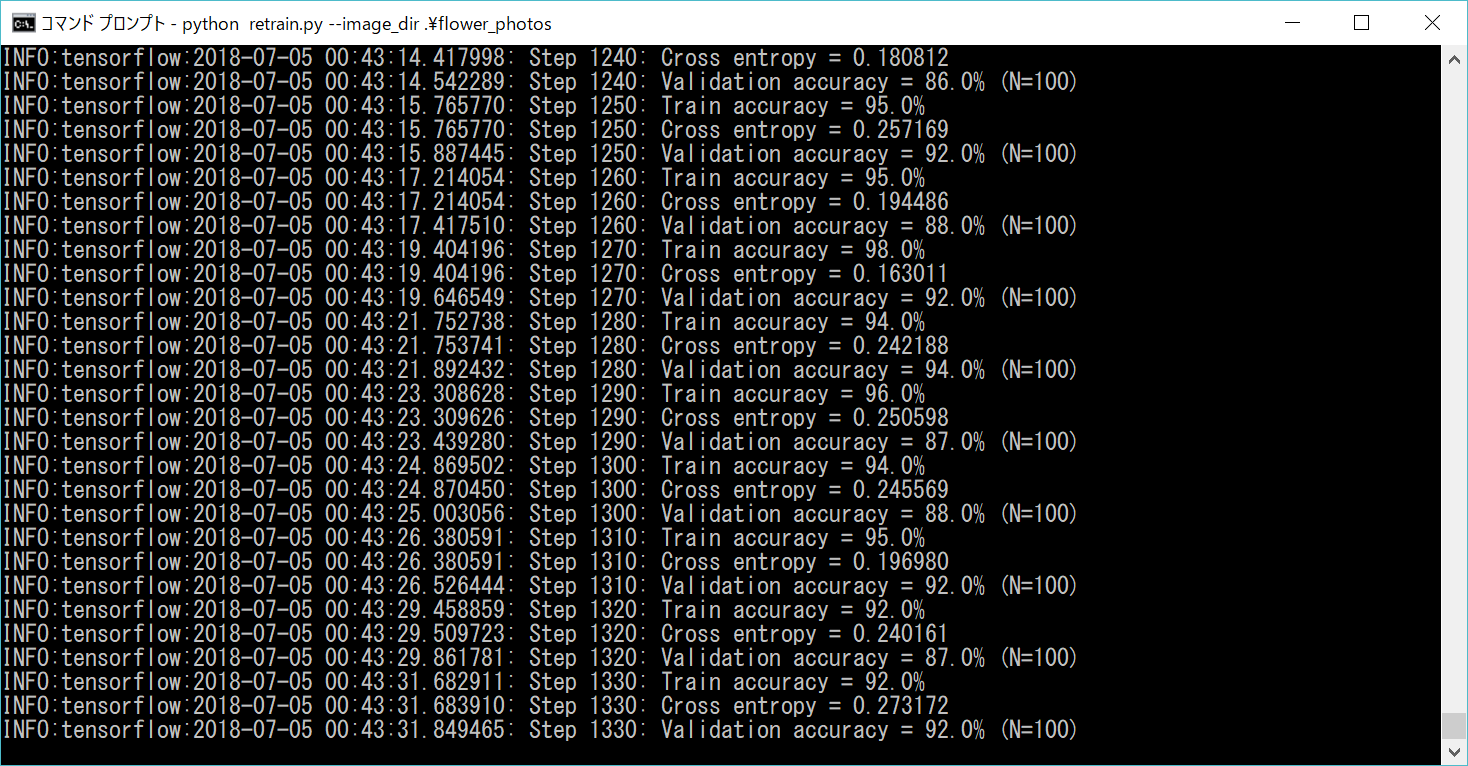
学習状況の確認
tensorboardコマンドを使って学習状況をリアルタイムに確認することができます。
デフォルトでは学習結果ファイルが/tmp(WindowsではC:/tmp)に作成されています。
tensorboardコマンドに上記の/tmp/retains_logsを指定して実行します。
※tensorboardはtensorflowを導入したpython環境をactivateしてから実行します。
(tensorflow)$ tensorboard --logdir C:/tmp/retains_logs
TensorBoard 1.8.0 at http://hostname:6006 (Press CTRL+C to quit)
起動後にブラウザからhttp://hostname:6006にアクセスすると、学習データが表示されます。

テスト
できあがった学習データを使って、本当にうまく画像分類してくれるかをテストします。
label_image.pyをgithubからダウンロードして適当なディレクトリに配置します。
https://github.com/tensorflow/tensorflow/raw/master/tensorflow/examples/label_image/label_image.py
先ほど生成された学習データを--graph'と--labels'に、分類したい画像を--imageに指定してlabel_image.pyを実行します。
(tensorflow)$ python label_image.py \
--graph=C:/tmp/output_graph.pb --labels=C:/tmp/output_labels.txt \
--input_layer=Placeholder \
--output_layer=final_result \
--image=~/flower_photos/daisy/21652746_cc379e0eea_m.jpg
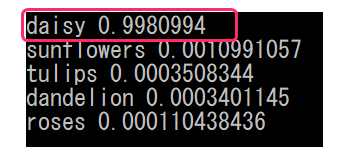
テスト画像はデイジー(ヒナギク)です。

実行してみると**「99%の確率でデイジー」と判定しました。**
ハムケツでチャレンジ
以上がチュートリアルです。ここからはハムケツでチャレンジします。
と言ってもテスト画像を差し替えるだけです。今回はhamketsuフォルダの中に、
- ハムケツばかりを集めた画像フォルダ「hamketsu」
- ハムケツによく似た大福ばかりを集めた画像フォルダ「nothamketsu」
の2種類を用意して画像を学習させます。枚数はそれぞれ約200枚です。
ちなみに学習画像はgoogle、being、twitterから自前のプログラムで収集しました。
https://github.com/quotto/imagecrawler
それでは学習させていきます。
(tensorflow)$ python retrain.py --image_dir ~/hamketsu
tensorboardで学習状況を見てみると、特にvalidationはチュートリアルに比べて上手く学習できていないことが伺えます。
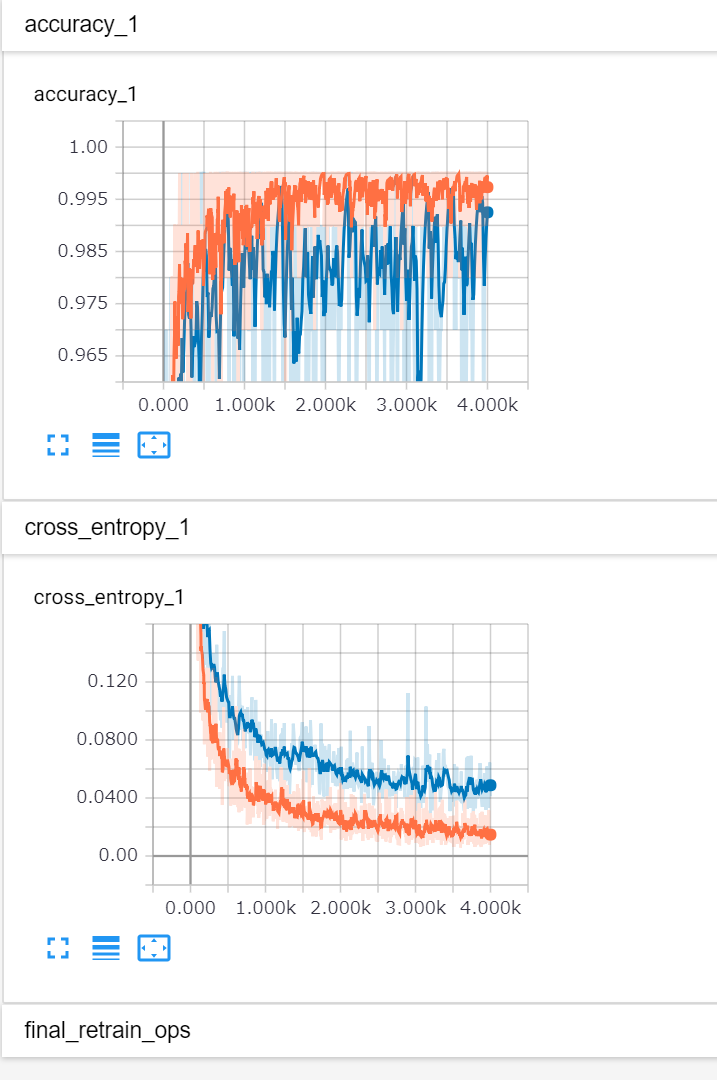
学習が終わったらテストをしてみます。
(tensorflow)$ python label_image.py \
--graph=C:/tmp/output_graph.pb --labels=C:/tmp/output_labels.txt \
--input_layer=Placeholder \
--output_layer=final_result \
--image=~/test/テストする画像ファイル.jpg
まずは大福です。

(https://ja.wikipedia.org/wiki/%E5%A4%A7%E7%A6%8F)
**「86%の確率でハムケツじゃない」**となりました。まずまずです。

続いてハムケツです。
 (https://www.imgrumweb.com/post/Bi_-_uTBVHX)
(https://www.imgrumweb.com/post/Bi_-_uTBVHX)
**「99%以上の確率でハムケツ」**と判定しています。完璧です。

しかしそう上手くもいきません。
例えばこの画像は「ハムスター」であって「ハムケツ」ではありません。

(http://www.nicovideo.jp/watch/sm25188364)
しかし**「89%の確率ではハムケツ」**と誤判定されてしまいました。

また、この画像は「子猫のケツ」です。
 (https://peco-japan.com/50783)
(https://peco-japan.com/50783)
しかしこれまた**「98%でハムケツ」**と誤判定されてしまいました。

以上のとおり、学習データも十分ではなくハムケツ判定の精度はイマイチでした。
しかしチュートリアルのように対象画像の範囲が限定される(例えば「花の画像」だと分かりきっている)場合は、ノンプログラミングでお手軽に画像分類ができます。
また公式ページには今回使用したプログラムのハイパーパラメータの指定方法なども掲載されているため、色々と試してみると良いかもしれません。