
Hello, my name is Sourav Saha, a member of NEC Digital Technology Research and Development Laboratories. This is an article for NEC デジタルテクノロジー開発研究所 Advent Calendar 2023 Day 16.
Recently I came across a few examples from some performance-critical data analysis applications that revealed some hidden costs while working with pandas. I am going to explain one of them in today's blog.
Let's first look at the below example:
ret = pd.DataFrame()
ret["x"] = s1 * 2 # Line-1
ret["y"] = s2 * 2 # Line-2
This is simply multiplying two series data and assigning the result into a data frame. Both s1 and s2 have 100 million elements of type float64.
Still, they differ in their execution time to a great extent as shown below:
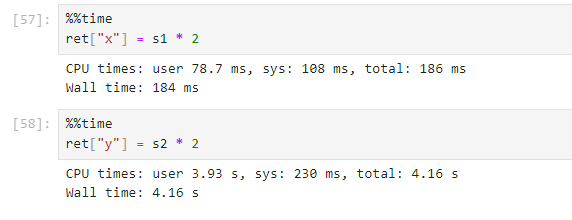
![]() Can you guess why?
Can you guess why?
Well, the fact amazed me when I first encountered this situation.
In pandas, the series and data frames are labeled with an “index” column (useful for multiple purposes).
Whenever an assignment (=) operation takes place, pandas first checks whether the index columns for both side of the expression are equally aligned or not. If not aligned equally, it performs an expensive reindex operation to align the data on the right-hand side of the assignment operator according to the data on the left-hand side.
In the above example, s1 and s2 have different index layouts (due to some sorting).
Hence Line-1 only involves the computation cost of a binary multiplication, whereas Line-2 involves the cost of a binary multiplication, along with the cost of index-alignment as depicted in the following figure.

Because of this expensive reindex operation, the execution of Line-2 consumes almost 50 times the execution time for Line-1 .
Needless to say, it is very crucial to take care of such assignments when performing within a loop.
For example, below is a sample program that attempts to perform the multiplication of each numeric column in the input data frame, df with 2. For each column that contains missing values (nulls), it sorts the data by the dates column, performs a forward fill operation to fill the missing values for those columns, and finally performs the multiplication on the modified column:
ret = pd.DataFrame()
for c in df.select_dtypes("number").columns:
if any(df[c].isnull())
tmp = df.sort_values("dates")[c].ffill()
ret[c] = tmp * 2
else:
ret[c] = df[c] * 2
There are two performance issues involved in the if part of the above program. The clearly visible one is the sort operation which is performed on the same data on every execution of the if part within the loop. Hence, let's first work on to optimize that:
# sorting and forward-filling are performed only once
sorted_df = df.sort_values("dates").ffill()
ret = pd.DataFrame()
for c in df.select_dtypes("number").columns:
if any(df[c].isnull()):
ret[c] = sorted_df[c] * 2
else:
ret[c] = df[c] * 2
The invisible performance factor is involved in the line: ret[c] = sorted_df[c] * 2.
Here it is trying to multiply target columns from sorted_df with 2 and assigning into the resultant dataframe.
After the sorting operation, index columns of df and sorted_df are no longer the same. Hence, whenever the if part is executed, along with the binary multiplication, an expensive reindex operation will take place making the above program very slow.
Hence, such assignments inside a loop should be avoided wherever possible.
One can perform the multiplication on the sorted_df and then perform sort_index on the result to get the intended result as shown below:
# sorting and forward-filling is performed only once
sorted_df = df.sort_values("dates").ffill()
target_input = sorted_df.select_dtypes("number")
ret = target_input * 2
ret = ret.sort_index() # to make the result as expected in the original program
Hope these tips will help you to accelerate your analysis when working with pandas. It is recommended to use an alternative python library developed at our laboratory, named FireDucks.
It is a multithreaded library accelerated with compiler technology enabling you to perform faster analysis even with the above situation (it can auto-optimize the first case, i.e., performing sort operation only once and reuse the same whenever needed) and is publicly available for use.
You may like to check out one of my articles explaining key features of FireDucks, along with its different layers of optimization to realize its potential to be used as a drop-in replacement for pandas.
Wrapping-up
Thank you for reading so far. ![]()
![]()
![]()
To summarize, I have discussed a few tips one should avoid while working with pandas. In the actual situation, just by performing the above optimization, we could successfully reduce the execution time of a performance-critical application from 2 hours 5 mins to 1 hour 30 mins. Using FireDucks further makes it possible to reduce the overall analysis time to 56 mins. With some further optimization, we could reduce the overall analysis time within 10 mins. Let's discuss a few of them in some other blog.
We recommend getting it installed using pip and try using it in your pandas application to enjoy its benefit. We are continuously striving towards improving its performance and releasing the same at frequent intervals. Please stay tuned with us and keep sharing your valuable feedback on any execution issues you may face or optimization requests you may have. We are eagerly looking forward to hearing from you!