キーワード:MLOps、機械学習パイプライン、マルチブランチ、マルチ学習、パイプラインGUIツール
目次
- 概要
- ケース紹介
- 課題抽出
- 設計と実装方法
概要
これまで各社が出された製品、及びOSSの中で、マルチブランチを容易に構成と実装するツールがなく、本稿では、複雑に絡み合う前処理と複数の学習、推論、評価を機械学習パイプラインで行う際のパラメーター設定の簡素化、パイプラインのデータチャンネルの繋ぎ方をご紹介します。
ケース紹介
A社(仮)は全国で80以上店舗を展開し、店舗毎に扱う商品は16種類です。店舗毎の商品別の時系列売り上げ予測モデルを作成するためのパイプライン構成
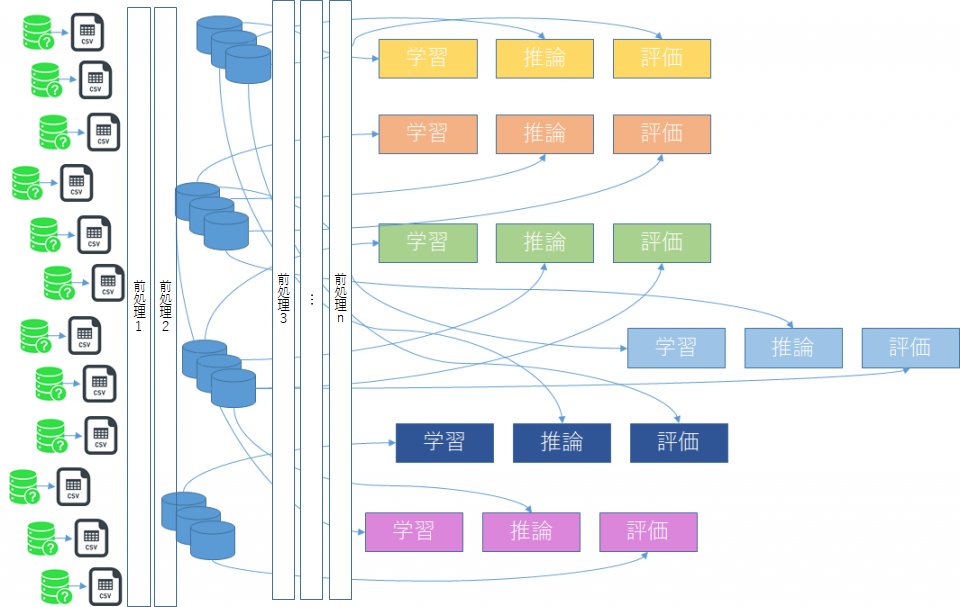
図2、表2に示す通り1つの学習モデルに対して学習、推論、評価用3つのデータセットが必要となるため、モデル数*3の3,840個が必要です。イメージしやすいよう、単純に12個のDBと7つのモデル作成にしました。
表2、パイプラインを動かすためのパラメーターは250,880個以上になります。
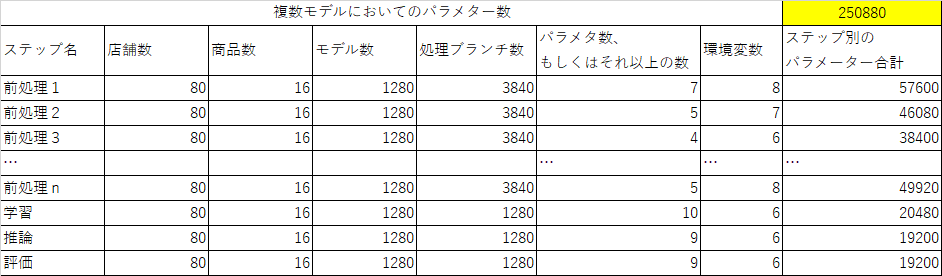
これらの大量のパラメーター(250,880個)も効率よく*yamlを作成し、パイプラインに渡す必要があります。
パラメータ数のみならず、各データセットと各学習、各推論、各評価とどのようなパスで繋いでいるか、ステップを組む際、パスを認識しやすいようワークフロー上での配置方法も工夫が必要です。
課題抽出
以上のケースから、以下の課題を抽出しました。
- 課題1: 大量のパラメーターの入力ミスを最小限に留めること
- 課題2: 入力パラメーター数をなるべく削減すること
- 課題3: パラメーター間の比較もできること
- 課題4: パラメーターの履歴も比較できること
- 課題5: 前処理時の作成したDBを容易に検索できること
- 課題6: 学習データセットと各モデル学習、推論、評価の関係性を入力しやすいこと
- 課題7: これらの大量のパラメーターをパイプラインに伝えること。
設計と実装方法
GUIツール上でパラメーター作成及びワークフローのステップチェーンを構成します。
課題1: 大量のパラメーターの入力ミスを最小限に留めること
対策1:
パラメーターの共通項目を洗い出して、共通部設定シートにまとめます。
実装方法1:
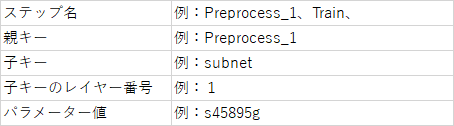
表示3のようにデータフレームへ辞書型変換の際、深いレイヤーをもつ辞書のキーはどのレイヤに置かれるかを識別するために、上位キーと下位キーを親子関係として紐づき、また子キーのレイヤー番号を1, 2, 3のように記入します。
表3、共通部テーブル構成
課題2: 入力パラメーター数をなるべく削減すること
対策2:
エクセルの関数と類似な機能で、共通項目+データセット名/モデル名を加味した加工値をpythonスクリプトで加工します。
実装方法2:
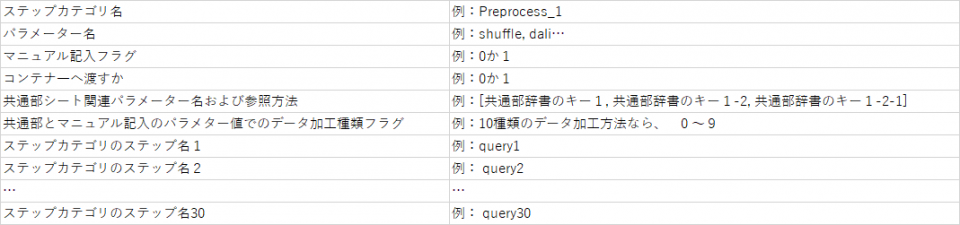
ステップカテゴリ毎のテーブルを用意します。
表4、ステップ毎のテーブル構成
課題3: パラメーター間の比較もできること
対策3: ステップカテゴリに、ステップ同士のパラメーターを列毎に用意します。
実装方法3:
ステップカテゴリの処理数(ここはデータセット作成数)に合わせて列を用意します。
表5、前処理1カテゴリーに4つのDB作成のために、
col1, col2, col3, col4を「前処理1」シートに用意します。

課題4: パラメーターの履歴も比較できること
対策4:
対策1~3より加工した最新情報をテーブルの形で保管します。
実装方法4:
方法1、(DB簡易版)python スクリプトよりパイプライン動作ディクトリーの./log/*.csvとして履歴保管します。
方法2、DBテーブルに保管・検索します。
課題5: 前処理時の作成したDBを容易に検索できること
対策5: 前ステップ<->後ステップのデータチャンネルは実ファイルパスの代わりに、キーワードを使います。
実装方法5:
前処理より出力された学習データセットのファイルパスを入力することをやめて、表6の黄色いセル入力エリアのquery1, query2のような名称を記入します。表5の示した前処理1~より作成したデータセット実パスをpythonスクリプトより検索し、パイプラインに渡します。検索対象は実装方法4で保管された履歴情報よりデータフレームとなります。
表6、query*をキーに、対策4で保管されたテーブルで
該当学習データセットの出力した実パスを検索します。

課題6: 学習データセットと各モデル学習、推論、評価の関係性を入力しやすいこと
対策6: 関係性をデータフレームに変換
実装方法6:
各ステップ(表7のコラム名はステップ名)のデータセット名と学習、推論、評価ステップ、学習済みのモデルと推論、評価の関係性マッピングをテーブルとしてまとめ、パイプライン上、各ステップの入出力をデータチャンネルとした形で認識します。
表7、ステップ関係性をテータフーム上でマッピング

課題7: これらの大量のパラメーターをパイプラインに伝えること。
対策7: ステップカテゴリ名、ステップ名、ステップのパラメーター名、パラメター値を辞書化としてまとめます。
実装方法7:
実際に流すジョブ数は ステップ x query数 あるいはモデル数になるので、今回ケースではかなりのジョブ数となります。対策4で得られたテーブル情報をjson辞書型->yamlに変換し、パイプラインに読ませてあげる形、そしてjob作成をそれぞれ関数化し、
辞書1
{
ステップ名:
{
query名(あるいはデータセット名、モデル名:
{ジョブ名:ジョブの中身}
}
}
という辞書型にまとめます。最後に、パイプラインをオーケストレーションするモジュールに図7の関係性を見て、辞書1をパス繋ぎ設定を行います。