表1:ターゲットリーケージ改善前後の訓練誤差・汎化誤差代理指標の比較
| カテゴリ | リーケージあり | リーケージ無し | 変化 |
|---|---|---|---|
|
訓練誤差 (正常結果/全データ数) |
96.1% (50/52) |
90.3% (47/52) |
▼5.8pt |
|
汎化誤差代理指標 (正常結果/全データ数) |
78.8% (41/52) |
88.4% (46/52) |
△9.6pt |
| ギャップ | 17.3pt | 1.9pt | 訓練誤差が拡大し汎化誤差が減少 リーク改善時の理想的な変化が発生 |
目次
はじめに
機械学習において、予測時点では知りえないはずのデータが学習用データ内に紛れ込んでしまう状態を 『ターゲットリーケージ』 と言います。
リーケージが発生すると、訓練時には「カンニング」をしているような状態になり、驚異的な高精度を叩き出しますが、いざ本番環境に投入すると、カンニングペーパーがないため精度がガタ落ちしてしまいます。
本来ターゲットリーケージは、発生していてもモデルは正常に動いているように見えるため発見が難しく、かつモデルの信頼性に直結してしまう難しい問題なのですが、
今回、自ら構築した精度検証基盤を通じてこのリーケージを特定・改善し、訓練性能と汎化性能のギャップを15pt以上縮小させることに成功しました。
この記事はその成功の秘訣をまとめていきます。
...と、華々しい成果だけを語れれば格好いいのですが、本記事の主役はその裏側にあります。
リーケージ改善中に発生したたった1つのバグ解消に3ヶ月という時間を費やした苦闘の記録と、そこから得た 「本番で機能し続けるMLシステム」への学びを共有していきます。
結論
- MLOpsは『監視・評価・改善』が大事であり、その始まりとなる『監視』が最も重要。
- 完ぺきな監視はないため、オーバーエンジニアリングにならないよう最小限の監視で最大限の効果を発揮するのがMLOpsの腕の見せ所。
- とはいえ後から監視を追加するのは難しいから最低限のデータリネージ管理は設計段階から組み込もうね!!!
ターゲットリーケージの発見と精度検証基盤構築
まずはターゲットリーケージ発見時の状況から。
私が担当しているコンタクト率モデルはパイプラインアーキテクチャを採用しており、構築容易性に優れているものの、度重なる改修によって典型的な密結合モノリシックアーキテクチャになっています。
この状態だと追加開発や既存処理の流れが追いづらく、非常に保守性が低かったため、リアーキテクチャリングを検討。
疎結合化、UT・監視強化によって今後の保守性とモデル信頼性を向上させようとしました。
それを実施するため処理を構造化し、どこで何しているかをドキュメントに落とし込んでいる際、特徴量の作り方と学習への利用の仕方に違和感が。
詳細は省きますが、ここで複数のモデルを同じデータ群を使用して作成する処理になっていて、対象サービスの実績データを省かずに学習している処理を発見しました。
これを顧客に報告し修正してはい完了!と行けばよかったのですが、事はそう簡単ではなく。
「処理が動いているからいいじゃないか」 という安定性を重視する顧客によって改善は阻止されてしまいました。
精度検証基盤を作って効果検証を提案
そこではいそうですかと引き下がっては私の存在意義がないなと思ったので、
- ターゲットリーケージがモデル出力の信頼性を損ねている
- コンタクト率を使ってマーケティング部門が意思決定をしているが、間違ったデータによって意思決定しているため大きな機会損失に繋がっている可能性が大きい
- 「動いている」ではなく「正しく動いていること」が機械学習モデルに求められる状態である
ということを訴求して改善の必要性をアピール。
そのうえで、現行の商用処理には手を一切加えず、別処理で効果を検証し汎化性能の向上が認められたら改修させてほしいと提案しました。
そんなこんなで始まったのが精度検証基盤構築。
まず、現行の処理フローは下記のようになっていました。
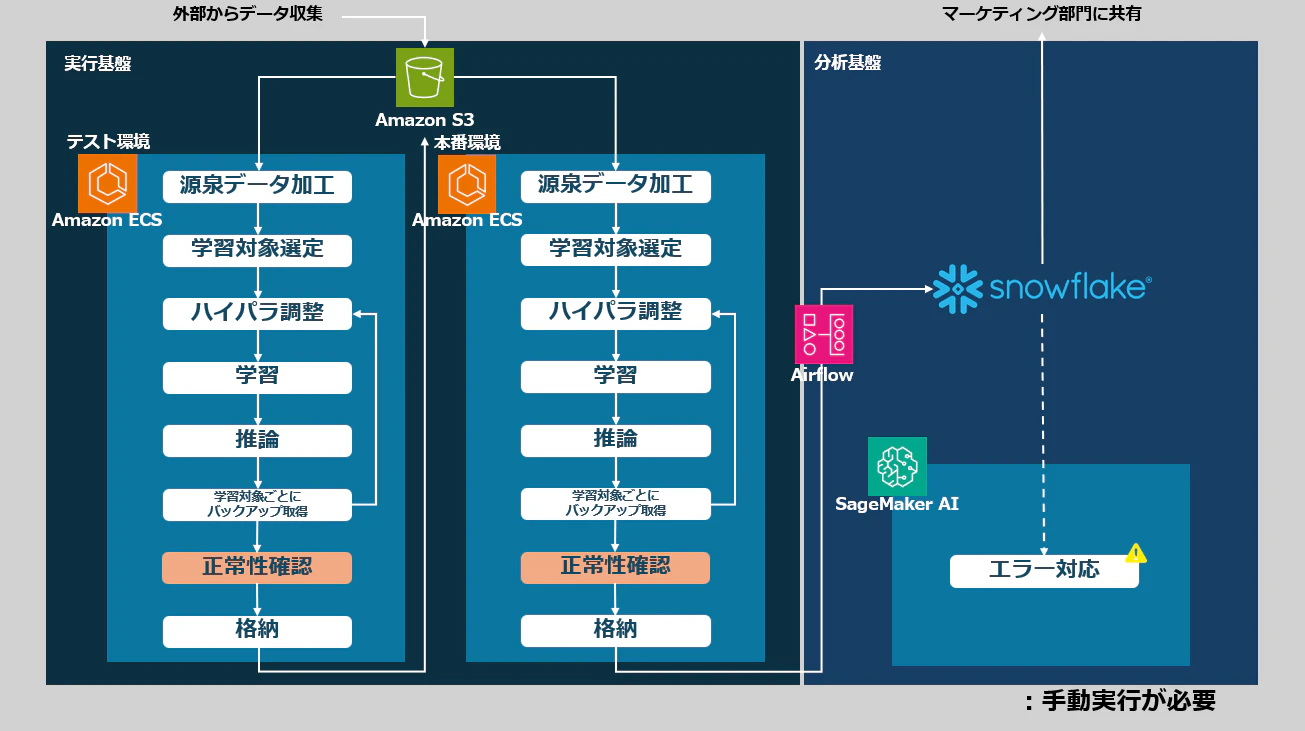
上記の「本番環境」と「テスト環境」は同じ処理を使ってコンテナだけ分けることで環境を分けているため、おいそれとコードを変更できる状態ではありませんでした。
私が提案したのは下記のように、同じ環境だけど本番処理には手を加えず、精度検証だけを簡単に行えるワークフローです。
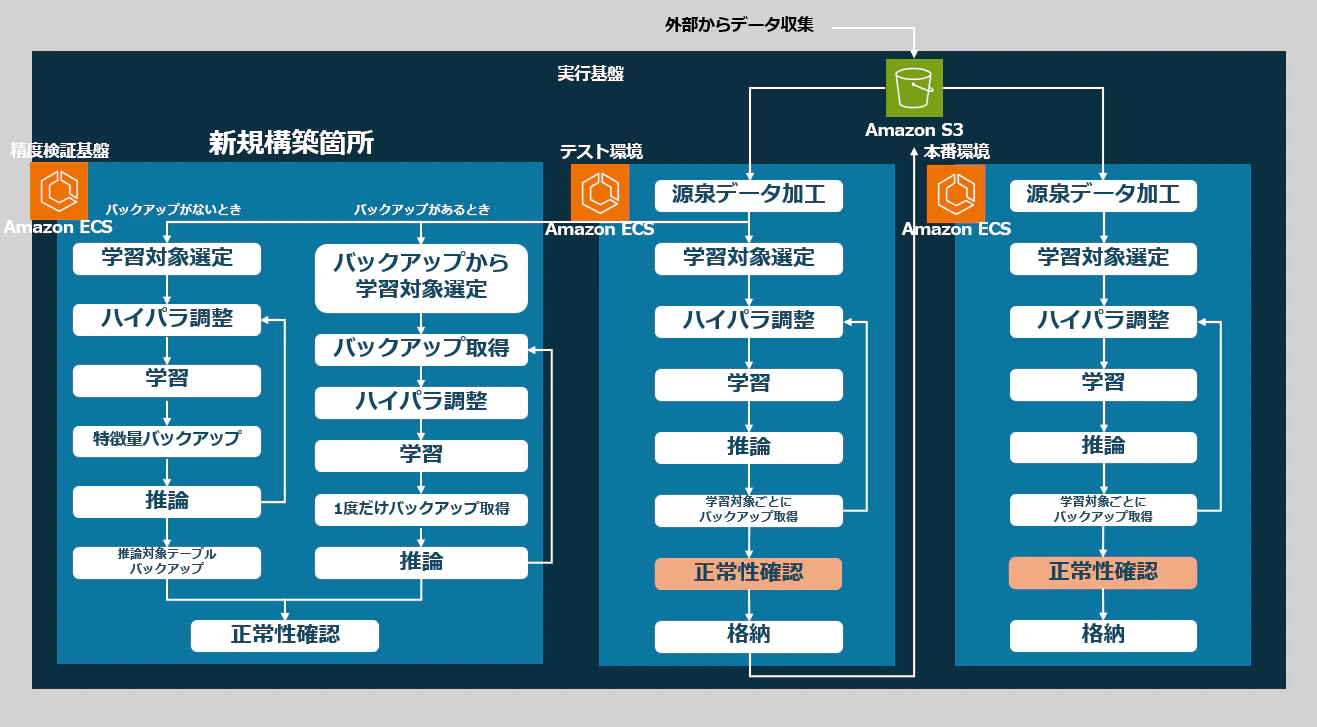
特徴量テーブルと推論対象テーブルバックアップを新たにバックアップし、そのデータから何度でも精度検証ができる構成です。
テスト環境でも特徴量テーブルはバックアップがあるものの、アカウントIDを保持していない生の特徴量データだったため、「どの実績値がどのユーザーのものか」を特定できず精度検証に向かなかったため新規にアカウントIDありでバックアップを取り、学習時にそぎ落とす方式を取っています。
意識したのはコストパフォーマンス。
以前の調査(下記記事参照)にて前処理に5.4万円かかることを受け、前処理を使用して作成した中間テーブルをバックアップすることでその工程をスキップするようにしています。
https://zenn.dev/zenn_mita/articles/bd54d81c4dab31
トレードオフになったのは実行時間。
通常50メディア24時間で完了していたところを、S3からスキャンする時間が増えたため50メディア33時間かかるように。
コンピュートコストで0.9万円コストがかかり、前処理スキップで5.4万円かかるので、1回の実行当たり4.5万円ほどコスト回避できている基盤となっております。
今回のリーケージ改善にて、後述のバグ調査も合わせて15回以上回しているため、すでにトータル70万円程度コスト回避しており、今後の特徴量エンジニアリングなどを考えると年間数百万円はコスト回避に貢献できたと考えています。
精度改善結果
そんなこんなで、精度検証基盤を作ってターゲットリーケージを改善したところ冒頭の表のように改善できました。
(再掲)表1:ターゲットリーケージ改善前後の訓練誤差・汎化誤差代理指標の比較
| カテゴリ | リーケージあり | リーケージ無し | 変化 |
|---|---|---|---|
|
訓練誤差 (正常結果/全データ数) |
96.1% (50/52) |
90.3% (47/52) |
▼5.8pt |
|
汎化誤差代理指標 (正常結果/全データ数) |
78.8% (41/52) |
88.4% (46/52) |
△9.6pt |
| ギャップ | 17.3pt | 1.9pt | 訓練誤差が拡大し汎化誤差が減少 リーク改善時の理想的な変化が発生 |
「汎化誤差代理指標」とは、モデルの性質上正確な汎化性能を図ることが難しいため導入されているもので、疑似的に汎化性能を測る独自指標です。
結果は訓練誤差が5.8pt上がったものの、汎化誤差が9.6ptも向上。
訓練誤差と汎化誤差のギャップにおいては15pt以上改善。比率で言えば12.2%程汎化性能が向上しています。
カンニングを修正したことによって正当な訓練性能におちつき、正しく学習できているからこそ汎化性能が上がるという、ターゲットリーケージ改善のお手本のような結果となっています。
精度検証基盤に起こった1つのバグ
精度検証基盤構築によって商用処理への影響を排除したうえでコスト削減とターゲットリーケージ改善を同時にこなすという素晴らしい成果を生みだした!
...と言いたいところですが、そううまくいかないのが現実というものです。
基盤を動かしてみると、出力結果に 身に覚えのない「NaN」 が混入し、正常な精度検証ができないという事態に陥りました。
消えないNaNと「月10日間」のチャンス
調査を始めると、商用処理と精度検証基盤で、そもそも分母となる「学習対象のユーザー数」や「実績値」が食い違っていることが判明しました。
まず疑ったのは、今回新設した「精度検証基盤用のバックアップ処理」です。
「NaNが出るということは、0除算やNullが関わっているはずだ」と仮説を立て、バックアップ前後のデータ数、型、Null数、0の数を徹底的に洗い出しました。
しかし、この調査には大きな壁がありました。本番データが毎月10日に洗い替えされてしまうという仕様です。
一度チャンスを逃すと、検証に必要な「本番と同じデータ断面」が消えてしまうため、再試行のチャンスが極めて少なく、これが解決までに時間を要した大きな要因となりました。
そんな時間的制約もある中、粘り強く検証を重ねた結果、以下のことが分かりました。
まずは問題なかった点。
- バックアップ処理自体に欠損や不備はない。
- UTもすべてパスしている。
- データの型も商用処理と完全に一致している。
次に問題があった点。
- 精度検証基盤だけ推論結果テーブルに「0」の値を持つユーザーがおらず 「Null」の値を持つユーザーが急増していた
- 実績の平均値等を算出する際割り算があったが、分子分母のどちらかに一つでもNullが入ると結果はNaNになる
- 上記を鑑みて0ユーザーとNullユーザーの合計値は商用処理と精度検証基盤で一致すべきだがどのメディアもずれていた
うーーーーーん?
ずれるはずのない値がずれてるのはなんでだ????
バグの正体:本番処理のデータずれ
さらなる深掘りの末、ようやくNaNの正体に辿り着きました。原因は、商用処理と精度検証基盤で 「最終的な実績値を取得する際のテーブル断面」が異なっていたこと でした。
『実績ユーザーの数はどのテーブルからとっても変わらない』という暗黙知で動いていたため、推論結果にデータを結合する際の参照テーブルを商用と変えてコスト削減を狙っていた部分が問題でした。
これによって一部のユーザーに予期せぬNullが発生し、計算過程でNaNへと変化していたのです。Nullを排除する正常性確認を実装しようやくNaNは消失しました。
しかし、ここで私はさらなる 「不都合な真実」 に気づいてしまいます。
氷山の一角:連鎖していたデータ不整合
NaNが消えても、商用と精度検証基盤で「実績ありユーザー数」の合計値がどうしても一致しませんでした。
本来、実績値は確定した事実であるため、Nullのユーザーと0のユーザーを足し合わせれば、どの環境でも一致するはずです。
「精度検証基盤側のバグではないとしたら、もしや……」
嫌な予感を抱えながら調査のメスを商用処理側に入れると、衝撃の事実が判明しました。
- 特徴量データのレコード数(実績ありユーザーを学習データとしているため)
- 推論対象テーブルの各メディアごとの実績ありユーザー数
- 推論結果テーブルの実績ありユーザー数
これらすべてが、微妙にズレていたのです。
つまり、精度検証基盤のバグだと思っていたものは、実は商用環境に潜在していた「データ不整合」というさらに深い闇が、基盤構築によって表面化したものでした。
元々密結合で保守性の悪いコードだったうえに、この根本的なズレが精度検証基盤の挙動と複雑に絡み合っていたことが、問題特定に3ヶ月という時間を要した真の理由です。
今後の対応と学び
調査の結果、現在発生しているデータのズレは全体数の 最大0.45% であることが分かりました。
現時点では予測精度にクリティカルな影響を及ぼす規模ではないものの、「正しく動く」ことを目指す上で無視できるものではありません。
今回の経験から、今後のアクションと学びを整理しました。
-
「どこでズレているか」の継続調査と方針決定
どのテーブル間でデータが脱落・変質しているのかを完全に特定し、「どの値を正解(真実)とするのか」の定義を再整備します。その上で、現状維持で許容するか、パイプラインそのものを改修するかを検討します。 -
「WEBシステム的思考」から「MLOps的思考」への脱却
これまでの処理は「止まらずに動いていればOK」という、WEBシステム的な安定性に重きが置かれたシステムになっていました。しかし、機械学習システムにおいては「値が正しいこと」「データの系譜(リネージ)が追えること」がそれ以上に重要です。 -
データリネージ管理の早期導入/抜本的なリアーキテクチャリング
後からデータの流れを追うのはあまりに苦痛を伴います。設計段階から、どのデータがどの処理を経てどこへ行くのかを監視・評価できる基盤を組み込むことが、結果として最短で成果を出すための唯一の道であると痛感しました。
また、私はパイプラインが組み込まれた後に参画したため設計に関われていなかったのですが、ほかのモデルのアーキテクチャ選定を任されているので、そちらではこのような問題が起こらないような設計にできればと考えています。
感想
本当に疲れました。
課題解決のために粘り強く調査を続け、根本原因の特定から解決策の提案まで完遂できたことは、自分の中でも確かな実績になったと感じています。
ただ、いかんせん今回起きたことは事象が複雑で、要素も多く、それらが密に絡み合ってたので、この記事もわかりづらいものになっている気がして不安です。
正直、今はそれすら考えるのがしんどいほどエネルギーを使い果たしてしまいました。
今後もまだまだやるべきことは山積みですが、まずはこの週末に泥のように眠って、また来週から頑張ろうと思います。