目次
初めに
やったことと結果
SHAP値処理の改修
背景
課題1:for文の中でlambda式を使用
課題2:intをstrに変更している
解決策
実行時間
回避コスト算出
モデル作成における前処理スキップ
背景
解決策
削減コスト算出
なぜむなしいのか
感想
初めに
SHAP値処理を最適化することで99.99%以上の処理時間削減およびAWSコンピュートコストを年間440万円以上抑制することに成功。
バッチ処理を回すたびに重い中間テーブルを作成していた前処理を飛ばせるようにしてAthenaのスキャン料を年間60万円以上削減。
ビジネス上において非常にインパクトが大きく意味のあるエンジニアリングを実現しているはずなんだ。
なのになぜだ。
このどことない地味さは。
どうしてこんなに「やってやった」感がないんだ。
なんてむなしいんだ...
ということで、このむなしさの整理を兼ねてやったことをアウトプットしてみることにしました。
やったことと結果
先ほども書きましたがやったことは下記2つ
- SHAP値処理を最適化することで99.99%以上の処理時間削減およびAWSコンピュートコストを年間440万円以上抑制
- バッチ処理を回すたびに重い中間テーブルを作成していた前処理を飛ばせるようにしてAthenaのスキャン料を年間60万円以上削減
結果、累計年間500万円以上のコスト削減を実現。
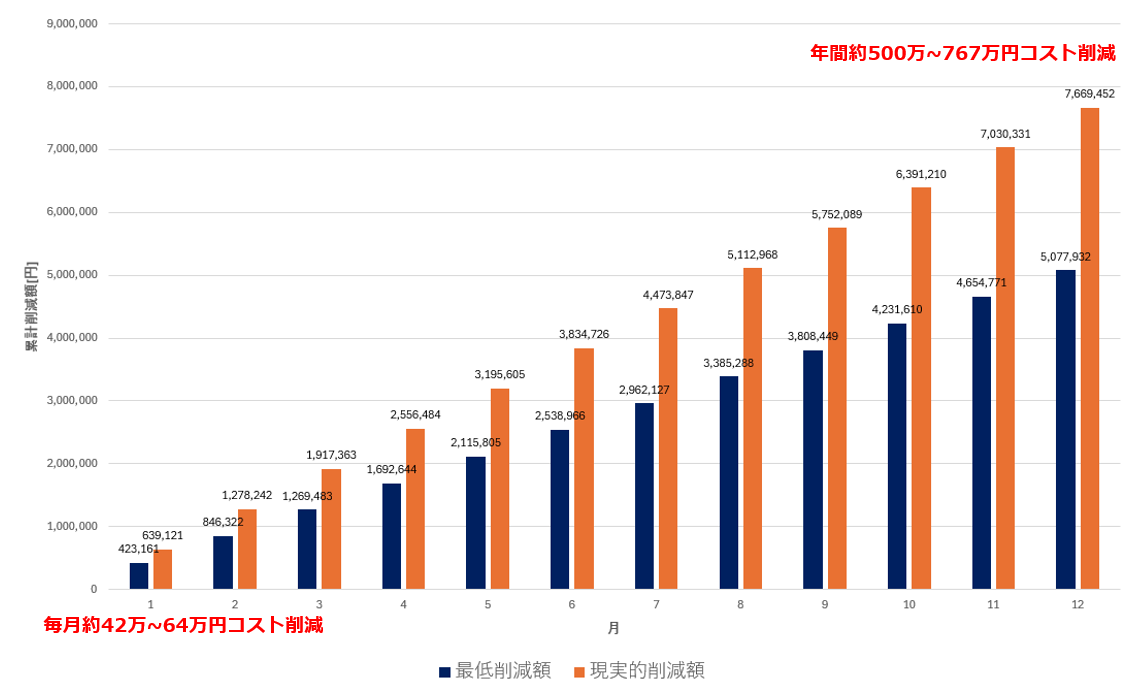
それぞれの背景と具体的な対応方法を整理します。
SHAP値処理の改修
背景
こちらはコスト回避。
ここでいうコスト回避とは、本来かかるはずだったコストを未然に防ぎましたよって意味です。
新しくSHAP値処理を追加するが、他機能で実装されているSHAP処理だと高コストだったので、大規模モデルでも扱えるように最適化しました。
SHAP値とはモデルの予測結果に対して、各特徴量がどれだけ寄与したかを公平に数値化する指標で、機械学習モデルが出力した値が、なぜその値になったか?を説明するためのものです。
この取り組みの背景には過剰学習がありました。
訓練誤差は極めて小さいが汎化誤差が20%以上、大きいものだと45%以上も誤差が出てしまっていたため、汎化誤差拡大原因を切り分けるための作業の1つとしてSHAPを追加する運びになったという形です。
(実際は過剰学習ではなくターゲットリーケージだったのですがそれは別の機会に。)
課題1:for文の中でlambda式を使用
他モデルではSHAP処理を採用していたので、そちらを流用して処理を流したところSHAP処理の途中でログが止まりました。
エラーは出ないのですが、処理が動いている様子もない、という状態。
色々調べてみると下記のような処理で止まっていました。
for i in Series.index:
if Series.loc[:, i].max() == Series_median[i]:
Series.loc[:, i] = Series.loc[:, i].apply(lambda x: 1 if x==Series_median.loc[:, i].max() else 0)
else:
...
SHAP解釈のための前処理なのですが、問題は処理ロジックではなく、実装の仕方でした。
上記はlambda式を使って条件に合えば1, それ以外は0を返すという処理で、Series単位でPython関数呼び出しを行っています。
lambdaをapplyで回す実装は記述量を減らすことができますが、内部的には要素ごとにPython関数を呼ぶ形となり、ベクトル化が効きません。
結果として関数呼び出しのオーバーヘッドとforループによる反復回数が掛け算となり、ビッグデータではボトルネックになりやすいです。
...というfor文が既存SHAP値処理には3つ存在しており、とんでもなく時間がかかるようになっていました。
課題2:intをstrに変更している
上記の例があったため、ほかに処理が遅い場所がないか探したところ見つけたのがこちらです。
SHAP値を算出するにはプラスマイナスが重要になってきます。
何のプラスマイナスかというと特徴量そのものの大きさと予測への影響。
特徴量の大きさが大きくて予測にプラスの影響を与えていたら++、という風に++,+-,-+,--の4象限に特徴量を分けて影響度を確認します。
上記を算出するために、既存SHAP値処理では下記のようにintをstrに変換して4象限を把握していました。
Series = Series.astype(str)
shap_values = shap_values.astype(str)
answer = Series + shap_value
...
for i in Series:
df_shap.loc[df_shap["fea_name"]==i, "fea+_shap+"] = len(answer[answer[i]=="11"])
...
上記は結構なアンチパターンであり、
-
intからstrに変換するコストが高い -
strはメモリ使用量が増える -
strなのでベクトル演算が効かずPython処理にフォールバックする - Python処理なのでオーバーヘッドもかさむ
というなかなかに凶悪な処理となっていました。
解決策
ということでリファクタリング。
まず課題1については下記のように変更しました。
for i in X_median.index:
if X.loc[:, i].max() == X_median[i]:
X.loc[:, i] = np.where(X.loc[:, i] == X.loc[:, i].max(), 1, 0)
else:
...
意識した点は、「lambda処理を廃止しnumpyに統一することでベクトル演算を最大限生かせるようにする」という1点のみです。
ベクトル演算とは、for文で1要素ずつ処理するのではなく、numpy配列全体に対して同じ計算を一括で書けることを指します。
今まではPython関数を呼び出してlambdaを使って1要素ずつ計算していたため莫大な時間がかかっていましたが、上記の処理だとX.loc[:, i] == X.loc[:, i].max()という処理がシリーズ全体に一気にかけられるため一瞬で終わります。
課題2も同様にベクトル演算がかけられるように、かつ++等の4象限をうまく表現できるよう工夫しています。
df_shap["fea+_shap+"] = 0
df_shap["fea+_shap-"] = 0
df_shap["fea-_shap+"] = 0
df_shap["fea-_shap-"] = 0
for i in Z_median.index:
# 2つの0/1列から、0, 1, 2, 3 の4状態を表すユニークな数値列を生成
# (Z=1, S=1) -> 3 (++)
# (Z=1, S=0) -> 2 (+-)
# (Z=0, S=1) -> 1 (-+)
# (Z=0, S=0) -> 0 (--)
combined_code = Z[i] * 2 + shap_values_df[i]
counts = combined_code.value_counts()
row_index = df_shap["fea_name"] == i
df_shap.loc[row_index, "fea+_shap+"] = counts.get(3, 0)
df_shap.loc[row_index, "fea+_shap-"] = counts.get(2, 0)
df_shap.loc[row_index, "fea-_shap+"] = counts.get(1, 0)
df_shap.loc[row_index, "fea-_shap-"] = counts.get(0, 0)
同様にベクトル演算で完結するようにしたうえで、++などの表現を11などでするのではなく、ビット演算チックな計算combined_code = Z[i] * 2 + shap_values_df[i]を入れています。
これによって下記のように++なら3、+-なら2という風に、独立な数値が返って寄与度を算出することができるという寸法です。
| Z | SHAP | combined_code |
|---|---|---|
| + | + | 3 |
| + | - | 2 |
| - | + | 1 |
| - | - | 0 |
この処理を思いついたときは「アルゴリズム勉強しててよかった~」と心底思いました。
どこに何が役立つか分からないもんですね。
実行時間
このモデルは特定のメディアに対してコンタクト率を算出するモデルで、通常48メディア程度学習します。
特徴量も1メディアごとに150個近く存在しているため、forループを回る特徴量の合計は7200個と、かなり大規模となっています。
改修前と後で各ステップにおける実行時間をまとめると下記のようになります。
| 改修前 | 改修後 | |
|---|---|---|
| forループ1つ目 | 1特徴量回して17秒 | 150特徴量を回して0.5秒 |
| forループ2つ目 | 測定不能(処理が固まったため) | 150特徴量を回して5.6秒 |
| forループ3つ目 | 測定不能 | 150特徴量を回して15秒 |
| SHAP値算出 | 測定不能 | 150特徴量を回して0.015秒 |
| 合計 | 測定不能 | 1メディアを回して30秒 |
改修前は1つ目のforループ途中でスワップスラッシングを起こして固まったため、2つ目以降のforループを測定することができませんでした。
改修後の値を見ると1ループ30秒以上はかかっていたのでは...
回避コスト算出
最低回避コスト算出のため、SHAP値算出含めてすべての改修前の実行時間がforループ1つ目と同じ時間かかっていると考えようと思います。
4つのフェーズごとにおいて、1つのメディアを学習するのに必要な時間は、
$17[s] * 150[特徴量] * 48[メディア] = 122400[s] = 34[h]$
1フェーズごとに34時間かかるので、4つのフェーズがある全体の処理時間は
$34[h/フェーズ] * 4[フェーズ] = 136[h] = 5.66[day]$
となり、すべてのメディアのSHAP値算出だけで5日半以上かかる計算になります。
これらはバッチ処理であり、毎月初めに定期実行されます。
また、コード修正が起こった時にはテストデバッグとして本番環境をコピーした環境にて実行する必要があり、毎月2~6回程度実行されるので、毎月最低3回は実行されると考えられます。
バッチ処理はAWSのEC2上で実行され、使用インスタンスは1時間あたり$6.05であるr5.24xlargeというモンスター級のハイスペックマシンを使用しているため、年間にかかるコンピュートコストは、
$6.05[$/h] * 150[円/$] * 136[h] * 3[回/month] * 12[month]= 4,443,120[円/年]$
となります。
対して、改修後で同様の計算をすると、48メディアで1440秒 = 0.4時間なので
$6.05[$/h] * 150[円/$] * 0.4[h] * 3[回/month] * 12[month]= 13,068[円/年]$
となります。
したがって、年間最低回避コストは
$4,443,120[円/年] - 13,068[円/年] = 4,430,052[円/年]$
となります。
実に440万円以上のコスト回避。
う~~~ん素晴らしい。
図にすると下記。

う~~~んよくわからん。
文字通り桁違いなコスト回避ということでしょうか。
モデル作成における前処理スキップ
背景
次にコスト削減です。
先ほども書きましたが本モデルはバッチ処理であり、本番環境とテスト環境があります。下記がアーキテクチャ図。

本番環境は月に1回以上、テスト環境は月に2回以上動くのですが、数十億レコードを学習する大規模モデルなだけあってAthenaのスキャン料金がとんでもないです。
大体1回実行するのに5.5万かかります。
ただ、パイプラインの自動化に取り組んでいたり、今後データリークや細かいリファクタリングを実施する上で、テストデバッグをしないわけにはいきません。
そんなわけで、テストデバッグの実行コストがネックになっていました。
解決策
以前の取り組みで、Athenaのスキャン料を多くとられているのは特徴量データ取得ではなく、前処理における中間テーブル作成だとわかっていました。
以前の取り組みは下記。
https://zenn.dev/zenn_mita/articles/da8d84d0369869
その中間テーブル作成をスキップできれば大幅コスト削減ができると思って調べたところ、中間テーブルはCTASされていて、S3に物理的におかれていることを発見しました。
ということで、引数に特定文字列を渡したら前処理の中間テーブル作成をスキップするよう改修。
本番環境では引数無しで実行するため、下記のように影響範囲をテスト環境のみに絞り込めます。

削減コスト算出
改修後にテストデバッグをしてAthenaスキャン量を確認し、改修前と比較したものが下記のようになります。
料金の算出方法は、$スキャン量 * 5[$/TB] * × 0.000000000001[TB] * 150[円/$]$です。
| 改修前 | 改修後 | |
|---|---|---|
| スキャン量 | 72314455573227 | 1347775563955 |
| 料金 | 約55,000円 | 約1,010円 |
したがって、1回の再実行において約5.4万円のコスト削減ができます。
最低限のコスト削減額を求めると、先ほど同様定期実行1回、テストデバッグ2回となるため、2回目のテストデバッグのみで削減効果が期待できます。
年間の最低削減コストは、
$54,000[円/回] * 1[回/month] * 12[month] = 648,000[円]$
となります。
図にすると下記。

コスト回避策と比較するとわかりやすさは増しましたが、額としては大したことないな?といったところ。
しかし先月のテストデバッグ料金は1月あたり約34万円となっており、大体6回フル実行したことになります。
今後改修が続くため、毎月5回分コスト削減できるとなると、
$54,000[円/回] * 5[回/month] * 12[month] = 3,240,000[円]$
となり、非常に大きいコスト削減になります。
改めて図にすると下記。

...比率が変わらないので見た目も変わるわけないですよね。
ただ、数値としては増加するので、コスト回避と合わせて、最低500万円以上、現実的には760万円以上のコスト削減に寄与できたと考えています。

なぜむなしいのか
今回の改修は、数字だけ見れば十分にインパクトのある成果だったと思います。
それでも、どこか「やってやった」という感覚が湧かず、むなしさが残りました。
色々考えたあげく、ふと思い至りました。
誰からも褒められてない...
今回の取り組みは「新しく何かを生み出した仕事」ではなく、「起こるはずだった問題を削った仕事」です。
削ったのだから問題は起きなくて当然なのですが、MLOpsなどの基盤改善系の業務は「動いて当たり前」と無意識に認識されていることが多く、結果として「何も起きない = 何もなかった」かのように見えてしまいます。
今回感じた地味さやむなしさは、成果が小さかったからではなく、責任をもって処理の根幹をいじり、年間500万円以上のコスト削減というどでかい成果を生み出したにもかかわらず、周囲が無反応すぎたため温度差から生まれたものかなと考えています。
称賛と承認って、大事ですね。
後輩ができたらいっぱいほめてあげようと思います。
感想
今回の改修は、モデルを継続運用する上でのリスクとランニングコストを構造的に下げることを目的とした取り組みでした。
個人的に「エンジニアリングを通じてビジネス的価値を生み出す」ことを目標にしてエンジニアをやっているので、今回の成果は理想的な価値の出し方だなと考えています。
記事では最低削減コストをメインに計算しましたが、
- 削った長時間実行の中には、ネットワークエラーやOOMによる中断が原因の再実行などのリスクが含まれており、それもあわせて抑制できている
- 学習の途中まで回す、というテストデバッグは頻繁にある
- 定期実行も3か月に1回のペースで失敗して月に2回本番環境を実行している
などなど、本来ならばより多くのコストがかかることが予想されており、それらを未然に防げたのが今回の改修の肝かなと考えています。
単発のコスト削減ではなく、仕組みの改善による継続的なコスト削減なので、本モデルを使用する期間が長ければ長いほど効いてくるのも美しいですね(自画自賛
実際の削減コストは計算できないものの、下手したら年間数千万に達するのではないか...と夢が膨らむエンジニアリングを実施できました。
それでも、MLOpsは「動いて当たり前」な仕事であり、やっていることも地味めなのでほめられることがあまりなく、本当にすごいことをやったのか実感がわいてこなくて悲しいです。
ただ、だからこそ、こうして言語化して残すこと自体に価値があり、周囲に頑張りや成果をアピールするためにも重要だなと考えています。
自分の成果をアピールしてほめてもらって、単価向上・昇給・昇格の材料にするのも自分の仕事だなと思えましたし、
今回の改善から、他の大規模バッチ処理やMLOps案件にも横展開可能な考え方を学べたことは大きいので、引き続き精進しながらできる限りほめてもらえるようアピールしていきます。