Tensorflowで手書き中国語漢字の認識から音声出力
<-- 副タイトル : 数学が苦手なプログラマが機械学習をやってみた -->
経緯
近年、AI(人工知能)テクノロジーの使用が沢山の分野と業界に広がっています。古い形式のビジネスがこの世の中から段々追い出されています。この時代に、AIを知らないと恥ずかしいでしょう。
この文章は現在流行っているAI分野の機械学習について自らの開発体験をメモして、音声出力まで遊んでたもの紹介しようとしています。
やったこと
一言というと、google製機械学習のAPI tensorflowを用いて、中国語手書き画像をトレーニングして、中国語の漢字画像を認識し、そしてピンイン(Pinyin)に変換し、読み上げるまでです。
「これ、内容つまらないかもしれないですね。」
「ええ、文章の数を一つ足していますよ。」
この実装は他人の実装に参考したものですが、他山の石として勉強しました。
テクノロジーの裏
この文章で紹介された機械学習は畳み込みニューラルネットワーク(Convolutional Neural Network,CNN)を用いた実装です。
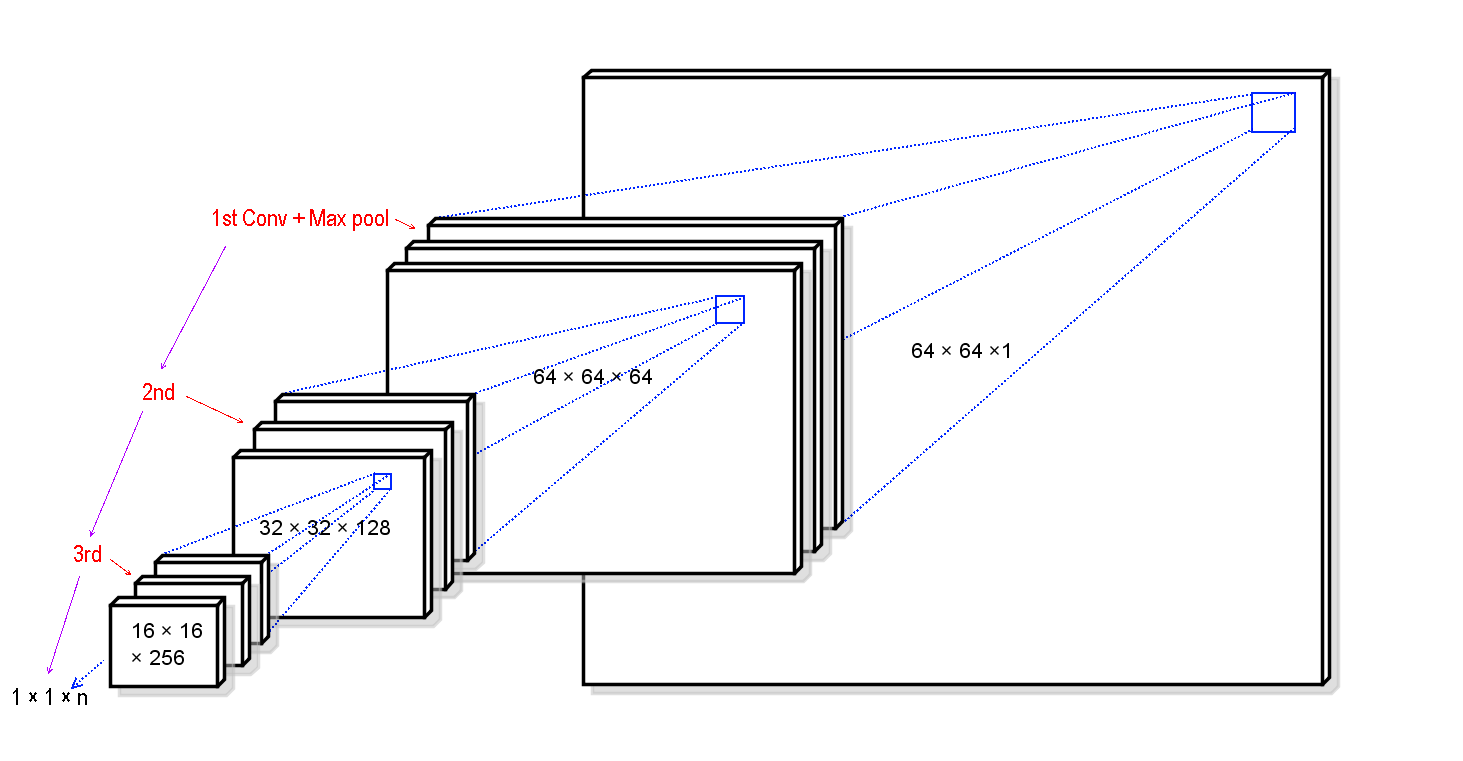
CNNの原理は上図のように、入力画像の局所的な特徴を抽出し、マトリクスで各局所の計算(次元削減)を繰り返して、結果を求めること。図に描かれている特徴の断片は各層に畳み込みの形で並んでいます。
畳み込み層の階数実装や各段階に使うアルゴリズムは規定されてないので、どのアルゴリズムやどんなパラメータを使うのが個別的に実証実験する必要があります。
開発環境の準備
開発環境の要件は下記のものです。
・Windows
・Python 3
・tensorflow と その他ライブラリ
AnacondaというツールがPythonの基本パッケージをまとめてインストールしてくれて、また「virtual env」みたいな複数の開発環境を簡単に用意してくれたので、その上に今回の環境を構築します。
まず、Python v3版のAnaconaを以下のページからダウンロードしてインストールします。
次に、Anaconda Prompt(ターミナル)から「tensorflowtest」という環境を作成し、切り替えて使用ます。
conda create -n tensorflowtest
activate tensorflowtest
また、tensorflowとPinyin(ローマ字もの)、音声処理用ライブラリをインストールします。
pip install tensorflow pypinyin pydub pyaudio
データの準備
こちらは自分勉強用のため、インターネット上に公開した手書き画像をダウンロードして使いました。
今回使用したデータについては、CASIA-HWDB1.1をダウンロードしてプログラミング中に使用できるフォーマットのPNGファイルに変換しました。(リンク、変換方法は略)
実際にダウンロードしたファイルはトレーニング用とテスティング用のもの両方があるので、直接に使用できます。ただし、個人用やビジネス用パソコンに対して学習対象のファイルが結構大きいし、学習するための所要時間が長いから、一部だけ取り出して使っても良いと思いました。
取り出した画像(抜粋)は以下のようです。

実装
Pythonのソースコードを一部コメントして説明します。
トレーニング
トレーニングは学習結果の辞書を求めることです。ソースの中のストラクチャは以下の「バッチ準備」、「OP計算」、「セッション処理」と「マルチスレッド処理」に分けています。
バッチ準備
# 画像テンソルの生成
images_tensor = tf.convert_to_tensor(self.image_names, dtype=tf.string)
# ラベルテンソルの生成
labels_tensor = tf.convert_to_tensor(self.labels, dtype=tf.int32)
# 入力画像、ラベルを一回スライスし、キューに入れる
input_queue = tf.train.slice_input_producer([images_tensor, labels_tensor], num_epochs=1)
# 入力バッチをシャッフルする
image_batch, label_batch = tf.train.shuffle_batch([input_queue[0], input_queue[1], batch_size=labels_number, capacity=20000, min_after_dequeue=5000)
OP計算
# 確率のプレースホルダ
keep_prob = tf.placeholder(dtype=tf.float32, shape=[], name='keep_prob')
# 画像バッチのプレースホルダ
images = tf.placeholder(dtype=tf.float32, shape=[None, 64, 64, 1], name='image_batch')
# ラベルバッチのプレースホルダ
labels = tf.placeholder(dtype=tf.int32, shape=[None], name='label_batch')
# 畳み込み層1
conv_1 = sl1m.conv2d(images, 64, [3, 3], 1, padding='SAME', scope='conv1')
# プーリング層1
max_pool_レイヤ2slim.max_pool2d(conv_1, [2, 2], [2, 2], padding='SAME')
# 畳み込み層2
conv_2 = slim.conv2d(max_pool_1, 128, [3, 3], padding='SAME', scope='conv2')
# プーリング層2
max_pool_2 = slim.max_pool2d(conv_2, [2, 2], [2, 2], padding='SAME')
# 畳み込み層3
conv_3 = slim.conv2d(max_pool_2, 256, [3, 3], padding='SAME', scope='conv3')
# プーリング層3
max_pool_3 = slim.max_pool2d(conv_3, [2, 2], [2, 2], padding='SAME')
# 1次元化
flatten = slim.flatten(max_pool_3)
# 全結合層(活性化関数:tanh)
fc1 = slim.fully_connected(slim.dropout(flatten, keep_prob), 1024, activation_fn=tf.nn.tanh, scope='fc1')
# logits for softmaxアルゴリズム
logits = slim.fully_connected(slim.dropout(fc1, keep_prob), labels_number, activation_fn=None, scope='fc2')
# 損失
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=labels))
# 精度
accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(logits, 1), labels), tf.float32))
# epoch
global_step = tf.get_variable("step", [], initializer=tf.constant_initializer(0.0), trainable=False)
# 最適化Adam関数
train_op = tf.train.AdamOptimizer(learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-08, use_locking=False, name='Adam').minimize(loss, global_step=global_step)
# クラス分類処理
probabilities = tf.nn.softmax(logits)
# サマリのいろいろ
tf.summary.scalar('loss', loss)
tf.summary.scalar('accuracy', accuracy)
merged_summary_op = tf.summary.merge_all()
# top-kアルゴリズムで予測
predicted_val_top_k, predicted_index_top_k = tf.nn.top_k(probabilities, k=top_k)
# top-kアルゴリズムの精度
accuracy_in_top_k = tf.reduce_mean(tf.cast(tf.nn.in_top_k(probabilities, labels, top_k), tf.float32))
セッション処理
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
マルチスレッド処理
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
saver = tf.train.Saver()
try:
while not coord.should_stop():
train_images_batch, train_labels_batch = sess.run([train_images, train_labels])
feed_dict = {images : train_images_batch,
labels : train_labels_batch,
keep_prob : 0.8}
_, loss_val, train_summary, step = sess.run([train_op, loss, merged_summary_op, global_step], feed_dict=feed_dict)
except tf.errors.OutOfRangeError:
...
saver.save(sess, os.path.join(checkpoint_directory, 'cnn-test'),
global_step=global_step)
finally:
coord.request_stop()
coord.join(threads)
画像認識
準備した認識用のファイルを実行します。
ckpt = tf.train.latest_checkpoint(checkpoint_directory)
if ckpt:
saver.restore(sess, ckpt)
predict_val, predict_index = sess.run([predicted_val_top_k, predicted_index_top_k],
feed_dict={images: temp_image, keep_prob: 1.0})
文字から音声へ変換
認識された文字列のピンイン音声を合成します。この音声変換には、ピンインのサンプル音声は予め録音する必要です。中国語の声調が4種類なので、各ピンインの単語は4つを用意しないといけません。例えば、「ni」の音声ファイルは「ni1.wav」、「ni2.wav」、「ni3.wav」と「ni4.wav」のように録音する必要があります。この実装の場合に、録音したファイルを「dicionary_path」に置いています。
from pydub import AudioSegment
from pypinyin import lazy_pinyin, TONE3
...
def get_voice_dictionary(dicionary_path):
voice_file_list = [f for f in os.listdir(dicionary_path) if f.endswith('.wav')]
voice_dictionary = {}
for voice_file in voice_file_list:
item_name = voice_file[:-4]
voice_handle = AudioSegment.from_wav(os.path.join(dicionary_path, voice_file))
voice_dictionary.setdefault(item_name, voice_handle)
return voice_dictionary
def transfrom_word_to_voice(chinese_sentence, dicionary_path, output_path):
pinyin_list = lazy_pinyin(chinese_sentence, TONE3)
voice_dictionary = get_voice_dictionary(dicionary_path)
voice = AudioSegment.empty()
for pinyin in pinyin_list:
pinyin_voice = voice_dictionary.get(pinyin)
voice = voice.append(voice, crossfade=100)
voice.export(output_path, format='wav')
音声再生
生成した音声ファイルを再生します。
from pydub import AudioSegment
from pydub.playback import play
def play_voice(input_path):
voice = AudioSegment.from_wav(input_path)
play(voice)
結果と結論
実際の精度について、こちらのグラフを参考してください。
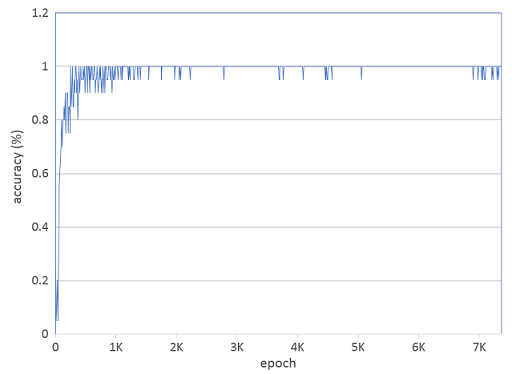
なんやかんやノイズがモヤモヤとされています。使っていたデータが少ないか、めちゃくちゃ汚い手書き文字が少し混ぜているから、精度に影響を与えていますかね。
最後に、僕の感想です。機械学習はそんなに難しくないですが、普通のプログラマはこれに関する数学的な知識は深く理解する必要がありません。現在、世界中の研究者はこのテーマの研究について、熱心に、積極的に行っています。それらの成果を参考し、実在するシナリオの要素と混じって考えたら、きっと役に立つでしょう。
(文面の不備や誤りがございましたら、ご指導のほどよろしくお願いいたします。)