この記事について
この記事はPythonのPandasを用いた情報処理 -DataFrame編-の続きです。具体的なデータを使って解析の練習をしていきます。コードはCourseraで公開されているMichigan大学の講座を参考にしています。
Coursera : Introduction to Data Science in Python
実行環境
- Windows10
- Python3.6
- Jupyter Notebook
使用データ
アメリカの国勢調査局のデータ(2010-2015)
https://drive.google.com/open?id=1WYfbEsv_uEP0KTGoOGg7v_cjetn-zb8V
データの確認
今回練習に使うデータの確認です。
import pandas as pd
df = pd.read_csv("census.csv")
df.head()
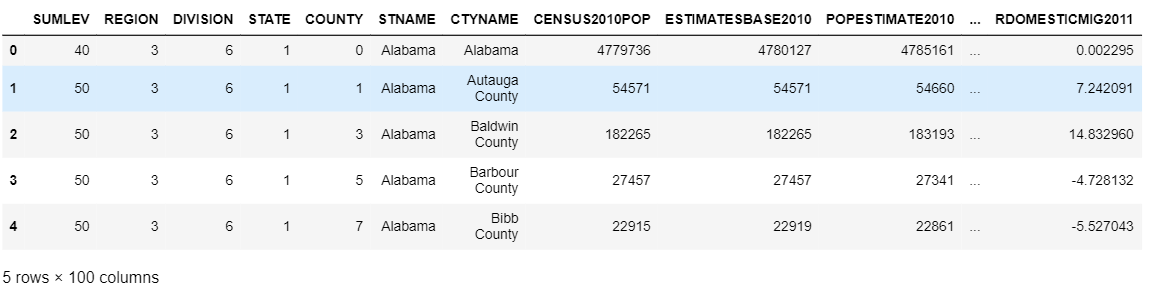
画面に入りきらないので1画面に入る分を載せました。
今回の練習で使う分のカラムが示している内容は下のようになっています。
- SUMLEV : 区分、州の場合は40,都市の場合は50
- STNAME : 州の名前
- CTYNAME : 市の名前
- BIRTH〇〇〇〇 : 〇〇〇〇年に生まれた人数
- POPESTIMATE〇〇〇〇 : 〇〇〇〇年の推定人口
使うカラムを抜き出す
100カラムもあるデータのうち一部しか使わないのに丸々全部のデータを使うのは面倒なので、使う分だけ取り出します。
columns_to_keep = ['SUMLEV',
'STNAME',
'CTYNAME',
'BIRTHS2010',
'BIRTHS2011',
'BIRTHS2012',
'BIRTHS2013',
'BIRTHS2014',
'BIRTHS2015',
'POPESTIMATE2010',
'POPESTIMATE2011',
'POPESTIMATE2012',
'POPESTIMATE2013',
'POPESTIMATE2014',
'POPESTIMATE2015']
df2 = df[columns_to_keep]
同じ州の中には多くの都市がありますので、データを表示すると同じ州が何回も表示され、見にくいです。これを改善します。州の名前と都市の名前をインデックスにすれば見やすくなりそうです。
df3 = df.set_index(['STNAME', 'CTYNAME'])
df3.head()
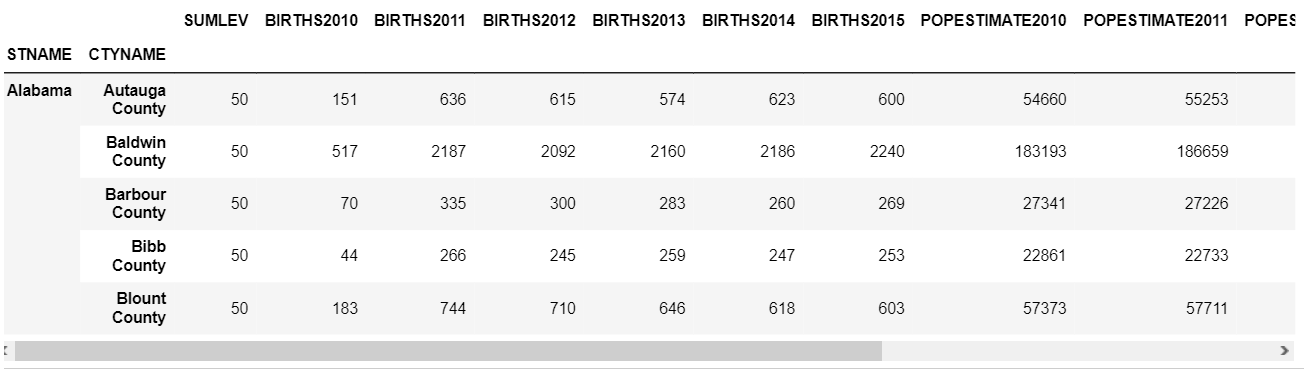
最初の5行だけ見てみてもわかりませんが、この中にはSUMLEV=40のものが混ざっています。解析の際に、州と都市が混ざっていては解析に不便です。都市だけ抜き出します。
df4 = df3[ df3['SUMLEV']==50 ] #df3['SUMLEV']==50がtrueの行だけ抜き出す
解析を行う
データの整理ができたので、試しにいろいろ簡単な解析してみます。まずは出生数に着目してみます。
出生数の解析
2010年に出生数が最も大きかった都市を調べてみます。
df4['BIRTHS2010'].max()
# -> 31740
df4['BIRTHS2010'].idxmax() #'BITHS2010'が最大になるときのインデックスを表示
# ->('California', 'Los Angeles County')
ロサンゼルスで30000人以上が生まれており、それがこの年の最大であることがわかります。逆に最小はどこで何人なのかも気になります。
df4['BIRTHS2010'].min()
# -> 0
df4['BIRTHS2010'].idxmin() #'BITHS2010'が最小になるときのインデックスを表示
# ->('Colorado', 'Hinsdale County')
ゼロ...こんなのあるんだ。気になるので他の情報も見てみます。
df4.loc['Colorado', 'Hinsdale County']
# ->
# SUMLEV 50
# BIRTHS2010 0
# BIRTHS2011 5
# BIRTHS2012 6
# BIRTHS2013 9
# BIRTHS2014 9
# BIRTHS2015 6
# POPESTIMATE2010 844
# POPESTIMATE2011 827
# POPESTIMATE2012 798
# POPESTIMATE2013 808
# POPESTIMATE2014 781
# POPESTIMATE2015 774
人口が1000人に満たない、小さな地域であることがわかります。ググってみたら緑豊かな風景が広がっていました。
2010年から2015年までの出生数の変化を見てみます。
df4['BirthChange'] = df4['BIRTHS2015'] - df4['BIRTHS2010']
df4['BirthChange'].max()
# -> 98330
df4['BirthChange'].idxmax()
# -> ('California', 'Los Angeles County')
df4['BirthChange'].min()
# -> -16
df4['BirthChange'].idxmin()
# -> ('Virginia', 'Manassas Park city')
大都市では人口増加が激しい一方、地方では人口が減少している、日本と同じような状況がアメリカでも生じていることが想像できます。ただ、アメリカでは最も出生数が減っているところでも-16なので、全体的に人口が増加しているといえます。これを確かめてみます。
人口変化
アメリカ全体の人口はPOPESTIMATEの数字の各都市に対する和を求めればわかります。
import matplotlib.pyplot as plt
pop = []
cols = ['POPESTIMATE2010', 'POPESTIMATE2011', 'POPESTIMATE2012', 'POPESTIMATE2013', 'POPESTIMATE2014','POPESTIMATE2015']
for col in cols:
pop.append(df4[col].sum())
year = [2010, 2011, 2012, 2013, 2014, 2015]
plt.plot(year, pop, '-o')
plt.title('Population in America')
plt.xlabel('Year')
plt.ylabel('Population')
plt.show()
プロットしてみた結果が下のようになっています。
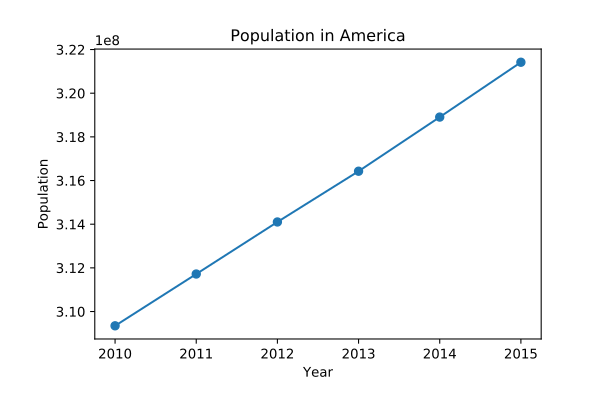
縦軸が0からになっていないので急激に増加しているように見えてしまっていますが実際は3%の増加です。このようにアメリカでは日本とは異なり人口が順調に増加していることがわかります。
都市ごとの出生数の変化
ここまで簡単な解析をしてみて、各都市ごとの人口変化をもう少し詳しく知りたくなりました。しかしながら、人口変化(POPESTIMATE)をただ調べただけでは人口増加に寄与するファクターが少なくとも移民の移住によるものと、出生によるものの2つあります。なるべくファクターは少ないほうがわかりやすいので、今回は人口変化ではなく出生数の変化を各都市で調べることにしました。
なるべくわかりやすい結果をまとめたいので、新しくデータを用意しました。それが各都市の緯度・経度のデータです。このデータは以下のサイトから入手しました。
gaslamp media:
https://www.gaslampmedia.com/download-zip-code-latitude-longitude-city-state-county-csv/
このデータは下のような情報を含んでいます。
data = pd.read_csv('zip_codes_states.csv')
data.head()

これを今まで解析してきたデータと統合します。
data['county'] += ' County'
data2 = data[['county', 'latitude', 'longitude']]
data3 = data2.groupby('county').agg(np.mean)
data4 = data3.reset_index()
df5 = df4.reset_index().rename(columns={'CTYNAME' : 'county'})
data5 = pd.merge(df5, data4, how='inner')
data6 = data5[['STNAME', 'county', 'BirthChange', 'latitude', 'longitude']]
data6.head()
dataをみると、countyの列がdf4のCTYNAMEに対応していることがわかります。しかし、df4では都市の名前の後に"County"がついているのに対してdataのほうではそれがありません。最初の行ではそれの処理をしています。また、rename()の行で、カラム名をcountyに統一しています。
data2ではdataのなかから使うカラムだけ抜き出しています。さらに、このデータはもともと郵便番号のデータなので、同じ都市でも郵便番号の数だけ同じ都市がデータ中に出てきます。その処理をしているのが.groupby()の行です。countyに対してデータをまとめ、まとめた後の緯度・経度の値には平均(np.mean)を使うようにしています。
そしてmerge()の行で2つのデータの統合をしています。2つのデータはcountyが共通しているのでこれを軸にして統合しています。how=innerを指定しているので、統合後のデータでは両方のデータに存在しているcountyのみ残っています。
ではこの処理によってできたdata6を使ってアメリカの出生数の変化を都市別に視覚化します。
data7 = data6.groupby('county').agg(np.mean)
inc10000 = data7[data7['BirthChange'] >= 10000] #出生数が10000以上増加している都市
inc1000 = data7[(data7['BirthChange'] >= 1000) & (data7['BirthChange'] < 10000)]
inc100 = data7[(data7['BirthChange'] >= 100) & (data7['BirthChange'] < 1000)]
dec_data = data7[data7['BirthChange'] < 0]
plt.plot(inc100['longitude'], inc100['latitude'], 'o', color='green')
plt.plot(inc1000['longitude'], inc1000['latitude'], 'o', color='orange')
plt.plot(inc10000['longitude'], inc10000['latitude'], 'ro')
plt.plot(dec_data['longitude'], dec_data['latitude'], 'bo')
plt.xlim([-130,-65])
plt.ylim([25,50])

出生数が10000以上増加している都市が赤色、1000人以上がオレンジ、100人以上が緑、減少しているのが青色であらわしています。減少している都市がないように見えますが、データ上は2つあります(隠れて見えませんが。。。)。やはり出生数の増加が激しいのは西海岸カリフォルニア州や右上のワシントン・ニューヨークといった大都市近傍であることが読み取れます。
終わりに
今回は、DataFrameを使って簡単なデータ解析をしてみました。最初にCouseraの講座を参考にしていると書きましたが、最後のほうは完全に逸脱してしまいました(笑)。
次回は、機械学習などもう少し実践的な方法を取り入れられれば良いと考えています。