この記事について
前回のSeries編の続きです。
環境
- Windows10
- Python 3.6
- Juoyter notebook
Series編と同様、Jupyter Notebookで実行すること想定しています。また、前回と同様にpandasは次のようにインポートします。
import pandas as pd
pd.DataFrameとは
前回の記事では、Seriesを扱いました。Seriesでは、インデックスがあり、それに対応するデータ(数値や何かの名前など)が存在していました。これを表であらわすと、例えば下のようになります。
| Golf | Scotland |
| Sumo | Japan |
| Tekwondo | Korea |
コードで書くと、
sports = { 'Golf' : 'Scotland',
'Sumo' : 'Japan',
'Tekwondo' : 'Korea'
}
s = pd.Series(sports)
みたいな感じです。これに対して、DataFrameでは列に対しても名前が付きます。例えばこんな感じのものを想像するとわかりやすいかもしれません。
| Sports | Country | |
|---|---|---|
| 0 | Golf | Scotland |
| 1 | Sumo | Japan |
| 2 | Tekwondo | Korea |
この構造を作るには、例えば下のようなコードを書けばよいです。
sports = ['Golf', 'Sumo', 'Tekwondo']
country = ['Scotland', 'Japan', 'Korea']
df = pd.DataFrame({'Sports' : sports, 'Country' : country})
この記事では、DataFrameに話を限定して説明をしていきます。
DataFrameの基本的な扱い
SeriesからDataFrameを作る
いくつかのSeriesを結合することでDataFrameを作ることができます。
purchase_1 = pd.Series({'Name': 'Chris',
'Item Purchased': 'Dog Food',
'Cost': 22.50})
purchase_2 = pd.Series({'Name': 'Kevyn',
'Item Purchased': 'Kitty Litter',
'Cost': 2.50})
purchase_3 = pd.Series({'Name': 'Vinod',
'Item Purchased': 'Bird Seed',
'Cost': 5.00})
df = pd.DataFrame([purchase_1, purchase_2, purchase_3], index=['Store 1', 'Store 1', 'Store 2'])
# ->
# Cost Item Purchased Name
# Store 1 22.5 Dog Food Chris
# Store 1 2.5 Kitty Litter Kevyn
# Store 2 5.0 Bird Seed Vinod
リストからDataFrameを作る
これは最初に紹介した方法です。いくつか方法があります。
item = [22.5, 2.5, 5.0]
purchased = ['Dog Food', 'Kitty Litter', 'Bird Seed']
name = ['Chris', 'Kevyn', 'Vinod']
index = ['Store1', 'Store1', 'Store2']
# 方法1
df = pd.DataFrame({'Item' : item, 'Purchased' : purchased, 'Name' : name}, index=index)
# 方法2
column = ['Item', 'Name', 'Purchased']
df2 = pd.DataFrame([item, purchased, name], columns=column, index=index)
数値ならばリストではなくてnumpy.ndarrayからでも作れます。数値計算をした結果を表としてまとめたいときにはこの方法が便利でしょう。
カラムを指定するときにはcolumns=とcolumnが複数形であることに注意です。
DataFrameからデータを取り出す
Seriesと同様にlocが使えます。
df.loc['Store2']
# ->
# Cost 5
# Item Purchased Bird Seed
# Name Vinod
# Name: Store 2, dtype: object
df.loc['Store1']
# ->
# Cost Item Purchased Name
# Store 1 22.5 Dog Food Chris
# Store 1 2.5 Kitty Litter Kevyn
df.loc['Store1', 'Cost'] #Numpy.array的な取り出し方?
# ->
# Store 1 22.5
# Store 1 2.5
# Name: Cost, dtype: float64
カラムとインデックスを入れ替える
Numpyと同様に、.Tを使ってカラムとインデックスを入れ替える(転置する)ことができます。
df.T
# ->
# Store 1 Store 1 Store 2
# Cost 22.5 2.5 5
# Item Purchased Dog Food Kitty Litter Bird Seed
# Name Chris Kevyn Vinod
行を落とす
データ処理をしていると、データが不完全で抜け落ちがあるデータに出会うこともあります。そのようなデータに対する対処法としてはいくつもの方法がありますが、一番簡単なものは欠損があるものは捨ててしまうことです。
df.drop('Store1')
# ->
# Cost Item Purchased Name
# Store 2 5.0 Bird Seed Vinod
df #df自体に変化はない。
# ->
# Cost Item Purchased Name
# Store 1 22.5 Dog Food Chris
# Store 1 2.5 Kitty Litter Kevyn
# Store 2 5.0 Bird Seed Vinod
欠損値を落としたDataFrameを保存したいときにはdf2 = df.drop()などとして新たなDataFrameを作ります。
列を落とす
列を落とすにはdelを使います。
del df2['Name']
# ->
# Cost Item Purchased
# Store 2 5.0 Bird Seed
csvファイルからDataFrameを作る
データ処理をしようとすると、csvファイルをとってきて、それを解析することがあります。pandasにはcsvを処理するための機能も備えています。
例えば、olympics.csvというファイルがあったとしてこれを読み込みましょう(元データ:Wikipedia)。これにはpd.read_csv()を使います。
df = pd.read_csv('olympics.csv')
df.head() #先頭5行を表示する
列数が多く、コメントアウトして表示するには無理があるのでNotebookのスクリーンショットを載せます。
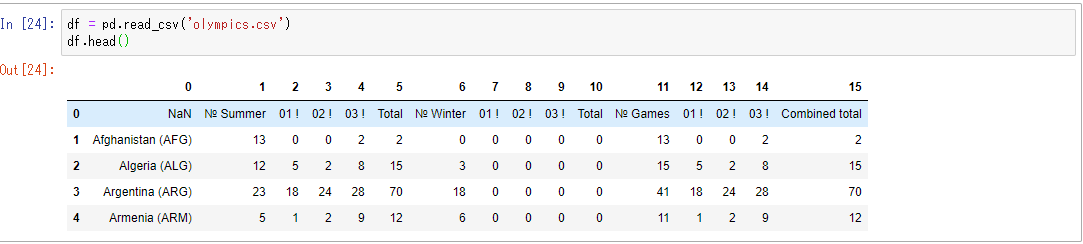
無事、作れています。しかし、今のままではインデックスもカラムも通し番号になってしまっています。これを解消します。
df = pd.read_csv('olympics.csv', index_col=0, skiprows=1)
df.head()
まず、index_col=0で0列目(カラム0)をインデックスとして用いると宣言します。さらにskiprows=1で先頭から1行飛ばして読み込むことを宣言します。その結果は下のようになります。

インデックスはちゃんとしたものになりました。
カラム名の数字は何を意味しているのでしょうか?これはさすがに元データの入手元から確かめるしかありません。どうやら01は金メダルの個数、02は銀メダル、03は銅メダルのようです。これをもとにカラム名を書き換えます。それにはrenameを使います。
for col in df.columns:
if col[:2]=='01':
df.rename(columns={col:'Gold' + col[4:]}, inplace=True)
if col[:2]=='02':
df.rename(columns={col:'Silver' + col[4:]}, inplace=True)
if col[:2]=='03':
df.rename(columns={col:'Bronze' + col[4:]}, inplace=True)
if col[:1]=='№':
df.rename(columns={col:'#' + col[1:]}, inplace=True)
df.head()
各行にあるinplace=Trueというのはrenameによる変更がdropの時のように一時的なものにならないようにするためのオプションです。
この結果は下のようになりました。

これでデータはだいぶきれいになりました。
終わりに
今回は、DataFrameの説明と、簡単なデータの前処理を説明しました。次回は、実際のデータを用いて解析を行う手法を説明したいと思います。