2023年8月にPython in Excelが発表されました。
これにより、Excelでscikit-learnやpandas(Pythonのライブラリ)を使うことができ、簡単に機械学習を実装できるようになりました。
なので今回は機械学習においてHello World!の位置づけ(入門者向け)にあるアヤメの分類をやっていきたいと思います。
Python in Excelの始め方はこちら
Python環境(Google Colabratory)のアヤメの分類はこちら
動画Ver
YouTubeにこの記事の内容を動画にしたものがあります。
動画で流れを確認したい方はこちらをご活用ください。
概要
アヤメの分類は機械学習の中でも教師あり学習の範囲になります。
教師あり学習とは、学習データに答えを付けた状態で学習をさせる方法です。
つまり、機械学習モデルに対して答え付きでデータを渡し学習をさせ、未知のデータに対して分類をさせます。
※同じ写真ばかり使っていますが実際は違うもの(データ)を準備します。
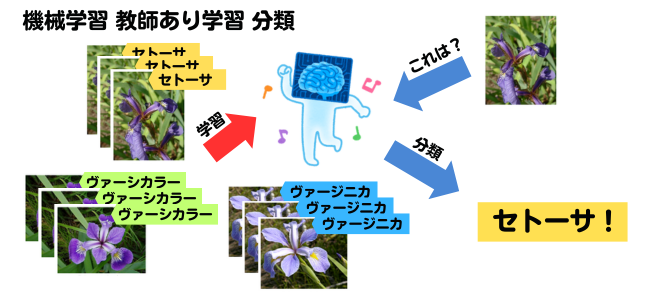
機械学習にはscikit-learnを使用します。機械学習ライブラリというもので、様々なアルゴリズムを使うことができますが、今回はサポートベクトルマシン(サポートベクターマシン)というアルゴリズムを使って分類を行います。
サポートベクトルマシンは簡単に言うと、データに対して境界線を引くことで分類をしていくアルゴリズムです。

Step1 機械学習に使うデータを準備する
機械学習を使うデータを準備していきます。ExcelでPythonを使うには=Py( とセルに入力するか、数式タブのPythonの挿入ボタンを押します。
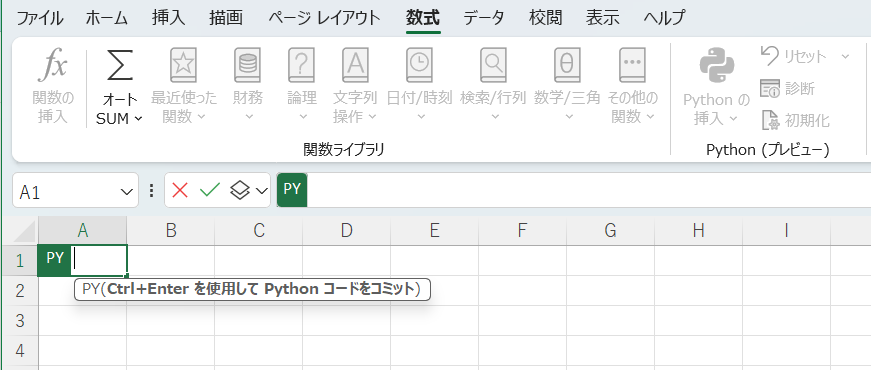
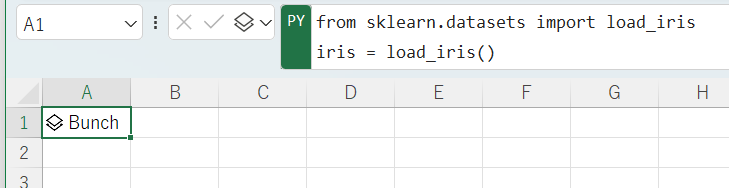
iris = load_iris()でアヤメのデータセットをダウンロードします。
この先importという単語が良く出てきますが、これはscikit-learnやpandasなどと言った便利な機能を持つものを使うために宣言をしています。
from sklearn.datasets import load_iris
iris = load_iris()
実行するとBunchと出力されます。Bunchとは束という意味でこの中には色々なデータが含まれています。このデータの中から必要なものだけ取り出していきます。
ここでpandasというライブラリを使用します。pandasは表形式を扱うライブラリで、2次元(Excelで言う表データ)のDataFrameと1次元のSeriesというものがあります。
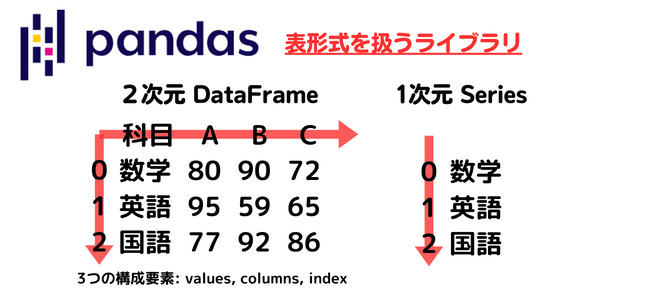
Bunchの中からアヤメの情報(がく片の長さ、がく片の幅、花びらの長さ、花びらの幅)とそれに対する答え(花の種類)を取り出します。
import pandas as pd
iris_data = pd.DataFrame(iris.data, columns=["がく片の長さ","がく片の幅","花びらの長さ","花びらの幅"])
iris_target = pd.DataFrame(iris.target, columns=["花の種類"])
iris_all = pd.concat([iris_data,iris_target], axis=1)
import pandas as pdでpandasを使えるようにしています。as pdとはpdという名前で使えるようにしており、Pythonは慣習的にこのように宣言する場合があります。(別にimport pandasでも構いません。)
pd.DataFrameでBunchの中にあるデータをDataFrameに変換しています。
pd.concatで2つのデータフレームを結合しています。(axis=1で横方向、axis=0で縦方向に結合)
セルにDataFrameと出力されます。Python形式で表示されているのでExcel形式に変換します。
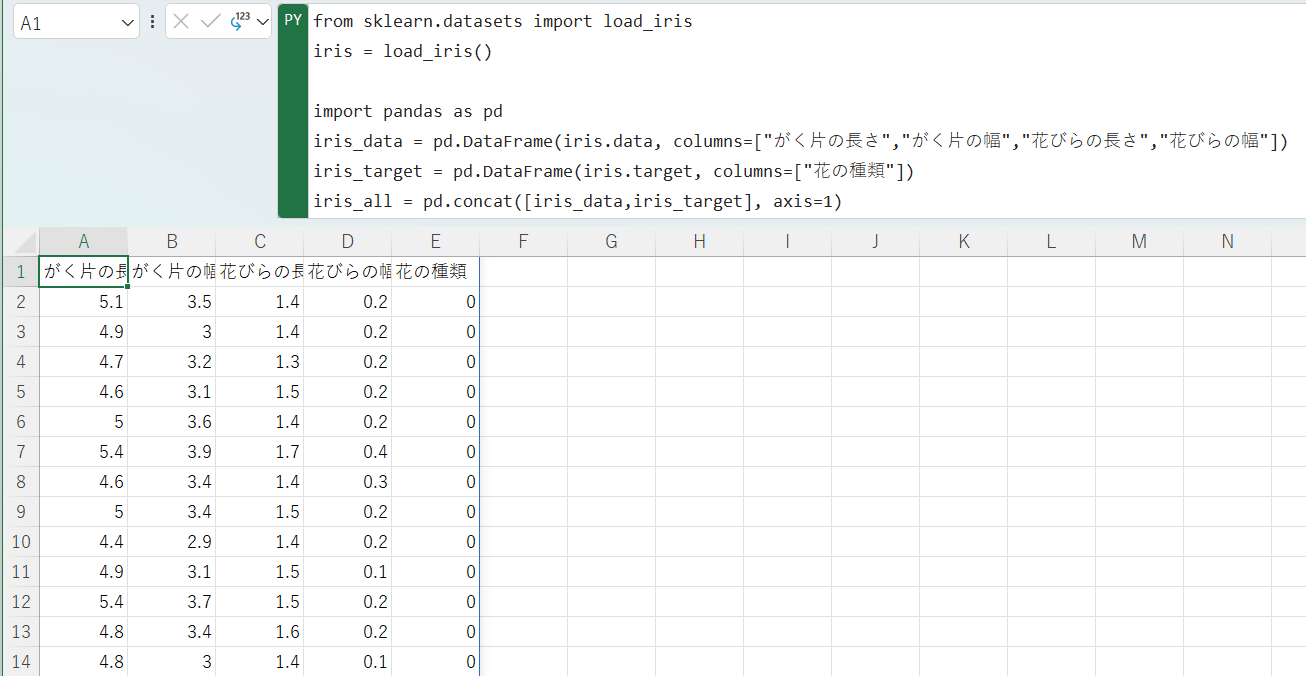
データを確認することができました。
次に、このデータを学習用とテスト用に分けます。scikit-learnにはtrain_test_splitというデータを分ける便利な機能があるのですが、どういうわけかPython in Excelで使うことができませんでした。(もし何か知っている方がいたら教えてください。)
なので今回はpandasを使って自力でデータを分割します。
iris_df = iris_all.sample(frac=1)
train = iris_df[:100]
test = iris_df[100:]
X_train = train.loc[:,["がく片の長さ","がく片の幅","花びらの長さ","花びらの幅"]]
y_train = train.loc[:,"花の種類"]
X_test = test.loc[:,["がく片の長さ","がく片の幅","花びらの長さ","花びらの幅"]]
y_test = test.loc[:,"花の種類"]
iris_df = iris_all.sample(frac=1)でデータをランダムに並べ替えます。
今回は、150ヶのデータセットになるので、学習用に100ヶ、テスト用に50ヶで分けます。(2行目と3行目)
そして分けたデータに対して、さらにアヤメの情報と答えで分けます。(4~7行目)
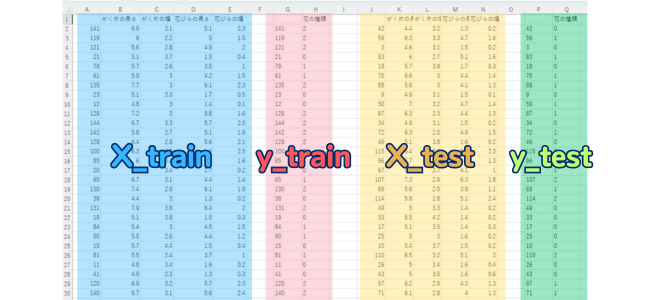
X_train,y_train,X_test,y_testをそれぞれを出力するとこんな感じ。
これでデータの準備は完了です!
Step2 機械学習を使って未知のデータを予測しよう
準備したデータを使って機械学習を実装していきます。
まずは学習用のデータを使って機械学習モデルを作ります。
from sklearn import svm
model = svm.LinearSVC(max_iter=1000)
model.fit(xl("B2:E101"), xl("H2:H101"))
max_iterは学習回数になります。model.fitで学習をさせていますが、xlでX_train,y_trainの範囲を指定しています。
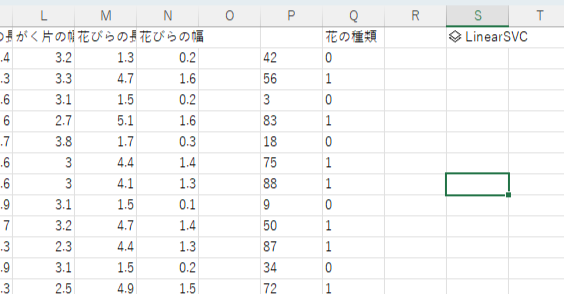
学習が完了するとLinearSVCと出力されます。
この機械学習モデルを使って未知のデータを予測をします。
pred = model.predict(xl("K2:N51"))
ans = pd.DataFrame(pred,columns=["推論結果"])
model.predictで先ほど作成したモデルを使って推論を行っています。xlにはX_testを指定します。
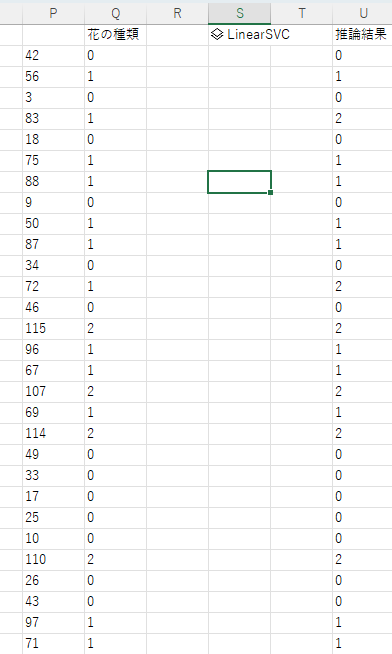
出力結果を確認すると、ある程度正解していることが分かります。(左側がy_testで右側が推論結果になります。)
最後に正答率を確認します。
from sklearn.metrics import accuracy_score
accuracy_score(xl("Q2:Q51"), pred)
xlはy_testを指定します。
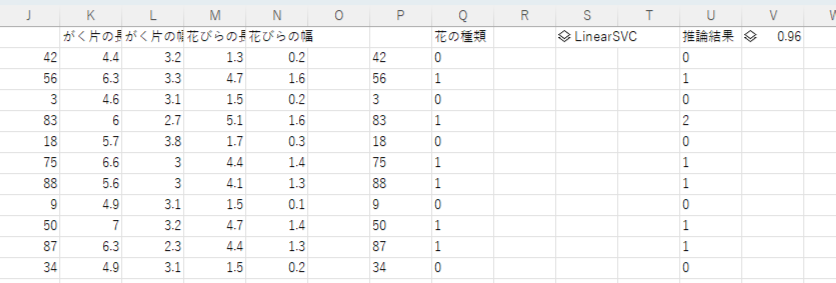
今回の正答率は96%(画面右上)でした。max_iterの回数を上げればもう少し精度が上がるかもしれません。(別のアルゴリズムを使うのもありです。)
おわりに
今回はPython in Excelを使ってアヤメの分類を行いました。
比較的短いコードで実装できるので、興味のある方は是非挑戦してみてください。(scikit-learnには他のサンプルデータセットもあります。)
YouTubeにて、Pythonチュートリアル(公式ドキュメント)を使ってPythonの基礎文法を解説しています。
こちらもよろしければご活用ください。
あわせて読みたい