はじめに
Qiita初心者の@pyopp8128と申します。
これまでに記事を2本ほど投稿してみたのですが、他人に見てもらえる記事というのはそう簡単に書けるものでもなく、「あ~楽してLGTM沢山貰いたいな~」などと言っているところでしたが、じゃあ LGTMが多くつく記事ってどんな記事だ? という疑問に至りました。
そこで、記事本文を自然言語処理により解析し、LGTMがつく/つかないを判別する機械学習モデルができないか を試してみることにしました。
本記事の内容は以下の通りです。
- LGTMの数を基準に、Qiita上の記事がバズるかバズらないかを判別するAI を作ったよ
- BERTのファインチューニングにより、Qiita中の記事がLGTM>100かどうか判別する2クラス分類深層学習モデルを作成したよ
- Qiita APIを通して取得した約10,000記事のデータセットを用いてモデル構築&性能評価を行ったよ
- 性能評価の結果、正解率81%、AUC0.89とまあまあのモデルが出来たよ
問題設定
本記事では、記事全文(テキストデータ)を入力として高LGTM群/低LGTM群を判別する2クラス分類問題 を解く。そこで、LGTMの多い記事の特徴を考えてみると、
- 内容の需要が高い
- 分かりやすい
の2点が主軸になるのではないかと考えられる。
前者は突き詰めて言えば「話題」なので、古典的なトピック分析などの手法でも対応できる可能性がある。
しかし、いくら需要の高い話題の記事でも、難解なものにLGTMはつきにくいだろう。
すなわち後者の要素も必須であるが、「分かりやすさ」を構成するのは「表現力」や「論理構成」といった抽象的な概念であり、これらを機械が学習するためには。抽象的で高度な文章把握力が必要になる可能性が高い。
そのため、本解析では自然言語処理のトップランナーともいえるBERTを利用することにした。
実行環境
- Google Colaboratory
- Python 3.7.13
- Pytorch 1.11.0+cu113
- Numpy 1.21.6
- transformers 4.20.1
- fugashi 1.1.2
- unidic-lite 1.0.8
データ取得
取得方法
Qiita APIを使用して記事全文とそのLGTM数を取得する。Qiita APIのドキュメントはこちら。本筋ではないのでデータ取得方法の詳細は割愛するが、以下の条件でデータを取得した。
- 以下の2群に分けてデータを取得した
- 高ストック群:ストック数が100を超えている記事
- 低ストック群:Qiitaに公開されている全ての記事
- 上の2群に対して、2022年06月19日18:16:37時点での最新記事から5,000記事ずつ取得した
- 取得した合計10,000記事から重複を削除し、取得時点での LGTM数が100を超えているもの を高LGTM群、それ以外を低LGTM群とした
- 記事本文のみ を解析対象とし、HTMLタグやコードブロックは前処理により削除した
なお、APIでのデータ取得時にLGTM数ではなくストック数を使っているのは、Qiita APIではどうやら検索時にLGTM数は条件指定できないらしいことが分かったからである。ストック数とLGTM数はだいたい比例しているだろうという仮定のもと、ストック数による検索を実施した。
データセット概要
dataset.csvに全データが格納されている。
# データセット読込
dataset = pd.read_csv('dataset.csv')
# 重複行をIDで判別して削除
dataset = dataset.drop_duplicates(subset='id')
# 2クラスに分割
dataset_pos = dataset[dataset['likes_count']>100] # 高LGTM群
dataset_neg = dataset[dataset['likes_count']<=100] # 低LGTM群
#
print(dataset_pos.head(5))
実行結果 (一部カラムをマスク処理)
id title created_at userid \
710 ******************** ****** 2022-06-13T23:58:07+09:00 ******
800 ******************** ****** 2022-06-13T09:31:51+09:00 ******
997 ******************** ****** 2022-06-12T08:31:38+09:00 ******
1458 ******************** ****** 2022-06-08T14:26:46+09:00 ******
1704 ******************** ****** 2022-06-06T14:57:11+09:00 ******
likes_count body
710 403 はじめに 「なんか、レビューのたびに変数名を指摘されてる気がする...」 「日本人なんだか...
800 143 はじめに 今回は「エンジニア1年生の自分に読んでもらいたい書籍」を紹介します。 自分は20...
997 682 わかりにくいシステム構成図とは こんなシステム構成図を書いてないでしょうか? このシステ...
1458 246 動機 これまでの自分の失敗だったり、レビューの中で感じたり、 書籍などで読んだ知識のまとめ...
1704 113 この記事は、勉強会で発表したスライドを Qiita Engineer Festa 向けに書き...
title列に記事タイトル、likes_count列にLGTM数、body列に記事本文が入っている。
LGTM数や記事の長さの簡単な分布を調べてみる。
# 本文の長さの列を追加
dataset_pos['body_length'] = list(map(len, dataset_pos['body'].to_list()))
dataset_neg['body_length'] = list(map(len, dataset_neg['body'].to_list()))
# 表示
print('positive:')
print(dataset_pos.describe())
print(' ')
print('negative:')
print(dataset_neg.describe())
実行結果
positive:
likes_count body_length
count 4751.000000 4751.000000
mean 379.264155 4730.130920
std 443.722346 5328.789305
min 101.000000 1.000000
25% 157.000000 1911.000000
50% 231.000000 3350.000000
75% 413.500000 5554.000000
max 6729.000000 94139.000000
negative:
likes_count body_length
count 5230.000000 5230.000000
mean 5.746654 1600.242639
std 19.780432 2193.336845
min 0.000000 1.000000
25% 0.000000 413.250000
50% 0.000000 973.000000
75% 1.000000 2004.000000
max 100.000000 46460.000000
高LGTM群が4,751記事、低LGTM群が5,230記事だった。
それにしても LGTMが0の記事の多さよ。低LGTM群の少なくとも半数以上がLGTM = 0であることが分かる。かくいう私も 一度もLGTMもらったことないのだけど。
また直感的にも分かる通り、高LGTM群の方が記事本文が長い傾向にあり、それだけ内容が充実していると考えられる。
BERTで2クラス分類
BERTとファインチューニング
BERT (Bidirectional Encoder Representations from Transformers) は深層学習モデルの一種で、自然言語処理の分野では高い注目を浴びているモデルである。BERTの解説は多数存在する解説記事に譲るが、BERTの大きな特徴のひとつとして、大規模データで事前学習されたモデルを、個別のタスクに合わせて追加学習(ファインチューニング)して使用する という点がある。私のようなデータサイエンティストの端くれにもならない一般人でも、公開されている事前学習済みのBERTをダウンロードすることで、低コストまたは無料で高性能な自然言語AIを作ることができる(かもしれない) というのは、非常に大きなメリットだと思われる。
Hugging Face
Hugging Faceは最新のモデルを多数取り揃えた深層学習プラットフォームで、様々なモデルを比較的簡単に自分の環境で動かす ことができる便利ツールである。自然言語処理であれば、transformersというライブラリを使えば、わりと簡単にBERTの学習を行える。pip経由でインストール可能。
今回は、Hugging faceから使える多数のBERTの中でも、日本語に対応したBERTとして、東北大学の乾研究室が公開しているBERT(https://github.com/cl-tohoku/bert-japanese)を使用する。
実装
それではここから、バズり記事判別AI(今名付けた)を実装していく。先述のデータセットがdataset.csvに保存されている設定で以降のプログラムを記述する。
なお、Google Colaboratory上で動かすことを想定している。まずは以下のコマンドを実行し、Colab上に必要モジュールをインスト―ルする。
!pip install -q transformers # Hugging FaceのAPI
!pip install -q fugashi # 形態素解析ツール
!pip install -q unidic-lite # 形態素解析用の辞書
下準備・前処理
必要モジュールのインポートと、データの読み込み・加工を行う。
# モジュールのインポート
import os
import pandas as pd
import numpy as np
import torch
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score
from transformers import AutoTokenizer, BertForSequenceClassification
from transformers import TrainingArguments, Trainer
# データセット読込
dataset = pd.read_csv('dataset.csv')
# 重複行をIDで判別して削除
dataset = dataset.drop_duplicates(subset='id')
# 2クラスに分割
dataset_pos = dataset[dataset['likes_count']>100]
dataset_neg = dataset[dataset['likes_count']<=100]
# 訓練とテストに分割
dataset_pos_train, dataset_pos_test = train_test_split(dataset_pos, train_size=0.5, random_state=0)
dataset_neg_train, dataset_neg_test = train_test_split(dataset_neg, train_size=0.5, random_state=0)
# それぞれのサンプル数を確認
print('positive:')
print(len(dataset_pos_train), len(dataset_pos_test))
print('negative:')
print(len(dataset_neg_train), len(dataset_neg_test))
実行結果
positive:
2375 2376
negative:
2615 2615
とりあえず訓練/テストの 分割比率は半々 にしておいた。
positiveとnegativeの偏りはそれほど大きくないので、あまり気にせず進めて良さそうだ。
def extract_dataset(pos, neg, random_state=0):
'''
2クラスのデータを結合し、
データセットとなるテキストとラベルを準備する
--- Inputs ---
pos, neg : pandas.DataFrame
データセットから選択した各クラスのデータ
--- Returns ---
texts : list
テキストのリスト
labels : list
pos = 1, neg = 0としてtextsの位置に対応づけたリスト
'''
# データフレームを結合し、ラベルの列を追加
posneg = pd.concat([pos, neg])
posneg['label'] = [1 for _ in range(len(pos))] + [0 for _ in range(len(neg))]
# シャッフルしておく(transformers側でされているのか不明なため)
# 適当に乱数を発生させ、その大小で並べ替える
np.random.seed(random_state)
posneg['random_number'] = np.random.rand(len(posneg))
posneg_sorted = posneg.sort_values('random_number')
# 値の取り出し
texts = posneg_sorted['body'].to_list()
labels = posneg_sorted['label'].to_list()
return texts, labels
texts_train, labels_train = extract_dataset(dataset_pos_train, dataset_neg_train)
texts_test, labels_test = extract_dataset(dataset_pos_test, dataset_neg_test)
print(len(texts_train), len(texts_test))
実行結果
4990 4991
訓練データは4,990記事、テストデータは4,991記事となった。
データセット準備・事前設定
GPUのセットアップや、データのトークナイズ(BERTなどの自然言語モデルがテキストを読める形にエンコードする)を行う。トークン最大長は512とした。
# GPUを利用する
device = "cuda:0"
# 東北大BERT
model_name = "cl-tohoku/bert-large-japanese"
# トークナイザ。モデルに合ったものが自動で選択される
tokenizer = AutoTokenizer.from_pretrained(model_name)
# tokenize
token_maxlen = 512 # トークン最大長
tokenized_train = tokenizer(texts_train, return_tensors='pt', padding=True, truncation=True, max_length=token_maxlen).to(device)
tokenized_test = tokenizer(texts_test, return_tensors='pt', padding=True, truncation=True, max_length=token_maxlen).to(device)
# ログ記録用にテストデータを縮小したものも作っておく
tokenized_val = tokenizer(texts_test[:500], return_tensors='pt', padding=True, truncation=True, max_length=token_maxlen).to(device)
後の学習時に、検証データとしてテストデータをそのまま渡してしまうと学習時間がかかり過ぎてしまう問題が発生したため、テストデータのうち500件のみを使用した検証用データも作っておいた。
次に、PytorchのDatasetクラスを継承したQiitaDatasetクラスを作成し、データセットを準備する。
class QiitaDataset(torch.utils.data.Dataset):
'''
Qiitaの記事のデータセットクラス
--- Attributes ---
encodings : tokenizerによる処理後のデータ
labels : 0 or 1のラベルデータ
'''
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['labels'] = torch.tensor(self.labels[idx])
return item
def __len__(self):
return len(self.labels)
# それぞれデータセットにする
train_dataset = QiitaDataset(tokenized_train, labels_train)
test_dataset = QiitaDataset(tokenized_test, labels_test)
val_dataset = QiitaDataset(tokenized_val, labels_test[:500])
事前学習済みのモデルをロードする。
from_pretrained()メソッドの引数で特に指定がなければ、自動で出力層が2クラス分類用に設定される。
# 学習済みモデル(東北大BERT)をロード
model = BertForSequenceClassification.from_pretrained(model_name).to(device)
実行結果
Some weights of the model checkpoint at cl-tohoku/bert-large-japanese were not used when initializing BertForSequenceClassification: ['cls.predictions.bias', 'cls.predictions.transform.dense.weight', 'cls.seq_relationship.weight', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.transform.dense.bias', 'cls.predictions.decoder.bias', 'cls.seq_relationship.bias', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.decoder.weight']
- This IS expected if you are initializing BertForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of BertForSequenceClassification were not initialized from the model checkpoint at cl-tohoku/bert-large-japanese and are newly initialized: ['classifier.bias', 'classifier.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
こんな風にログが出てきたら、ロードに成功していると思われる。
学習中のvalidationにAccuracyなどの評価関数を表示させたいので、compute_metrics()を作成してTrainerクラスに渡せるようにしておく。
softmax = torch.nn.Softmax(1)
def compute_metrics(pred):
'''
学習中に実行される評価関数
'''
# 各metricsが扱えるベクトルに変換
labels = pred.label_ids # 正解ラベル
outputs = softmax(torch.Tensor(pred.predictions))
probabilities = outputs[:,1] # 予測値(0~1の連続値)
preds = outputs.argmax(1) # 予測値(0 or 1のバイナリ)
# metricsを計算
acc = accuracy_score(labels, preds)
pre = precision_score(labels, preds)
rec = recall_score(labels, preds)
auc = roc_auc_score(labels, probabilities)
# 辞書として返す
return {
'accuracy': acc,
'precision': pre,
'recall': rec,
'auc': auc
}
ここで ややハマってしまった のだが、このcompute_metrics()に与えられるpredという引数は、label_idsやpredictionというattributeを持っており、それぞれ正解ラベルと予測値を意味している。これらのshapeはともに(-1, 2)の 2次元テンソルである 。1次元だと勘違いしていたために、意図せぬ挙動を起こしてしまった。
また、pred.predictionsは ソフトマックス関数をかける前の出力値である ことにも注意が必要である。
訓練
さていよいよ、モデルを訓練する。
バッチサイズは4としたが、これは4より大きくするとメモリに載らずエラーとなったためである。
また、バッチサイズが小さく、1エポックあたりの重み更新回数が多いため、学習率は小さめに$5 \times 10^{-6}$とした。
これらの設定で適当に3エポックほど回してみる。
# 訓練時のパラメータ
training_args = TrainingArguments(
output_dir='./results', # 結果の出力先
num_train_epochs=3, # エポック数
per_device_train_batch_size=4, # バッチサイズ(訓練時)
per_device_eval_batch_size=4, # バッチサイズ(検証時)
weight_decay=0.01, # 重み減衰率
save_total_limit=1, # チェックポイントを保存する数(?)
learning_rate=5e-6, # 学習率
dataloader_pin_memory=False,
evaluation_strategy="steps",
logging_steps=200,
logging_dir='./logs'
)
# モデルの訓練を行う
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
compute_metrics=compute_metrics
)
trainer.train()
実行結果
...
***** Running training *****
Num examples = 4990
Num Epochs = 3
Instantaneous batch size per device = 4
Total train batch size (w. parallel, distributed & accumulation) = 4
Gradient Accumulation steps = 1
Total optimization steps = 3744
...
del sys.path[0]
[3744/3744 1:43:38, Epoch 3/3]
Step Training Loss Validation Loss Accuracy Precision Recall Auc
200 0.613200 0.616104 0.708000 0.625731 0.922414 0.826573
400 0.549500 0.698150 0.706000 0.623907 0.922414 0.841884
600 0.591800 0.519343 0.768000 0.693333 0.896552 0.864803
800 0.536200 0.489937 0.776000 0.711268 0.870690 0.867891
1000 0.512400 0.595424 0.762000 0.681672 0.913793 0.871140
1200 0.494900 0.546745 0.796000 0.728873 0.892241 0.887207
1400 0.464000 0.612337 0.810000 0.766537 0.849138 0.886339
1600 0.493400 0.616295 0.804000 0.741007 0.887931 0.896037
1800 0.414400 0.687071 0.802000 0.733333 0.900862 0.892000
2000 0.442400 0.698275 0.802000 0.738351 0.887931 0.892193
2200 0.438600 0.654879 0.822000 0.776062 0.866379 0.895273
2400 0.479600 0.578558 0.830000 0.838710 0.784483 0.900010
2600 0.401800 0.642983 0.824000 0.813043 0.806034 0.898345
2800 0.256300 0.739498 0.830000 0.812766 0.823276 0.897573
3000 0.225000 0.943871 0.802000 0.733333 0.900862 0.899905
3200 0.302000 0.830640 0.818000 0.772201 0.862069 0.901361
3400 0.278800 0.909467 0.810000 0.758491 0.866379 0.898860
3600 0.328900 0.937071 0.808000 0.746377 0.887931 0.899720
***** Running Evaluation *****
...
2~3時間回したところで学習が終了した。
最終的な学習結果の評価には、trainer.evaluate()を使用する。
# 最終的な評価
trainer.evaluate(eval_dataset=test_dataset)
実行結果
***** Running Evaluation *****
Num examples = 4991
Batch size = 4
...
del sys.path[0]
[1248/1248 09:12]
{'epoch': 3.0,
'eval_accuracy': 0.8120617110799438,
'eval_auc': 0.8926348410813039,
'eval_loss': 0.9276387095451355,
'eval_precision': 0.7618353969410051,
'eval_recall': 0.8804713804713805,
'eval_runtime': 552.8911,
'eval_samples_per_second': 9.027,
'eval_steps_per_second': 2.257}
Accuracyが 81% 、AUCが 0.89 と、そこそこ上手く分類できているのではなかろうか。
モデル保存
ついでではあるが、transformersで作成したモデルの保存方法についても紹介しておく。
# 保存先ディレクトリを作成
savedir = 'bert/qiita_model'
os.mkdir(savedir)
tokenizer.save_pretrained(savedir) # トークナイザを保存
model.save_pretrained(savedir) # モデルを保存
# 保存したモデルをロードする場合、
# from transformers import AutoModelForSequenceClassification
# model = AutoModelForSequenceClassification.from_pretrained(savedir)
# でロード可能
考察
今回BERTモデルに渡したのは、最大長512のトークン列である。トークンとは大雑把に言えば「単語のようなもの」であるが、記事の大半はそれより多い単語数で構成されていることは容易に想像できる。実際、以下のコードで確認してみると、半数以上の記事はトークン列長が512以上であり、BERTに入力される前に後ろの方が切り落とされていることがわかる。
from matplotlib import pyplot as plt
# 最大長の指定無しでテストデータの記事500件をトークナイズ
tokenized = tokenizer(texts_test[:500])
# 記事500件のトークン列長のリスト
token_lengths = list(map(len, tokenized.input_ids))
# 横軸に累積度数、縦軸にトークン列長をとってグラフ描画
plt.plot(sorted(token_lengths), color='blue')
# トークン列長512のところに水平線を引く
plt.hlines(512, 0, len(token_lengths), color='r', linestyles='dashed')
plt.ylabel('token length')
plt.show()
実行結果
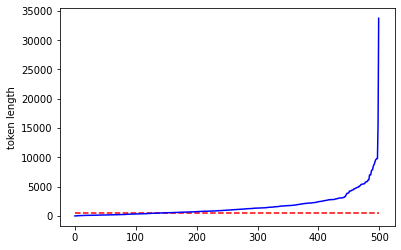
したがって、記事全文をBERTに入力する必要はなく、前半部だけでも分類可能 だと考えられる。
このことから、今回のトークン列最大長512というのは「記事の需要の高さ」や「記事の分かりやすさ」を十分把握できる長さなのかもしれない。もしそうであれば、記事本文の別々の箇所からトークン列を生成し、それぞれBERTに入力した結果を総合して判定する ことで、さらなる性能向上が見込めると考えられる。
ちなみに
作成した「バズり記事判別AI」に 本記事自身 を入力してみたところ・・・
def predict_article_buzz(article, model):
'''
記事がバズるかどうか判別する
--- Inputs ---
article : str
対象記事の本文
model : 訓練済みBERTモデル
'''
# 改行を空白に変換
article = article.replace('\n', ' ')
# トークナイズ
tokenized_article = tokenizer(article, return_tensors='pt', padding=True,
truncation=True, max_length=512).to(device)
# モデルに記事本文を入力し、出力を計算
with torch.no_grad():
outputs = model(**tokenized_article).logits # ロジット関数の出力値
article_prob = softmax(outputs) # ソフトマックスにかけて確率値を計算
article_pred = outputs.argmax(axis=1) # 予測値のラベル
# バズるかどうかを出力
if myarticle_pred == 1:
print('この記事はバズります!')
else:
print('この記事はバズりません…')
# 確率値を添えておく
print(f'prob.: {myarticle_prob.max():.4f}%')
# 本記事の冒頭 (トークン長が512を超えるのを確認できるところまで)
myarticle = '''
はじめに
Qiita初心者の@pyopp8128と申します。
これまでに記事を2本ほど投稿してみたのですが、他人に見てもらえる記事というのはそう簡単に書けるものでもなく、「あ~楽してLGTM沢山貰いたいな~」などと言っているところでしたが、じゃあ LGTMが多くつく記事ってどんな記事だ? という疑問に至りました。
そこで、記事本文を自然言語処理により解析し、LGTMがつく/つかないを判別する機械学習モデルができないか を試してみることにしました。
本記事の内容は以下の通りです。
LGTMの数を基準に、Qiita上の記事がバズるかバズらないかを判別するAI を作ったよ
BERTのファインチューニングにより、Qiita中の記事がLGTM>100かどうか判別する2クラス分類深層学習モデルを作成したよ
Qiita APIを通して取得した約10,000記事のデータセットを用いてモデル構築&性能評価を行ったよ
性能評価の結果、正解率81%、AUC0.89とまあまあのモデルが出来たよ
問題設定
本記事では、記事全文(テキストデータ)を入力として高LGTM群/低LGTM群を判別する2クラス分類問題 を解く。そこで、LGTMの多い記事の特徴を考えてみると、
内容の需要が高い
分かりやすい
の2点が主軸になるのではないかと考えられる。
前者は突き詰めて言えば「話題」なので、古典的なトピック分析などの手法でも対応できる可能性がある。
しかし、いくら需要の高い話題の記事でも、難解なものにLGTMはつきにくいだろう。
すなわち後者の要素も必須であるが、「分かりやすさ」を構成するのは「表現力」や「論理構成」といった抽象的な概念であり、これらを機械が学習するためには。抽象的で高度な文章把握力が必要になる可能性が高い。
そのため、本解析では自然言語処理のトップランナーともいえるBERTを利用することにした。
'''
# 果たしてバズるのか!?
predict_article_buzz(myarticle, model)
実行結果
この記事はバズります!
prob.: 0.9919%
やったね!