あまりQiita記事執筆は慣れてないのでご愛嬌ということで、、
Cloud Data Fusionとは
Googleの公式リファレンスによると、
Cloud Data Fusionは、データパイプラインを素早く構築、管理できる、クラウドネイティブのフルマネージド エンタープライズ データ統合サービスです。
(引用:https://cloud.google.com/blog/ja/products/data-analytics/set-up-a-secure-data-pipeline-easily-in-the-cloud)
一言で言うと、下図のようにGUIベースでパイプライン構築ができる非常に便利なサービスです。

(2021/08 現在、正直バグが多い気がする。今後の発展に期待です)
今回はGoogle Cloud Strage(以下:GCS)などに格納されているCSVを、BigQuery(以下:BQ)にデータを格納するパイプラインをノーコードで構築します。
前提
- GCPアカウント作成
- Cloud Data Fusionのインスタンス作成
- BQに格納したいcsvデータをGCSにアップロード
未作成の方はこちら→https://cloud.google.com/data-fusion/?hl=ja
パイプラインの作成
①データクレンジング
持ってきたデータからBQでの解析に必要なカラムだけに抽出します。
TOP画面で「Wrangle」を選択

GCSにアップロードしておいたCSVを選択すると、以下のようなテーブルが現れます。
(今回はWordpressで構築したサイトのログデータを持ってきました。1行目はヘッダー)
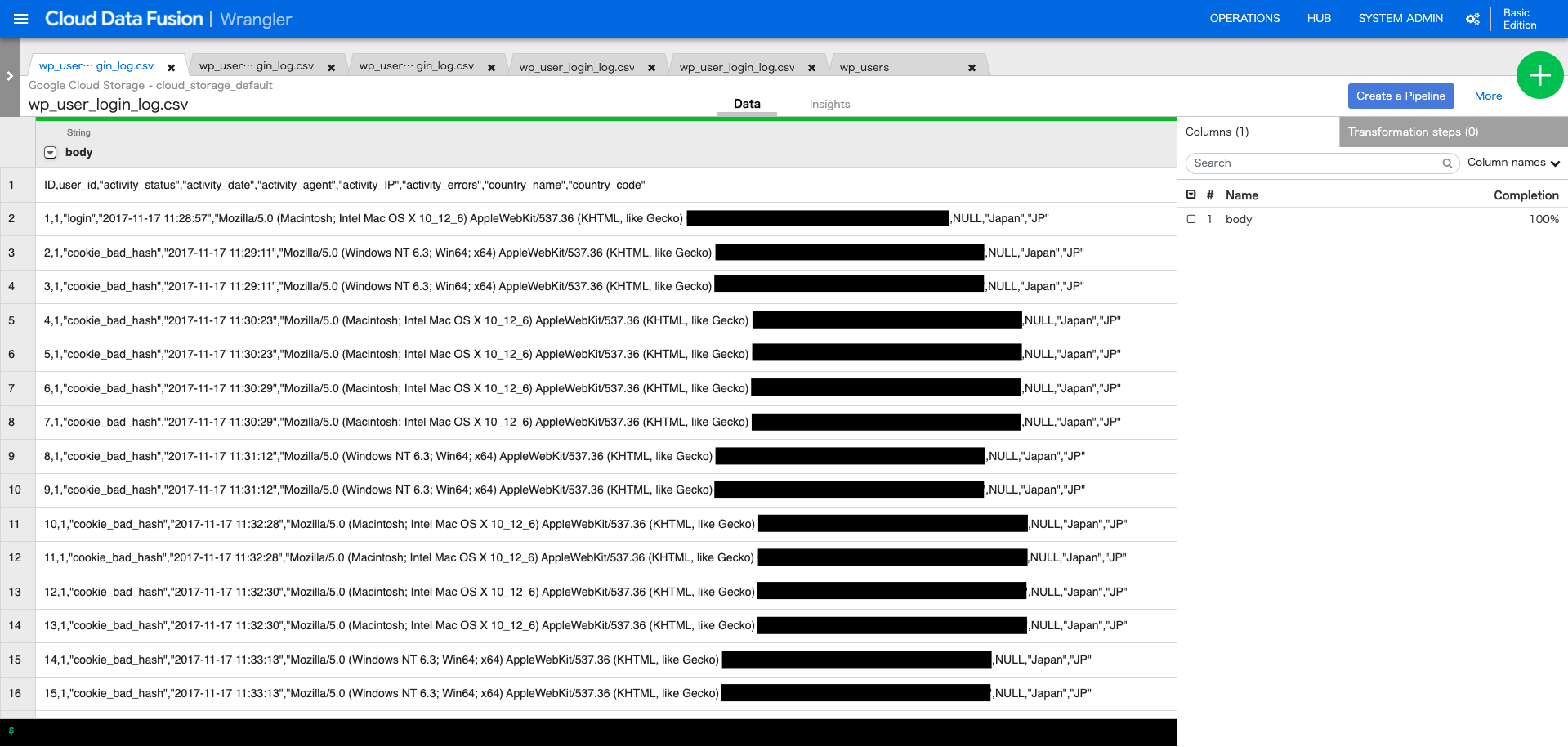
CSVにパースします(元データはCSVのはずですが、なぜかテキスト扱いになっている??)

「comma」を選択し、1行目がヘッダーの場合は「Set first row as header」をチェックし、Applyをクリック(ファイルに合わせて適宜変換かけてください)

すると綺麗にカラムごとに分かれてくれます。

1列目のbody列はもう不要なので削除します。

パースした直後はID列など、数値しか入っていないカラムもString型になっているのでInteger型にキャストします。

他にも、大文字変換や空文字変換などが可能です(ここでは説明を割愛)
②パイプライン作成
①が完成したら、「Create a Pipeline」を選択。

Batch Pipelineを選択

すると、GCSからCSV変換までのパイプラインを自動的に構築してくれます。

※「Wrangler」>「Properties」を選択し、「Output Schema」で出力するカラムの指定ができます。

③BQへの接続設定
サイドメニュー>Sinkから「BigQuery」を選択。

「Wrangler」から「BigQuery」まで矢印を伸ばし、Propertiesを選択します。


必須項目の「Label」「Reference Name」「Dataset」「Table」を埋め、Validateを選択し、「No error found.」と出ればOK。
(※Tableは小文字じゃないと怒られます、怒られた後修正しても怒られた時のデータが消えないバグあり 2021/08/27現在)

④パイプライン実行
ヘッダーメニュー>Previewから「Run」を選択。Succeedと出ればOK

※エラーを吐いた場合は、「Wrangler」>Error Handlingで「Skip error」にして、半強制的にエラーを潰せます(エラー潰してデプロイ実行した後、BQ上の完成品を見ても、ぶっちゃけ問題なさそうだった)

Previewをパスしたら、Deployを選択し、

Runを選択します。10分以上は大体かかるので、成功をお祈りします

StatusがSucceededとなれば成功です。BQの中身を覗きにいきましょう。
図のようにcsvの内容がBQに反映されていれば完成です。

まとめ
ノーコードで、わかりやすくGCP内の各サービスにデータの受け渡しができるのは魅力的ですね。
今後はオンプレDBやCloud SQL上のDB、AWSのS3からのデータ取り込みしようかなと思います。