こちらはSupership Advent Calendar 2018の4日目の記事になります。
こんにちは。はじめまして。
データサイエンティストのps010です。
普段は、広告配信のログからユーザーのWeb上の行動履歴を解析しています。
今回のエントリは、Word2Vecの実践報告です。
はじめに
最近、ユーザーが興味をもつ情報を解析する手法として、Word2Vecに関心を持ち始めました。
今回はWord2Vecを使って、小説やエッセイなど、分野の異なる作家のテイストや文体の違いを把握できるのか、試してみたいと思います。
具体的には、作家ごとにWord2Vecのモデルを学習し、2つのアプローチで結果を比較してみます。
1. 類義語:単語の使われ方や文体の違いを比較
2. 単語の演算:単語間の関係性を可視化
本題の前にWord2Vecについて簡単におさらいです。
Word2Vecは単語の前後関係をベクトルで表現する手法です。単語をベクトルに変換することで、基礎集計だけではなし得ないような”単語の意味”的な演算が可能になるメリットがあり、ビジネスなど実用面での応用が期待され、今なお盛んに研究開発が行われています。
なお、技術説明はこちら1が詳しいので、ご参照ください。
データソース
データソースは、青空文庫のテキストデータを使用します。
青空文庫は、著作権が消滅したり公開が許諾された作品を電子化し、公開しています2。
作家は、明治期から太宰治、宮沢賢治、北大路魯山人とタイプの異なる3人を選びました。
太宰治は小説、宮沢賢治は童話、北大路魯山人は漫画「美味しんぼ」の海原雄山のモデルとなった芸術家・美食家で、芸術や食に関するエッセイを多く書いています。
今回は3人の作品をコーパスとします。
コーパスの対象作品は、分析を容易にするため「新字新仮名遣い」の散文のみとし、ファイルサイズが5KBに満たない短文は除外しました。
それでは、コーパスの概要を確認しましょう。

太宰は対象となる散文作品が多く、小説で文章が長いこともあり、ユニーク単語数、総単語数が多くなりました。特にエッセイとの差が大きく、ユニーク単語数は約4倍、総単語数は約12倍の開きが出ました。文章の長さの違いが、総単語数に影響しているようです。
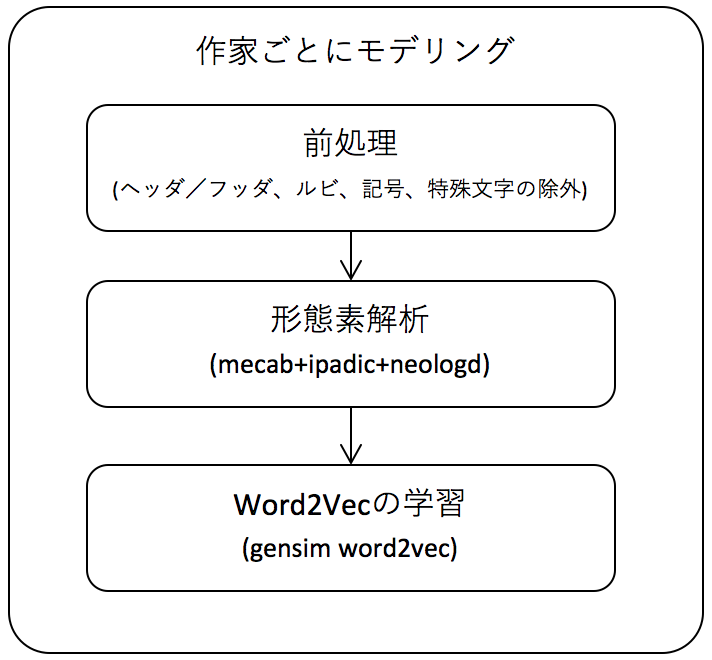
Word2Vec学習までの流れ
学習までの流れを図にしました。
前処理で余分な情報を除外し、形態素解析で文章を単語の分かち書きに変換します。
これらの後、Word2Vecの学習を行います。
Word2Vecの学習
Word2Vecの学習には、pythonのgensimを使用しました。
作家ごとにモデルを分け、文章単位で学習を行います。
[データセットイメージ]

from pathlib import Path
from gensim.models import word2vec
'''
“data/aozora”の配下に作家ごとにフォルダを作成し、作品を格納
作家ごとに前処理、形態素解析を施して、wakati.txtに保存済み
'''
p = Path('data/aozora')
subdirs = [x for x in p.iterdir() if x.is_dir()]
wakati_files = [path.joinpath("wakati.txt") for path in subdirs]
# 設定値を入力
size = 300
window = 5
min_count = 5
for file in wakati_files:
with open(file, 'r') as f:
# 1行1文を単語ごとに分けてword2vecに渡す
sentences = word2vec.LineSentence(f)
model = word2vec.Word2Vec(
sentences,
size=size,
window=window,
min_count=min_count,
sg=1)
model.save(str(file.parents[0] / 'w2v.model'))
パラメータの異なるモデルを複数作成し、単語ベクトル同士のコサイン類似度が高い単語、つまり類義語がどの程度確からしいかによって、最適なパラメータを探索します。
調整したハイパーパラメータはsize、window、min_countの3つです。今回は文脈を学習して単語を予測するため、手法はskip-gramを選びました。なお、提案者のTomas Mikolovがskip-gramは学習データが少なくても機能する旨の発言をしており3、データ量の面でもskip-gramの方が適しているかもしれません。
[パラメータ設定値/調整幅]
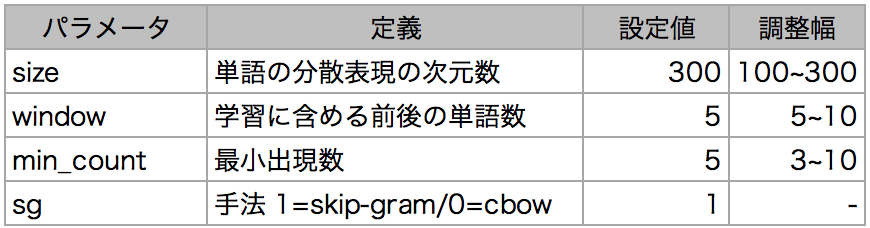
パラメータの調整範囲は、一般的な設定値を参考にしました。
「心」など3つの単語で類義語を比較したところ、主観ではありますが、sizeは大きいほど、windowとmin_countは小さいほど近しさが増すように感じました。ただ、min_countは3だと少し特殊な言葉が出てくるように感じました。
基礎集計
詳細な分析の前に、コーパスの頻出単語を見ておきましょう。
形態素解析で名詞/形容詞/動詞を抽出し、ストップワードを除外してます。
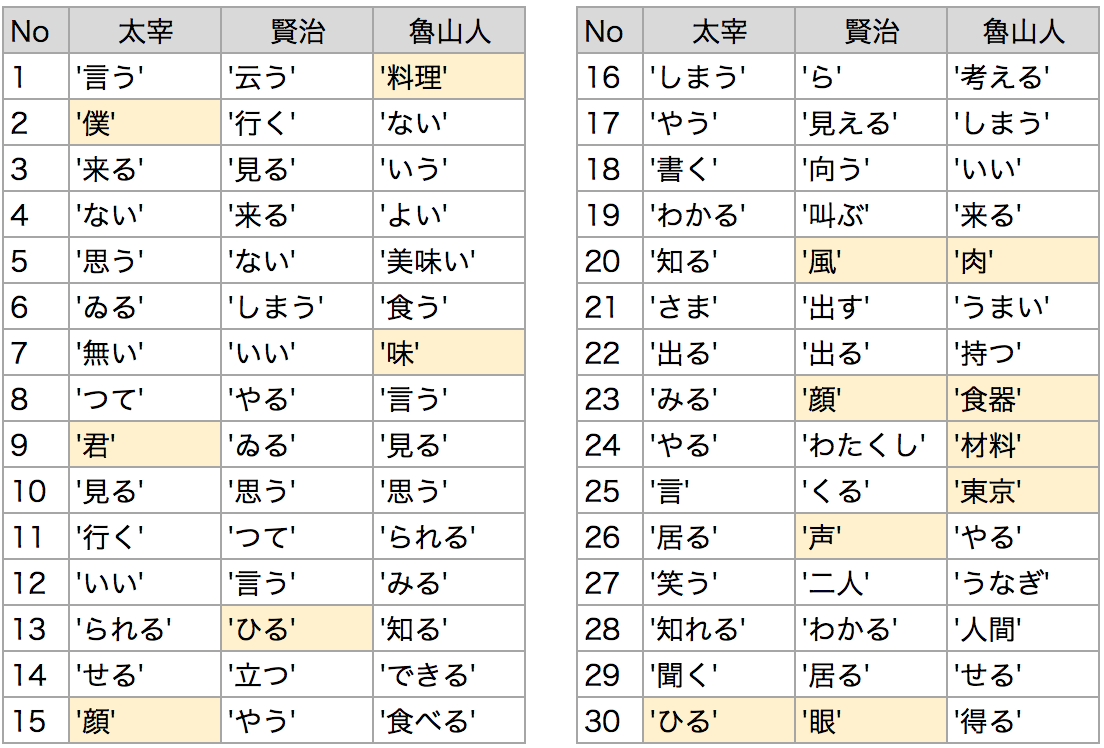
特徴の出やすい名詞に色をつけました。
太宰は「僕」「君」「顔」が出てきました。男女の物語が多い、彼らしいラインナップです。
賢治は「ひる」「風」「声」「顔」など、自然と人に関する単語が多いようです。
魯山人は「料理」と「味」です。「ない」「よい」「美味い」「食う」など、料理の良し悪しが頻繁に語られているようです。
類義語の比較
それでは、採用したモデルの単語の類義語から、単語の使われ方を比較してみましょう。
作家ごとに、共通の単語の類義語を並べてみます。類似度はコサイン類似度で計算します。
作家による違いを比較するために、品詞別に、どの作家でも比較的多く使われている単語を選びました。参考値として単語が含まれる作品のカバー率と対象語の出現数を添付します。
まず名詞から、「眼」の類義語を見てみましょう。

太宰と賢治は体の部位や眼の所作が並びます。
太宰は目の周辺部位や「つき」「色」「横目」など細やかな表現、賢治は上半身全体や「じっと」「ぶるぶる」などの動作の形容詞が見られます。魯山人はいろんな単語が混ざってます。
次は形容詞から。「よい」といえば何でしょうか。
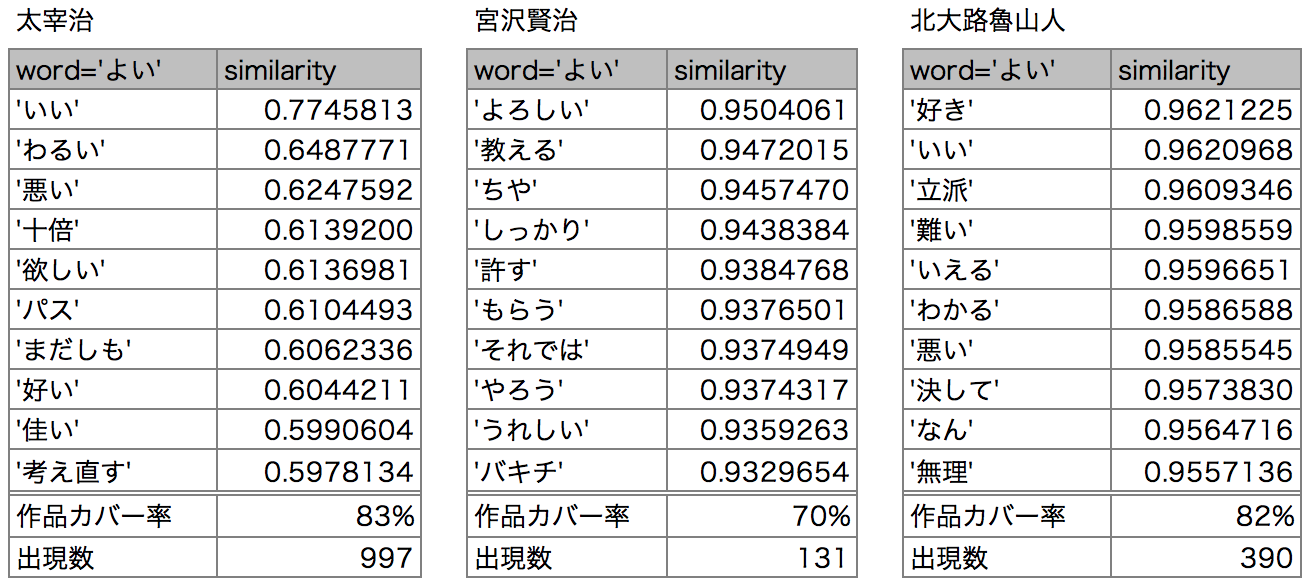
太宰は「いい/好い/佳い」と一緒に「わるい/悪い」などの対義語が出てきます。
Word2Vecは単語の前後関係を学習するため、「私はリンゴが好きです」と「私はリンゴが嫌いです」のように、使われ方が似てて前後に同じ単語が並ぶケースに弱いのですが、その典型例のようです。
賢治は「よろしい」「うれしい」の他は少々雑多です。魯山人にも「好き」「いい」「立派」と一緒に「悪い」が見られます。
最後に動詞「知る」です。
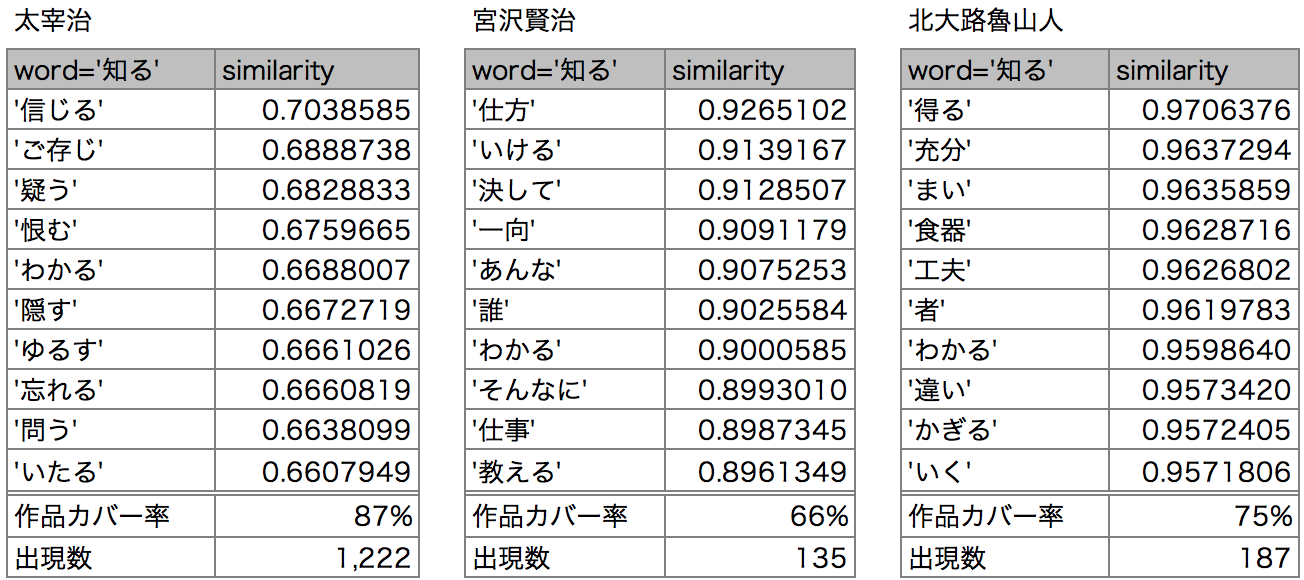
作家によってニュアンスが違います。太宰は対象を深く知り、感情を動かされるニュアンス、他2人は少々雑多ですが、賢治は「仕方」や「仕事」を教えるニュアンス、魯山人は「得る」「違い」「わかる」など理解を深めるニュアンスが見られます。
「知る」の類義語のニュアンスを、それらの類義語で確かめましょう。太宰と賢治を見ます。
まずは太宰の「知る」の類義語「わかる」「忘れる」「疑う」の類義語を見てみましょう。
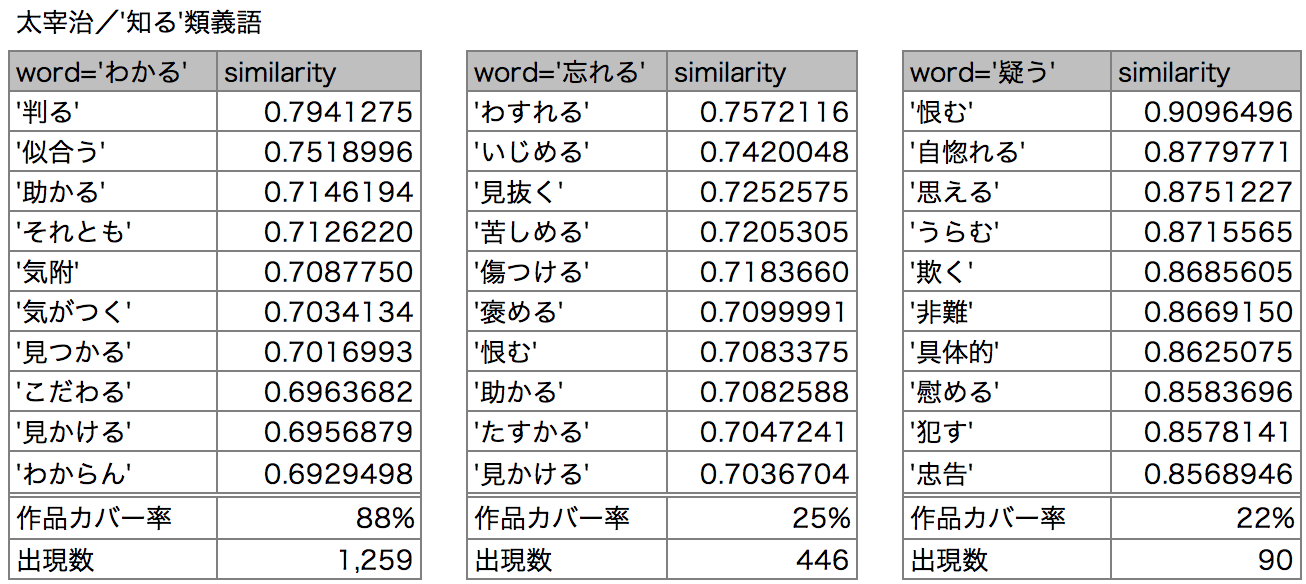
「わかる」は認知や理解、「忘れる」と「疑う」は「苦しめる」、「恨む」、「非難」など負の情動を表す単語が見られます。
次に賢治の「知る」の類義語「わかる」「仕事」「教える」を見てみましょう。
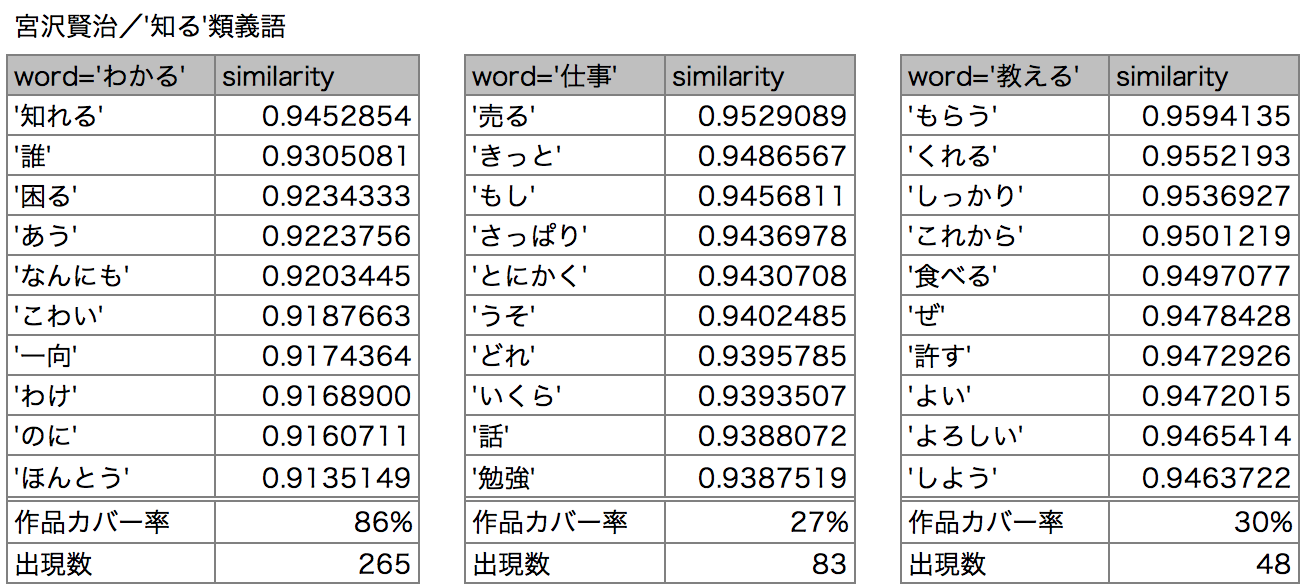
「わかる」は漠然とした困惑や恐怖、「仕事」は商売や勉強、「教える」は支援や評価のニュアンスが見られます。
「知る」の類義語のニュアンスを比較すると、太宰は出来事を理解したり、感情が深く動かされるニュアンス、賢治は他者との関わりの中で経験して覚えるニュアンスがあることがわかりました。
ここまで、同じ単語で作家のモデルを比較しました。
同じ単語でも作家によって使い方が異なり、「眼」では描く対象や表現スタイルの違い、「知る」では「知る」と言う単語のニュアンスの違いが見えました。
反面、類義語のそれらしさという点では、作家や単語によりバラつきが見られました。
意味のバラつきが見られる単語は出現数が少ないことが多く、魯山人のように単語数の少ない作家ほど顕著でした。魯山人の眼のケースでは類似度が0.99以上と極端に高いですが、作品のカバー率や出現数が低く、単語の特徴を十分に学習しきれていないと思われます。
単語の演算
最後に、単語の演算処理から単語間の関係性を見てみましょう。
Word2Vecでは「王」−「男」+「女」=「女王」という演算が定番ですが、
ハムレットのパロディを書いている太宰で試してみましょう。
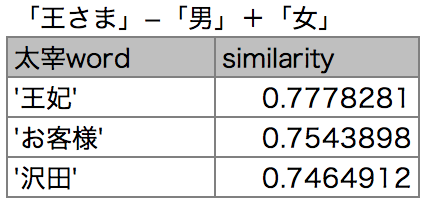
「王妃」が出てきました。いや、ほんとに出てくるものですね。
さて、演算の機能を確認したところで、本題に戻りましょう。
ここでは「僕」を比較してみます。まずは類義語の確認をしましょう。
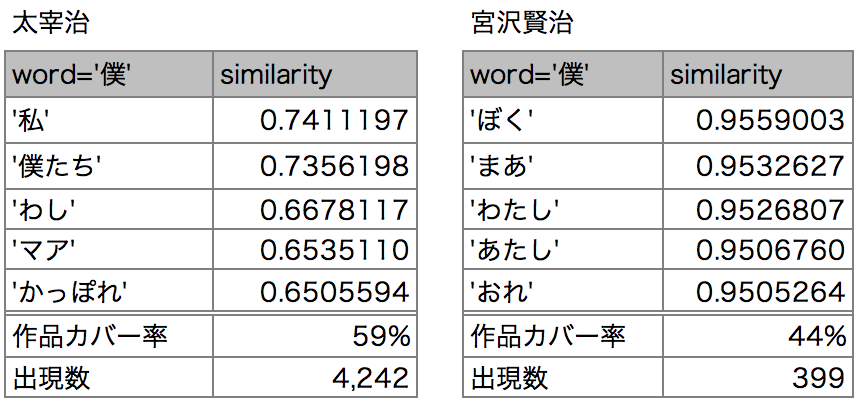
出現数の少ない魯山人は対象から外しました。
太宰は「僕たち」など人が半分、賢治はひらがなの一人称代名詞が並んでます。
さて、「僕」から「男」を引くと何が出てくるのでしょうか。
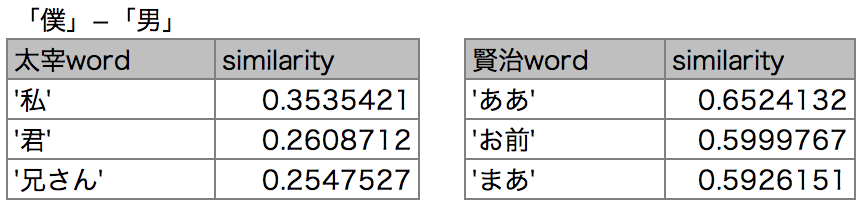
太宰は「私」が出てきました。性別は不明です。「君」は恋人でしょうか。
賢治は「お前」です。君より表現が砕けています。
ここからは、太宰の結果を深掘りしてみます。
先ほどの結果を、もう一つの演算「父」−「男」と比べてみましょう。
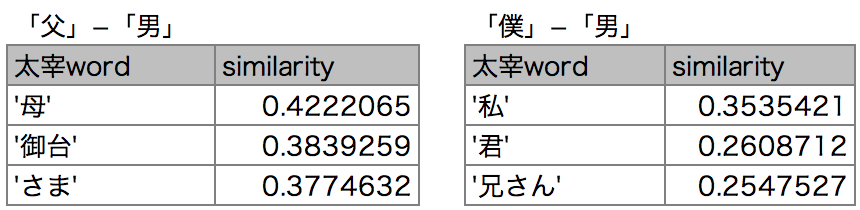
「母」と「御台」が出てきました。「僕」も「父」も"相棒"が出てきます。
「僕」と「父」にあって「男」にないもの=身近な人間、なのでしょうか。
「僕」と「君」、「父」と「母」の関係性を主成分分析(PCA)で可視化してみました。
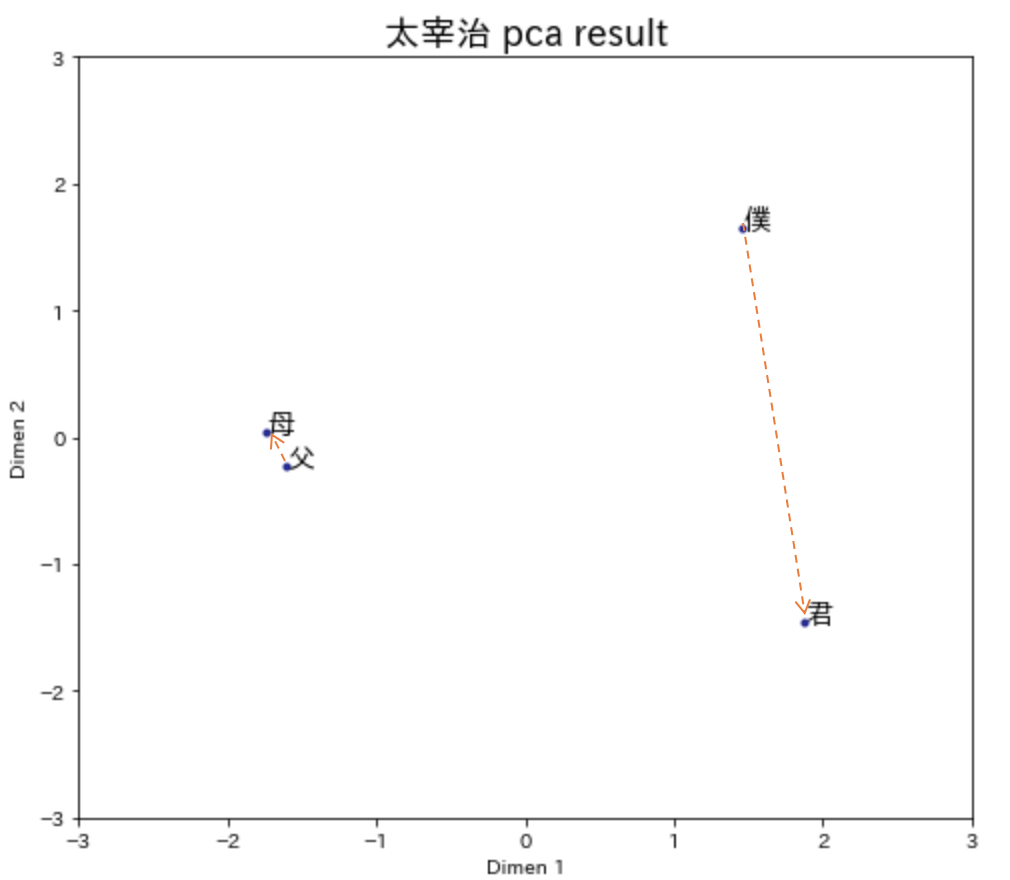
「僕」と「君」の方が、「父」と「母」より距離が遠いようです。
他人のうちは、距離が遠いのかもしれませんね。
まとめ
Word2Vecを使って、分野の違う作家ごとにテイストの可視化を試してみました。
3人の文豪の単語の使い方やニュアンスを観察でき、興味深かったです。
類義語の比較では、作家によるニュアンスの違いを確認できました。
「眼」のケースでは、心の機微を描く小説と言動を描く童話の、表現の違いが観察できました。
「知る」のケースでは、太宰は理解や情動のニュアンス、賢治は経験して覚えるニュアンスが見られ、作者による単語の用い方の違いが確認できました。
また今回、小さいコーパスを使ったところ、作家によって類義語の厚みにバラツキが出ました。
太宰は比較的どの単語でも意味が取れ、情動の表現が多彩でした。賢治は人の動き、魯山人はモノの良し悪しなど特定の単語に厚みがあるものの、それ以外はまとまりに欠けがちでした。
これは作家が取り扱う分野と対象単語の出現数が影響していると思われます。
最も開きのある太宰と魯山人では、総単語数で12倍の差があります。魯山人はエッセイなので1作品辺りの単語数が少ない上に、サイズの小さい作品を除外したこともマイナスに働いたのかもしれません。
単語の演算では、太宰コーパスで「僕/父」−「男」の意味合いが見て取れました。「僕」と「父」にあって「男」にないものが身近な人間とは、実に小説らしいです。
惜しむらくは、今回のアプローチでは作風の再現まではできませんでした。
作風の再現には、より多くの単語の関係性や、文章そのものを表現する手法が必要になりそうです。
終わりに
今回の実践報告を通じて、Word2Vecでできること・できないことが具体的にイメージできるようになりました。
どのようなコーパスを使うかによって、含まれる語彙や、距離の近い単語が異なることが観察できました。作家ごとの小さなコーパスを使うと単語の出現数が少なくなり、それらしい類義語を得るのが難しいこともわかりました。Word2Vecを使う際は、コーパスの分野や単語の出現数を考慮したいと思います。
反面、使われ方が同じで出現数の多い単語でないと結果が安定しないので、コンテキストによって複数の意味を持つ単語などの特徴は捉えにくいと思われ、場合によっては違うアプローチを検討する必要があると思われます。引き続き、周辺技術を学びたいと思います。
次回機会があれば、Word2Vecを応用した情報推薦や、単語よりも単位の大きいパラグラフやトピックでの意味の演算も試してみたいなと思います。
-
Word2Vecの理論について、提案者の論文と参考にしたサイトをご紹介します。
◆提案者の論文
“Efficient Estimation of Word Representations in Vector Space” submitted on 16 Jan 2013 (v1)
Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean
◆参考にしたサイト
word2vec 理論説明 Word2Vec:発明した本人も驚く単語ベクトルの驚異的な力
word2vec(Skip-Gram Model)の仕組みを恐らく日本一簡潔にまとめてみたつもり
Wikipedia2Vecを用いた文書分類
TensorFlow : Tutorials : Data representation : 単語のベクタ表現
Statistical Semantic入門 ~分布仮説からword2vecまで~ ↩ -
青空文庫の所蔵作品は平安時代から昭和期に渡り、東西の文学作品が約1万点収録されてます。
下記サイトから、青空文庫の概要と所蔵リストを閲覧できます。
青空文庫早わかり
青空文庫:公開中リスト
青空文庫:作家リストすべて(csvダウンロード可能) ↩ -
Tomas MikolovのGoogle groupでの発言を引用しています。
出典元:https://groups.google.com/forum/#!searchin/word2vec-toolkit/c-bow/word2vec-toolkit/NLvYXU99cAM/E5ld8LcDxlAJ ↩