私たちは、マルチコアCPUやSIMDアーキテクチャのHW性能を引出す組込みSW最適化技術をコアコンピタンスとするスタートアップを目指す有志集団です。
Raspberry Pi 3/4のCPUだけでどれくらいDeep Learningを高速化できるかに挑戦しています。
過去、Chainerやdarknetといったフレームワーを対象としていましたが、現在はONNX runtimeの高速化に挑戦しています。
現時点での結果は以下の通りです。
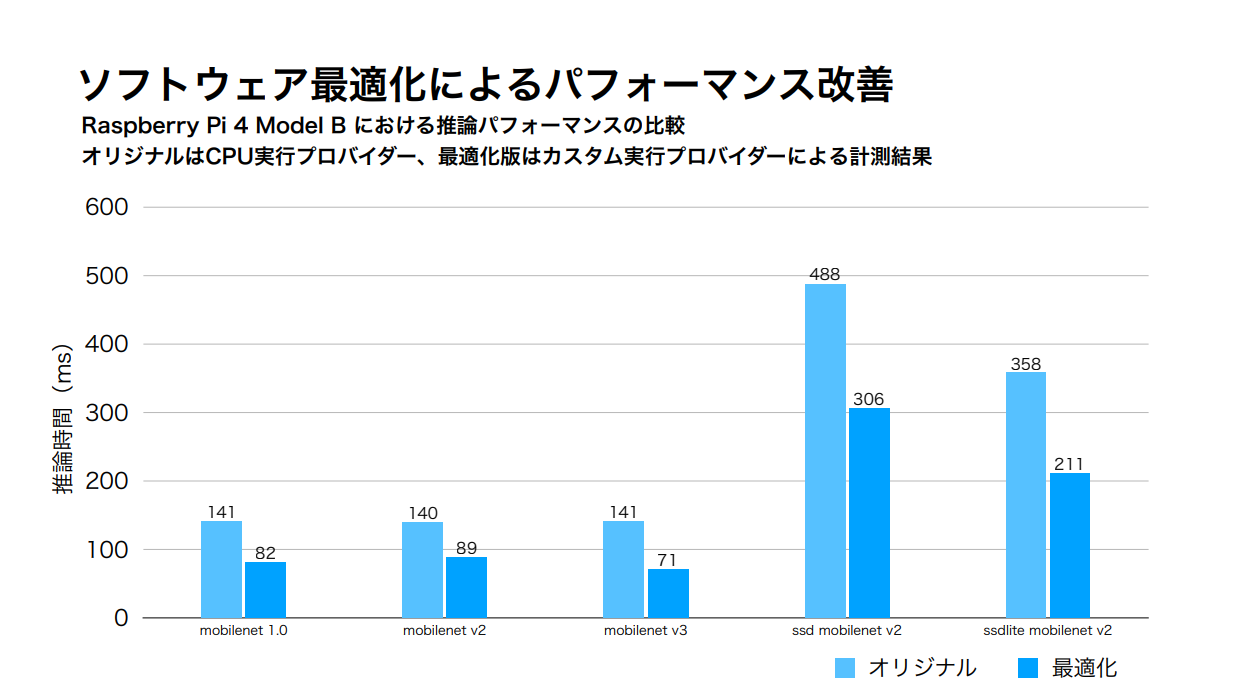
@onnxruntime on RPi4(CPU Only)
— Project-RAIZIN (@ProjectRaizin) September 8, 2020
MobileNetV3(Image clasification)
MobileNetV2-SSDLite(Image detection)
Original vs. Accelerated#RaspberryPi #Python #DeepLearninghttps://t.co/wvBLn9Tfes
もともとMicrosoftやFacebookがプロジェクトを推進しているだけあって、数倍の高速化は難しいですが、im2colやgemm、Activation関数などをチューニングすることでなんとかパフォーマンスを2倍にすることができました。
その他にもいろいろなモデルのデモ動画を公開しています。
Youtubeチャンネル
私たちのこだわりポイント
- 1. Raspberry PiのCPUだけを使用してDeep Learningを実行する
- 2. 32bit版Rasbianを使用する
- まだ64bit版Raspbianに対応できていない...
- 3. 既存モデルをそのまま使用する
- 私たちで量子化/枝刈り/蒸留などの軽量化を行わない(そもそもできない...)
- 4. 計算精度を可能な限り変えない
高速化アプローチ
高速化アプローチは以下に示すような一般的なものです。
- a. コード最適化
- b. マルチコア並列化
- c. SIMDベクトル化
- d. ソフトウェアパイプライン
- e. メモリ効率化
一般的な項目を、プロファイルを取りながら少しでも速くもう少しでも速くと空雑巾を絞るがごとく突き詰めていく姿勢がほかにない私たちの特徴的なところだと思っています。
記事の最後に
今回は、結果の紹介にとどまってしまいましたが、忘備録を兼ねて各項目毎に技術資料をまとめて、随時公開していきたいと考えています。