Kaggleを始めた経緯
機械学習や深層学習は学生時代に遊び程度に触っていました。就職してからはあまりなかったのですが、最近自分の中でデータ分析が再熱したため、kaggleに挑戦しようと思いました。
そこで今回はkaggleの入り口、チュートリアルのTitanic: Machine Learning from Disasterにチャレンジした記事を書いていこうと思います。
どんなコンペティションか
タイタニック号の乗客名簿を基に、乗客の生死を予想するコンペティションです。
参考文献に詳しく乗っているため、省略。
0. 筆者環境
Python 3.7.0
Jupyter Notebook
Visual Studio Code
pandas 0.23.4
pandas-profiling 1.4.1
numpy 1.15.4
scikit-learn 0.19.2
xgboost 0.81
1. データの準備
ここから下記2つのcsvファイルをダウンロードします。
それぞれの役割はこんな感じ。
| csvファイル名 | 内容 |
|---|---|
| train.csv | 学習用のデータ。このデータを用いて学習する。 |
| test.csv | 検証用のデータ。乗客の生死の情報(Survived)が抜けている。 |
提供されているデータの詳細はここに分かりやすく書いてありましたので参考にさせていただきました。
2. データ読込
まずは落としてきたデータを読み込みます。
import pandas as pd
import numpy as np
# csvファイルのパス
TRAIN_DATA = 'input/train.csv'
TEST_DATA = 'input/test.csv'
# csv読込
train = pd.read_csv(TRAIN_DATA)
test = pd.read_csv(TEST_DATA)
落としてきたデータを読み込んだので、まずは今回学習に用いるデータと検証用のデータを表示させます。
Survivedが検証用のデータでは抜けていることがパッと見て分かります。
また、Cabinの列を見てみると、NaN(欠損値)があることが分かります。
train.head(5)

test.head(5)

データをパッと見た感じではNameとTicketは加工しないとすぐには使えなさそうです。
しかし、色々カーネルを見てるとMr等の敬称を特徴量とすることが有効みたいなので時間があるときにやってみたいと思います。
Cabinに関しても後述しますが欠損値が多く扱えなさそうです。
そのため、学習で扱うカラム以外をここで捨てていきたいと思います。
train = train.drop(['PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1)
test = test.drop(['Name', 'Ticket', 'Cabin'], axis=1)
3. 前処理 ~欠損値の補完~
読み込んだデータを表示したところ、Cabinに欠損値がありました。
他にも欠損している値があるかもしれないので、データの詳細を見ていきます。
ここでpandas-profilingを使うととても楽ができます。どんなものかはこちらを参考に。
import pandas_profiling as pdp
pdp.ProfileReport(train)
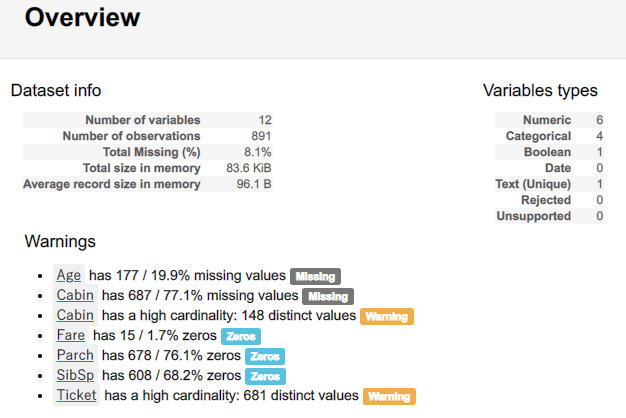
trainとtestのデータセットの詳細を見ると、Age, Cabin, Embarked, Fareに欠損値があるようなのでそれぞれ欠損値を補完します。
しかし、Cabinに関しては学習用データだけでも77%も欠損しているみたいなので、今回はAge, Embarked, Fareの3つだけ補完していきます。
ここからは例として、train(学習用データ)のみに対して処理を加えていきます。
Ageの補完
いくつか手法があるようですが、一番簡単なのは平均値で補完することです。
# Ageの欠損値をAgeの平均値で補完
train['Age'] = train['Age'].fillna(train['Age'].mean())
次に、他の方のカーネルを見ていて良さそうだと思ったのが、平均と標準偏差から補完です。
今回はこちらを採用します。
# 年齢の平均
age_avg = train['Age'].mean()
# 年齢の標準偏差
age_std = train['Age'].std()
age_null_count = train['Age'].isnull().sum()
# Ageの欠損値を平均と標準偏差から乱数を生成し補完
age_null_random_list = np.random.randint(
age_avg - age_std, age_avg + age_std, size=age_null_count)
train['Age'][np.isnan(train['Age'])] = age_null_random_list
train['Age'] = train['Age'].astype(int)
Fareの補完
こちらは1件だけ欠損値が出ていました。
今回はFareの中央値で補完します。
# Fareの欠損値を中央値で補完
train['Fare'] = train['Fare'].fillna(train['Fare'].median())
Embarkedの補完
Embarkedに関しては数値ではなく文字が入っています。
そのため、今回は最頻値で補完します。
先程のProfileReportによるデータセットの詳細を見ると、'S'が最頻値のため、’S’を入れて補完していきます。
(ここで一々調べなくても可視化されてすぐ分かるProfileReportってとても便利・・・)
# Embarkedの欠損値をSで補完
train['Embarked'] = train['Embarked'].fillna('S')
前処理 ~文字列から数値データへ~
欠損値を補完したので、再度データセットを表示させてみます。
train.head(5)
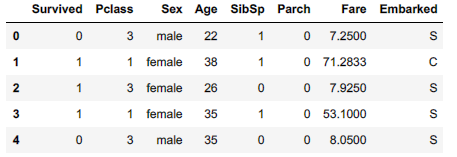
ここで、SexとEmbarkedが文字列で表現されていることに気づくと思います。
モデルによってはこのままの方が良い場合もあるようですが、今回は数値に変換していこうと思います。
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
cols = ['Sex', 'Embarked']
for col in cols:
train[col] = le.fit_transform(train[col].values)
tmp = pd.get_dummies(train[col], col)
for col2 in tmp.columns.values:
train[col2] = tmp[col2].values
train.drop(col, axis=1, inplace=True)
train.head(5)
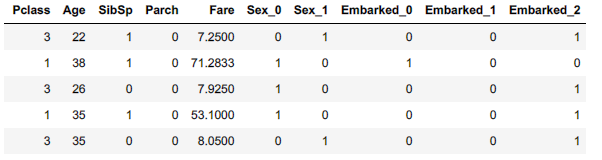
結果を見て分かるように、先程まで文字列だったSexとEmbarkedに関して0と1で表すことができました。(OneHotエンコード)
少し話はそれますが、他にもモデルによってはAgeとFareを標準化(平均0、分散1)するとよいとかなんとか。
これもscikit learnで簡単にできます。
from sklearn.preprocessing import StandardScaler
# 標準化
std_scale = StandardScaler().fit(train[['Age', 'Fare']])
train[['Age', 'Fare']] = std_scale.transform(train[['Age', 'Fare']])
train.head(5)
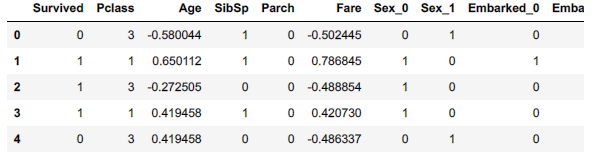
まとめ
少し長くなったので、今回はデータの準備までとしたいと思います。
次の記事で実際に色々モデル(最近流行りらしいXGboostとかでも)で学習してみて比較したりして遊んでみたいと思います。
また、コードに関しては自分で関数化しているものを多少変更して記載しているため、ミスでうまく動作しないものもあるかもしれません。
参考にしたページ
https://qiita.com/catman_john/items/629052ba47301c168408
https://www.codexa.net/kaggle-titanic-beginner/
https://www.youtube.com/channel/UCiECS_auJLNpFsvjTi1WuxQ