画像アップロードできなくなったから一時的に投稿(一回でも投稿してないとアップロードできなくなるらしい)
随時編集していく
マイクからの音声を学習させて誰が話した音声なのか識別をやってみようという話です.
画像認識に興味を持ち,その延長線上で何かできないかなって思いやってみました.
アプローチとかに関しては問題ありありのありだと思いますがそこら辺は目を瞑っていきたいと思います・・・
何回かに分けて投稿していこうと考えています.
やりたいこと
- マイクからの音声を画像に変換,学習させてリアルタイムに誰が話しているかを識別する
- ライブラリを使って出来るだけ分かりやすく,専門知識がなくてもできるものにする
この記事の内容
- どんな流れでやっていくか
- 環境どういうの使っていくか
アプローチ
大体の流れはこんな感じ.
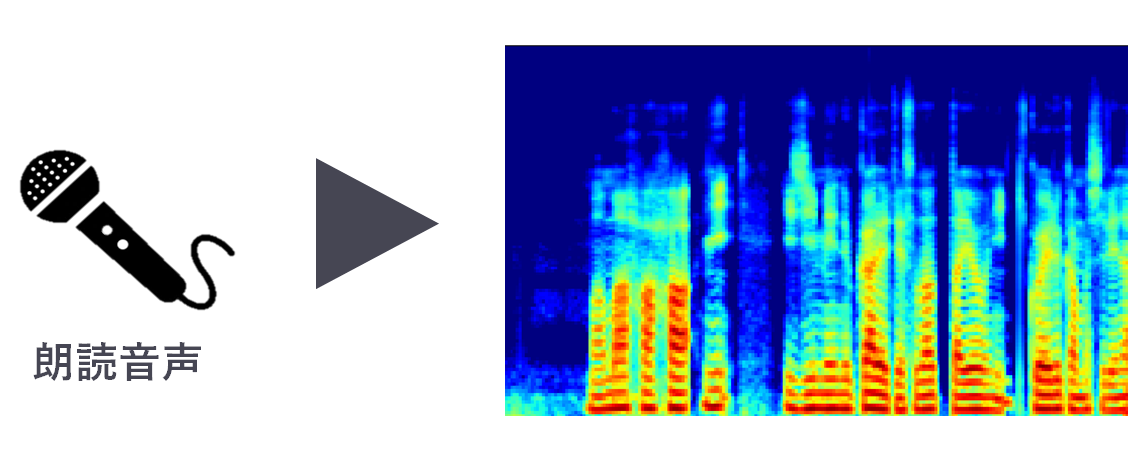
1. マイクからの音声をサウンドスペクトログラムに変換
マイクからの音声データをサウンドスペクトログラムという周波数,時間,信号強度の3次元グラフに変換する.
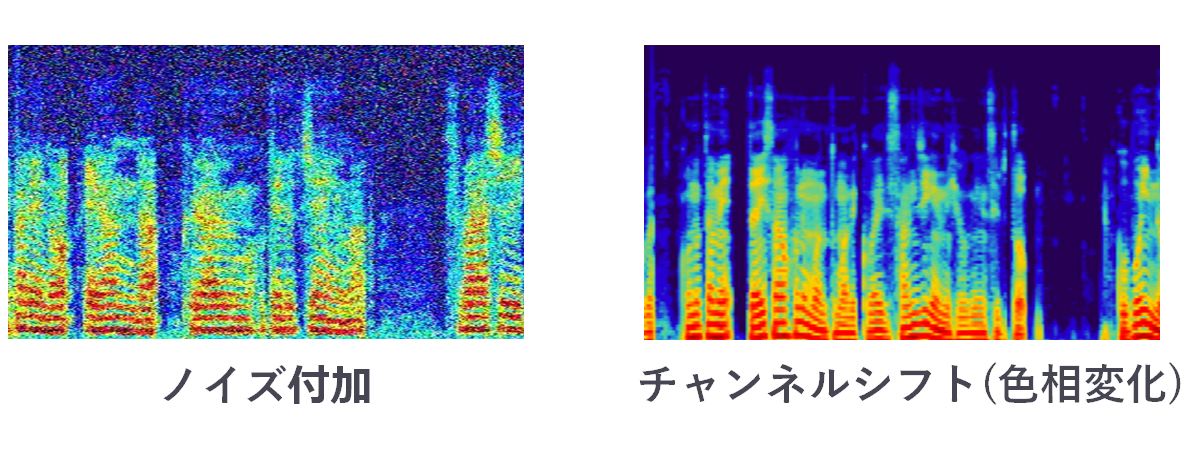
2. 精度を良くするために画像に前処理
そのままCNNに突っ込んでもいいんだけど,なるべく汎化性能を良くしたいので変換した画像に対して前処理を行う.
ここで音声に対して前処理を行わないで変換した画像に対して行っているのはマイクからの音声データをそのままサウンドスペクトログラムへ変換してしまったため(手抜き)
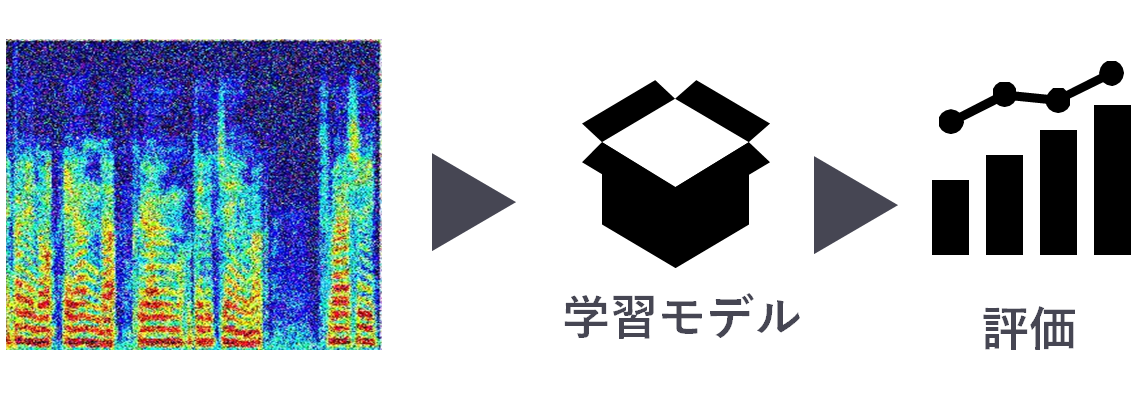
3. 学習モデルを作成して評価
サウンドスペクトログラムからCNNのモデルを作成,そのモデルを使って誰が話しているのかを識別する.