普段、業務でNordicが提供するnRF52系のマイコンを使用したFW開発に携わる事があるのですが、その多くをNonOS上で制御しています。
その中で、NonOS開発特有の難しさなどから脱却したいという思いがあり、業務の一環としてFreeRTOSに触れる機会がありました。
この、nRF52へのFreeRTOSポーティングを通じて学んだ、知識として入れておくと役立つ事を記事にしたいと思います。
(主に自分へのメモとして)
1. タスクの状態遷移と各状態について
状態遷移
FreeRTOSのスケジューラは、タスクを4つの状態で管理しています。
FreeRTOSの使用には、この状態遷移の理解が不可欠でしょう。
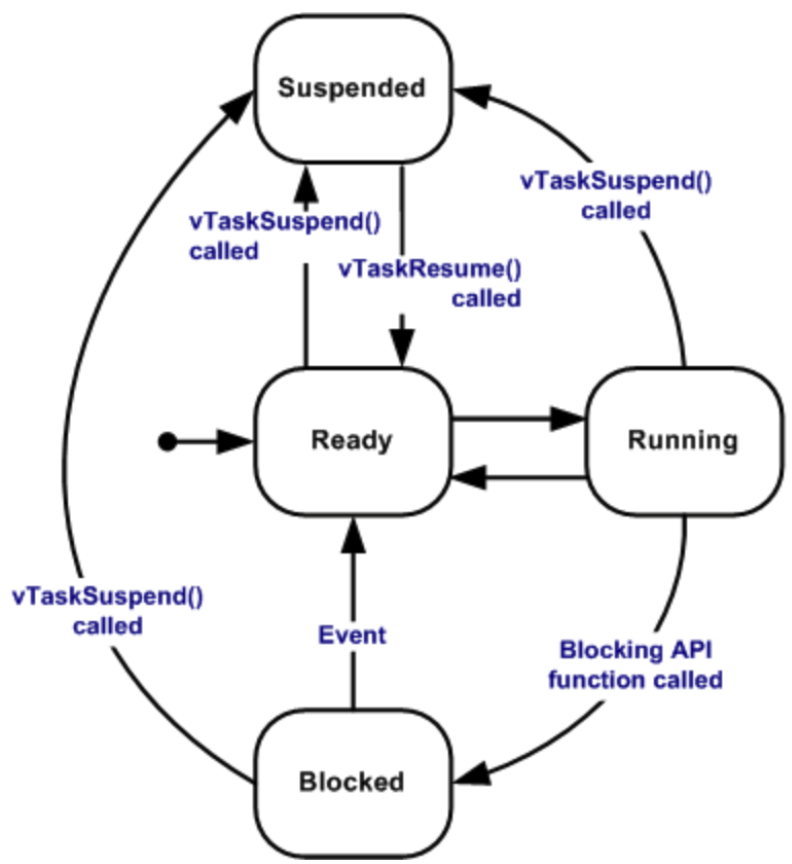
各状態
Ready
タスクの登録直後は(vTaskCreate())、まずReady状態(実行可能状態)に遷移します。
そこからスケジューラがタスクの優先度に応じて、Running状態(実行状態)に遷移させます。
Running
実際にタスクが処理を行なっている状態です。
CPUを占有している状態で、FreeRTOSにおいて同時にRunning状態となれるタスクは一つです。
デフォルトでは対応していませんが、デュアルコアのマイコンでFreeRTOSを動作させる方法もあるようです。
- https://www.digikey.com/en/maker/projects/introduction-to-rtos-solution-to-part-12-multicore-systems/369936f5671d4207a2c954c0637e7d50
- https://www.freertos.org/STM32H7_Dual_Core_AMP_RTOS_demo.html
- https://www.freertos.org/2020/02/simple-multicore-core-to-core-communication-using-freertos-message-buffers.html
Blocked
特定のFreeRTOS APIを叩くことで、Blocked状態(停止状態)に遷移します。
他のタスクからの通信や割り込みからの通信を待つ時や、リソースの取得(セマフォ・ミューテックス)を待つような処理を行う事で、そのタスクがこの状態に遷移します。
Blocked状態にはタイムアウト期間を指定でき、それを過ぎるとタスクはReady状態になります。
vTaskDleay()を呼ぶ事で遅延周期を終えるまで、タスクをBlocked状態に遷移させる事も可能です。
Suspended
Suspended状態(待ち状態)は、Blocked状態と同様にCPU資源を消費しない状態です。
明示的にvTaskSuspendを呼ぶ事で、他のタスクを実行する事が可能になります。
Blocked状態との違いは、タスクがどの状態からでもSuspended状態に遷移させることができる点です。
また、vTaskResumeでSuspended状態から復帰させることも可能で、
タスクがSuspended状態に遷移した時点からから処理を再開します。
2. タスクのスケジューリング方法
FreeRTOSスケジューラは、FreeRTOSConfig.hで定義されている以下に記載する2つの設定の組み合わせに応じて、カーネルのスケジューリング動作が変わります。
プリエンプション
configUSE_PREEMPTIONの値を1(有効)に設定すると、
あるタスクが処理の実行中に、そのタスクよりも優先度の高いタスクが実行可能状態になった場合、優先度の低いタスクの処理を中断して優先度の高いタスクを実行します。
より優先度の高いタスクが優先的に実行されるということです。
configUSE_PREEMPTIONの値を0(無効)に設定した場合、
各タスクがBlocked状態・Suspended状態になるまで他のタスクへの切り替えが発生しません。これを、協調的マルチタスクと呼びます。
(タイムスライシングも無効になります。)
これは、複数のタスクからアクセスされるリソースに対する、排他制御を考える必要がなくなるといったメリットはありますが、
優先度に応じたタスク切り替えが行われなくなるので(Ready状態に遷移したものから順番に実行される)、
そもそもRTOSを導入するメリットが薄まってしまうスケジューリング動作になってしまうと思われます。
(それこそ、NonOSと割り込みだけでも実現できるはずです。)
タイムスライシング
優先順位が同一のタスクがあった場合、設定した時間毎にタスクを切り替えながら動作させる事が可能で、この機能をタイムスライシングと呼びます。
(configUSE_TIME_SLICINGの値を1にする事で機能が有効になります。)
タスク切り替えの時間は、configTICK_RATE_HZで設定が可能です。
(単位がHzなので、1000で1msとなるようです。)
タスクのコンテキストスイッチの頻度が高まるので、オーバーヘッドも大きくなる事が想定される機能です。
(configUSE_PREEMPTIONの設定を無効としている場合、機能しない設定です。)
タスクが切り替わるタイミング
FreeRTOSのタスクが切り替わるタイミングは3つです。
- タイマ割込み
- Blocked状態/Suspended状態のタスクが、Ready状態に切り替わった時
- Running状態のタスクが、Blocked状態/Suspended状態に切り替わった時
3. FreeRTOSで主要となる機能
FreeRTOSに限らずですが、RTOSを利用したファームウェアを実装したい場合には、
以下の主要機能が理解出来ていれば問題ないと思います。
-
排他制御
-
タスク間通信
1. ソフトウェアタイマ
これまで、NonOSでnRF52を使用する環境では、app_timerを用いた純粋なISRからのタイマ割り込みを制御していましたが、
FreeRTOS上でタイマ機能を実現する場合、ソフトウェアタイマを使用します。
また、FreeRTOSにはタイマ用のタスク(デーモンタスクと呼ばれている)が存在しており、
xTimerに登録したハンドラはデーモンタスクからコールされるため、
NonOSで動作させていた時のようなISRからの呼び出しでは無いといった違いがあります。
そのため、xTimerに登録したハンドラと、あるユーザタスクで共通の資源にアクセスする処理があった場合、プリエンプションの設定やタスクの優先度によっては、
そこに排他の仕組みが必要なケースがある点に注意してください。
(ユーザタスクとデーモンタスク間での資源の排他です)
このデーモンタスクは、configTIMER_TASK_PRIORITYで優先度設定が可能です。
逆に、プリエンプションは有効でも、デーモンタスクの優先度がユーザタスクに比べ低く設定されていた場合、
実行可能状態となっているタスクの数が多くなるほど、タイマハンドラの応答性が悪くなるといった自体が発生する事が想定されます。
これは、デーモンタスクがRunning状態となっていても、それよりも優先度の高いユーザタスクもRunning状態であった場合、そちらのタスクの処理が優先されるためです。
(ユーザタスクが数個で済むようなシステムであれば、対して考慮する必要も無いかもしれませんが。)
基本的にはconfigTIMER_TASK_PRIORITYの設定値はユーザタスクに比べ優先度を高く保つべきだと考えられます。
また、前述したとおり登録したハンドラはデーモンタスクのコンテキストから呼ばれるので(タスクなので)、
デーモンタスクをblocking状態に遷移させてしまうAPIをハンドラ内で叩かないように注意しないといけません。
でないと、xTimerに登録した他のハンドラが呼ばれない状態となってしまいます。
FreeRTOSはxTimerを使用しますが、app_timerもこれまで通り使用する事ができます。
※ただし、内部的にはxTimerを使用した実装に置き換わっています。
(詳しくは、app_timer_freertos.cを参照してください)
また、このデーモンタスクのスタックサイズにも注意が必要です。
このタスクのスタックサイズ自体は、configTIMER_TASK_STACK_DEPTHで設定が可能ですが、設定したスタックサイズが小さすぎると登録したタイマハンドラが呼ばれない事態が発生する事があります。
※少なくとも、Exampleの初期値 「configTIMER_TASK_STACK_DEPTH (80)」のままですと、そのような挙動が見られました。
ここで厄介なのは、設定したスタックサイズが小さすぎる事が原因だとして、
vApplicationMallocFailedHook()、vApplicationStackOverflowHook()といった仕組みで検知できない点です。
登録したハンドラでの処理内容(関数ネストの深さ、各関数内のAuto変数の数)によってスタックサイズは変わってくるはずなので、
仮に同様の事象に遭遇した場合は、スタックサイズの設定が怪しく無いか確認してみてください。
2. 排他制御
セマフォとミューテックスについて
セマフォとは、あるリソースに対する同時実行の上限を設定できる機構となります。
FreeRTOSにはセマフォの中でも、
- 1タスクからのみアクセスできるバイナリセマフォ
- 2つ以上のタスクからの利用を可能とするカウンティングセマフォ
があります。
ミューテックスとは、相互排除(Mutual Exclusion)を略したもので、あるタスクがミューテックスを取得する事で、
別タスクの実行を制限する事ができます。
バイナリセマフォ、ミューテックスは非常に似ているのですが、いくつか違う点もあるため、分かった事を以下に記述していきます。
バイナリセマフォ
バイナリセマフォがミューテックスと大きく異なる部分は、オブジェクトを生成した直後は動作許可がないという特徴がある事です。
(※多分ここら辺はFreeRTOS独自の仕様です。itron系とかは違かったような。。)
そのため、排他制御と言うよりも割り込みとタスクの同期処理に親和性が高そうな印象です。
(その用途を想定されて作られていそう)
つまり、バイナリセマフォの使い方としては、
オブジェクトの生成後動作許可がないセマフォを取得しようとしBlocked状態となったタスクに対し、
割り込みから許可を出すといった構成に使えそうです。
そのBlocking状態のタスク優先度を高くしておけば、割り込みが来たことをいち早くフェッチし、
直ちに割り込みに応じたタスク処理を実行する事ができるはずです。
(もちろん、タスクからタスクへ許可を出す、といった使い方も可能です。)
コード例1
static TaskHandle_t s_task_A;
static TaskHandle_t s_isr_task;
static SemaphoreHandle_t s_semaphore_handle;
// 割り込みハンドラや、タスクを想定してください
static void isr_task(void* arg) {
NRF_LOG_INFO("%s : semaphore give", __func__);
xSemaphoreGive(s_semaphore_handle); // 割り込みハンドラから呼び出す場合は、ISR用のAPIを使用してください!
vTaskSuspend(NULL);
}
static void taskA(void* arg) {
s_semaphore_handle = xSemaphoreCreateBinary();
xTaskCreate(isr_task, "isr_task", 128, NULL, 0, &s_isr_task);
BaseType_t result;
while (1) {
NRF_LOG_INFO("%s : blocking take the semaphore", __func__);
result = xSemaphoreTake(s_semaphore_handle, portMAX_DELAY);
if (result == pdTRUE) {
NRF_LOG_INFO("%s : semaphore take success", __func__);
}
}
}
int main(void) {
xTaskCreate(taskA, "taskA", 128, NULL, 0, &s_task_A);
vTaskStartScheduler();
for (;;) {
APP_ERROR_HANDLER(NRF_ERROR_FORBIDDEN);
}
}
task_Aは起動後にxSemaphoreCreateBinaryでセマフォを生成し、xSemaphoreTakeで取得を試みます。
この時点ではまだセマフォ取得ができないため、task_Aは引数に指定した時間分Blocked状態に遷移する事になります。
(portMAX_DELAYを指定する事で無限待ちします。ケースに応じて値を指定してください)
その後、isr_taskがxSemaphoreGiveする事で、task_Aはセマフォを取得できxSemaphoreTakeから抜けて後続の処理が可能となります。
(isr_taskは、task_Aで生成していますが、割り込みハンドラが呼ばれていると仮定して見てみてください。
割り込みからgiveしたい場合は、ISR用のAPIを使用してください。)
コード例2
static TaskHandle_t s_task_A;
static TaskHandle_t s_task_B;
static SemaphoreHandle_t s_semaphore_handle;
static void taskB(void* arg) {
BaseType_t result;
while (1) {
NRF_LOG_INFO("%s : blocking take the semaphore", __func__);
result = xSemaphoreTake(s_semaphore_handle, portMAX_DELAY);
if (result == pdTRUE) {
NRF_LOG_INFO("%s : semaphore take success", __func__);
}
//////////////////////////////////////
// 排他区間(開始)
//////////////////////////////////////
NRF_LOG_INFO("%s : semaphore delay start", __func__);
vTaskDelay(200);
NRF_LOG_INFO("%s : semaphore delay end", __func__);
NRF_LOG_INFO("%s : semaphore give start", __func__);
xSemaphoreGive(s_semaphore_handle);
NRF_LOG_INFO("%s : semaphore give finish", __func__);
//////////////////////////////////////
// 排他区間(終了)
//////////////////////////////////////
NRF_LOG_INFO("%s : delay start", __func__);
vTaskDelay(500);
NRF_LOG_INFO("%s : delay end", __func__);
}
}
static void taskA(void* arg) {
BaseType_t result;
while (1) {
NRF_LOG_INFO("%s : blocking take the semaphore", __func__);
result = xSemaphoreTake(s_semaphore_handle, portMAX_DELAY);
if (result == pdTRUE) {
NRF_LOG_INFO("%s : semaphore take success", __func__);
}
//////////////////////////////////////
// 排他区間(開始)
//////////////////////////////////////
NRF_LOG_INFO("%s : semaphore delay start", __func__);
vTaskDelay(100);
NRF_LOG_INFO("%s : semaphore delay end", __func__);
NRF_LOG_INFO("%s : semaphore give start", __func__);
xSemaphoreGive(s_semaphore_handle);
NRF_LOG_INFO("%s : semaphore give finish", __func__);
//////////////////////////////////////
// 排他区間(終了)
//////////////////////////////////////
NRF_LOG_INFO("%s : delay start", __func__);
vTaskDelay(200);
NRF_LOG_INFO("%s : delay end", __func__);
}
}
int main(void) {
s_semaphore_handle = xSemaphoreCreateBinary();
xSemaphoreGive(s_semaphore_handle);
xTaskCreate(taskA, "taskA", 128, NULL, 0, &s_task_A);
xTaskCreate(taskB, "taskB", 128, NULL, 0, &s_task_B);
vTaskStartScheduler();
for (;;) {
APP_ERROR_HANDLER(NRF_ERROR_FORBIDDEN);
}
}
こちらは、セマフォを割り込み検知では無く、タスク間の排他に使用する例です。
main関数等でセマフォを生成した直後にxSemaphoreGiveでtake可能な状態にしています。
セマフォを使用したいタスクは、排他制御したい区間をxSemaphoreTakeとxSemaphoreGiveで囲うようにして使用します。
task_A、task_Bの優先度が同じ場合は、giveのタイミングにタスクが切り替わる訳では無く、
xSemaphoreGive後にvTaskDelay等でタスクをBlocked状態やSuspended状態にする事で、
コンテキストスイッチが発生し、take待ちしていたタスクに処理が移ります。
task_A、task_Bのうち片方のタスク優先度を上げておき、
優先度の高いタスクがtakeできるのを待っているBlocked状態でセマフォをgiveすると、
直後にプリエンプションによるコンテキストスイッチが発生し、優先度の高いBlocked状態のタスクに処理が移ります。
カウンティングセマフォ
オブジェクトを生成した直後は動作許可がないという点(giveするまでtakeできない)では、
バイナリセマフォと同じですが、
このカウンティングセマフォはセマフォの数を管理する事ができるという特徴があり、
複数タスクからの同一資源へのアクセスや、アクセス数の監視を行うといった事を可能とします。
(Giveでカウンタを1増やし、Takeすると1減る仕組みです。)
前述したバイナリセマフォを使い、割り込みからセマフォをgiveする(タスクで割り込みを待つ)ような構成だった場合、
セマフォをtakeする側のタスク優先度によっては即座に動き出せなかったり、
割り込み後に開始したタスク内の処理が重い場合その間に再度発生した割り込みを取りこぼす、
といった可能性が出てきます。
割り込んだ回数を管理したい場合、カウンティングセマフォを使用すれば、
giveで数を加算してくれるので、待ち受ける側のタスクはカウントが0になるまでtakeする事が可能になります。
(割り込みを取りこぼす可能性が少なくなるはずです。上限を設定する必要があるため)
後述するキューの機能でも同様の事は可能ですが、データ構造を持つ必要がない場合などは、
カウンティングセマフォを使用した方が、処理時間やメモリの容量も抑えられそうですね。
コード例
static TaskHandle_t s_task_A;
static SemaphoreHandle_t s_semaphore_handle;
static void on_timer_isr(TimerHandle_t xTimer) {
BaseType_t result = xSemaphoreGive(s_semaphore_handle);
if (result == pdTRUE) {
NRF_LOG_INFO("%s : semaphore give success", __func__);
} else {
NRF_LOG_INFO("%s : semaphore give failed", __func__);
}
NRF_LOG_INFO("%s : semaphore count = %d", __func__, uxSemaphoreGetCount(s_semaphore_handle));
}
static void taskA(void* arg) {
BaseType_t result;
while (1) {
NRF_LOG_INFO("%s : blocking take the semaphore", __func__);
result = xSemaphoreTake(s_semaphore_handle, portMAX_DELAY);
if (result == pdTRUE) {
NRF_LOG_INFO("%s : semaphore take success", __func__);
}
NRF_LOG_INFO("%s : semaphore count = %d", __func__, uxSemaphoreGetCount(s_semaphore_handle));
vTaskDelay(2000);
}
}
int main(void) {
// 10がキューの深さ。0は生成直後に取得できるセマフォの初期値
s_semaphore_handle = xSemaphoreCreateCounting(10, 0);
s_timer_handle = xTimerCreate("Timer", 1000, pdTRUE, (void*) 0, on_timer_isr);
xTimerStart(s_timer_handle, 0);
xTaskCreate(taskA, "taskA", 128, NULL, 0, &s_task_A);
vTaskStartScheduler();
for (;;) {
APP_ERROR_HANDLER(NRF_ERROR_FORBIDDEN);
}
}
xSemaphoreCreateCountingでカウンティングセマフォを生成し、1000ms毎のタイマ割り込みからセマフォをgiveします。
task_Aはカウントが0になるまでセマフォのtakeが可能です。
カウントが0の状態でtakeを行うと、設定したtimeout時間に応じてBlocked状態に遷移します。
このケースでは、最大カウント数を10としているので、10カウント以上のgiveには失敗します。
また、カウンティングセマフォは生成した時点から取得可能なセマフォの数も設定でき、設定した数値分が即座にtake可能です。
ミューテックス
セマフォは排他制御や、割り込みからタスクへ動作の許可を示す同期処理的な意味合いで使用できるAPIでしたが、
ミューテックスは、複数タスク間でのリソース排他制御を行いたい場合に使用します。
ミューテックスはセマフォと違い、オブジェクトを生成したタイミングから取得(take)が可能です。
タスクは取得したミューテックスを最後に破棄(give)する事で、他の取得待ちタスクへアクセス権を与えられるようになります。
また、ミューテックスには優先度継承と呼ばれる機能を持っています。
(※これは、大体のRTOSが機能として持ってるはず。。)
これは、セマフォを排他制御に使用した場合に発生する優先度逆転現象に対応するための機能です。
例えば、タスクA(優先度:高)、タスクB(優先度:中) 、タスクC(優先度:低)のタスクがあり、タスクAとタスクBが、バイナリセマフォによる排他制御が行われているリソースにアクセスする処理があるとします。
ここで、先にタスクCがセマフォを取得(take)していた場合、タスクAはそのセマフォが解放(give)されるまで、Blocking状態になりますが、
この状態でタスクBがReady状態に遷移すると、プリエンプションによりタスクBが実行されてしまい、タスクAの実行開始が依存関係の無いタスクBにより遅れてしまうことになります。
(これを優先度逆転と呼び、いろんなRTOSの教科書に出てきます。)
FreeRTOSの優先度継承機能とは、ミューテックスの取得待ちでBlocking状態になったタスクの優先度が、現在ミューテックスを取得中のタスク優先度よりも高かった場合、
そのミューテックス取得中のタスク優先度を、Blocked状態のタスク優先度に引き上げる、というものになります。
つまり、
タスクA(優先度:高)、タスクB(優先度:中) 、タスクC(優先度:低)のような優先度のタスクがあり、
タスクC → タスクAの順番でミューテックスを取得しに行くようなタイミングがあった場合、
タスクCにタスクAの優先度が継承されるため(優先度:低→高)、タスクBの処理を挟まずにタスクCの処理が実行されるという事になります。
(タスクAのBlocking状態が短い時間で済むという事です。)
コード例
static TaskHandle_t s_task_A;
static TaskHandle_t s_task_B;
static TaskHandle_t s_task_C;
static SemaphoreHandle_t s_semaphore_handle;
static void taskB(void* arg) {
while (1) {
NRF_LOG_INFO("%s : Task B -> Running, Task C Priority = %d", __func__, uxTaskPriorityGet(s_task_C));
vTaskDelay(100);
}
}
static void taskA(void* arg) {
vTaskDelay(1000); // タスクCが初めにミューテックスを取得したいので、1000msディレイさせます
BaseType_t result;
while (1) {
NRF_LOG_INFO("%s : blocking take the mutex", __func__);
result = xSemaphoreTake(s_semaphore_handle, portMAX_DELAY);
if (result == pdTRUE) {
NRF_LOG_INFO("%s : mutex take success", __func__);
}
//////////////////////////////////////
// 排他区間(開始)
//////////////////////////////////////
vTaskDelay(150); // mutex取得状態を維持
NRF_LOG_INFO("%s : mutex give start", __func__);
xSemaphoreGive(s_semaphore_handle);
NRF_LOG_INFO("%s : mutex give finish", __func__);
//////////////////////////////////////
// 排他区間(終了)
//////////////////////////////////////
vTaskDelay(500);
}
}
static void taskC(void* arg) {
BaseType_t result;
while (1) {
NRF_LOG_INFO("%s : Priority before getting mutex = %d", __func__, uxTaskPriorityGet(s_task_C));
NRF_LOG_INFO("%s : blocking take the mutex", __func__);
result = xSemaphoreTake(s_semaphore_handle, portMAX_DELAY);
if (result == pdTRUE) {
NRF_LOG_INFO("%s : mutex take success", __func__);
}
//////////////////////////////////////
// 排他区間(開始)
//////////////////////////////////////
NRF_LOG_INFO("%s : Priority after getting mutex = %d", __func__, uxTaskPriorityGet(s_task_C));
NRF_LOG_INFO("%s : loop start", __func__);
// Running状態を維持する処理ループ
for (int i = 0; i < 20000000; i++) {
}
NRF_LOG_INFO("%s : loop end", __func__);
NRF_LOG_INFO("%s : Priority after getting mutex = %d", __func__, uxTaskPriorityGet(s_task_C));
NRF_LOG_INFO("%s : mutex give start", __func__);
xSemaphoreGive(s_semaphore_handle);
NRF_LOG_INFO("%s : mutex give finish", __func__);
//////////////////////////////////////
// 排他区間(終了)
//////////////////////////////////////
vTaskDelay(100);
}
}
int main(void) {
s_semaphore_handle = xSemaphoreCreateMutex();
xTaskCreate(taskA, "taskA", 128, NULL, 2, &s_task_A);
xTaskCreate(taskB, "taskB", 128, NULL, 1, &s_task_B);
xTaskCreate(taskC, "taskC", 128, NULL, 0, &s_task_C);
vTaskStartScheduler();
for (;;) {
APP_ERROR_HANDLER(NRF_ERROR_FORBIDDEN);
}
}
まず、main関数でミューテックス・task_A(優先度:2)、B(優先度:1)、C(優先度:0)を作成します。
各タスクの動作は以下のようになります。
-
task_Aは(起動時のみ1000msのTaskDelay後)以下を繰り返します
- ①ミューテックスをtake
- ②TaskDelay(150)
- ③ミューテックスをgive
- ④TaskDelay(500)
-
task_Bは以下を繰り返します
- ①task_Cの優先度をコンソール出力
- ②TaskDelay(100)
-
task_Cは100ms毎に、
- ①ミューテックスをtake
- ②処理想定のforループ
- ③ミューテックスをgive
- ④TaskDelay(100)
優先度により、まずはtask_Aが起動しますが、vTaskDelay(1000)によりBlocked状態に遷移します。
その間にtask_Bが起動、100ms毎のログ出力を開始しだすので、
その後起動するtask_Cが、最初にミューテックスを取得する事になります。
task_Cがforループ処理中も、優先度により定期的にtask_Bにタスクスイッチし、
コンソールログ出力が行われるのですが、
task_Aがミューテックスの取得待ちでBlocked状態になると、task_Cの優先度が2に引き上げられるので、task_Bへのプリエンプションが発生しなくなります。
その後、task_Cがミューテックスをgiveするとその時点でプリエンプションが発生し、task_Aの処理がはじまります。(task_Cは優先度が0に戻ります)
task_AがvTaskDelay(150)している間に、task_Cがミューテックスの取得待ちになり、
task_AはBlocked状態からの復帰後にミューテックスをgiveしますが、
その時点ではtask_Cにタスクスイッチはしません。(優先度の関係上)
task_AがvTaskDelay(500)を行う事でBlocked状態に遷移し、task_CがRunning状態に遷移してミューテックスtake後の処理が再び行われます。
再帰的ミューテックス
通常のミューテックスでは、giveする事なく再度takeするとデッドロック状態になります。
つまり、タスクはミューテックスが取得できるまでBlocked状態となりますが、
そのタスクがすでにミューテックスの保有者となっている場合、自分自身を待つことになるのでデッドロック状態となってしまうのです。
それに対して再帰的ミューテックスは、
すでにミューテックスを取得しているタスクが、再度ミューテックスを取得する事を可能とします。
ネストしてtake出来るという事ですが、解放するためにはtakeと同じ回数分のgiveを呼ぶ必要があります。
コード例
static TaskHandle_t s_task_A;
static TaskHandle_t s_task_B;
static SemaphoreHandle_t s_recursive_mutex_handle;
static void taskA(void* arg) {
xSemaphoreTakeRecursive(s_recursive_mutex_handle, portMAX_DELAY);
NRF_LOG_INFO("%s : Recursive Mutex Take 1!!", __func__);
vTaskDelay(pdMS_TO_TICKS(1000));
xSemaphoreTakeRecursive(s_recursive_mutex_handle, portMAX_DELAY);
NRF_LOG_INFO("%s : Recursive Mutex Take 2!!", __func__);
vTaskDelay(pdMS_TO_TICKS(1000));
xSemaphoreTakeRecursive(s_recursive_mutex_handle, portMAX_DELAY);
NRF_LOG_INFO("%s : Recursive Mutex Take 3!!", __func__);
vTaskDelay(pdMS_TO_TICKS(1000));
xSemaphoreGiveRecursive(s_recursive_mutex_handle);
NRF_LOG_INFO("%s : Recursive Mutex Give 1!!", __func__);
vTaskDelay(pdMS_TO_TICKS(1000));
xSemaphoreGiveRecursive(s_recursive_mutex_handle);
NRF_LOG_INFO("%s : Recursive Mutex Give 2!!", __func__);
vTaskDelay(pdMS_TO_TICKS(1000));
xSemaphoreGiveRecursive(s_recursive_mutex_handle);
NRF_LOG_INFO("%s : Recursive Mutex Give 3!!", __func__);
vTaskSuspend(NULL);
}
static void taskB(void* arg) {
while (1) {
if (xSemaphoreTakeRecursive(s_recursive_mutex_handle, 1000) == pdTRUE) {
NRF_LOG_INFO("%s : Recursive Mutex Take !!", __func__);
vTaskSuspend(NULL);
}
NRF_LOG_INFO("%s : Recursive Mutex Take Failed!!", __func__);
}
}
int main(void) {
s_recursive_mutex_handle = xSemaphoreCreateRecursiveMutex();
xTaskCreate(taskA, "taskA", 128, NULL, 0, &s_task_A);
xTaskCreate(taskB, "taskB", 128, NULL, 0, &s_task_B);
vTaskStartScheduler();
for (;;) {
APP_ERROR_HANDLER(NRF_ERROR_FORBIDDEN);
}
}
まず、task_Aがネストしてミューテックスを取得します。
task_Aがtakeする毎にvTaskDelayでBlocked状態になるので、
その間にtask_Bがミューテックスの取得を試みますが、ネストしてtakeした分のgiveを行うまでミューテックスが解放されないため、
taskAが3回目のgiveを終えたら、初めてtask_Bがミューテックスの取得ができるようになります。
3. タスク間通信
event flag(gloup)
タスク間通信の機能の中でも、イベントフラグ(グループ)が持つ最も特徴的な仕様は、以下の2点です。
- 1つのタスクが複数のタスクからのイベントを同時に待てる
- 複数のタスクを同時にBlocked状態からReady状態に遷移させる
イベントグループを使用すれば複数のタスクからのイベントを1回のBlocking状態で同期的に待ち受ける事が出来るようになります。
全てのビットが立つまで待ち受けたり、一つでもビットが立てば動作を開始できたりと柔軟に使えそうです。
また、1つのイベントを待ち受けるようなケースであれば、セマフォ(ミューテックス)でも同様の事が可能ですが、
イベントフラグ(グループ)は同じイベントを待ち受ける複数のタスクを同時にReady状態に遷移させられるという特徴があるので、
実現したい事に応じてAPIを使い分ける必要があるでしょう。
ただし、
ISRからイベントグループに対する行うビット操作要求は、実際にはその操作をデーモンタスクが行っているため、
ISRからのビット操作でBlocked状態から抜けるタスクは、デーモンタスクのコンテキストで実行される点に注意です。
コード例1
#define TASK_B_EVENT (1 << 0)
#define TASK_C_EVENT (1 << 1)
#define TASK_D_EVENT (1 << 2)
#define TASK_ALL_EVENT (TASK_B_EVENT | TASK_C_EVENT | TASK_D_EVENT)
static TaskHandle_t s_task_A;
static TaskHandle_t s_task_B;
static TaskHandle_t s_task_C;
static TaskHandle_t s_task_D;
static EventGroupHandle_t s_event_group_handle;
static void taskA(void* arg) {
while (1) {
NRF_LOG_INFO("%s : blocking Set the Events", __func__);
EventBits_t event_bits = xEventGroupWaitBits(s_event_group_handle, TASK_ALL_EVENT, pdTRUE, pdTRUE, portMAX_DELAY);
if (event_bits == TASK_ALL_EVENT) {
NRF_LOG_INFO("%s : All Event Get!!", __func__);
}
}
}
static void taskB(void* arg) {
while (1) {
vTaskDelay(1000);
NRF_LOG_INFO("%s : Task B Event Set", __func__);
xEventGroupSetBits(s_event_group_handle, TASK_B_EVENT);
vTaskSuspend(NULL);
}
}
static void taskC(void* arg) {
while (1) {
vTaskDelay(2000);
NRF_LOG_INFO("%s : Task C Event Set", __func__);
xEventGroupSetBits(s_event_group_handle, TASK_C_EVENT);
vTaskSuspend(NULL);
}
}
static void taskD(void* arg) {
while (1) {
vTaskDelay(3000);
NRF_LOG_INFO("%s : Task D Event Set", __func__);
xEventGroupSetBits(s_event_group_handle, TASK_D_EVENT);
vTaskSuspend(NULL);
}
}
int main(void) {
s_event_group_handle = xEventGroupCreate();
xTaskCreate(taskA, "taskA", 128, NULL, 1, &s_task_A);
xTaskCreate(taskB, "taskB", 128, NULL, 0, &s_task_B);
xTaskCreate(taskC, "taskC", 128, NULL, 0, &s_task_C);
xTaskCreate(taskD, "taskD", 128, NULL, 0, &s_task_D);
vTaskStartScheduler();
for (;;) {
APP_ERROR_HANDLER(NRF_ERROR_FORBIDDEN);
}
}
task_Aが、task_B、task_C、task_Dの全てのイベント通知が来るのを待つパターンのコード例です。
task_Aは、起動後に各タスクがセットする3つのビットが全てセットされるまで、Blocked状態に遷移します。(xEventGroupWaitBitsの引数xWaitForAllBitsをpdTRUEにする)
その後、task_B・task_C・task_Dがそれぞれビットをセットする事で、
task_AがRunning状態に遷移します。
イベント受信後に、イベントグループにセットされているビットをクリアしたい場合には、
引数xClearOnExitをpdTRUEに設定して使用します。
コード例2
#define TASK_B_EVENT (1 << 0)
#define TASK_C_EVENT (1 << 1)
#define TASK_D_EVENT (1 << 2)
#define TASK_ALL_EVENT (TASK_B_EVENT | TASK_C_EVENT | TASK_D_EVENT)
static TaskHandle_t s_task_A;
static TaskHandle_t s_task_B;
static TaskHandle_t s_task_C;
static TaskHandle_t s_task_D;
static EventGroupHandle_t s_event_group_handle;
static void taskA(void* arg) {
while (1) {
NRF_LOG_INFO("%s : blocking Set the Events", __func__);
EventBits_t event_bits = xEventGroupWaitBits(s_event_group_handle, TASK_ALL_EVENT, pdTRUE, pdFALSE, portMAX_DELAY);
if (event_bits == TASK_B_EVENT) {
NRF_LOG_INFO("%s : Task B Event Get!!", __func__);
}
if (event_bits == TASK_C_EVENT) {
NRF_LOG_INFO("%s : Task C Event Get!!", __func__);
}
if (event_bits == TASK_D_EVENT) {
NRF_LOG_INFO("%s : Task D Event Get!!", __func__);
}
}
}
static void taskB(void* arg) {
while (1) {
vTaskDelay(1000);
NRF_LOG_INFO("%s : Task B Event Set", __func__);
xEventGroupSetBits(s_event_group_handle, TASK_B_EVENT);
vTaskSuspend(NULL);
}
}
static void taskC(void* arg) {
while (1) {
vTaskDelay(2000);
NRF_LOG_INFO("%s : Task C Event Set", __func__);
xEventGroupSetBits(s_event_group_handle, TASK_C_EVENT);
vTaskSuspend(NULL);
}
}
static void taskD(void* arg) {
while (1) {
vTaskDelay(3000);
NRF_LOG_INFO("%s : Task D Event Set", __func__);
xEventGroupSetBits(s_event_group_handle, TASK_D_EVENT);
vTaskSuspend(NULL);
}
}
int main(void) {
s_event_group_handle = xEventGroupCreate();
xTaskCreate(taskA, "taskA", 128, NULL, 1, &s_task_A);
xTaskCreate(taskB, "taskB", 128, NULL, 0, &s_task_B);
xTaskCreate(taskC, "taskC", 128, NULL, 0, &s_task_C);
xTaskCreate(taskD, "taskD", 128, NULL, 0, &s_task_D);
vTaskStartScheduler();
for (;;) {
APP_ERROR_HANDLER(NRF_ERROR_FORBIDDEN);
}
}
task_Aが、task_B、task_C、task_Dからのイベント通知がどれかひとつでも来るのを待つパターンのコード例です。
task_Aは、起動後に各タスクがどれか一つでもビットをセットするまで、Blocked状態に遷移します。(xEventGroupWaitBitsの引数xWaitForAllBitsをpdFALSEにする)
その後、task_B・task_C・task_Dがそれぞれビットをセットする毎に、task_AがRunning状態に遷移します。
コード例3
#define TASK_A_EVENT (1 << 0)
#define TASK_B_EVENT (1 << 1)
#define TASK_C_EVENT (1 << 2)
#define TASK_D_EVENT (1 << 3)
#define TASK_ALL_EVENT (TASK_A_EVENT | TASK_B_EVENT | TASK_C_EVENT | TASK_D_EVENT)
static TaskHandle_t s_task_A;
static TaskHandle_t s_task_B;
static TaskHandle_t s_task_C;
static TaskHandle_t s_task_D;
static EventGroupHandle_t s_event_group_handle;
static void taskA(void* arg) {
while (1) {
vTaskDelay(pdMS_TO_TICKS(1000));
NRF_LOG_INFO("%s : Task A Set the Event", __func__);
xEventGroupSync(s_event_group_handle, TASK_A_EVENT, TASK_ALL_EVENT, portMAX_DELAY);
NRF_LOG_INFO("%s : Each task will proceed synchronously", __func__);
}
}
static void taskB(void* arg) {
while (1) {
vTaskDelay(pdMS_TO_TICKS(2000));
NRF_LOG_INFO("%s : Task B Set the Event", __func__);
xEventGroupSync(s_event_group_handle, TASK_B_EVENT, TASK_ALL_EVENT, portMAX_DELAY);
NRF_LOG_INFO("%s : Each task will proceed synchronously", __func__);
}
}
static void taskC(void* arg) {
while (1) {
vTaskDelay(pdMS_TO_TICKS(3000));
NRF_LOG_INFO("%s : Task C Set the Event", __func__);
xEventGroupSync(s_event_group_handle, TASK_C_EVENT, TASK_ALL_EVENT, portMAX_DELAY);
NRF_LOG_INFO("%s : Each task will proceed synchronously", __func__);
}
}
static void taskD(void* arg) {
while (1) {
vTaskDelay(pdMS_TO_TICKS(4000));
NRF_LOG_INFO("%s : Task D Set the Event", __func__);
xEventGroupSync(s_event_group_handle, TASK_D_EVENT, TASK_ALL_EVENT, portMAX_DELAY);
NRF_LOG_INFO("%s : Each task will proceed synchronously", __func__);
}
}
int main(void) {
s_event_group_handle = xEventGroupCreate();
xTaskCreate(taskA, "taskA", 128, NULL, 0, &s_task_A);
xTaskCreate(taskB, "taskB", 128, NULL, 0, &s_task_B);
xTaskCreate(taskC, "taskC", 128, NULL, 0, &s_task_C);
xTaskCreate(taskD, "taskD", 128, NULL, 0, &s_task_D);
vTaskStartScheduler();
for (;;) {
APP_ERROR_HANDLER(NRF_ERROR_FORBIDDEN);
}
}
このパターンは、各タスク同士が同期的に動作したい場合のケースを想定しています。
xEventGroupSyncを使用する事で各タスクが自身のイベントビットをセットしつつ、
引数uxBitsToWaitForで設定したビットパターンが全てセットされるのをBlocked状態で待ち受けます。
この使い方により、各タスクがビットをセットするタイミングは異なりますが、
xEventGroupSyncでBlocked状態となっているタスクを、同時にReady状態に遷移させる事が可能です。
stream buffer/message buffer
タスク間で可変長データの送受信を行いたい場合などに使用されるようです。
受信側が任意の長さでデータ受信を待ち受けられる事が特徴ですが、
必ずしも受信側が指定したサイズ分のデータを受信する事でunblockされる、というわけでも無く、ちょっとだけ条件が複雑です。
コード例
static TaskHandle_t s_task_A;
static TaskHandle_t s_task_B;
static StreamBufferHandle_t s_stream_buffer;
static void taskA(void* arg) {
uint8_t rx_buf[100];
size_t rx_size;
while (1) {
rx_size = xStreamBufferReceive(s_stream_buffer, rx_buf, 10, 1000);
NRF_LOG_INFO("%s : Stream Buffer Receive!! rx_size=%d, Available=%d", __func__, rx_size, xStreamBufferBytesAvailable(s_stream_buffer));
NRF_LOG_HEXDUMP_INFO(rx_buf, rx_size);
// vTaskDelay(pdMS_TO_TICKS(5000)); // バッファに溜まるのを待ちたい場合
}
}
static void taskB(void* arg) {
static uint8_t counter = 0;
while (1) {
xStreamBufferSend(s_stream_buffer, &counter, sizeof(counter), portMAX_DELAY);
NRF_LOG_INFO("%s : Stream Buffer Send!! count=%d, space=%d", __func__, counter, xStreamBufferSpacesAvailable(s_stream_buffer));
counter++;
vTaskDelay(pdMS_TO_TICKS(400));
}
}
int main(void) {
s_stream_buffer = xStreamBufferCreate(100, 5);
xTaskCreate(taskA, "taskA", 128, NULL, 0, &s_task_A);
xTaskCreate(taskB, "taskB", 128, NULL, 0, &s_task_B);
vTaskStartScheduler();
for (;;) {
APP_ERROR_HANDLER(NRF_ERROR_FORBIDDEN);
}
}
xStreamBufferCreateでオブジェクトを生成しますが、100はバッファのサイズを表します(xBufferSizeBytes)。
xTriggerLevelBytesはデータの受信(バッファからの読み出し)を許可するサイズを指定する事ができます。
task_Bが400ms毎に1byteずつデータを送信するのに対して、
task_AがxStreamBufferReceiveでBlocked状態となり、xBufferLengthBytes10でデータを待ち受けます。
この時、task_AがBlocked状態から抜けた時に受信できるデータのサイズは、5〜10バイトになります。
つまり、xStreamBufferCreateでxTriggerLevelBytesを5としているので、
xStreamBufferReceiveでxBufferLengthBytesを10としても、xStreamBufferReceiveを呼んだ時点で溜まっているデータが5byteあると
(もしくは、xStreamBufferReceiveを呼んでから5byte受信した時)、
すぐにunblockされるという事です。
逆に、10byte以上受信されていてもxBufferLengthBytesが10に設定されているので、
取り出せるのは10byteとなります。
xStreamBufferBytesAvailableでバッファから取り出す前のバイト数を、
xStreamBufferSpacesAvailableで送信可能なバイト数(空き領域)を知る事が可能です。
Queue
キューはその名の通り、要求をFIFO形式でキューに積むものです。
それは積まれた順に処理されるため、セマフォとは違い要求された処理の順序性が担保されるという特徴があります。
セマフォやミューテックスも多重要求があった場合に内部的にはキューイングされますが、
タスクの優先度によって必ずしも要求順に資源を獲得できる訳ではないので、
順序性を必要とする排他制御などには、キューを使用すると良いかもしれません。
FLASHへのログ書き込みのリクエストをミューテックスを使用した排他制御で実装したとすると、
要求元の優先度が異なる場合、時系列順にログが書き込まれないといったケースが発生します。
コード例
typedef struct {
char* p_task_name;
} queue_struct_t;
static TaskHandle_t s_task_A;
static TaskHandle_t s_task_B;
static TaskHandle_t s_task_C;
static TaskHandle_t s_task_D;
static QueueHandle_t s_queue_handle;
static void taskA(void* arg) {
queue_struct_t rcv_queue;
while (1) {
if (xQueueReceive(s_queue_handle, &rcv_queue, portMAX_DELAY) != pdFAIL) {
NRF_LOG_INFO("%s : Queue send from %s", __func__, rcv_queue.p_task_name);
}
}
}
static void taskB(void* arg) {
queue_struct_t send_queue;
send_queue.p_task_name = pcTaskGetName(s_task_B);
while (1) {
vTaskDelay(pdMS_TO_TICKS(1000));
if (xQueueSend(s_queue_handle, (void*) &send_queue, 10) != pdPASS) {
APP_ERROR_HANDLER(NRF_ERROR_NO_MEM);
}
}
}
static void taskC(void* arg) {
queue_struct_t send_queue;
send_queue.p_task_name = pcTaskGetName(s_task_C);
while (1) {
vTaskDelay(pdMS_TO_TICKS(2000));
if (xQueueSend(s_queue_handle, (void*) &send_queue, 10) != pdPASS) {
APP_ERROR_HANDLER(NRF_ERROR_NO_MEM);
}
}
}
static void taskD(void* arg) {
queue_struct_t send_queue;
send_queue.p_task_name = pcTaskGetName(s_task_D);
while (1) {
vTaskDelay(pdMS_TO_TICKS(3000));
if (xQueueSend(s_queue_handle, (void*) &send_queue, 10) != pdPASS) {
APP_ERROR_HANDLER(NRF_ERROR_NO_MEM);
}
}
}
int main(void) {
s_queue_handle = xQueueCreate(8, sizeof(queue_struct_t));
xTaskCreate(taskA, "taskA", 128, NULL, 1, &s_task_A);
xTaskCreate(taskB, "taskB", 128, NULL, 0, &s_task_B);
xTaskCreate(taskC, "taskC", 128, NULL, 0, &s_task_C);
xTaskCreate(taskD, "taskD", 128, NULL, 0, &s_task_D);
vTaskStartScheduler();
for (;;) {
APP_ERROR_HANDLER(NRF_ERROR_FORBIDDEN);
}
}
このコード例では、task_B、task_C、task_Dが各々のタイミングで、キューに対し送信を行います。
キューに対して送受信するデータの型はqueue_struct_tで定義していて、各送信側のタスク名のポインタを渡すようにしています。
task_Aは起動後、xQueueReceiveでBlocked状態になっており、キューの受信を契機にRunning状態に遷移し、タスク名をコンソール出力します。
送信側のxQueueSendにもtimeoutの時間を設定できるのですが、
これは、キューの受信数にも上限があるため、仮にキューの送信時に受信数が上限一杯だった時に、
受信キューからデータがpopされて空きができるのを、timeoutに設定した時間分待つ事が可能とします。
Notification
他のタスク間通信の機構と異なり、中間オブジェクトを生成しないという特徴があり、
省メモリで他のAPIに比べて処理が速いようです。
(実測したわけではないので、どれぐらいの性能差があるのかは不明ですが。)
メモリの消費量も1タスクあたり8byte固定となります。
また、Notifyは送信側が複数回送信したらキューイングされているという訳ではなく、
1つの値しか保持しておけないという制約があるため、
使い方次第では前回のNotification Valueを取り逃してしまった、といったケースも考えられそうです。
セマフォ/ミューテックスに似ている部分もありますが、Notificationは4バイト長のメッセージの送受信を可能とするため、通知内容に応じた処理をする、といった事が可能になります。
(セマフォ/ミューテックスの方がより機能としてはシンプルで原始的です。)
また、イベントフラグ(グループ)的な使い方もでき、タスクハンドルさえ分かれば
Notificationの送信が可能なので、複数タスクからのイベント(ビットセット)を待ち受ける、といった使い方も可能です。
イベントフラグ(グループ)のように複数のタスクを同時にReady状態に遷移させたい訳ではない場合、
Notificationの機能を使用すれば、中間オブジェクトも不要になるため処理速度の向上とメモリの削減が見込めそうです。
コード例1
#define TASK_B_EVENT (1 << 1)
#define TASK_C_EVENT (1 << 2)
#define TASK_D_EVENT (1 << 3)
static TaskHandle_t s_task_A;
static TaskHandle_t s_task_B;
static TaskHandle_t s_task_C;
static TaskHandle_t s_task_D;
static void taskA(void* arg) {
uint32_t notify;
while (1) {
if (xTaskNotifyWait(0xffffffff, 0xffffffff, ¬ify, portMAX_DELAY) != pdFAIL) {
NRF_LOG_INFO("%s : Notification Value %d", __func__, notify);
}
}
}
static void taskB(void* arg) {
uint32_t notify = TASK_B_EVENT;
while (1) {
vTaskDelay(pdMS_TO_TICKS(1000));
if (xTaskNotify(s_task_A, notify, eSetValueWithOverwrite) != pdPASS) {
NRF_LOG_INFO("%s : Notification send failed", __func__);
}
vTaskSuspend(NULL);
}
}
static void taskC(void* arg) {
uint32_t notify = TASK_C_EVENT;
while (1) {
vTaskDelay(pdMS_TO_TICKS(2000));
if (xTaskNotify(s_task_A, notify, eSetValueWithOverwrite) != pdPASS) {
NRF_LOG_INFO("%s : Notification send failed", __func__);
}
vTaskSuspend(NULL);
}
}
static void taskD(void* arg) {
uint32_t notify = TASK_D_EVENT;
while (1) {
vTaskDelay(pdMS_TO_TICKS(3000));
if (xTaskNotify(s_task_A, notify, eSetValueWithOverwrite) != pdPASS) {
NRF_LOG_INFO("%s : Notification send failed", __func__);
}
vTaskSuspend(NULL);
}
}
このコード例は、uint32_tの範囲で表現できる任意の値を、タスクに送信するケースです。
task_Aは、xTaskNotifyWaitで通知が来るまでBlocked状態に遷移します。
Notificationは通信用のオブジェクトの生成が不要なので、送信側のタスクはタスクハンドルが分かれば、通知が可能です。
ただし、Notificationは一つの値しか保持できないので、設定によってはtask_Aは受信待ちする前に、xTaskNotifyが重なると送信されてきた値を取りこぼす可能性がある点に注意してください。
また、受信するまで(xTaskNotifyWaitを呼ぶまで)受信した値はpending状態(保留)になるため、
それを解消したい場合、xTaskNotifyStateClearでpending状態をクリアする事もできます。
xTaskNotifyWaitの引数ulBitsToClearOnEntryは、
Notificationの受信待ちよりも前(xTaskNotifyWait呼び出し前)にxTaskNotifyされていた場合(pending)に、
Notification valueをulBitsToClearOnEntryで設定した任意のビットでクリアできます。
(0xFFFFFFFFに設定すると、0クリアされる事になります。)
ulBitsToClearOnExitも同じく、
xTaskNotifyWaitで値を受信した後のNotification Valueを
ulBitsToClearOnExitで設定した任意のビットでクリアする事ができます。
(0xFFFFFFFFに設定すると、0クリアされる事になります。)
※notifyで受け取る、*pulNotificationValueは、クリア前の値です!
送信側のタスクは、xTaskNotifyの引数にeSetValueWithOverwriteをセットしていますが、
これは、受信タスクがまだNotification Valueを取り出していない場合(pending)であっても、
新しい値で上書く、という設定です。
受信タスクがまだNotification Valueを取り出していない場合(pending状態)に、
新しい通知で上書きしたくない場合は、eSetValueWithoutOverwriteにする事で、Notifyの送信に失敗して終了することができます。
コード例2
// デーモンタスクのタイマーハンドラですが、
static void on_timer_isr(TimerHandle_t xTimer) {
uint32_t notify = 0;
if (xTaskNotify(s_task_A, notify, eIncrement) != pdPASS) {
NRF_LOG_INFO("%s : Notification send failed", __func__);
}
}
static void taskA(void* arg) {
uint32_t notify;
while (1) {
vTaskDelay(10000);
if (xTaskNotifyWait(0xffffffff, 0xffffffff, ¬ify, portMAX_DELAY) != pdFAIL) {
NRF_LOG_INFO("%s : Notification Count = %d", __func__, notify);
while (notify > 0) {
NRF_LOG_INFO("%s : TaskA Processing", __func__);
notify--;
}
}
}
}
int main(void) {
s_timer_handle = xTimerCreate("Timer", 800, pdTRUE, (void*) 0, on_timer_isr);
xTimerStart(s_timer_handle, 0);
xTaskCreate(taskA, "taskA", 128, NULL, 0, &s_task_A);
vTaskStartScheduler();
for (;;) {
APP_ERROR_HANDLER(NRF_ERROR_FORBIDDEN);
}
}
Notificationをカウンティングセマフォのように使用する方法です。
xTaskNotifyの引数にeIncrementを使用することで、Notification Valueをインクリメントしていく使い方ができます。
xTaskNotifyWaitのulBitsToClearOnExitを0xFFFFFFFFにすることで、
そこまでのカウント値をクリアする事ができます。
※notifyで受け取る、*pulNotificationValueは、クリア前のカウント値です!
コード例3
#define TASK_B_EVENT (1 << 1)
#define TASK_C_EVENT (1 << 2)
#define TASK_D_EVENT (1 << 3)
#define TASK_ALL_EVENT (TASK_B_EVENT | TASK_C_EVENT | TASK_D_EVENT)
static TaskHandle_t s_task_A;
static TaskHandle_t s_task_B;
static TaskHandle_t s_task_C;
static TaskHandle_t s_task_D;
static void taskA(void* arg) {
uint32_t notify;
while (1) {
if (xTaskNotifyWait(0, 0, ¬ify, portMAX_DELAY) != pdFAIL) {
NRF_LOG_INFO("%s : Notification Receive = %d", __func__, notify);
if (notify == TASK_ALL_EVENT) {
NRF_LOG_INFO("%s : All Event Get!!", __func__);
// ulTaskNotifyValueClear(s_task_A, 0xFFFFFFFF);
xTaskNotifyWait(0xFFFFFFFF, 0, NULL, 0);
vTaskResume(s_task_B);
vTaskResume(s_task_C);
vTaskResume(s_task_D);
}
}
}
}
static void taskB(void* arg) {
uint32_t notify = TASK_B_EVENT;
while (1) {
vTaskDelay(pdMS_TO_TICKS(1000));
if (xTaskNotify(s_task_A, notify, eSetBits) != pdPASS) {
NRF_LOG_INFO("%s : Notification send failed", __func__);
}
vTaskSuspend(NULL);
}
}
static void taskC(void* arg) {
uint32_t notify = TASK_C_EVENT;
while (1) {
vTaskDelay(pdMS_TO_TICKS(2000));
if (xTaskNotify(s_task_A, notify, eSetBits) != pdPASS) {
NRF_LOG_INFO("%s : Notification send failed", __func__);
}
vTaskSuspend(NULL);
}
}
static void taskD(void* arg) {
uint32_t notify = TASK_D_EVENT;
while (1) {
vTaskDelay(pdMS_TO_TICKS(3000));
if (xTaskNotify(s_task_A, notify, eSetBits) != pdPASS) {
NRF_LOG_INFO("%s : Notification send failed", __func__);
}
vTaskSuspend(NULL);
}
}
int main(void) {
xTaskCreate(taskA, "taskA", 128, NULL, 0, &s_task_A);
xTaskCreate(taskB, "taskB", 128, NULL, 0, &s_task_B);
xTaskCreate(taskC, "taskC", 128, NULL, 0, &s_task_C);
xTaskCreate(taskD, "taskD", 128, NULL, 0, &s_task_D);
vTaskStartScheduler();
for (;;) {
APP_ERROR_HANDLER(NRF_ERROR_FORBIDDEN);
}
}
このコード例は、Notificationをイベントグループの様に使用する事で、
task_Aが、task_B、task_C、task_Dの全てのイベント通知が来るのを待つパターンのコード例です。
task_Aは、xTaskNotifyWaitでNotification受信を待つBlocked状態に遷移します。
各タスクがxTaskNotifyする毎に、task_AはRunning状態に遷移するのですが、
Notification Valueに全てのビットがセットされていない場合は、再度xTaskNotifyWaitでBlocked状態となります。
xTaskNotifyWaitの引数ulBitsToClearOnEntry、ulBitsToClearOnExitを共に0に設定しておく事で、受信後もNotification Valueを維持しています。
全てのイベントが受信できたと判定できたら、
xTaskNotifyWait(0xFFFFFFFF, 0, NULL, 0);でNotification Valueをクリアしています。
ただ単に、Notification Valueをクリアするだけであれば、ulTaskNotifyValueClearを使用するのが良さそうですが、v10.0.0にはないAPIのようです。
4. RTOSでのリソース排他方法
1. ゲートキーパータスク
特定のデバイスなどへのアクセスの入り口となるタスクを用意する設計手法があります。
(FreeRTOSでは、ゲートキーパータスクと用語が付けられていました。。)
他のタスクがあるリソースにアクセスしたい場合、それらをゲートキーパータスクを介して間接的にアクセスさせるというものです。
例えば、タスクA(優先度:低)、タスクB(優先度:高)2つのタスクが存在し、
各タスクから外部メモリやRTCにアクセスできるような実装であった時に、
タスクAがRTCにアクセス中に、タスクBにプリエンプトされる事もOSの仕様上ありえますが、
この時、タスクBもRTCへのアクセスが必要だった場合、排他処理などの機構が実装されていないと、処理がかち合う事で予期しない動作の元になる事が想像できます。
ゲートキーパータスクを用いると、複数のタスクからのアクセスが必要とされるデバイスへのアクセスが、
一つのタスクからしか行われないため、資源に対する同時アクセスなどによる競合が起こらなくなります。
例えば、今回のFreeRTOSポーティングで実装したRTCやFLASHにアクセスする機能は、デバイス単位でタスクを実装したのですが、
spiやi2cなどは同じバス上に複数のデバイスが繋がっている場合には、競合が発生しないようにペリフェラルレベルでのタスク化も必要あるかもしれませんし、
i2cはNordicが提供するTWI Managerを使用すれば、ペリフェラルレベルでのタスク化は必要ないかもしれず、そこはケースバイケースですね。
ゲートキーパータスクをミューテックスを使用した構成にした場合、ミューテックスを取得待ちするタスクが複数あると、その要求は内部的にキューイングされる実装になってはいるのですが、
優先度によってはキューされた順番に処理されない可能性があるので、それをよしとするかどうかかと思われます。
要求を出されたものから順にこなしたい場合には、キュー一択だと思います。
また、メッセージキューの場合、メッセージ(要求)を一度投げさえすれば、処理が行われる間にそのタスクは別のことができる利点もあります。
(だいたいはその後、何かしら結果を待ち受ける機構にはなると思いますが。。)
2. 割り込み禁止
taskENTER_CRITICAL()、taskEXIT_CRITICAL()でクリティカルセクションを作る事が可能です。
タスクのコンテキストスイッチ・割り込みが共に禁止の状態となります。
(コンテキストスイッチも禁止の状態となるのは、タスクの切り替えもsystick割込みにより実現しているためのようです)
割り込みから使用する場合は、
taskENTER_CRITICAL_FROM_ISR()、taskEXIT_CRITICAL_FROM_ISR()を使用してください。
これらのAPIはネストさせて呼び出す事が可能です。
critial region enter()は使っちゃダメ??
3. タスクコンテキストスイッチの禁止
vTaskSuspendAll()で、OSのスケジューラのみを停止する事が出来ます。
この方法では、割り込みが禁止状態になる事はないため、何かの資源を他のタスクからのみ守りたいケースに使用するのが良さそうです。
ただし、プリエンプションやタイムスライシングが無効な設定となっている場合は、
タスクに割り込まれる事が無いので、考える必要はありません。
サスペンド状態からの復帰は、xTaskResumeAll()で可能です。
(サスペンド状態で発生したコンテキストスイッチは、ペンディングされるようになっており、レジュームされるタイミングで実行されます。)
こちらも、APIをネストさせて呼ぶ事が可能です。
5.デバッグに役立つ機能
1. ヒープサイズの調整
前述したFreeRTOSが提供する多様な機能は(キュー、イベントフラグ、タスク、セマフォ)、OSカーネルが動的にRAMを確保してオブジェクトを生成させる事で利用する事ができます。
(ヒープ領域の管理はOSがやってくれており、その方法は何通りか存在します)
しかし、これらの機能は動的にメモリを使用する分、オブジェクトが利用されなくなったタイミングでメモリ領域の解放をしないと、ヒープ領域が枯渇していく可能性があります。
※ヒープの設定によっては(Heap1.c)、生成したオブジェクトを削除できないので注意する必要があります。
空いているヒープ領域を確認する方法
xPortGetFreeHeapSize()を使用する事で、フリーになっているサイズを取得する事ができます。
configTOTAL_HEAP_SIZEで設定する、ヒープサイズの調整に使用できます。
Malloc Failed Hook 関数
FreeRTOSはヒープ領域を使用する各オブジェクト生成の際、
RAM不足が要因で失敗した時に、hookしてくれる機能があります。
この機能を有効にした場合は、以下のような関数をユーザーコードに実装する事でフックが可能です。
void vApplicationMallocFailedHook(void) {
#ifdef DEBUG
NRF_BREAKPOINT_COND;
#endif
configASSERT(0);
}
動的オブジェクトの生成時にこの関数が呼ばれたら、ヒープ領域が足りない事が原因となるので、
ヒープ領域として設定しているconfigTOTAL_HEAP_SIZEのサイズがそもそも小さい、
もしくは、不要となった動的オブジェクトを削除していない事により、
ヒープ領域を圧迫している、といった原因が挙げられると思います。
2. スタックサイズの調整
1つのマイコン(コア)で複数のタスクを制御するため、
OSカーネルはタスクのスイッチングの際にタスクの状態(変数、プログラムカウンタ)をメモリに退避させる仕組みが使われています。
この仕組みの実現のため、FreeRTOSはタスクの作成の際には、そのタスク専用のメモリ領域を確保します。
これがスタック領域と呼ばれ、xTaskCreateで設定する値のことです。
使用されるスタックのサイズは、タスク内で宣言されるAuto変数の数により変わってきます。
関数のネストが深いほど(各関数でAuto変数を使用していると)容量が増える可能性もありますし、
タスク内の処理がどう分岐するかによっても変数の使用量が変わる可能性があるため、
なかなか見積もることも難しい項目でもあります。
Stack Overflow Hook 関数
FreeRTOSには、タスク生成時に割り当てられたサイズを超えてスタックを使用した時に、hookしてくれる便利機能があります。
フック関数にタスクのハンドルとタスク名を渡してくれるので、どのタスクでオーバーフローが発生したのかを確認する事ができるはずです。
この機能を有効にした場合は、以下の関数をユーザーコードに実装してください。
void vApplicationStackOverflowHook(xTaskHandle xTask, signed char* pcTaskName) {
(void) xTask;
(void) pcTaskName;
#ifdef DEBUG
NRF_BREAKPOINT_COND;
#endif
configASSERT(0);
}
タスクの空いているスタック領域を確認する方法
uxTaskGetStackHighWaterMarkを使用する事で、
そのタスクが動作を開始してからAPIを呼んだ時点までの、スタック残量が最も少なくなった時のその残量を調べる事ができます。
スタックサイズの設定はAuto変数の数から大体のあたりを付け、
要所要所にuxTaskGetStackHighWaterMarkを仕込んで、フック関数も併用しながら適切なスタックサイズに調整していくのが良い気がします。
(必要なタスク数が少なくメモリも潤沢にあるのであれば、
難しい事は考えず、大きめにスタックサイズを設定してしまうのもアリかもしれません。)