
作成日:2024年7月15日
1.はじめに
文字起こしの歴史は古く、旧約聖書や新約聖書などが有名ですが、古代ギリシャの哲学者プラトンが彼の師であるソクラテスとの対話を集め、これをまとめた「Platonic Dialogues」(プラトンの対話篇)などが有名です。
「Platonic Dialogues」は、ソクラテスが実際に行った会話や議論を文字に起こしたもので、哲学的思考や教育方法に関する重要な資料です。
このように我々は後世に記録を残すことで知識や経験の積み上げを行ってきました。
昨今では自分に起きた記録を残す日記や会議などの議事録も同じように知識や経験の積み上げを行う重要な手段と言えます。
文字起こしはその時代で実現可能な方法で実施されてきており、速記からテープでの録音後のテープ起こし、ICレコーダでの録音後の文字起こし、音声会議ツールでの録音&文字起こし後の修正など、進化をつづけておりますが、2018年ころから提供が始まったAIの深層学習技術を用いた文字起こしで飛躍的な進化がありました。
AIによる文字起こしは様々なサービスが提供されていますが、今回は企業内でクローズド環境で利用できる文字起こしの一つの方法としてAzure Cognitive ServicesのSpeech to Textについてまとめたいと思います。
2.代表的な文字起こしサービス
AIによる文字起こしでよく知られているものには以下のようなサービスがあります。
| 項番 | サービス名 | 説明 | 備考 |
|---|---|---|---|
| 1 | Google Cloud Speech-to-Text | 高精度な音声認識を提供し、130以上の言語と方言を認識することができます。また、リアルタイムの音声変換も可能です。 | 多様な用途に利用可能 |
| 2 | IBM Watson Speech to Text | 音声をテキストに変換する際に、音声認識と自然言語理解を組み合わせることで高い精度を実現しています。また、複数の話者を識別する機能もあります。 | 高精度な音声認識と話者識別能力 |
| 3 | Microsoft Azure Speech to Text | 深層学習モデルを使用して高精度な音声認識を提供します。また、リアルタイムとバッチ処理の両方をサポートしており、カスタム音声モデルの作成も可能です。 | 高精度な音声認識とカスタム音声モデル作成可能 |
| 4 | Amazon Transcribe | AmazonのAIサービスで、音声をテキストに自動変換します。自動的に句読点や書式を付けることができ、また複数の話者の識別も可能です。 | 音声をテキストに自動変換、句読点や書式の自動付与 |
| 5 | Baidu Deep Speech | Baiduが開発した音声認識技術で、深層学習モデルを使用しています。現在は英語と中国語の音声をテキストに変換することができます。 | 英語と中国語の音声認識に特化 |
| 6 | OpenAI Whisper | OpenAIが開発した音声認識システムで、大量の音声データを学習して高精度な音声認識を提供します。 | 高精度な音声認識 ※詳細は「https://www.notion.so/00a327ddb0f645e6a88fc6c1aae72d81?pvs=21」を参照してください。 |
3.文字起こしサービスの位置づけ
Azureには文字起こしサービスとしてAzure Cognitive Services - Azure Speech Service - Text to SpeechとAzure OpenAI Service - Whisperがあります。
これらのサービスは、AIと深層学習を利用して高精度な音声認識を提供します。
また、リアルタイムとバッチ処理の両方に対応しているため、多様なシーンでの利用が可能です。
Text to SpeechはAzure独自のサービスで、WhisperはOpenAI社が開発したサービスのAzure版です。
Azureではサービスがネストしていたり、Whisperはモデルであったり、少し複雑なので、Text to SpeechとWhisperの位置づけを以下の表にまとめます。
| No | 大区分 | 小区分 | サービス&モデル | 説明 | 備考 |
|---|---|---|---|---|---|
| 1 | Azure Cognitive Services | Azure Speech Service | Speech to Text | 高精度で音声をテキストに変換します。 会議のリアルタイム字幕生成や音声コマンドの受け取りなどに利用できます。 |
|
| 2 | Text to Speech | テキストを自然な音声に変換します。ディープニューラルネットワークを活用したニューラルボイスを使用可能です。 カスタム音声フォント機能を使えば、ブランドに合わせた独自の音声を生成することも可能です。 |
|||
| 3 | Speech Translation | リアルタイムでの多言語音声翻訳を提供します。 いわゆる同時通訳機能です。 |
|||
| 4 | Speaker Recognition | 独自の声の特徴を使用して話者を検証し、識別します。 アプリに話者の認証と識別を追加することで、相手の身元を確認したり、会議で誰が発言しているかを識別したりすることができます。 |
|||
| 5 | Azure OpenAI Service | - | gpt-35-turbo | 一般的な文章生成や質問応答、文章の要約などに使用します。 | |
| 6 | gpt-35-turbo-16k | 長い文章の生成や要約などに使用します。 | |||
| 7 | gpt-4 | 一般的な文章生成や質問応答などに使用します。より高精度な結果を提供します。 | |||
| 8 | gpt-4-32k | 長い文章の生成や要約などに使用します。より高精度な結果を提供します。 | |||
| 9 | text-embedding-ada-002 | 文章のベクトル表現を生成します。文章間の関係性の分析などに使用します。 | |||
| 10 | whisper | 音声をテキストに変換します。高精度な音声認識を提供します。 |
※黄色でハッチングした部分がそれぞれのサービスとなります。
4.Speech to Textとは
MicrosoftのSpeech to Textは、音声をテキストに変換する高精度なAPIサービスです。このサービスは深層学習モデルを使用しており、リアルタイムの音声認識とバッチ処理の両方をサポートしています。
利用者は音声データをAPIに送信するだけで、それがテキストに変換されます。
また、このサービスはカスタム音声モデルの作成も可能で、これにより利用者は自分たちのニーズに合わせた音声認識モデルを作ることができます。
さらに、Speech to Textは音声の言語や話者を識別する機能も備えています。これにより、多言語環境や複数の話者が存在する場面でも利用することができます。
このような多様な機能と高精度な音声認識により、MicrosoftのSpeech to Textは幅広い用途に適応できます。
5.Speech to Textの価格
Speech to Textには価格レベル(価格オプション)としてFree(F0)とStandard(S0)が存在します。
| No | 区分 | モデル | 項目 | Standard(S0) | Free(F0) | 備考 |
|---|---|---|---|---|---|---|
| 1 | リアルタイム音声テキスト変換 | 標準 | 基本機能 | サポート | サポート | |
| 2 | 同時要求数 | 100(規定値) | ||||
| クォータにより変更することが可能 | 1 | |||||
| 3 | 利用時間制限 | 無し | 5時間/月 | |||
| 4 | 価格(標準) | 1USD/時間 | 無料 | 従量課金制です | ||
| 5 | Custom Speechモデル | 基本機能 | サポート | サポート | ||
| 6 | REST APIの制限 | 300回/分 | 300回/分 | FreeプランでもREST APIは利用可能です | ||
| 7 | 音声データセットの最大数 | 500 | 2 | |||
| 8 | データ インポートの最大音響データセット ファイル サイズ | 2 GB | 2 GB | |||
| 9 | データ インポートの最大言語データセット ファイル サイズ | 1.5 GB | 200 MB | |||
| 10 | データ インポートの最大発音データセット ファイル サイズ | 1 MB | 1 KB | |||
| 11 | https://westcentralus.dev.cognitive.microsoft.com/docs/services/speech-to-text-api-v3-1/operations/Models_Create/ API 要求で text パラメーターを使用する場合のテキストの最大サイズ | 500 KB | 200 KB | |||
| 12 | 価格(Custom Speechモデル) | 1.2USD/時間 | 無料 | 従量課金制です | ||
| 13 | バッチ文字起こし | ー | 基本機能 | サポート | 未サポート | |
| 14 | REST APIの制限 | 300回/分 | ↓ | |||
| 15 | オーディオ入力ファイルの最大サイズ | 1GB | ↓ | |||
| 16 | コンテナーごとの BLOB の最大数 | 10000 | ↓ | |||
| 17 | 文字起こし要求あたりの最大ファイル数 (入力として複数のコンテンツ URL を使用する場合) |
1000 | ↓ | |||
| 18 | ダイアライゼーションが有効になっている文字起こしの最大オーディオ長。 | 240分/ファイル | ↓ |
※「Speech サービスのクォータと制限」及び「Azuire AI Speechの価格」を参照
6.Speech to Textサービスの作成
Speech to TextサービスはAzureポータルの「音声サービス」([Azureポータル]⇒[Azure AI services]⇒[音声サービス])の一つの機能です。
利用するには「音声サービス」の作成が必要です。
以下にSpeech to Textサービスの作成方法を記載します。
①Azureポータルにサインイン
https://potal.azure.com/
②すべてのサービスを表示
Azureポータルトップ画面の「その他のサービス」をクリックしすべてのサービスを表示します。

③Azure AI serviceを選択
すべてのサービスから「Azure AI services」を選択します。
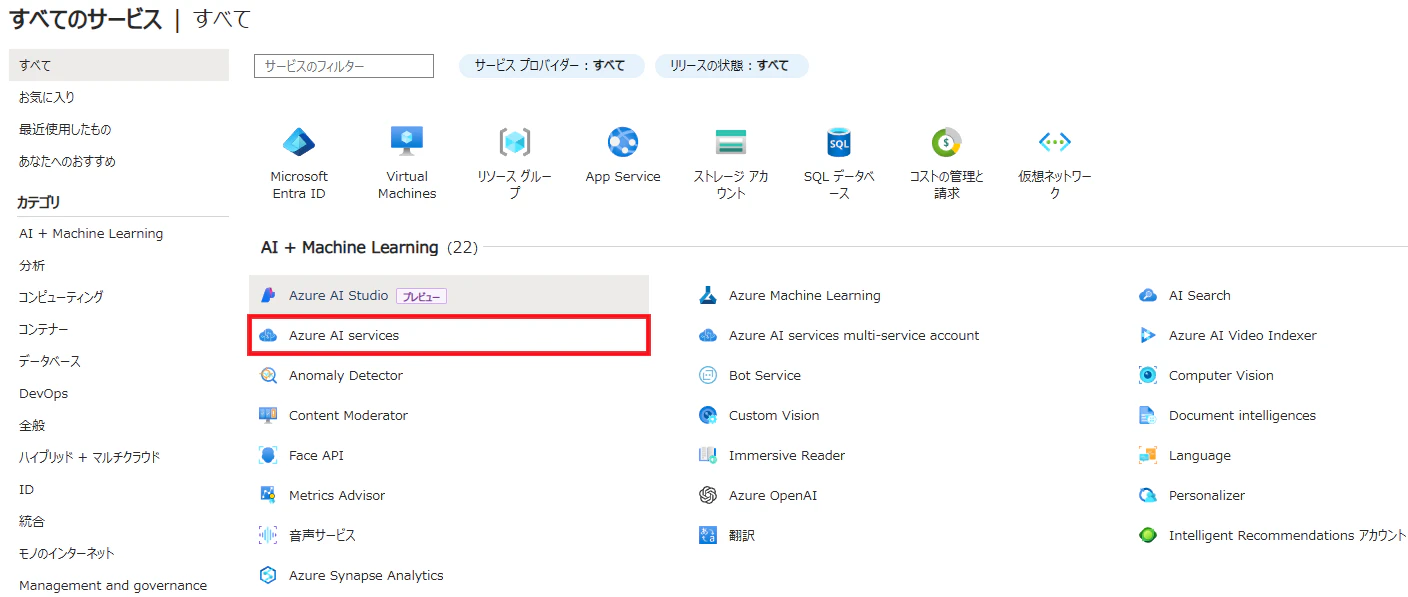
④音声サービスを選択
Azure AI servicesの中から「音声サービス」(Speech Service)を選択します。

⑤音声サービスを作成します。
左上にある「+作成」ボタンで作成します。

⑥Speech Serviceの作成
必要な情報を入力してSpeech Serviceを作成します。
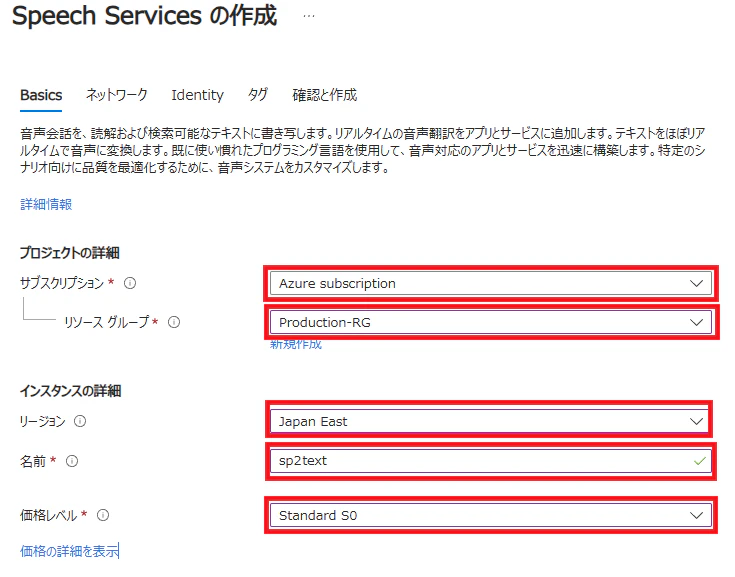
| No | 項目 | 説明 | 備考 |
|---|---|---|---|
| 1 | サブスクリプション | サービスを作成するAzureのサブスクリプションを選択します。 | ー |
| 2 | ┗リソースグループ | Azureではサービスをリソースグループ単位で管理しますので、適切なリソースグループ名を割り当てます。 | ー |
| 3 | リージョン | Japan Eastで音声サービスは提供されていますので、Japan Eastで良いと思います。 | ー |
| 4 | 名前 | サービスに適当な名前を付けます。この名前はエンドポイントとして使用されるわけでもないので、日本リージョンでユニークになる名前を、英数字で付与します。 | ー |
| 5 | 価格レベル | 音声サービスにはStandard(S0)プランとFree(F0)プランがあります。 Free(F0)プランは月内の利用時間や同時要求数に制限があるため、私はStandard(S0)プランを選択しましあ。 REST APIの検証目的ならばFree(F0)プランでも良いと思います。 |
ー |
サービスを作成するとこのような画面が表示されデプロイが完了しましたと表示されます。

7.Speech Studioからの確認
作成した「音声サービス」はSpeech Studioから試します。Speech StudioではAzure OepnAI ServiceのWhisperもAzureポータル上のGUIから試すことができます。
①作成した音声サービス
(今回はsp2text)のリソースにアクセスする
サービスの概要ページには「Speech Studioに移動する」というリンクがありますので、「Speech Studioに移動する」をクリックします。

②リアルタイム音声テキスト変換
Speech Studioで利用可能な機能
| No | 音声テキスト変換機能 | 説明 | 備考 |
|---|---|---|---|
| 1 | リアルタイム音声テキスト変換 | コードを書くことなく、自分のオーディオでライブトランススクリプト機能をすばやくテストできます。 | ー |
| 2 | Azure OpenAI ServiceのWhisperモデル | Azure OpenAIリソースを利用して、自分の音声でライブ文字起こし機能をすばやくテストし、プロンプトを使用して文字起こしの品質を向上させます。 | ー |
| 3 | Batch音声テキスト変換 | バッチ文字起こし機能をすばやくテストして、ストレージ内の大量のオーディオを文字起こしし、Azure SpeechモデルまたはOpenAI Whisperモデルを使用して非同期的に結果を受信します。 | ー |
| 4 | Custom Speech | カスタマイズされた音声テキスト変換モデルを使用して、独自のデータを追加し、特定の話し方やボキャブラリに適応させます。 | ー |
| 5 | 音声テキスト変換による発音評価 | スクリプトを音声で読み上げて、発音の正確さと流暢さに関するフィードバックをすばやく受け取ります。 | ー |
| 6 | 音声翻訳 | 短い待機時間で、選択した他の言語に音声を翻訳します。 | ー |
③文字起こし
リアルタイム音声テキスト変換を用いてファイルをアップロードして文字起こしを行うことができます。

8.文字起こしの比較
Text to Speechを「リアルタイム音声テキスト変換」で文字起こしをしたものとWhisperを使って文字起こししたものを比較したところ、以下のような結果となりました。
魔王魂。、サイトで、森田交一氏により公開されている「【魔王魂公式】シャイニングスター.mp4」を使用して検証しました。
| No | オリジナル歌詞 | Text to Speech | 判定 | Whisper | 判定 |
|---|---|---|---|---|---|
| 1 | 作詞作曲:森田交一 ただ風に揺られて 何も考えずに ただ雲を眺めて 過ごすのもいいよね |
まだ風に揺られて、 何も考えずに ただ雲も眺めて 過ごすのもいいよね。 |
× | 作詞・作曲・編曲 初音ミク ただ風に揺られて 何も考えずに ただ雲を眺めて 過ごすのもいいよね |
○ |
| 2 | 誰しも何かしら 使命を抱えてる ただそれだけのこと 悩むのはもうやめた |
誰しも何かしら 姫を抱えてる。 ただそれだけのことを 悩むのはもうやめた。 |
× | 誰しも何かしら 使命を抱えてる ただそれだけのこと 悩むのはもうやめた |
○ |
| 3 | さざなみの音に癒やされてく 軌跡を運ぶ風の音 時を閉じ込めて |
ら身の。音に癒されてく 軌跡を運ぶ風のね 茎を閉じ込めて。 |
× | さざ波の音に癒されてく 奇跡を運ぶ風の音 時を閉じ込めて |
○ |
| 4 | シャイニングスター綴れば 夢に眠る幻が掌に降り注ぐ 新たな世界へ I'll believe of my sensation 果てしない道の向こうで 瞼の裏に映る 一滴の光 トキメキを感じて |
夢に眠る無心のひらにふりさこ 改めて世界や。 果てしない道の向こうで。 ひとしくの光。 きめきを。 |
× | Shining star 綴れば 夢に眠る幻が 手のひらに降り注ぐ 新たな世界へ I'll sleep on my sensation 果てしない道の向こうで まぶたの裏に映る 一雫の光 ときめきを感じて |
× |
| 5 | 貴方が触れる全て 幸せであるように 今生きる喜びを 忘れてしまわないよう |
溢れるすべて 幸せであるように、 今生きる喜ぶを 忘れてしまわないよう |
× | あなたが触れるすべて 幸せであるように 今生きる喜びを 忘れてしまわないよう |
○ |
| 6 | 月の光 隠す雲は揺らぎ 自由の翼は今も 大空を翔る |
月の光。隠。ぎ 自由の翼は今も 大空をかける。 |
× | 月の光 隠す雲は揺らぎ 自由の翼は今も 大空を翔ける |
○ |
| 7 | シャイニングスター綴れば 無限のイマジネーション 魔法が使えるような 世界が広がる I'll believe of my sensation 今も降り募る想いよ 切なさやトキメキが 心の真ん中で 熱いメロディになる |
無限のイマジネーネション の王国がいるような 時代が広がる。 想いを 失ってやっときめきか 心の舞う中で 熱いメロディー。 |
× | Shining star 綴れば 無限のイマジネーション 魔法が使えるような 世界が広がる I'll sleep on my sensation 今も降り注ぐ想いよ 切なさやときめきが 心の真ん中で 熱いメロディーになる |
× |
| 8 | シャイニングスター綴れば 無限のイマジネーション 魔法が使えるような 世界が広がる I'll believe of my sensation 今も降り募る想いよ 切なさやトキメキが輝き出す |
輝きたくさいに二つ崩れた夢に眠るも、 殺しなくてのひらにくり、そこあらためて凱。 |
× | Shining star 綴れば 無限のイマジネーション 魔法が使えるような 世界が広がる I'll sleep on my sensation 今も降り注ぐ想いよ 切なさやときめきが 輝きだす |
× |
| 9 | シャイニングスター綴れば 夢に眠る幻が掌に降り注ぐ 新たな世界へ I'll believe of my sensation 果てしない道の向こうで 瞼の裏に映る 一滴の光 トキメキを感じて |
旋を混ぜてしょう 果たしない道の向こうで、 眠くての胸に映る 人しくの光 ときめきをくじて。 |
× | Shining star 綴れば 夢に眠る幻が掌に降り注ぐ 新たな世界へ I'll sleep on my sensation 果てしない道の向こうで 瞼の裏に映る 一雫の光 ときめきを感じて I'll sleep on my sensation |
× |
※今回の検証で使用では魔王魂。、サイトで、森田交一氏により公開されている「【魔王魂公式】シャイニングスター.mp4」CC BY 4.0 DEED「クリエイティブ・コモンズ 表示 4.0 国際ライセンス」のものです。
9.API利用
作成した「音声サービス」をPythonから利用する方法を試します。
①キーとエンドポイントの確認
[Azureポータル]⇒[Azure AI services]⇒[音声サービス]から作成したサービス(今回はsp2text)の「キーとエンドポイント」からAPIエンドポイントとアクセスキーを確認します。

②Python仮想環境の準備
D:\Python\sp2text等のフォルダを作成し仮想環境作成コマンドで仮想環境を作成します。
D:\Python\sp2text>python -m venv venv
③仮想環境をアクティベートします。
D:\Python\sp2text>venv\Scripts\activate.ba(venv)
D:\Python\sp2text>
④azure-cognitiveservices-speechパッケージをインストールします。
(venv) D:\Python\sp2text> pip install azure-cognitiveservices-speech
Collecting azure-cognitiveservices-speech
Downloading azure_cognitiveservices_speech-1.34.1-py3-none-win_amd64.whl.metadata (1.5 kB)
Downloading azure_cognitiveservices_speech-1.34.1-py3-none-win_amd64.whl (1.5 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.5/1.5 MB 16.2 MB/s eta 0:00:00
Installing collected packages: azure-cognitiveservices-speech
Successfully installed azure-cognitiveservices-speech-1.34.1
(venv) D:\Python\sp2text>
⑤クライアントソースコードを作成します。
以下のspeechsdkを使用したPythonコードでファイルの文字起こしはできたのですが、楽曲など音声と曲が混ざったものは文字起こしできませんでした。
また、私が試した環境では入力フォーマットもmp4やmp3は読めませんでした。
ファイルから文字起こしするサンプルプログラム(file-to-text.py)
#!pip install azure-cognitiveservices-speech
import azure.cognitiveservices.speech as speechsdk
# Connecting Informations
speech_subscription = 'xxxxxxxxxx'
speech_region= 'japaneast'
language = 'ja-JP'
# Set configuration to speecksdk
speech_config = speechsdk.SpeechConfig(subscription=speech_subscription, region=speech_region,speech_recognition_language=language)
# Set file
# from https://maou.audio/14_shining_star/
#voice_file = 'maou_14_shining_star.wav'
# from https://child-programmer.com/download/japanese-long-sentence/
voice_file = 'voice2.wav'
audio_input = speechsdk.AudioConfig(filename=voice_file)
# Set audio input to sdk
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_input)
print("Transcribing")
result = speech_recognizer.recognize_once_async().get()
text=result.text
print("result:",text)
print("Finished")
マイクから文字起こしするサンプルプログラム(mic-to-text.py)
#!pip install azure-cognitiveservices-speech
import azure.cognitiveservices.speech as speechsdk
import time
# Connecting Informations
speech_key = 'xxxxxxxxxx'
speech_region = 'japaneast'
language = 'ja-JP'
# Set configuration to speecksdk
speech_config = speechsdk.SpeechConfig(subscription=speech_key, region=speech_region,speech_recognition_language=language)
print("Say something")
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config)
def recognized(evt):
print('「{}」'.format(evt.result.text))
# do something
def start(evt):
print('SESSION STARTED: {}'.format(evt))
def stop(evt):
print('SESSION STOPPED {}'.format(evt))
speech_recognizer.recognized.connect(recognized)
speech_recognizer.session_started.connect(start)
speech_recognizer.session_stopped.connect(stop)
try:
speech_recognizer.start_continuous_recognition()
time.sleep(60)
except KeyboardInterrupt:
print("bye.")
speech_recognizer.recognized.disconnect_all()
speech_recognizer.session_started.disconnect_all()
speech_recognizer.session_stopped.disconnect_all()
print("Finished")
10.結果
Speech to Textは会社で使用しているTeamsほど悪くはありませんが、Whisperほど良くもありませんでした。
11.参考URL
- 音声サービスとは (Azure)
- Azure Speech Serviceとは?音声技術の重要性とAzureを用いたビジネスへの適用方法を解説 (Rworks)
- Speech サービスのクォータと制限 (Azure)
- Azure-Samples/cognitive-services-speech-sdk (GitHUB)
- Azure Speech SDKを用いて、音声からテキストへ変換すーる (Qiita)
- Azure Speech to Textを使って面倒な文字起こしの作業時間を90%以上削減した話 (Hatena Blog)