はじめに
こちらの記事は、Dataiku AcademyのAdvanced Prepare Recipe Usageをやってみました。(中編) の続きになります。中編をご覧になっていない方は、是非そちらもご覧ください。一層、Prepareレシピに関する理解が深まると思います。
本記事で扱う内容
Dataiku Academy - Advanced Prepare Recipe Usageに関する内容です。
今回は、下記の2つをご紹介します。
・Become a Master of Dataiku DSS Formulas - DataikuのFormulaに関するお話し
・Custom Python functions in the Prepare Recipe - Python Functionに関するお話し
Become a Master of Dataiku DSS Formulas
Introduction
Dataikuには、Formulaと呼ばれる、数式を書くための言語が含まれています。
これらは、Prepare レシピで新しい列を作成する場合や、行のフィルタリング、行にフラグ付けするような場面などで有効です。
上記で上げた場面以外にも、FormulaはPrepareレシピ以外の、Dataikuの多くの場所で、行の値をフィルタリングするために使用することができます。
・機械学習で、訓練セットとテストセットに使用するエッセンスを定義する場合
・PythonとJavascriptのAPIで、データセットから部分的なエッセンスを取得する場合
・Public APIで、データセットから部分的なエッセンスを取得する場合
・Group、Window、Join、Stackレシピで、事前(事後)にフィルタリングを実行する場合
・Filteringレシピで、行をフィルタリングする場合
Basic Usage
ここでは、Formulaの基本的な使い方を紹介していきます。
Formulaは、行ごとに適用される式を定義します。
下記のような、N1 (数値)、N2 (数値)、S (文字列) の列を持つデータセットを例として、いくつかの数式の例を紹介します。
2 + 2(数値計算)
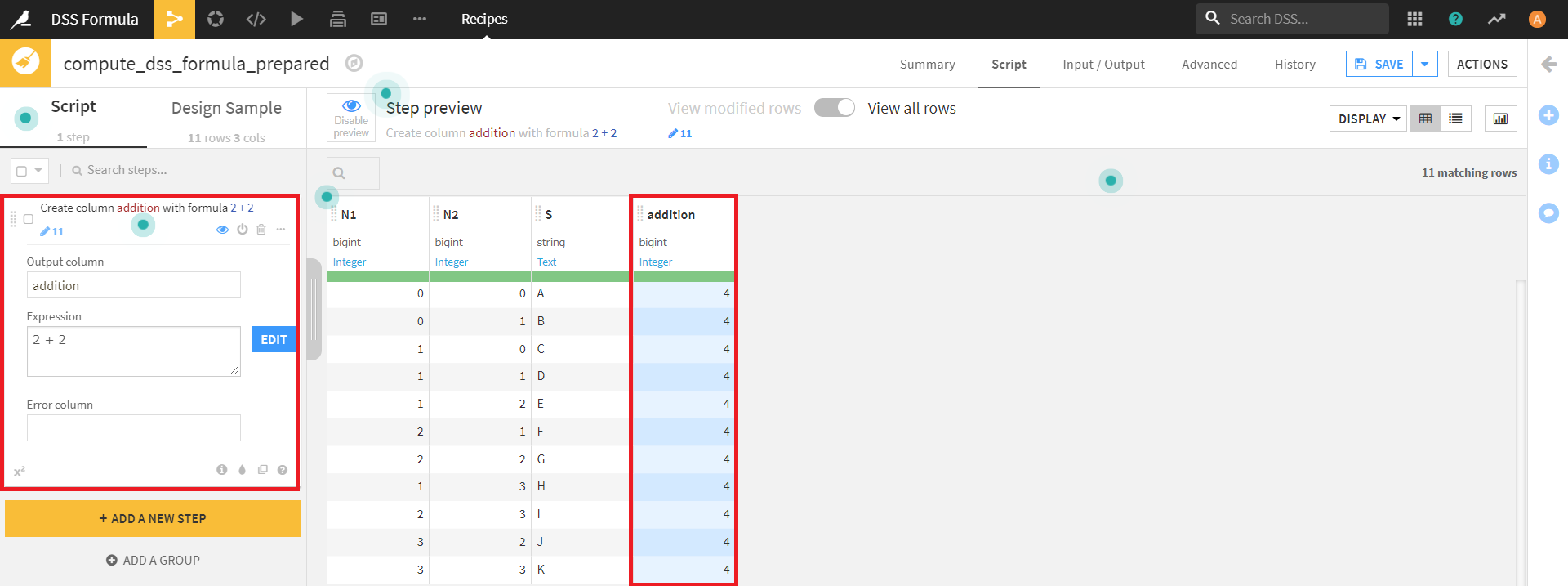
まずは、Prepareレシピの[+ ADD A NEW STEP]をクリックし、Formulaステップを追加します。


Output columnに適当な名前を付け(今回は足し算を意味するadditionとしています)、Expressionで数式(今回はタイトルの通り2+2)を記入します。
すると、上記手順で作成したカラムが追加されます。
Formulaでは、上記のような固定の数値の計算以外にも、データセットのカラムを活用した計算が可能です。
下記で、それを紹介していきます。
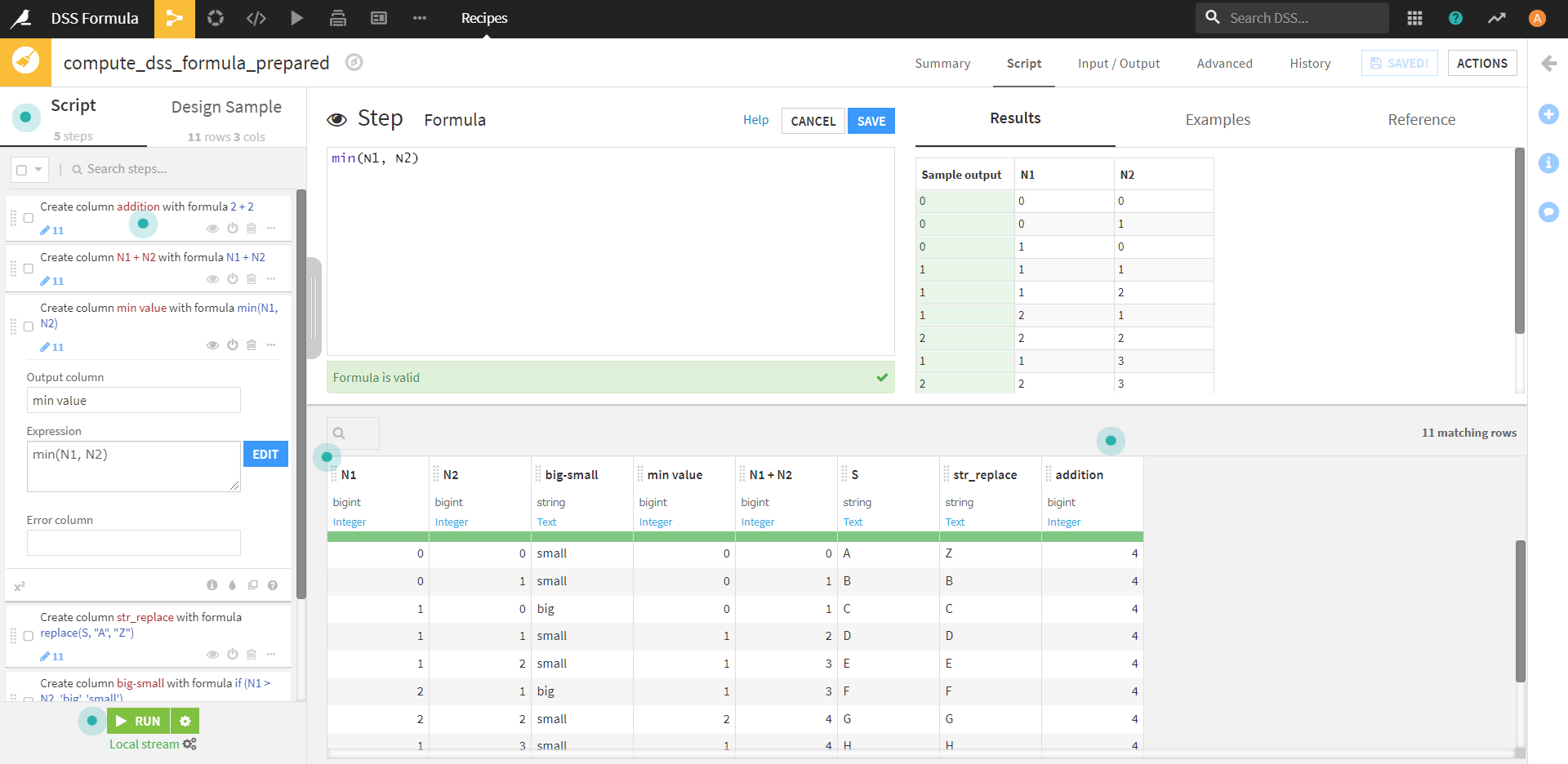
N1 + N2
この式では、N1、N2カラムの数値の合計を持つ列を作成することができます。

min(N1, N2)
この式では、N1、N2カラムの数値を比較して、最小の数値を返すことができます。

replace(S, 'A', 'Z')
この式では、Sカラムの値'A' を 'Z' に置き換えたものを返すことができます。

if (N1 > N2, 'big', 'small')
この式では、N1、N2カラムの同じ行の値を比較して、N1 > N2の場合にはbig、そうでない場合にはsmallを返すことができます。

ここまで、Formulaで記述可能な簡単な式を幾つかピックアップして見てきました。
余談ですが、Formulaで式を書く際に、その隣の[EDIT]をクリックすると、さらに便利な使い方ができます。

この操作によって、画面上部の大きな画面での編集が可能になります。
今回紹介したような簡単な式ではなく、より複雑な式を書きたい場合には、こちらの方がストレスなく操作できると思います。
Resultsでどのような結果になるか見られるのもうれしいですね。
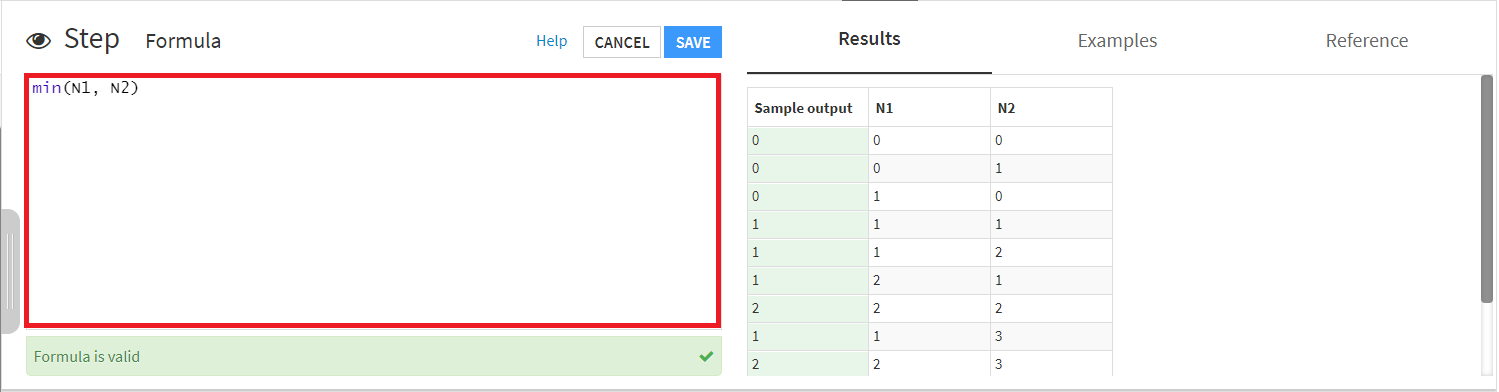
Results以外の、右側の項目のタブを切り替えると、Examlesでは簡単な例の紹介が、Referenceでは、左上のSearch...から検索することで、より複雑な計算式の概要や返り値を調べることができます。


Fun with arrays and objects
Dataikuでは、配列 ([0,1,2]) やオブジェクト ({"firstname": "John", "lastname": "Smith"}) を含むカラムを操作することができます。配列とオブジェクトは JSON 記法を使用して表現されています。Formulaには、配列やオブジェクトを操作するための多くのツールが含まれています。
Access elements
DataikuのFormulaは、以下のような、PythonやJavascriptの構文を使った配列要素とオブジェクトキーへのアクセスをサポートしています。
・array[0]
・object["key"]
・object.key ('key' が有効な識別子である場合にのみ有効)
配列とオブジェクトの列は、DSSではデフォルトでは解析されませんが、配列を使用する関数でのみ自動的に解析されます。しかし、インデックスやキーアクセスは関数ではないので、カラムをオブジェクトに変換するには、下記の例のように parseJson を使う必要があります。
・parseJson(request_details)["page_data"] :page_dataの配列を抽出します。
・parseJson(request_details)["page_data"][1]: page_data配列の2番目の要素を抽出します。
・parseJson(request_details)["page_data"][1]["url"]: page_data配列の2番目の要素のURLを抽出します。
Use ‘with’ to simplify an expression
withを使うと、式を単純化するために変数を式に結合することができます。例えば、最初の2つのランク変数を合計したい場合、以下のようになります。
parseJson(request_details)["page_data"][0]["rank"] + parseJson(request_details)["page_data"][1]["rank"] となりますが、withを使うと下記のように書けます。
# Alias parseJson(request_details)["page_data"] as "pages"
with(parseJson(request_details)["page_data"], pages,
pages[0]["rank"] + pages[1]["rank"]
Apply a function
式言語には、各要素に関数を適用した後に新しい配列を返すための forEeach 関数と forEachIndex 関数があります。構文は下記のとおりです。
forEeach(array a, variable v, expression e) (returns: array)
上記構文では、式aを配列に評価し、各配列要素について、その値を変数名vにバインドした後、式eを評価し、その結果を結果配列にプッシュしています。
使用例として、下記のような配列があり、その合計を求めたい場合があります。
配列 A ["1", "5", "12"]
sum() 関数は数値しか受け付けないため、このような場合に、forEach関数を使うことができます。
Other Useful Formulas
Use formula to ‘fill blanks from another column’
Formulaを使用して、カラムの空白(欠損値)を埋めた新たなカラムの生成をすることができます。
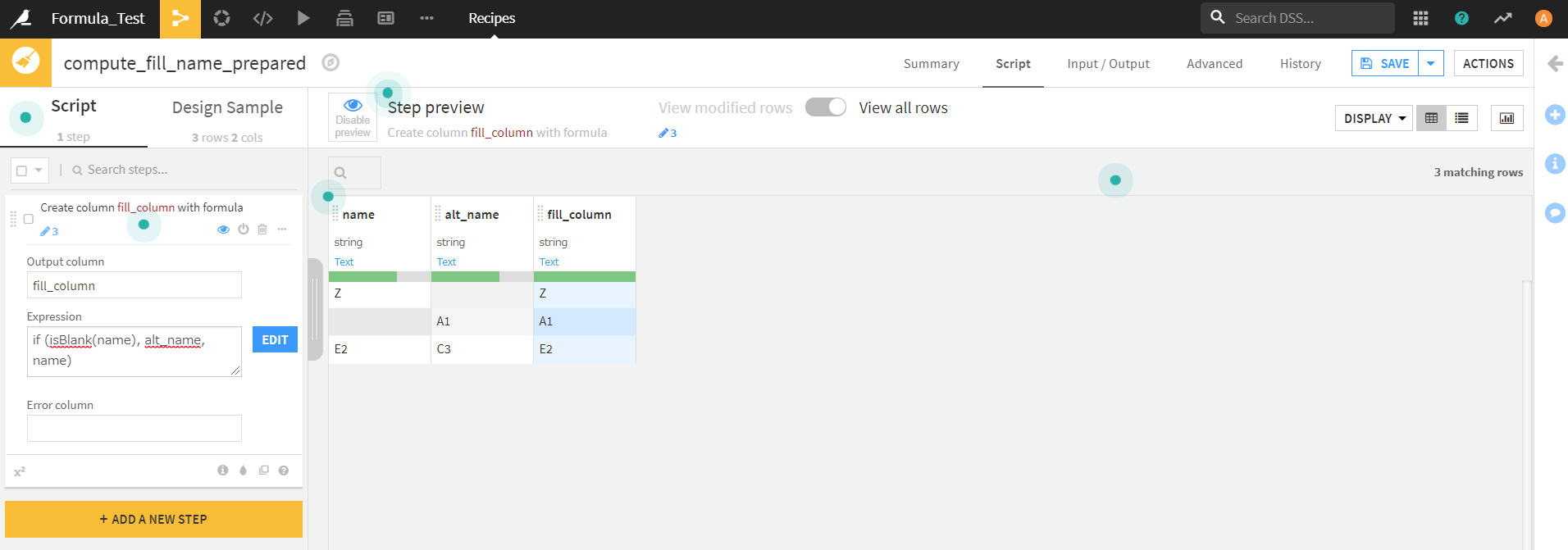
今回は、下記のデータセットのnameカラムの欠損値の部分を、alt_nameカラムの値で埋めてみようと思います。
[+ ADD A NEW STEP]より、[Formula]ステップを追加します。

今回は、下記のような操作内容を記述しました。
if (isBlank(name), alt_name, name)
新たに作成したfill_columnのカラムは、nameカラムをベースに作成されており、欠損値となっている部分には、同じ行のalt_nameカラムの値が入りました。
ここまでFormulaで可能なことや、その実現方法について紹介してきました。ドキュメント(Formula Language)には、Formulaについて、より多くの内容が記載されていますので、興味のある方はそちらを覗いてみると、新たな発見があるかもしれません。
Custom Python functions in the Prepare Recipe
ここまででお分かりの通り、Dataikuのビジュアルレシピのなかで、データの前処理に一番持って来いなのがprepareレシピです。先ほど紹介したFormulaは、単純なprepareレシピでは物足りず、よりカスタマイズ性が欲しい場合に、自ら操作を作成するものでした。
これから紹介するPython functionは、さらに複雑な行単位のタスクを行う場合に(もちろん、Python言語が得意な方も)おすすめです。Python functionでは、3つのモードを適宜選択することで、関数の出力を決定することができます。
Cell mode
Cell modeでは、1つの列を出力します。列全体で最大の値を求めたり、名前が何らかのパターンに従う列の集合の合計を求めたりする場合などが主な使用する場面になりそうです。
以下の例では、データセット内の列の中で最も長い文字列の値を見つけています。チュートリアル「Cleaning Contacts」のデータを使って、試してみましょう。
データセットdss_dirty_data_exampleに対して適用した、prepareレシピをクリックして操作していきます。

画面左の[+ ADD A NEW STEP]より、ステップを追加します。

ここでは「Python function」を選択します。

上記で追加したステップの詳細の設定を行います。
Modeはタブの中から、「cell:produce a new cell for each row」を選択します。
Output columnに追加するカラムの名前を入力します。今回は、長い文字列だけを保持するカラムを作成したいので、longest_stringとしました。
ここまで準備ができたら、[EDIT PYTHON SOURCE CODE]をクリックし、pythonのコード入力に移ります。

すると、画面上部にStepというボックスが現れるので、ここにコードを入力していきます。
Stepの右端にあるSAVEをクリックすると、書いたコードによる操作が反映されます。心配な場合は、SAVEの左隣のPREVIEWで臨むような結果になっているか確認しておくと良いですね。
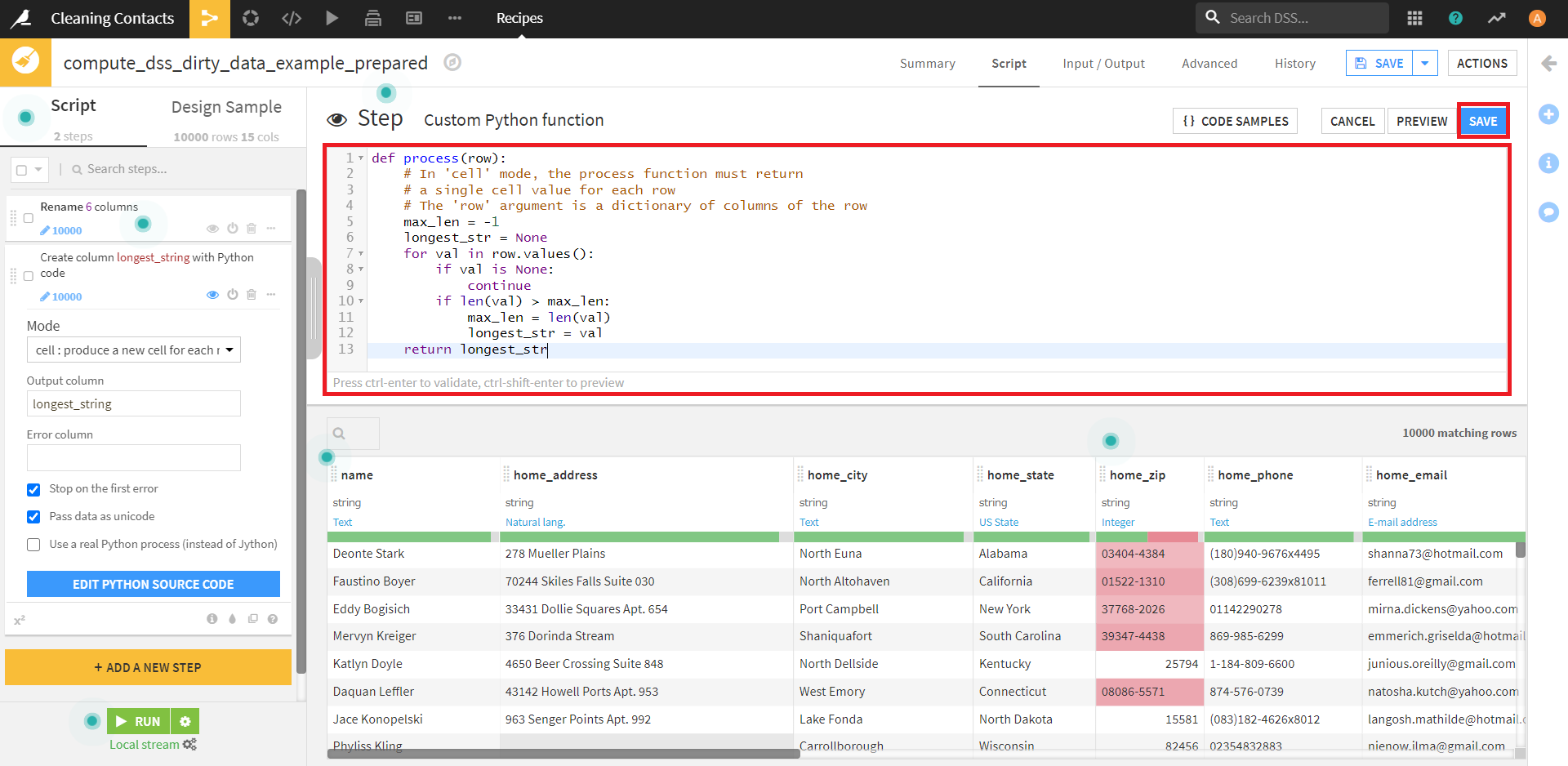
今回、長い文字列だけを保持するのに書いたコードは下記のとおりです。
def process(row):
max_len = -1
longhest_str = None
for val in row.values():
if val is None:
continue
if len(val) > max_len:
max_len = len(val)
longest_str = val
return longest_str
作成されたカラムを見てみると、longest_columnというカラム名で、同じ行のうち最も長い文字列を保持するカラムが作成できました。

Row mode
Row modeでは、既存の行を置き換えることができます。行に対してその場で演算を行う必要がある場合や、データセットに複数の行を追加する必要がある場合(列をまたいで行内の値の平均値や標準偏差を計算する場合など)などが使用場面になりそうです。
では、先ほどと同様に実際に試してみましょう。今回も、チュートリアル「Cleaning Contacts」のデータを使い、整数値の列に 5 を加算してみます。
画面左側の、[+ ADD A NEW STEP]より、[Python function]のステップを追加します。


Modeの選択で、[row:return a row for each row]を選択します。

それ以外の設定はデフォルトのまま、[EDIT PYTHON SOURCE CODE]をクリックします。
例によって、画面上部にStep(Pythonコードを書くスペース)が現れます。

今回、整数値のデータの列にだけ +5するため、以下のようなコードを書きました。
import ast
def process(row):
for i in row.keys():
try:
isint = type(ast.literal_eval(row[i])) is int
except:
isint = False
if isint:
row[i] = int(row[i]) + 5
return row
結果を比較してみると、しっかりとint型の列の数値に+5できていることがわかります。
● Pythonコード実行前

● Pythonコード実行後

Rows mode
Rows modeでは、既存の行を置き換える1つ以上の行を出力します。データをワイドフォーマットからロングフォーマットに変換する必要がある場合などが使用する場面になりそうです。
今回も、チュートリアル「Cleaning Contacts」のデータを使用し、同じ行に含まれる自宅・勤務先の情報を2行に分けたいと思います。例によって、まずは[+ADD A NEW ATEP]より、[Python function]を追加します。

Modeの選択で、[rows:produce a list of rows for each row]を選択し、[EDIT PYTHON SOURCE CODE]をクリックします。
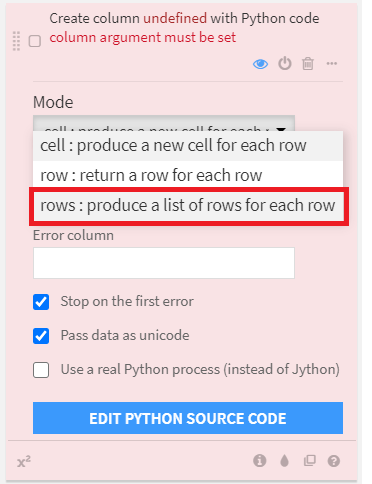
ちなみに、Modeの選択でrowsを選択すると、データセットの行が飛び飛びになります。これは、このあと、既存の1行を2行に分割するためだと思われます。
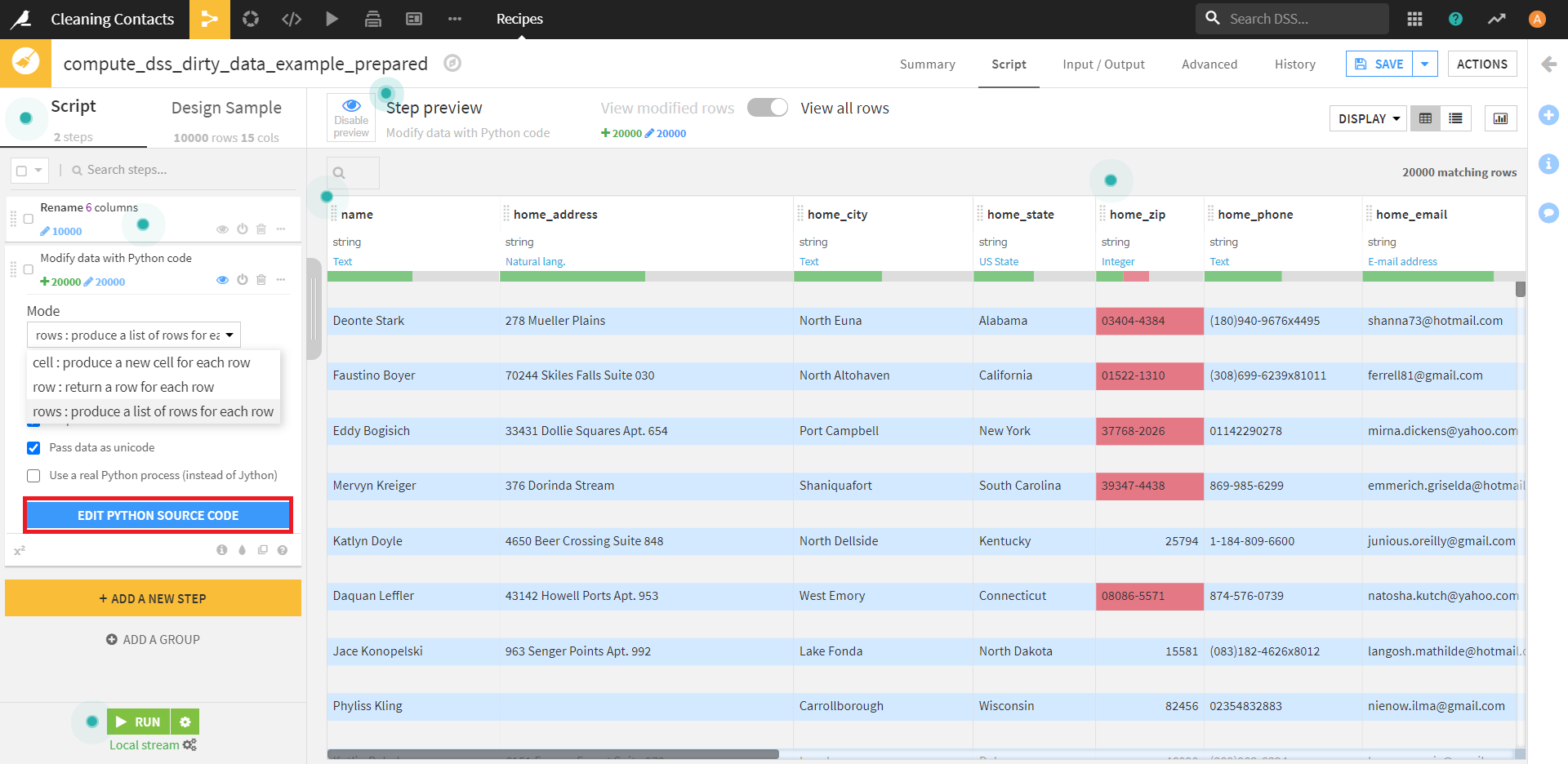
今回は下記のコードを書きました。
def process(row):
# In 'multi rows' mode, the process function
# must return an iterable list of rows.
ret = []
home = {"name": row["name"],
"type": "home",
"zip": row["home_zip"],
"state": row["home_state"]}
work = {"name": row["name"],
"type": "work",
"zip": row["work zipcode"],
"state": row["work state"]}
ret.append(home)
ret.append(work)
return ret
上記をStepで記述し、SAVEをクリックします。

すると、nameの各行が2つに分割されました。また、コードで書いたname、type、zip、stateのカラムが残り、他はまっさらな状態になっています。コードを書く前は、1 つの行に個人の勤務先と自宅の郵便番号と州の両方が含まれていたのが、各行に自宅と勤務先のどちらかの情報(type)と、自宅と勤務先のどちらの情報であるかを示すカラム(zip)が含まれています。
(下の2枚の図は繋がっているのですが、画面の都合上、分けて掲載しています。)
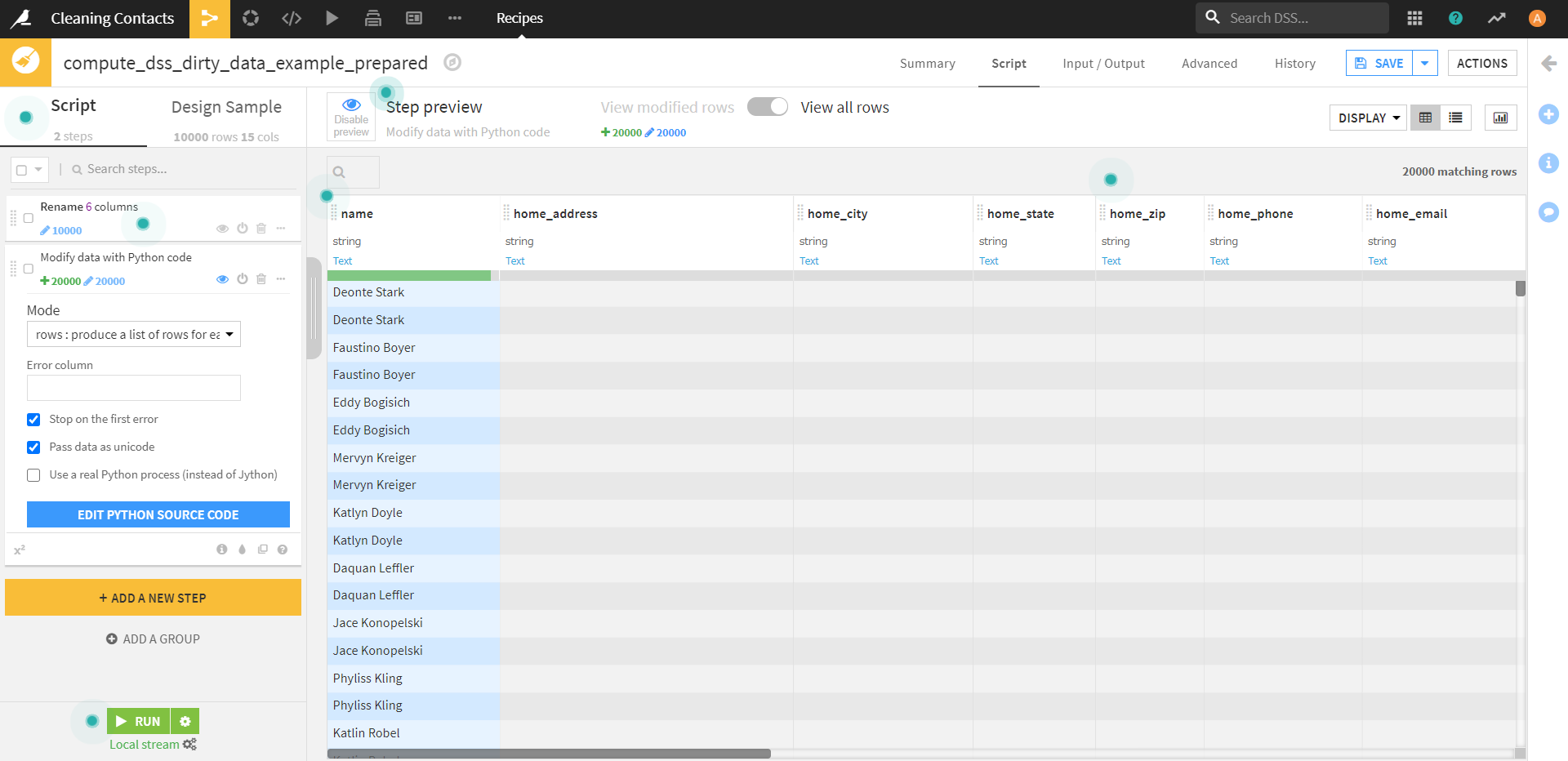

●コード実行前のデータセット
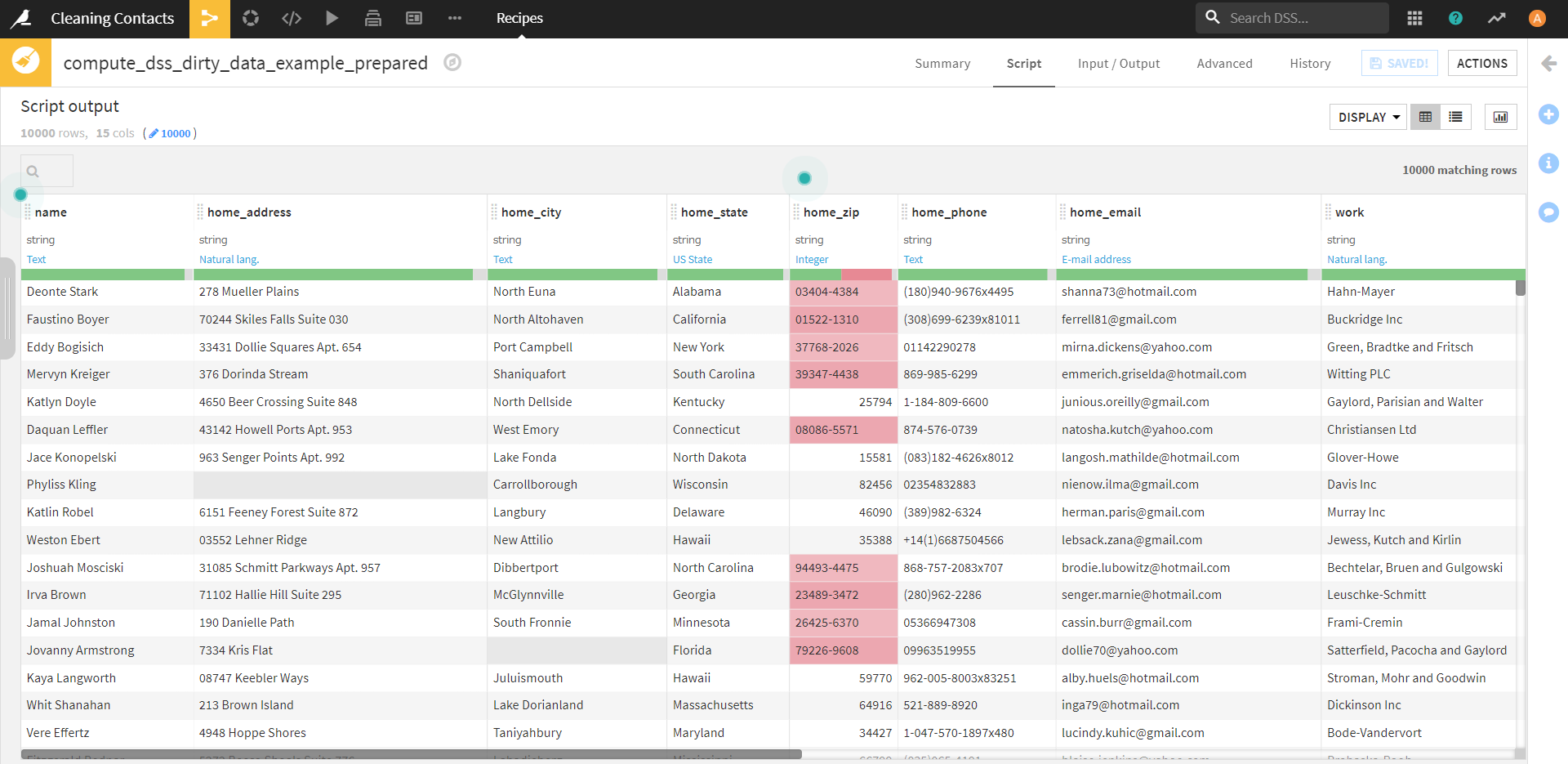
おわりに
ここまで全3編に分けて、Dataiku AcademyのAdvanced Prepare Recipe Usageの内容を紹介していきました。データ分析の作業の大半を占めるのがデータの前処理だとよく言われますが、それを楽にしてくれるのがPrepareレシピです。Prepareレシピを使いこなすことで、データの前処理が簡略化され、浮いた時間をより良いモデルの検討に充てることができると思います。私自身、Prepareレシピを完全に使いこなせているとは言えないので、これを機にさらに良い使い方を習得していきたいと思います。