参考にした本はこちらになります。
1.機械学習ワークフローの自動化がなぜ必要なのか?
既存のモデルの保守ではなく、新規モデルの開発に集中させる。
現行モデルを最新状態に保つことはとても時間と労力がかかるものです。
理由はいくつかあり、
①学習データを前処理するのにスクリプトを手動で実行している。
②一度しか使わないデプロイ用スクリプトを書く。
③モデルを手動でチューニングを行う。
手動で行うことは当然ヒューマンエラーが生じるものです。
わざわざエラーを修正して実行して・・・・
とても手間がかかるものです。
機械学習エンジニアやデータサイエンティストの目的とは、
新規モデルの開発に集中することです。
自動化というのは、この新規モデル開発に集中させる手助けになるのです。
便利な変更履歴
モデルのリリース管理により、モデルの変更履歴が生成されます。
実験中は、モデルのハイパーパラメーター、使用したデータセット、モデルの指標に関する変更を記録します。
これらは、データサイエンスチームがモデルを再現したり、モデルの性能を追跡する場合に特に役立ちます。
一般的な機械学習ワークフロー
機械学習を学習されている方にはよく見られるフェーズかと思いますが、MLパイプラインの基礎はこんな感じになっていますね。

参照:https://ai-trend.jp/business-article/ai-project/mlops1205/
このパイプライン構築ライブラリとなるのが、
Tensorflow Extendedとなります。以降TDXと呼びます。
TFXを使用して、パイプラインタスクを定義し、AirflowやKubeflow Pipelinesなどのパイプラインオーケストレーターで実行します。
私自身、MLops基盤の学習にあたりKubeflowという言葉を聞き、
何これ?
と思ってました。
Kubeflow
Kubernetes上で機械学習 (Machine Learning, ML) ワークフローを構築し、デプロイするためのオープンソースのプラットフォームです。
Kubernetesは、コンテナ化されたアプリケーションを効率的にデプロイ、スケール、管理するための人気のあるオーケストレーションツールであり、KubeflowはKubernetesを基盤として、機械学習ワークフローをシームレスに実行するためのツールやリソースを提供します。
そのため、Tensorflow ExtendedはKubeflowを実行させる上では、とても大切なライブラリってわけ。
KubeflowもTensorflowもどちらもGoogle様が開発したものになるから、GCPとの互換性もある。
また、Tensorflow Extendedはさまざまなツールとの依存関係が多いから、バージョン管理がとても面倒だった。
(裏でApache Beamも動いていたり。。でもそのおかげで GCPのDataflowも簡単に動く!)
次から、TFXについて説明していきます。
2.Tensorflow Extended入門
公式から持ってきたものになるのだが、これが先ほどのMLパイプラインをTFX版に書いたようなものです。

これは以下のフェーズに分解されます。
データの収集⇨ExampleGen
データの検証⇨StatisticsGen,Example Validator,SchemaGen
データの前処理⇨Transform
モデル学習⇨Trainer
モデルの分析と検証⇨Model Validator,Evaluator,Pusher
細かい説明は後ほど説明します。
3.Apache Beamについて
TFXコンポーネントのようなライブラリが、パイプラインデータを効率的に処理するために、
Apache BEAMへ依存しています。
Apache Beamは、分散データ処理の一般的な課題を解決するための高レベルのAPIを提供し、データ処理パイプラインの実行を最適化するランタイム環境を提供します。また、Apache Beamは、複雑なデータ処理のエラー処理、ウィンドウ処理、タイムスタンプ処理、状態管理などの機能をサポートしています。
GCPのDataflowもこのApache BEAMが元に動いております。
実際に、Tensorflow Transformなどの内部でこのapache BEAMが動いています。
まずは簡単に、apache beamについて動かしてみましょう。
環境は Google Colabで行っております。
apache_beamをインストールしていない場合は、pipでインストールしてください。
import apache_beam as beam
beam.__version__
# 2.46.0
ちなみに、apache BEAMの挙動は下のような感じになっております。
わかりやすいリンク貼っていたので、よかったらみてください。
細かい記述は公式ドキュメントを見るようにしてください。
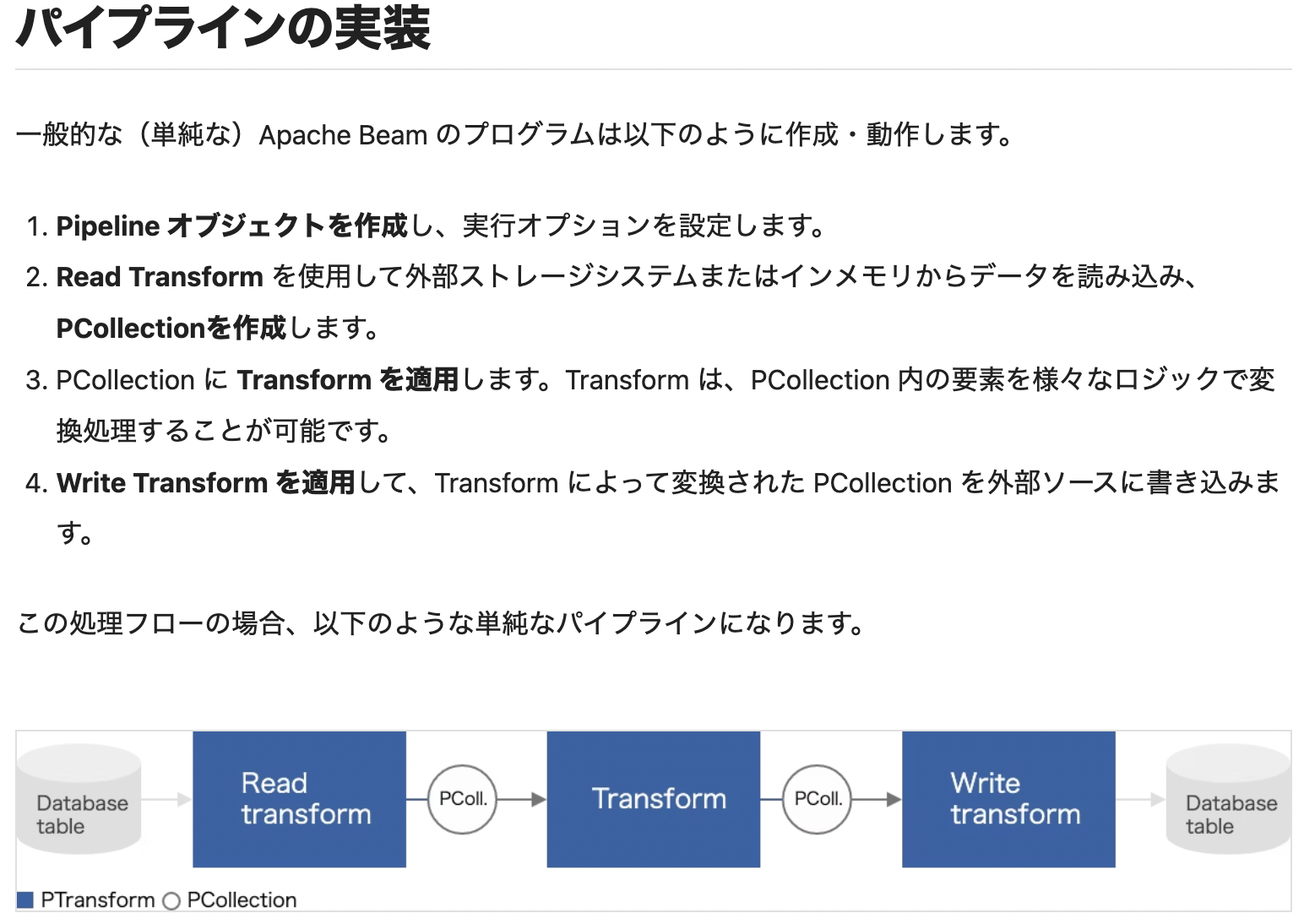
今回、データ処理では物語に出てくる単語の数を数える処理を行っていきます。
これはChat-GPTが作成してくれたちびまる子ちゃんの最終回らしいです。笑
こんな感じで、テスト用のデータをくれるのはありがたいなぁ笑
適宜コピーするか、Chat-GPTでジョジョの最終回とか作成してみてください笑
Title: The Final Episode of "Chibi Maruko-chan"
[Scene opens with Chibi Maruko-chan sitting at her desk in her room, writing in her diary.]
Chibi Maruko-chan: (thinking) Today is the last day of elementary school. It's been such an amazing journey with all my friends and teachers. I'll miss them all so much.
[Chibi Maruko-chan puts down her pen and looks out the window. She sees her friends walking towards school, and a sense of nostalgia washes over her.]
Chibi Maruko-chan: (sighs) I can't believe it's finally here. The last day of school.
[Chibi Maruko-chan gets dressed in her school uniform and heads to school. As she walks through the hallways, she sees her classmates exchanging hugs and promises to keep in touch.]
Classmate 1: (tearfully) I'm going to miss you all so much!
Classmate 2: (sniffling) Yeah, me too. We've been through so much together.
Chibi Maruko-chan: (smiling) Yeah, we have. But this isn't goodbye. We'll always be friends.
[Chibi Maruko-chan and her friends exchange heartfelt goodbyes as they graduate from elementary school. The scene shifts to a few years later, with Chibi Maruko-chan now in high school.]
Chibi Maruko-chan: (voiceover) High school has been a whole new adventure. I've made new friends and learned so much.
[Chibi Maruko-chan is shown studying diligently, participating in school activities, and spending time with her family.]
Chibi Maruko-chan: (thinking) Time flies so fast. I can't believe I'm almost done with high school too.
[The scene transitions to Chibi Maruko-chan's graduation day from high school. She stands on the stage, wearing her cap and gown, and delivers a heartfelt speech.]
Chibi Maruko-chan: (with tears in her eyes) Thank you, everyone, for the wonderful memories. I'll cherish them forever. As we move on to the next chapter of our lives, let's continue to chase our dreams and make a difference in the world. Thank you!
[The audience applauds as Chibi Maruko-chan receives her diploma. She looks out into the crowd and spots her family, friends, and teachers, all smiling and cheering for her.]
Chibi Maruko-chan: (smiling) I couldn't have done it without all of you. Thank you for always supporting me.
[The screen fades to black, and the words "The End" appear, signaling the conclusion of "Chibi Maruko-chan."]
[Epilogue: A montage of Chibi Maruko-chan's post-graduation life is shown, including her pursuing her passions, achieving her goals, and staying connected with her loved ones. The final scene shows an adult Chibi Maruko-chan, happily reminiscing about her childhood and flipping through her old diaries.]
Chibi Maruko-chan: (smiling) Those were some of the best days of my life. I'll treasure them always.
[The screen fades to black, and the credits roll, accompanied by a heartwarming soundtrack.]
[The end.]
では実際に書いていきます。
input_file = "/content/drive/MyDrive/pipeline-tfx/chibimaruko.txt"
output_file = "/content/drive/MyDrive/pipeline-tfx/word_count_chibimaruko.txt"
def format_result(word_count):
'''.txtファイルに書き出せるように、タプルから文字列に変換'''
(word , count) = word_count
return "{}:{}".format(word,count)
import re
with beam.Pipeline() as p:
lines = p | beam.io.ReadFromText(input_file) # テキストファイルの読み込み
counts = (
lines
| 'split' >> beam.FlatMap(lambda x : re.findall(r'[A-Za-z\']+' , x)) # reモジュールを使って単語を分割している
| 'count' >> beam.Map(lambda x : (x,1)) # 各単語ごとに1という要素を加えたタプルを返す
| 'Groupsum' >> beam.CombinePerKey(sum) # 単語ごとにグループ化し、数を足している
)
output = counts | 'format' >> beam.Map(format_result)
output | beam.io.WriteToText(output_file)
基本的に、lambdaを使って処理を書いていくことになります。
上の図のように、処理したらPcollectionに入れることになってますよね。
FlatMapメソッドはまさにそれで、Pcollectionにマップしています。
Mapメソッドは中で関数を実行させるためのメソッドになってます。
CombinePerKeyは要素を計算することができます。
また、変換はパイプ演算子を用いることで連鎖させることが可能です。
同じタイプの複数の変換を連鎖する場合は、パイプと>>の間に操作名を指定してあげる必要があります。
結果はこのようになります。
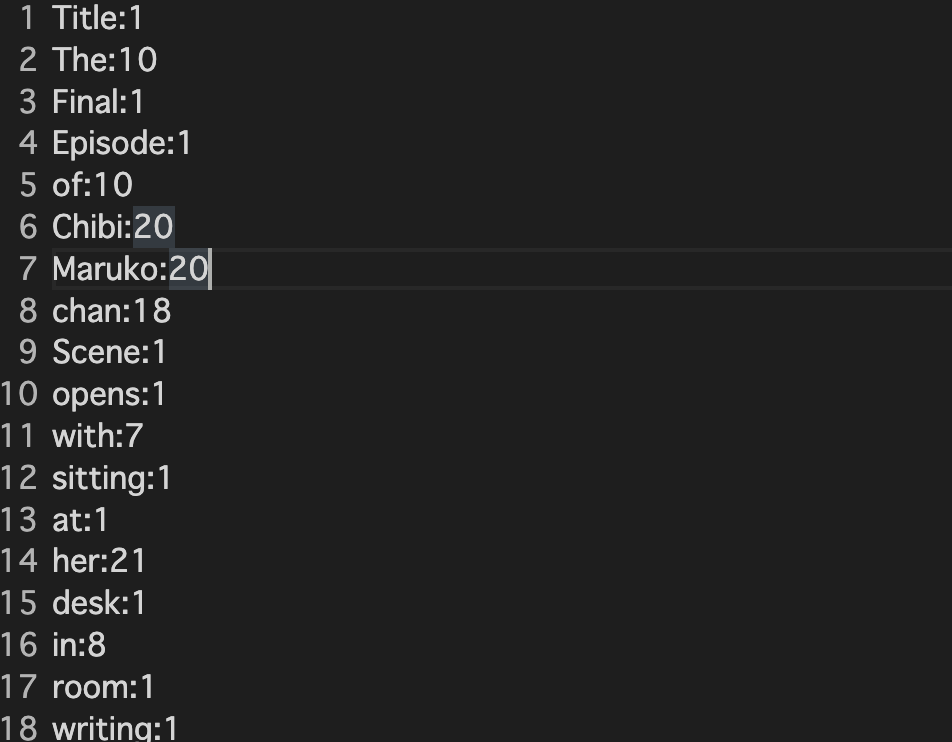
うまくテキストファイルに単語の個数が入っていることがわかりますね。
以上が Apache BEAMの超基本的なコードの記述でした。
4.TFXの内部の構造を理解する

コンポーネントの内部の3つの処理は、
ドライバ
エグゼキューター
パブリッシャと呼ばれています。
ドライバは、メタデータストアに対してクエリを発行している。
エグゼキューターはコンポーネントの処理を実行しています。
パブリッシャはメタデータをMatadatastoreへ保存する処理を管理しています。
処理の全体像としては下の図となっています。
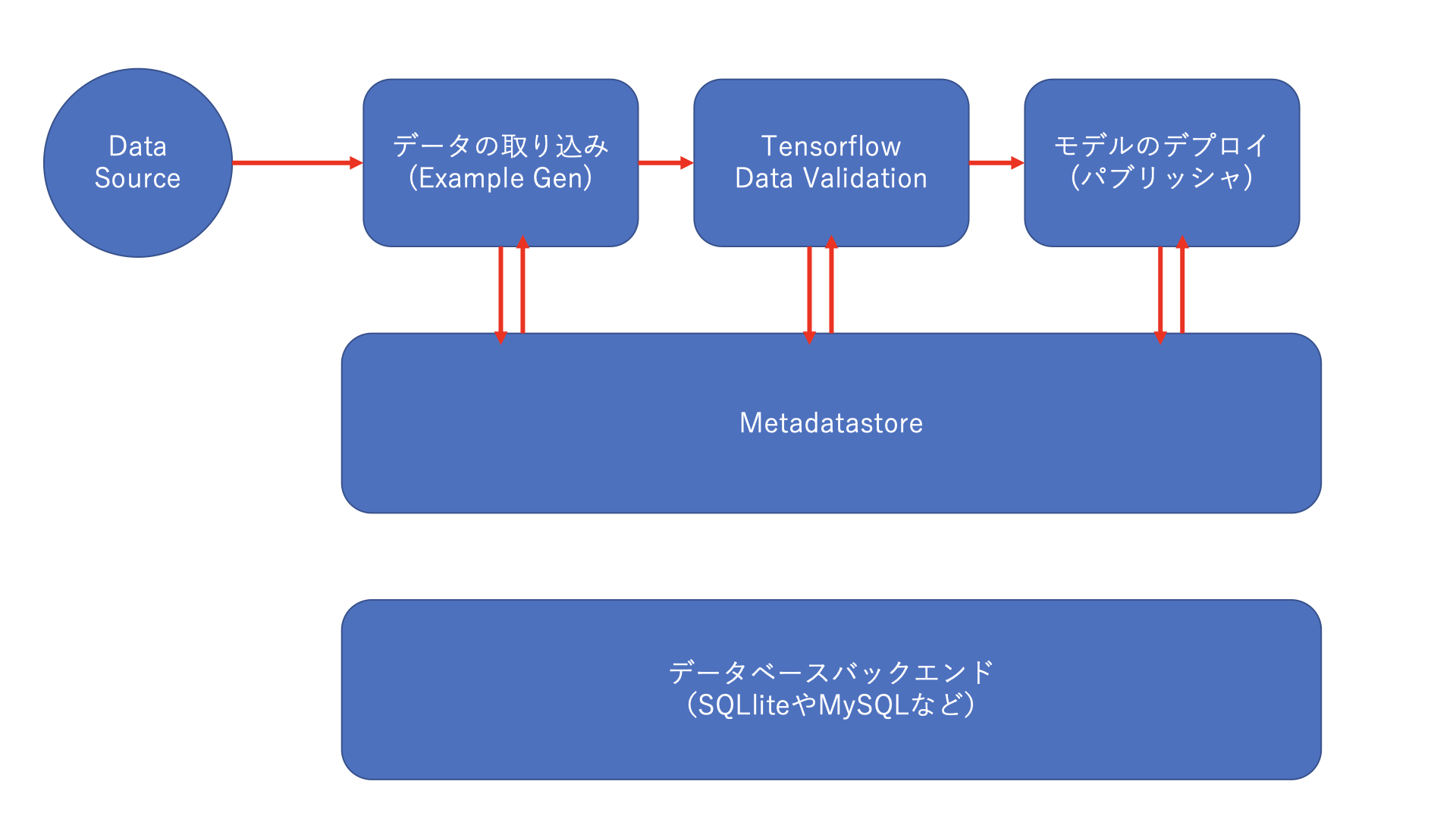
上の3つにあるのがそれぞれのコンポーネントとなっています。
各コンポーネント間では、メタデータを介してやり取りを行います。
コンポーネント間でアーティファクトを直接受け渡すのではなく、コンポーネントはアーティファクトへの参照を受け渡します。
アーティファクトは生データや、変換されたデータなどが挙げられます。
メタデータストアで集中管理することができるのが、大きなメリットになります。
MetadataStoreは、指定したデータベースバックエンドにメタデータを保存します。
4.TFX(ExampleGenについての説明):データの取り込み
ここからTFXを中心に解説していきます。
データの読み込みの元となるソースはBigqueryだったり、Avroだったりさまざまなデータを読み込むためのクラスを備えています。
今回は、ローカルのCSVファイルを読み込んでいきたいと思います。
4.1 環境構築の作成
ここからの説明は、この本の3章を元に説明しています。
githubにソースコードなどがありますが、そのままのバージョンでインストールするとエラーが起きてしまい、
TFXが実行できませんでした。
よかったら、このバージョンで動かしてみてください。公式ドキュメントを参考にして、競合が起きないパッケージを選びました。
!pip install tfx==1.9.0
!pip install tensorflow==2.9.0
では実際に、コードを書いていきます。
#ライブラリのインポート
import os
import tensorflow as tf
from tfx.components import CsvExampleGen
from tfx.orchestration.experimental.interactive.interactive_context import \
InteractiveContext
context = InteractiveContext()
example_gen = CsvExampleGen("/content/drive/MyDrive/movielens/Untitled Folder")
context.run(example_gen)
InteractiveContextは、
TFX パイプラインをインタラクティブモードで実行するためのコンテキストです。
それをインスタンス化し、
context.runでexample_genを実行させています。
この状態は、ただ読み込みを実行させているだけなので
メタデータにメタデータが保存されているわけではないので注意が必要です。
4.2 別のファイルのインポート手法
データをCSVで表現することが効率的ではない場合もあります。
例えば、画像を読み込みたい場合や、自然言語処理用に大規模なコーパスを読み込みたい場合などがあります。
このような場合は、TFRecordで変換することが考えられます。
TFRecordはデータをバイナリ形式で保存することができるのでデータ圧縮することが可能です。
その場合は、CsvExampleGenの部分がImportExampleGenに変わります。
5.まとめ
パイプライン構築のhow toはなかなか日本語がないのでとても困っていましたが、
この本のおかげでなんとか学習できそうです。
今回は、パイプラインの構築の概要とBEAM、データの取り込みまで行いました。
次はデータ検証から順に行っていきますので、投稿お待ちください。
それでは!