1.取り組んだきっかけ
Azureのデータパイプライン構築についてのサービスを知りたかった
GCPやsnowflakeなどのサービスについては少し触った経験があったが、Azureについては触れたことがなかった。
(AWSもAthenaのクローラーなども触ったことがあった)
GCP・Azure・AWSこの3大クラウドサービスを是非とも触ってみたかった。
調べていくと、何やらAzure Synapse Analyticsというものがあるらしい
要約すると、
S3やData Lake Storage Gen2などのデータレイクサービス
Apache Sparkなどを動かすことができるDataBricks(ETLや機械学習モデル構築)
Synapse SQL(DWH)
これらのサービスの統合をサポートするサービスだそう。
私自身Apache Airflowなどを学習していた部分があったが、
学習コストがかなり高いなと感じていた。
GUI上で操作できたらすごい便利だな〜と感じていたので、とてもハマった
2.参考にした学習サイト
こちらが参考にさせていただいた学習サイトになります。
あくまでもこのサイトは、Synapse AnalyticsのGUI上でデータパイプライン構築しようという題材から、
事前にsetupのコードが渡されている。
すぐにGUI上でパイプライン構築したいな〜と思われている方にはとても良いが、
Data Lake Storage Gen2や
Synapse SQL(DWH)のセットアップからやってみたいという方には少し物足りないものかと思います。
作成したパイプラインは以下の通りになります
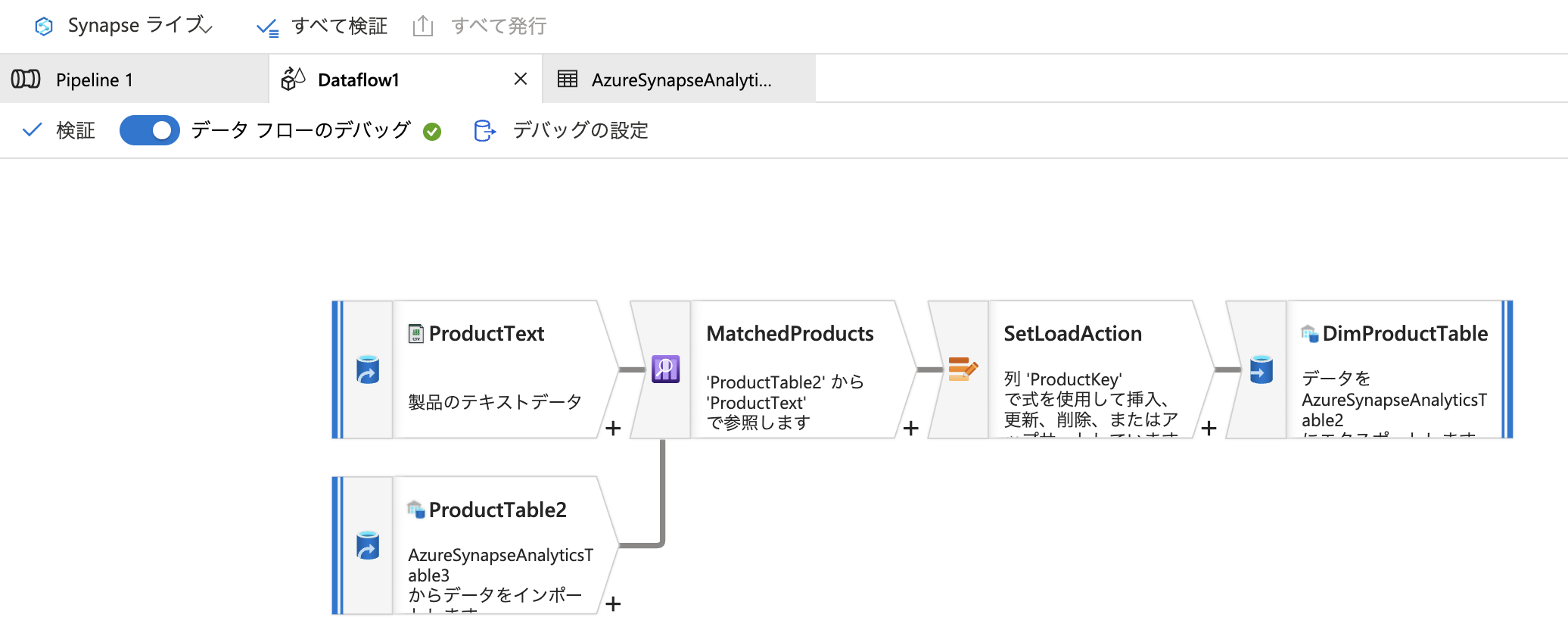
①データレイクサービスからテキストデータを
DWHからテーブルを参照して、外部結合し
②マッチしたデータを更新して
③マッチしないデータはそのままにし
④不要な列を削除して
⑤元のDWHを更新するというような作業になってます」
これが全て簡単に実行できました。
是非活用してみてください
3.これからの展望
以下のUdemyの教材がありました。
評価もかなり高く、時間もかなり長いので、勉強になりそうです。
日本語が対応していないのがとても弱みですが、サービス概要などが図で表されているので、
なんとか解読できるようにしていきます。