はじめに
はじめまして、Qiita初投稿になります@pololo648と申します。
私は京都のとある会社で働いているのですが、弊社の慣習として会議の議事録は一番年下がとる、というルールがあります。最近は後輩が増えてきたので私が作成する機会は減ってきましたが、それでも結構な頻度で作業が発生しています。なんとかこの業務を圧縮できないかと考えたときに、
スマホで録音すればええやん!と考えたわけですが、さらに、
スマホやったら音声認識できるやん!参加者の数だけスマホを使えば誰が発言したかも分かるやん!
という思いつきから、以下のような自動議事録作成アプリを作成しました。
http://cool-meeting.com

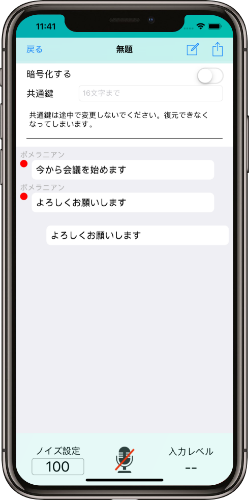
本稿ではアプリ作成に使ったコア技術の紹介をしたいと思います。
実現すべき機能
最低限実現すべき機能は
1.音声認識機能
2.リアルタイム同期機能
3.クライアントサイドでの暗号化機能
と考えました。それぞれ解説していきます。
音声認識機能
この機能は音声の書き起こしのために使用します。iOSではSiriと同じ音声認識エンジンがSFSpeechRecognizerという機能で公開されています。また、AndroidもOK Googleと同じ音声認識エンジンがSpeechRecognizerという機能で公開されています。音声認識はクラウドサービスを利用する方法もありますが、iOSやAndroidで実装すればコストがかからないメリットがあります。
今回はiPhone対象のアプリを実装しましたのでSFSpeechRecognizerを利用しました。
実装は以下が参考になりました。
https://qiita.com/KentaKudo/items/8473146d5d596069b857
認識部分を抜粋します。
func recognize(){
recognitionTask = speechRecognizer.recognitionTask(with: self.recognitionRequest!) { [weak self] (result, error) in
guard let `self` = self else { return }
var isFinal = false
if let result = result {
if let recog_text: String = result.bestTranscription.formattedString as String{
// 認識途中の結果が得られる
print(recog_text)
}
isFinal = result.isFinal
}
if error != nil {
// timeoutで処理するためここでは何もしない
}
if isFinal{
// 認識終了
return
}
if error == nil{
// 次の入力まで2秒のタイムアウトを設定
self.speechTimeoutInterval = 2
return
}
}
}
SFSpeechRecognizerはSFSpeechAudioBufferRecognitionRequestというバッファを使って音声をバッファリングすることができます。このSFSpeechAudioBufferRecognitionRequestはshouldReportPartialResultsをtrueとすることで、SFSpeechRecognizerが認識途中の結果を取得できます。
self.recognitionRequest = SFSpeechAudioBufferRecognitionRequest()
self.recognitionRequest!.shouldReportPartialResults = true //途中結果を受け取るか
最近の音声認識処理を含む自然言語処理のAIはコンテキスト(文脈)情報を使ってうまく類推するように学習していますので、情報を補完するような後続の入力があった場合は認識途中の結果が変わったりします。例えば、bankという単語は文脈によって「土手」と「銀行」をとり得えますので、後続の単語によって意味が決定されます。
認識途中の結果は変わってしまうので入力音声の終了をisFinalフラグで検知して、isFinalフラグが立ったときに最終結果を受け取れば良いのですが、isFinalフラグの設定は大味になっているため使いづらく感じました。具体的には30秒とか相当な時間の無音区間がないとフラグが立たないようでした。(入力文によって変わるかもしれません)
そこで、タイマーを使って2秒間の無音区間を検出すると強制的に文の終わりと判断するように実装しました。
private var speechTimeoutInterval: TimeInterval = 2 {
didSet {
restartSpeechTimeout()
}
}
private func restartSpeechTimeout() {
speechRecognitionTimeout?.invalidate()
speechRecognitionTimeout = Timer.scheduledTimer(timeInterval:speechTimeoutInterval, target: self, selector: #selector(timedOutRecognition), userInfo: nil, repeats: false)
}
timedOutRecognition関数を定義して、タイムアウト処理を実装しています。
その他に、SFSpeechRecognizerには以下の制限があります。
-
一度に認識できる音声データは60秒まで
http://www.cl9.info/entry/2018/01/14/184548 -
認識処理は1時間あたり1000回まで (1デバイス)
https://developer.apple.com/library/archive/qa/qa1951/_index.html#//apple_ref/doc/uid/DTS40017662 -
デフォルトの無音区間のタイムアウトは30秒
Code=203 "SessionId=com.siri.cortex.ace.speech.session.event.SpeechSessionId@747da8d, Message=Timeout waiting for command after 30000 ms"
- バックグラウンドで認識処理は動かせない
https://forums.developer.apple.com/thread/112225
上記のうち、上3つは自前タイマーで解決できそうですが、バックグラウンドで動かない制限は現在のところ解決手段はなさそうです。SFSpeechRecognizerのアップデートでいずれ対応してくれると期待して、今回は仕方なくアプリ実行中はスクリーンオフしないように制御するようにしました。
UIApplication.shared.isIdleTimerDisabled = true
リアルタイム同期機能
この機能は書き起こしたテキストを議事録に書き込んだときに、更新を他のユーザ端末に通知するために使用します。例えるなら5人でチャットをしているときに、1人の発言を他の4人の端末にも反映させるようなものです。
この機能はどう実現すれば良いでしょうか?
単純に考えると参加者の端末がそれぞれ一定時間ごとにサーバに問い合わせ(ポーリング)をすれば実現できそうです。しかし、この設計ではポーリング間隔を300ミリ秒とか500ミリ秒とか、許容できる(イライラしない程度に待てるぐらいの)短い時間に設定しなければいけません。サーバ側は問い合わせの度に更新があるかどうかを確認し、更新があれば結果を返すというように、常にリクエストをさばき続けなければいけません。これではユーザが増えたときに破綻することは目に見えています。そこで、最近はMQTTというプロトコルを使ってリアルタイム同期機能を実現します。ここらへんの歴史とMQTTの詳細については以下のリンクが参考になりました。
https://www.slideshare.net/mawarimichi/websocketwebrtc
詳細は割愛しますが、MQTTを使うことでPub/Subメッセージングモデルという形式でサーバとデバイスがやり取りすることになり、変更があったときにサーバからデバイスにメッセージを通知することが出来るようになります。そのため、ポーリング方式に比べて遥かにリアルタイム性を上げることができます。
このようなリアルタイム同期処理を実現する仕組みとしてGoogleのFirebaseやAmazonのAppSyncが有名です。それぞれ高速に処理するためにオンメモリのDBを用意したり、データ保存用のDBを用意したり、変更を通知する処理を実装したりといったサーバ側の設定をほとんどやってくれていますので、サーバーレスで簡単に実現することができます。今回は私の勉強のためにAppSyncを採用しました。
AppSyncの使い方は公式のチュートリアルとGithubが参考になりました。
https://docs.aws.amazon.com/ja_jp/appsync/latest/devguide/welcome.html
今回は複数の議事録と、1つの議事録に複数のコメントが格納される構成でしたので、公式チュートリアルのBlogサンプルがそのまま使えました。また、iOSとの連携は以下の記事が参考になりました。
https://qiita.com/Tanashun/items/edf297eaeeb6c04130ca
https://qiita.com/papi_tokei/items/ee4abf44703f8692f006
必要なことのほとんどは上記リンクに記載されていましたので本稿でコピペする必要はないと思いますが、1点だけ補足として、AppSyncの認証をAPI_KEYに設定した場合デフォルトでは有効期限が1週間に設定される点は注意が必要でした。
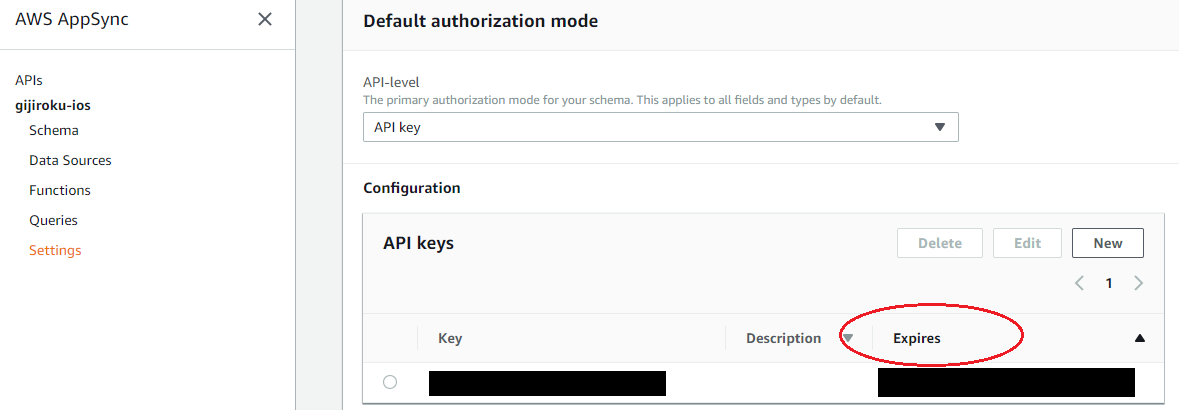
APIキーの有効期限は最大365日まで設定可能です。アプリをリリースする場合は忘れずに適切な長さに設定しておく必要がありました。
https://docs.aws.amazon.com/ja_jp/appsync/latest/devguide/security.html#api-key-authorization
クライアントサイドでの暗号化機能
会議の議事録を扱うというセンシティブな内容ですので、ほとんどの人は会議内容が漏れるリスクを懸念すると思います。今回はアプリのバックエンドを全てサーバレスで実装しましたので、アーキテクチャにバグがあって漏洩するというリスクは低いと思いますが、管理者(=私)が盗み見ているリスクも捨てきれません。(もちろんしませんが)
そこで、認識したテキストをAppSyncに送る前に暗号化する処理を実装しました。実装はCryptoSwiftを利用しています。以下の記事がとても参考になりました。
https://qiita.com/ochim/items/4690cdc5e7fde9ad1b45
暗号化方式はAESを採用しました。これは暗号化と復号を同じ鍵を使う方式で、共通鍵暗号方式と呼ばれます。今回は複数人で会議をするときに全員が復号しないといけないので、鍵は参加者で共有できるAESを採用しています。これで安心して議事録の作成ができるようになったかと思います。
最後に
SFSpeechRecognizerとAppSyncを使って、実現したかった議事録自動作成の機能は実装できたかなと思います。
音声認識を使った議事録作成ソリューションは既に世の中にいろいろありますが、このアプリの良いところは初期投資(H/W)がいらないことだと思っています。マイクも音声認識エンジンもスマホに入っていますからね。また、リッチな議事録作成のためには誰が発言したかという解析処理(Speaker Dialization)も必要ですが、これは1台のマイクを使うだけでは難しく、高度な処理が必要となります。この問題も複数のスマホを使うことで簡素に解決できたと思います。
今回はシンプルな機能のみ実装したアプリとなっていますが、ぜひ皆さんにもお使いいただいて、他にもあったら良い機能をリクエストしていただければ嬉しいです。