はじめに
慶應大学 理工学部 情報工学科 B3のぽこちゃんです
今回は技術系の記事を書きます!
学校の実験でAWSを一万円分くらい自由に使わせてもらえたので
タイトルにもあるとおり
AWSのKendraとGPTで自社ドキュメントを学習させたLINEbotを作った話
ソースコードも晒すのでぜひ作ってみてね
お金そこそこかかるので気をつけましょう
Xもやってるのでぜひフォローお願いします
フォロバします!
アーキテクチャについて

全体的にはこんな感じ
- LINEで質問を投げる
- S3に保存してあるドキュメント(PDF)からKendraでindexを作る
- LambdaでLINEから得た質問をクエリにしてKendraで類似するチャンクを3つ取得する
- チャンクのテキストとLINEの質問を組み合わせてGPTに投げる
- GPTから得た回答をLINEに出力する
早速作っていきましょうか
Kendraの設定から
AWSのアカウントは用意している前提で話を進めていきます
まずが上部の検索欄から Kendraと調べて下記のページに辿り着きましょう
その後右側のCreate an Indexを押してください
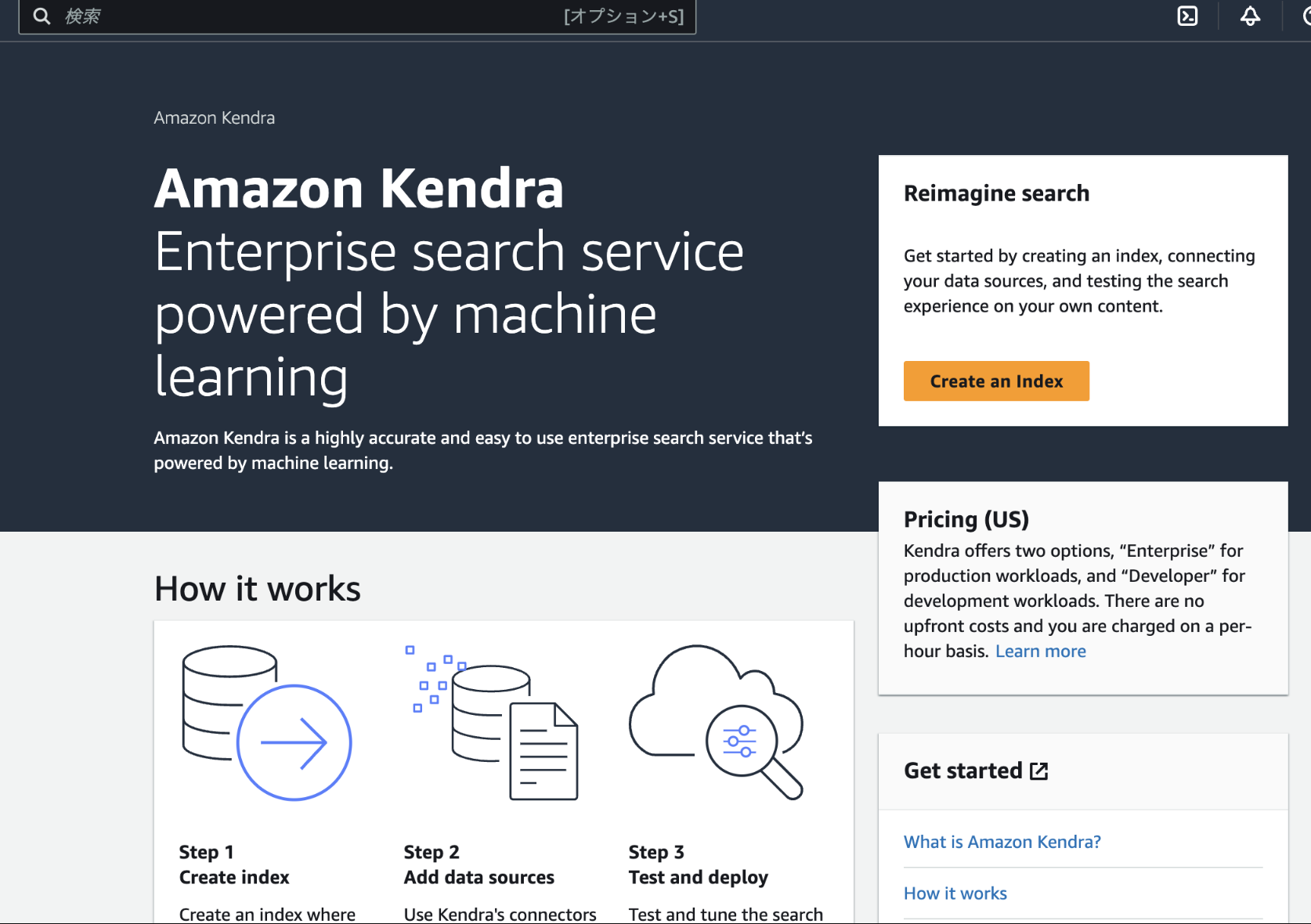
設定画面に移るのでこのページで設定するのは二つ
- Index name
- IAM role
その他はオプションなので必要の応じて設定してください


IAM roleは青部分で言われているように
Create a new roleが勧められています
IAM roleについて詳しくなければそうした方が便利です
(自分で権限設定しなければいけないので)

画面下部のNextを押して次に進みます
Step2,Step3と進んでいきますが特にこだわりがなければデフォルトで大丈夫です
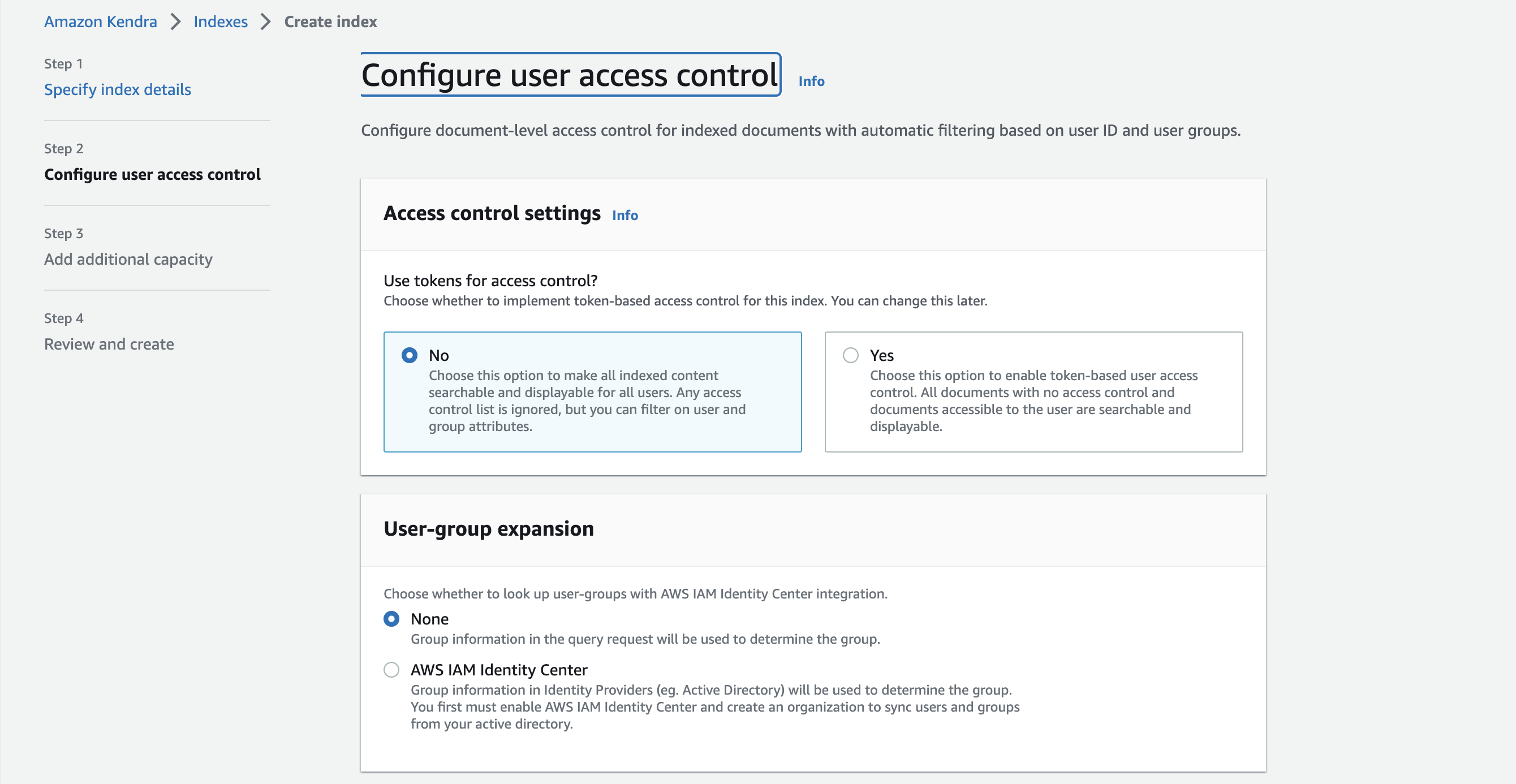
Review and createまで進んだら
画面下部のcreateを押してIndexを作成します
これ結構時間かかります
その間にデータソースとなるS3の設定をしましょう
S3の設定
今回はデータソースとしてS3を用います
他にもWebCrawlerの設定もできるので自動でクロールしてきてってのもできます
さっきと同様にS3と検索して
バケットを作成を押しましょう
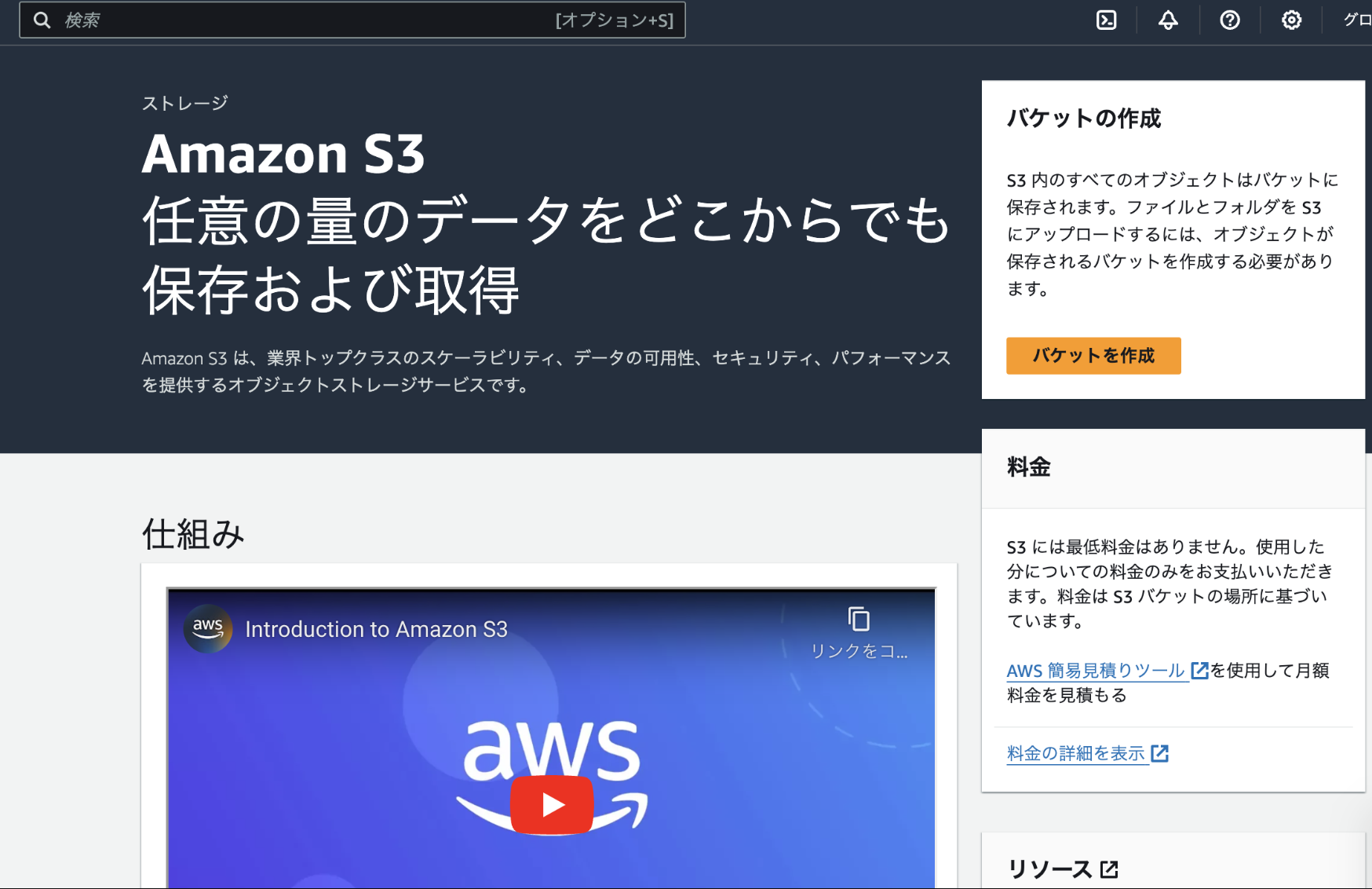
バケットの設定をしていきますが基本的にはデフォルトでいいです
設定したのはバケット名ぐらいですかね

バケットを作成したら何かドキュメントをアップロード(pdf)しておきましょう
その際に
s3://hogehoge/
(hogehogeはバケット名)というS3のURIを得ることができますが
後で使うのでメモっておいてください
そろそろKendraのIndex作成が終わった頃だと思うので戻りましょう
KendraとS3のSync
Kendraの画面に戻って左側のメニューを見てください

Data sourcesを選択すると
データソースの候補がたくさん出てきますが今回はS3なので
S3 connectorというのを探してください
Add connector をポチッと

connectorの設定画面に移るのでStepに従って進めていきます
ここで変えるのは
- Step1
- Data souece name (任意の名前)
- Default language (データソースの言語)
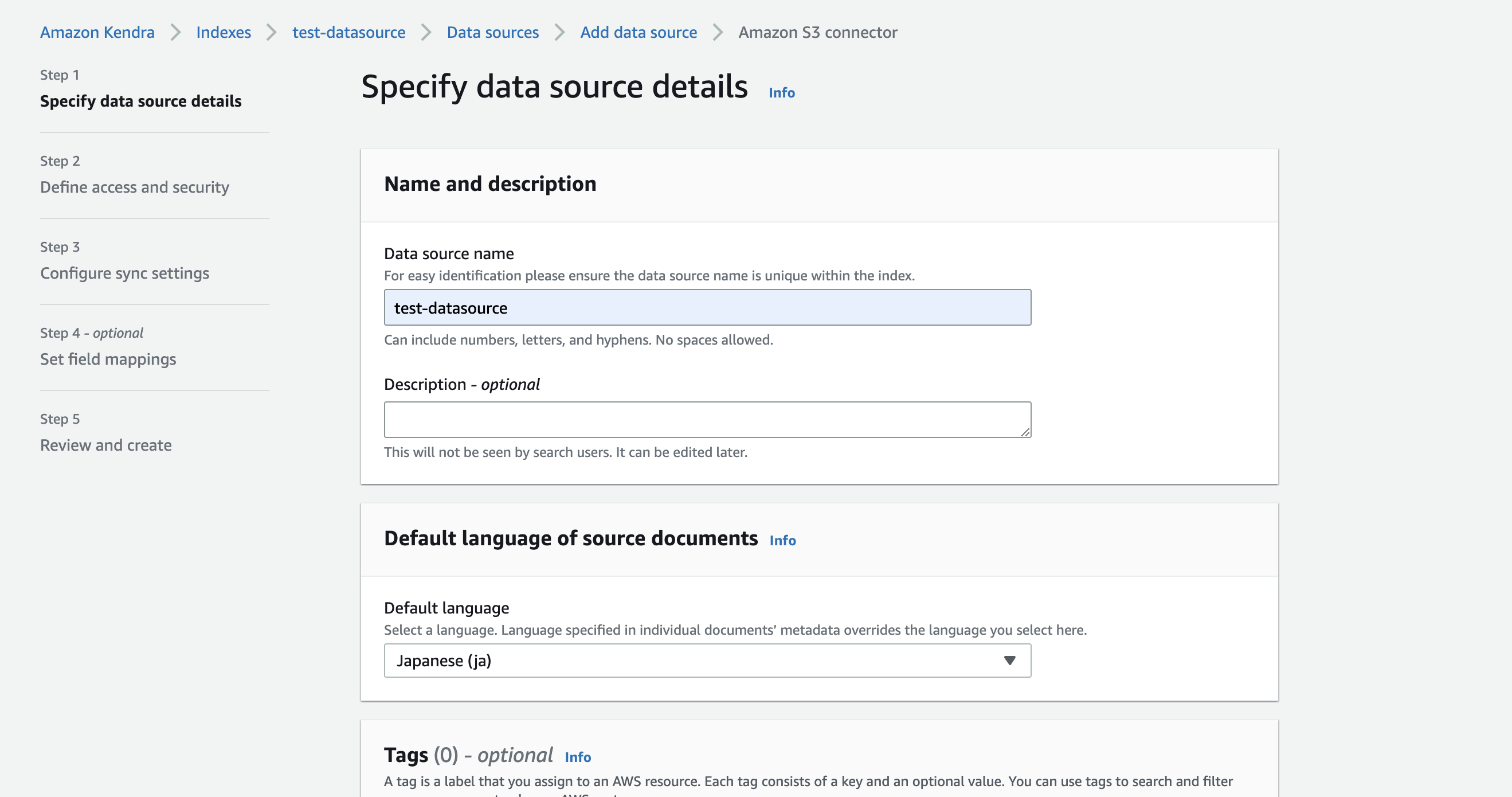
- Step2
- IAM role (さっきと同じように新規作成で平気です)

- Step3
- data source location
- さっき取得したs3://hogehoge/
- maxfile size
- テキトーに100 MBにしてます
- Sync run schedule
- Run on demandにしています
- 手動でsync nowボタンを押したら同期する設定にしてます
- data source location


- Step4,5
- デフォルトでOKだがfield mappingした方が精度上がるかも?
Sync now を押して同期をスタート!
これまたかなり時間かかります(30分くらい??)
その間にLambdaの設定をしちゃいましょう!
Lambdaの設定
Lambdaの設定をしていきます
ここでは
- 関数名
- ランタイム (Python 3.9)
- アーキテクチャ (x86_64,arm64どちらでも可)
を選択します
Pythonのバージョンは3.9にしましょう!
OpenAI,boto,LINESDKと色々importするのですが
各ライブラリの互換が取れるのが3.9だったと思います
3.11でやってたらクソ苦労しました
まじで半日かけた
関数ができたらこっから設定していきます

Lambdaのコードについて
コードは以下の通り
設定していただく必要があるのは
- "LINE_CHANNEL_ACCESS_TOKEN"
- "OPNEAIのAPIキー"
- 'KendraのindexID'
- 種々のプロンプト
KendraのindexIDってなんだって話ですが
kendraに戻っていただいて以下の赤丸で囲った部分です!

import boto3
import json
import langchain
import os
import openai
from openai import OpenAI
from linebot import LineBotApi
from linebot.models import TextSendMessage
kendra = boto3.client('kendra')
LINE_CHANNEL_ACCESS_TOKEN = os.environ['LINE_CHANNEL_ACCESS_TOKEN']
LINE_BOT_API = LineBotApi(LINE_CHANNEL_ACCESS_TOKEN)
openai_API_key = "OPNEAIのAPIキー"
os.environ["OPENAI_API_KEY"] = openai_API_key
openai.api_key = os.environ.get('OPENAI_API_KEY')
client = OpenAI()
def lambda_handler(event, context):
replyToken = event['events'][0]['replyToken']
if event['events'][0]['type'] == 'message':
if event['events'][0]['message']['type'] == 'text':
# LINEからのメッセージをクエリにする
query_text = event['events'][0]['message']['text']
index_id = 'KendraのindexID'
response = kendra.retrieve(
QueryText=query_text,
IndexId=index_id,
AttributeFilter={
"EqualsTo": {
"Key": "_language_code",
"Value": {"StringValue": "ja"},
},
},
)
# Kendra の応答から最初の3つの結果を抽出
results = response['ResultItems'][:3] if response['ResultItems'] else []
extracted_results = []
for item in results:
content = item.get('Content')
document_uri = item.get('DocumentURI')
extracted_results.append({
'Content': content,
})
print("Kendra extracted_results:" + json.dumps(extracted_results, ensure_ascii=False))
prompt = get_prompt(
ref_list=extracted_results,
query=query_text)
completion = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "user",
"content":str(prompt)}
]
)
print(completion.choices[0].message)
# LINEにChatGPTの回答を送る
messageText = completion.choices[0].message
LINE_BOT_API.reply_message(
replyToken,
TextSendMessage(text=messageText.content))
return None
def get_Hypothesis(
query:str
)->str:
assert query != None
hypothesis = hypothesis_dict(query=query)
completion = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "user",
"content":str(hypothesis)}
]
)
return str(completion.choices[0].message)
def get_prompt(
ref_list:list,
query:str
)->str:
assert ref_list != None
refs_template = ""
for i,item in enumerate(ref_list):
content = item['Content']
refs_template += "・{}".format(content) + "\n"
prompt = prompt_dict(
refs_template=refs_template,
query_text=query
)
return prompt
def hypothesis_dict(
query:str
) -> str:
prompt = """
背景情報を与えるプロンプト
"""
prompt.format(query=query)
return prompt
def prompt_dict(
refs_template:str,
query_text:str
)->str:
prompt = """
欲しい回答を与えるプロンプト
"""
return prompt.format(ref_template=refs_template,input_text=query_text)
もしかしたら get_Hypothesis使ってないかもです
API周り友達に任せちゃってたので聞いてみます
Lambdaのレイヤー設定について
コードはこれでOKですがライブラリが入ってないのでこれを追加します
ここがいちばんの難関なんですわ
チームで作る場合はできる人に任せた方がいいです
参考にしたのは記事の以下の部分です
(参考情報) Boto3のバージョンが古い場合の対応方法
基本的には
- ローカル環境で仮想環境を用意する
- ディレクトリを作成
- 2で作成したディレクトリにライブラリを入れる
- 3のディレクトリをpythonという名前に変える
- 4のディレクトリをzipする
- 4でpythonという名前にしないとレイヤーで読み込んでくれない
- zipファイルは大きすぎるとuploadできないのでレイヤー3つぐらいに分けた方がいいです
- 特にopenaiデカすぎなので
installするものリスト
line-bot-sdk
boto3
autopep8==1.6.0
certifi==2021.10.8
charset-normalizer==2.0.7
click==8.0.3
et-xmlfile==1.1.0
idna==3.3
itsdangerous==2.0.1
Jinja2==3.0.2
MarkupSafe==2.0.1
numpy==1.21.3
openai==1.3.6
openpyxl==3.0.9
pandas==1.3.4
pandas-stubs==1.2.0.35
pycodestyle==2.8.0
python-dateutil==2.8.2
python-dotenv==0.19.2
pytz==2021.3
requests==2.26.0
six==1.16.0
toml==0.10.2
tqdm==4.62.3
langchain==0.0.344
tiktoken==0.5.1
もしかするといらんもの入ってるかも

互換性のランタイムの部分はpython3.9を選ぶようにしてください!
LINEBotの設定
ここまですると話長くなってしまうので以下の記事を参考にしてください
あんまり難しくないです
APIGatewayの設定も必要です!
LINEとの接続もできたら完成です!
お疲れ様でした!
まとめ
AWSを用いて自社ドキュメントを学習させたLINEbotを作ってみました!
今回はS3に保存したデータを用いましたが
他にもデータソース選べるので無限にアイデアが膨らんできますね
ただ一点注意事項として
お金まあまあ使うので気をつけてください
Xもやってるのでぜひフォローお願いします
ご読了ありがとうございました!