おはこんばんにちは、 2023年12月に入りました。いかがお過ごしでしょうか!
NervesJP のポジローです。
#NervesJP のアドベントカレンダーを作った際にトップバッターを埋めたことを若干、若干ね、後悔しています(頑張って書くとはどこかでいいましたが、結局ギリギリになって書いている自分がいます
などと弱音は吐きますけど、始めていきましょう!
本記事は、 Nerves と直接の関係はないのですが、2023年は NIF を書く機会があったのでその際に私が学んだことや気づいたことを紹介できたら思います。
NIF を書くことになったきっかけ
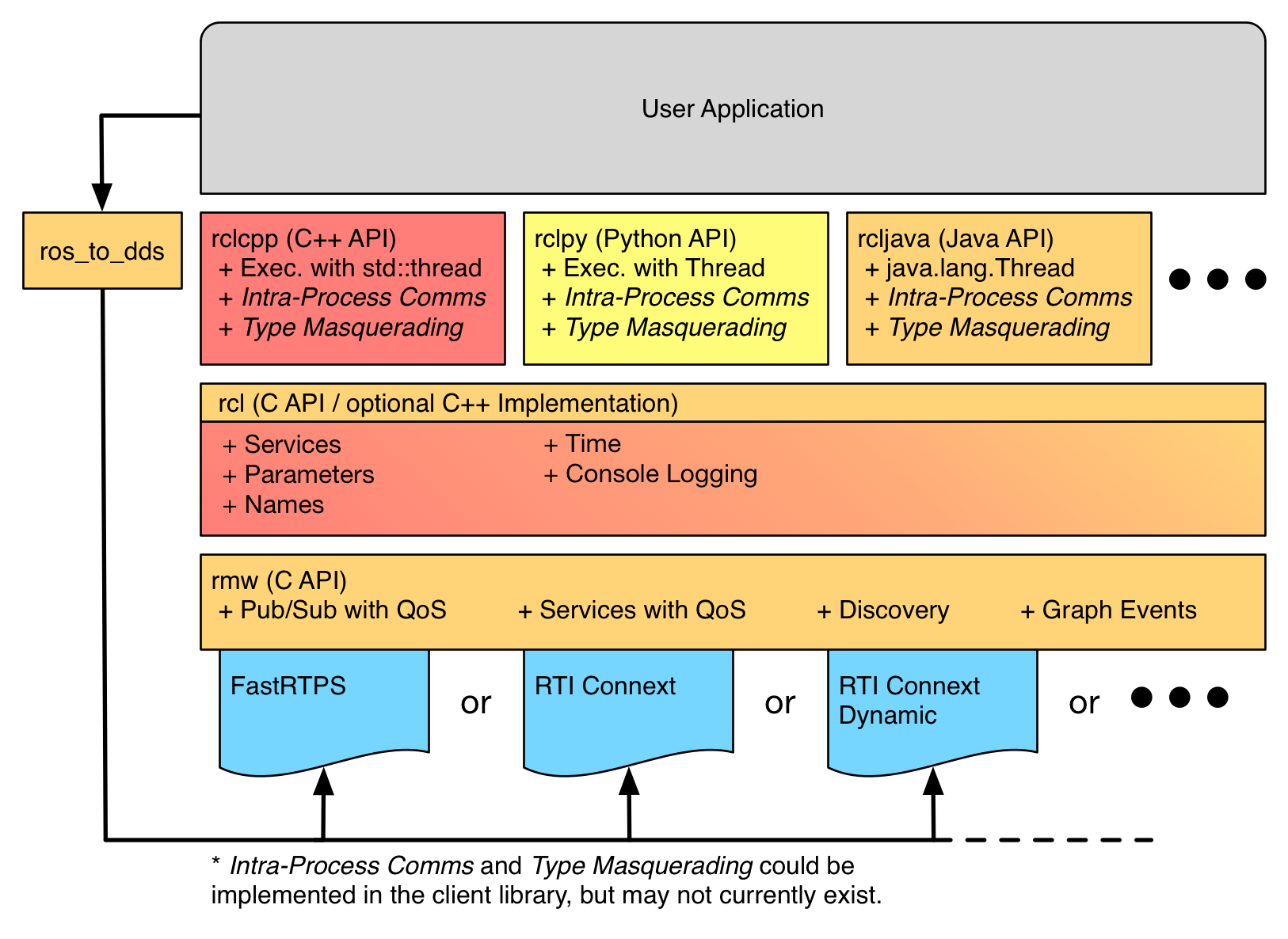
ROS 2 クライアントの Elixir 版として @takasehideki がコードオーナーの Rclex があります。
ROS 2 クライアントには rclcpp や rclpy などがありますが、その Elixir 版です。
これらクライアントは rcl という ROS 2 の C言語ライブラリ を C++, Python から呼び出して 各言語でのユーザ API を提供しています。 Rclex も例外にもれず、 rcl を NIF から呼び出しています。
Rclex は 2022年、2023年とコントリビュートさせていただく機会があり、そのプロセスで理解が深まったことで「動く Nerves」(カレンダー別日で書きます)を作れるのでは?となり実現もできました。

※ 動画 was made by @takasehideki & @Shintaro_Hosoai
これらを経て、 Rclex の面白さを知り、「もっと発展させたい」と「こうなってたらいいのにな」というちょっと勝手ではありますが、そういった思いをもちました。
それがきっかけとなり Rclex にコントリビュートしようとなって、今は 0.10.0 系の開発に参加しています。
不定期ではありますが、開発ミーティングもしています。
0.10.0 系は再設計を行うため、 NIF もリライトすることになりました(しました)。
それが本記事につながっています。
NIF を書く前に知っておくこと
ここからは NIF を書くことの話をしていくのですが、書き始める前に知っておいたほうがいいことがあるのでそれをさらっと紹介します。
NIF を使うことのトレードオフ
Erlang の公式ドキュメントにもあるように
As a NIF library is dynamically linked into the emulator process, this is the fastest way of calling C-code from Erlang (alongside port drivers). Calling NIFs requires no context switches. But it is also the least safe, because a crash in a NIF brings the emulator down too.
NIF を実装するとは emulator process である BEAM に動的にリンクされる共有ライブラリを実装することです。NIF である共有ライブラリは BEAM にリンクされるので、例外が発生した場合、その取り回しが悪いと BEAM ごとクラッシュします。処理の実行速度を手にする代わりにリスクを負うことになります。
Rustler は安全に NIF を書くために、 Rust で NIF を書くことを可能にするライブラリのようです。
が、 Rclex では C言語ライブラリである rcl を C の薄いラッパーとなる NIF でラップして呼び出すので Rustler は使わず、 C で NIF を書いています。
C で NIF を安全に書くにはどうしたらいいのか?
書き始める前に(書きながらだったかもだけど)、どのようにしたらできるだけ安全に C が書けるか悩んでいました。
このような場合、自分の無い頭を絞るよりは、先人たちの知恵を借りるのが得策です。
まず、 @zacky1972 が "Describe Robust NIFs: Elixir& C with Performance for Fault-tolerant Systems" という発表をされている動画があるので、まずこれを見ました。
ポイントは以下の3つで、
① Appropriately set a conditional branch where each function call may return an uncertain value.
①各関数呼び出しが不確実な値を返す可能性がある条件分岐を適切に設定すること
② Perform error handling according to general conventions.
②一般的な規則に従ってエラー処理を実行すること
③ Make assertions that specify implicit preconditions and raise exceptions for Supervisor to handle.
③暗黙的な前提条件を指定するアサーションを作成し、(それに違反したら)スーパーバイザーが処理する例外を発生させること
で、それぞれについて解説されています。自身 NIF を実際に書いてみて、そのとおりだと思いました。これは後述します。
次に、(実際には実装しながら良い書き方を探す中で)既に実装され使われているコード参考にしました。
読んだのは、CouchDB の 以下のコードです。
悩んだ時は既に使われている良い意味で枯れた実装を参考にしました。コードが公開されていることに感謝です。
実際に書いたコードを解説してみる
紹介するコードは Rclex の次期バージョンの開発ブランチ 0.10.0-dev からです。2023年12月は存在しますが、それ以降に本記事を読んでそのブランチが存在しなかったら main を見てみて下さい。多分マージされているはず(そのはず、そうであれ!)です。
以下のコードは rcl の context というリソースの終了処理をラップした関数 nif_rcl_fini です。
※この関数を選んだのは比較的紹介しやすいと判断したからです。
ERL_NIF_TERM nif_rcl_fini(ErlNifEnv *env, int argc, const ERL_NIF_TERM argv[]) {
if (argc != 1) return enif_make_badarg(env);
rcl_ret_t rc;
rcl_context_t *context_p;
if (!enif_get_resource(env, argv[0], rt_rcl_context_t, (void **)&context_p))
return enif_make_badarg(env);
if (!rcl_context_is_valid(context_p)) return raise(env, __FILE__, __LINE__);
rc = rcl_shutdown(context_p);
if (rc != RCL_RET_OK) return raise(env, __FILE__, __LINE__);
rc = rcl_context_fini(context_p);
if (rc != RCL_RET_OK) return raise(env, __FILE__, __LINE__);
return atom_ok;
}
この関数は以下のようにバインディングしており、
static ErlNifFunc nif_funcs[] = {
...
{ "rcl_fini!", 1, nif_rcl_fini, ERL_NIF_DIRTY_JOB_IO_BOUND },
...
};
Elixir からは以下のように呼び出される、引数が一つの例外を起こすことが想定される関数です。
rcl_fini!(context) # context は reference 型 の NIF リソース
それでは、 nif_rcl_fini を少しずつ見ていきます。
まず、引数の数チェックです。
if (argc != 1) return enif_make_badarg(env);
これは、どんな NIF 実装でも書かれていると思いますが、意図通りの引数の数で呼ばれてるかをチェックしています。意図と異なる場合は、問答無用で return です。 enif_make_badarg は badarg の例外を Elixir 側に返します。
引数の数があっていたら、引数が意図したリソース型であることを確認して、 Elixir の世界から C の世界に読み込みます。
if (!enif_get_resource(env, argv[0], rt_rcl_context_t, (void **)&context_p))
return enif_make_badarg(env);
ここでも、意図と異なる場合は、問答無用で return です。
NIF の関数ではまず、 Elixir の世界から C の世界に入ってくるものが意図通りのものであるかをチェックします。 これはそうですよね。だって、意図と違うものが入ってきたら困ってしまいます。意図と異なった時点で即、例外リターンで Elixir の世界に返しておけば、C の世界を守ることができ、それはすなわち BEAM を守ることになります。
これはハンドリングとして general な convention なので、 @zacky1972 の言うところの ② に相当すると思います。
次は、 rcl の機能を使ってさらに読み込んだ値をチェックしています。
if (!rcl_context_is_valid(context_p)) return raise(env, __FILE__, __LINE__);
context が valid でない場合、ここでは自作の raise 関数 を呼び出して return しています。
関数名のとおり何らかの例外を返す関数です。
raise 関数については後述します。
ここからは雰囲気が分かったと思うのでまとめて説明します。
rc = rcl_shutdown(context_p);
if (rc != RCL_RET_OK) return raise(env, __FILE__, __LINE__);
rc = rcl_context_fini(context_p);
if (rc != RCL_RET_OK) return raise(env, __FILE__, __LINE__);
return atom_ok;
rcl_shutdown は context のシャットダウン処理をします。このシャットダウン処理は以下を返す可能性があります。
RCL_RET_OK: if the shutdown was completed successfully, or
RCL_RET_INVALID_ARGUMENT: if any arguments are invalid, or
RCL_RET_ALREADY_SHUTDOWN: if the context is not currently valid, or
RCL_RET_ERROR: if an unspecified error occur.
なので、ここまでのチェックで RCL_RET_OK が返らない限りは、想定し得ない異常なこと(メモリリークではないけどメモリが枯渇したとか、ハードが壊れたとか)が起きていると思います。
(そんなことが起きていたら NIF に関係なく BEAM もおかしくなっているはずです。)
なので、 RCL_RET_OK が返らないのであれば raise させています。 rcl_context_finiも同様です。
関数から返りうる値を想定し、適切な条件分岐を書いていますし、ある意味で RCL_RET_OK が返るべきという assert を意図していますので @zacky1972 のポイントの ①、③に相当すると思います。
で、すべて正常に終わったら :ok アトムを返しています。 atom_ok は自作です。これも後述します。
工夫
自作の raise 関数
assert なそうあるべしという条件分岐にも関わらず、例外が発生した場合、開発中だとそれはバグであることが多い(かった)です。なので、それがどこで発生したかを分かるようにしたいモチベーションがありました。
そこで、以下のような自作の raise 関数を用意しました。
static inline ERL_NIF_TERM raise(ErlNifEnv *env, const char *file, int line) {
char str[1024];
snprintf(str, sizeof(str), "at %s:%d", file, line);
return enif_raise_exception(env, enif_make_string(env, str, ERL_NIF_LATIN1));
}
static inline ERL_NIF_TERM raise_with_message(ErlNifEnv *env, const char *file, int line,
const char *message) {
char str[1024];
snprintf(str, sizeof(str), "at %s:%d %s", file, line, message);
return enif_raise_exception(env, enif_make_string(env, str, ERL_NIF_LATIN1));
}
raise を利用する箇所が多くなるので、発生箇所を明確にするためにファイル名と行数が分かるように工夫しました。
Rclex ユーザーが例外を検出した場合は、 Rclex のバージョンと箇所を書いた issue を挙げてもらえれば、少なくともどこで起きたかは分かります。
よく使う atom は事前に作っておいて使い回す
ERL_NIF_TERM atom_ok;
ERL_NIF_TERM atom_error;
ERL_NIF_TERM atom_true;
ERL_NIF_TERM atom_false;
void make_atoms(ErlNifEnv *env) {
atom_ok = enif_make_atom(env, "ok");
atom_error = enif_make_atom(env, "error");
atom_true = enif_make_atom(env, "true");
atom_false = enif_make_atom(env, "false");
}
これはよくある手法のようで、 CouchDB の khash.c でもそのような実装があります。
:ok, :error なんかはよく使うので毎回作らず load 時に作っておけば、(実装も実行も)効率いいはずです。
避けては通れないかも DirtyNIF
以下のコードを書いた時に、触れていない点がありました。 ERL_NIF_DIRTY_JOB_IO_BOUND です。
static ErlNifFunc nif_funcs[] = {
...
{ "rcl_fini!", 1, nif_rcl_fini, ERL_NIF_DIRTY_JOB_IO_BOUND },
...
};
以降は私の想像が多いので、疑いながら読んで下さい
BEAM は erlexec により実行されるとその子プロセスとしてスケジューラーを作ります。
erlinit が起動する beam.smp プロセスについて のキャプチャを見ると
- scheduler が 4 つ
- dirty_cpu_scheduler が 4 つ
- dirty_io_scheduler が 10 つ
存在することが分かります。これは事実。
で、BEAM 上のプロセスは並行に処理されるようよしなに scheduler によって管理され実行されているはずです。これは想像。
では、BEAM に動的にリンクされる NIF はどうでしょうか?
https://www.erlang.org/doc/man/erl_nif の Long-running NIFs に以下の記載があります。
As mentioned in the warning text at the beginning of this manual page, it is of vital importance that a native function returns relatively fast. It is difficult to give an exact maximum amount of time that a native function is allowed to work, but usually a well-behaving native function is to return to its caller within 1 millisecond.
想像ですが、通常の scheduler からは NIF の動作のスケジューリングはできないので、NIF の処理はできる限り早く終わらせろと言っているのだと思います。
そして、そうはいってもすぐに終わらせられない NIF の処理というのは存在するので、そのために Dirty NIF scheduler がその特性に合わせて CPUバウンド と IOバウンド の二種が用意されているのだと思います。
within 1 millisecond の記載がありますが、大事なのは 1 ミリという時間ではなく(だって CPU によるだろうし)、計算処理の多い NIF や IO 待ちが発生するような NIF は Dirty NIF として扱うべき場面があるということだと思います。
私の経験として、実際に Rclex の NIF のリライトにおいて ERL_NIF_DIRTY_JOB_IO_BOUND を設定せずに実装を進め、テストを回していた際にテストの実行時間が実行毎で安定しないことがありました。
https://www.erlang.org/doc/man/erl_nif の Dirty NIF の節に記載のある以下のようなことが起こったのかなと想像します。
While a process executes a dirty NIF, some operations that communicate with it can take a very long time to complete. Suspend or garbage collection of a process executing a dirty NIF cannot be done until the dirty NIF has returned. Thus, other processes waiting for such operations to complete might have to wait for a very long time. Blocking multi-scheduling, that is, calling erlang:system_flag(multi_scheduling, block), can also take a very long time to complete. This is because all ongoing dirty operations on all dirty schedulers must complete before the block operation can complete.
これは、結果論ですが、ERL_NIF_DIRTY_JOB_IO_BOUNDを設定することでその現象は発生しなくなりました。
(rcl はネットワーク処理をするので IO_BOUND を設定しました)
Rclex は、 Rclex から見ると 3rd party である rcl ライブラリを NIF 内で呼び出します。処理時間がどのようにかかるかの計測はできますが(実際benceeスクリプトを書いて処理時間の計測をしています)、 rcl のバージョンアップでそれがどのように変わるかは想定できません。なので Rclex では rcl を呼び出す部分は ERL_NIF_DIRTY_JOB_IO_BOUND を設定するようにしています。(大雑把ではありますが、それが現状です)
まとめ
ここまで、NIF を書いた際のいろいろをつらつらと書いてみました。
参考になるかは、分かりませんがどこか一部でも読んでくださった方のどこかに引っかかるものがあれば嬉しいです。
もう今年も残すところ一ヶ月です。健康に気をつけて楽しい年の瀬を過ごしましょう!!
明日は、じゃかじゃん、 @MickeyOoh の記事がでます。お楽しみに!!