この記事は自作している強化学習フレームワークの解説記事です。
この記事のコード場所:examples/distribution
1:ここ
2:【強化学習】クラウドサービスを利用した分散強化学習(kubernetes編)
3:【強化学習】クラウドサービスを利用した分散強化学習(GKE/有料編)
はじめに
今回フレームワークにネットワーク経由の分散強化学習の仕組みを導入したのでそれについての記事となります。
分散強化学習自体の話は以前の記事を参照してください。
基本はApe-Xのアーキテクチャを採用しています。
以下採用までのちょっとした独り言
- IMPALAとの違いはLearner(Trainer)の数だけだと思っています。VTraceはアルゴリズム側の話になると思うので…
- Learnerが複数いる場合(GPUが複数ある場合)のニューラルネットの重みの取り扱いはまだ実装までこぎつけていません…。Tensorflow/Torch側に任せたいのですがなかなか…
- SEED RLは多分Actorが3桁とか大規模にならないと意味がないかと思って見送っています
- と言っても常に最新のParameterが使えるのは魅力です…
アーキテクチャ
ActorとTrainerの動きは以下です。
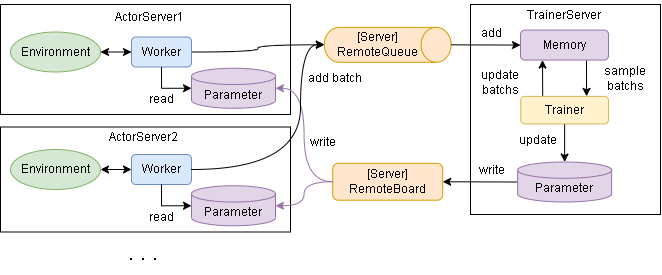
Actorは以下の役割があります。
- 環境を実際に動かし、経験(batch)を得る
- batchをQueueに渡す
- 更新されたParameterを受け取る
Trainerは以下の役割があります。
- batchを受け取って学習する
- Parameterを更新する
また、追加で学習自体の管理が必要になります。
ここをどういう形にしようか悩みましたが、ブラックボードアーキテクチャを採用し、学習をタスクという単位で管理しました。
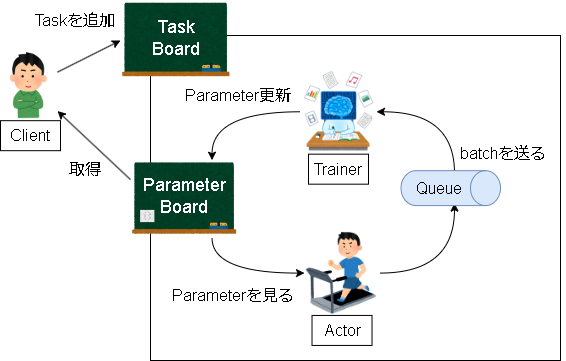
概念としては分けていますが、実装上はTaskBoardとParameterBoardは同じ扱いです。
黒板に書かれている内容は以下です。
- 学習の進行状況
- Actor/Trainerのアサイン状況
- 最新Parameter
それぞれ黒板に対して実施する操作は以下です。
- Actor
- Actorのアサイン状況を見て、なかったら自分をアサインする
- アサインしたら学習を開始し、Queueへ経験を送り続ける
- 定期的に黒板のParameterを見て自分のParameterを更新する
- Trainer
- Trainerのアサイン状況を見て、なかったら自分をアサインする
- アサインしたら学習を開始、Queueから経験を取り出す
- 定期的に黒板のParameterを更新する
- 学習が終わったら黒板に終わったと書く
- Client
- 黒板に新規のタスクを書く
- タスクが終わるまで待つ
具体的な仕組み
BoardにはRedisを採用しました。
Queueは選択できるようにしてあり、Redis,RabbitMQ,MQTT,GCP PubSubのコードを今のところ実装してあります。
課題ですが、ネットワーク経由でデータをやり取りするので速度の問題が出てきます。
Parameterは更新されなくてもActor/Trainer共に学習は進むので大きな問題にはなりませんが、Queueが遅いと学習に影響が出てきます。
一応コード上は以下の工夫をしています。
- 制約を設けてQueueが一定数以上溜まったらActor側はQueueが空くまで待つように待機処理をする
- サーバとのやりとりと本来の処理(Trainerなら学習、Actorなら経験収集)は非同期に行って互いにブロッキングしないように
- 後は死活監視も…
ローカル環境での実行例
まずはローカル環境での実行例を見ていきます。
1. Redisサーバの構築
Redisサーバを任意の場所に作成してください。
疎通性があれば別PCでも可能です。
コンテナでの立ち上げ例は以下です。
-
DockerDesktopがない場合は以下からインストールします。
https://www.docker.com/products/docker-desktop/ -
以下の docker-compose.yaml 作成します。
version: "3.9"
services:
redis:
image: redis:7.2-alpine
ports:
- 6379:6379
command: redis-server
redis-commander:
image: rediscommander/redis-commander:latest
environment:
- REDIS_HOSTS=local:redis:6379
ports:
- "8081:8081"
- 以下でコンテナを起動します。
> docker-compose -f docker-compose.yaml up -d
# 終了する場合
> docker-compose -f docker-compose.yaml down
起動に成功すると以下から管理画面にアクセスできます。
http://localhost:8081/
2. Actor/Trainerの起動
次にActorとTrainerを起動します。次のpythonファイルを実行します。
Actorはactor_num数起動する必要があります。
# Actor起動例
from srl.runner.distribution import RedisParameters, actor_run_forever
actor_run_forever(RedisParameters(host="localhost"), None)
# Trainer起動例
from srl.runner.distribution import RedisParameters, trainer_run_forever
trainer_run_forever(RedisParameters(host="localhost"), None)
3. 学習
最後にClientの実行です。"Pendulum-v1" を学習させてみます。
import srl
from srl.algorithms import dqn
from srl.runner.distribution import RedisParameters
rl_config = dqn.Config()
rl_config.hidden_block.set_mlp((64, 64))
rl_config.memory.set_proportional_memory()
rl_config.memory.capacity = 5000
runner = srl.Runner("Pendulum-v1", rl_config)
# 分散学習を実施
runner.train_distribution(
RedisParameters(host="localhost"),
actor_num=1,
max_train_count=20_000,
)
print(runner.evaluate())
実行結果です。
実行環境
CPUx1: Core i9-12900 2.4GHz
GPUx1: NVIDIA GeForce RTX 3060 12GB
memory 32GB
# --- Trainer
### env: Pendulum-v1, rl: DQN:tensorflow, max train: 20000
18:00:41 trainer: 1.00s( - left), 0tr/s, 0tr, 0mem, Q 0recv/s( 0), 0 send Param 1train is not over.
18:00:46 trainer: 6.00s( 7.4m left), 44tr/s, 223tr, 2814mem, Q 559recv/s( 2799), 5 send Param|loss 0.118|sync 1|lr 0.001
18:00:56 trainer: 16.01s( 4.5m left), 69tr/s, 923tr, 5000mem, Q 579recv/s( 8596), 15 send Param|loss 0.213|sync 1|lr 0.001
18:01:16 trainer: 36.02s( 4.4m left), 66tr/s, 2255tr, 5000mem, Q 583recv/s( 20259), 34 send Param|loss 0.106|sync 3|lr 0.001
18:01:56 trainer: 1.3m( 3.9m left), 64tr/s, 4844tr, 5000mem, Q 575recv/s( 43292), 72 send Param|loss 0.279|sync 5|lr 0.001
18:03:16 trainer: 2.6m( 2.6m left), 64tr/s, 9993tr, 5000mem, Q 570recv/s( 88902), 148 send Param|loss 0.162|sync 10|lr 0.001
18:05:45 trainer: 5.1m( 0.00s left), 66tr/s, 20000tr, 5000mem, Q 560recv/s( 172954), 290 send Param|loss 0.682|sync 20|lr 0.001
# --- Actor
### env: Pendulum-v1, rl: DQN:tensorflow, max train: 20000
18:00:42 actor 0: 1.00s( - left), 628st/s, 629st, 590mem, Q 588send/s( 589), 0 recv Param, 3ep, 200st,-1619.9 -1550.4 -1481.4 re|epsilon 0.100
18:00:47 actor 0: 6.00s( - left), 585st/s, 3558st, 3517mem, Q 584send/s( 3515), 5 recv Param, 17ep, 200st,-1852.0 -1554.6 -1184.7 re|epsilon 0.100
18:00:57 actor 0: 16.00s( - left), 581st/s, 9374st, 9335mem, Q 581send/s( 9334), 15 recv Param, 46ep, 200st,-1639.9 -1402.1 -833.7 re|epsilon 0.100
18:01:17 actor 0: 36.00s( - left), 584st/s, 21064st, 21033mem, Q 584send/s( 21032), 35 recv Param, 105ep, 200st,-1740.1 -1418.4 -1019.2 re|epsilon 0.100
18:01:57 actor 0: 1.3m( - left), 576st/s, 44121st, 44065mem, Q 575send/s( 44064), 75 recv Param, 220ep, 200st,-1852.6 -1392.8 -11.0 re|epsilon 0.100
18:03:17 actor 0: 2.6m( - left), 569st/s, 89693st, 89638mem, Q 569send/s( 89638), 154 recv Param, 448ep, 200st,-1783.0 -945.0 -1.303 re|epsilon 0.100
18:05:54 actor 0: 5.2m( - left), 536st/s, 173963st,173461mem, Q 533send/s( 173461), 310 recv Param, 869ep, 200st,-1092.2 -315.6 -0.491 re|epsilon 0.100
# --- Client
18:00:40 ACTIVE 1.00s( - left), 0tr (-1562.1eval)
trainer a90e08e3-5118-47d2-bc7e-43ea99490c3f 0.4s: 0tr/s, 0recv/s, tr, 0recv
actor0 not assigned
18:01:40 ACTIVE 1.0m( 4.9m left), 3380tr (-1376.7eval)
trainer a90e08e3-5118-47d2-bc7e-43ea99490c3f 7.9s: 55tr/s, 554recv/s, 3380tr, 33508recv
actor0 df0f2f25-63cf-4f19-a140-39d10efdb1f2 9.9s: 486st/s, 486send/s, 29385st, 29382send
18:02:40 ACTIVE 2.0m( 3.1m left), 7457tr (-1491.7eval)
trainer a90e08e3-5118-47d2-bc7e-43ea99490c3f 5.4s: 67tr/s, 576recv/s, 7457tr, 68358recv
actor0 df0f2f25-63cf-4f19-a140-39d10efdb1f2 9.4s: 581st/s, 580send/s, 64531st, 64512send
18:03:41 ACTIVE 3.0m( 2.1m left), 11569tr (-262.7eval)
trainer a90e08e3-5118-47d2-bc7e-43ea99490c3f 2.9s: 67tr/s, 580recv/s, 11569tr, 103492recv
actor0 df0f2f25-63cf-4f19-a140-39d10efdb1f2 9.9s: 563st/s, 563send/s, 98674st, 98634send
18:04:42 ACTIVE 4.0m( 1.5m left), 14973tr (-9.635eval)
trainer a90e08e3-5118-47d2-bc7e-43ea99490c3f 10.3s: 56tr/s, 549recv/s, 14973tr, 136746recv
actor0 df0f2f25-63cf-4f19-a140-39d10efdb1f2 9.3s: 547st/s, 547send/s, 131782st, 131776send
18:05:42 ACTIVE 5.1m( 8.81s left), 19360tr (-141.0eval)
trainer a90e08e3-5118-47d2-bc7e-43ea99490c3f 7.9s: 72tr/s, 564recv/s, 19360tr, 170858recv
actor0 df0f2f25-63cf-4f19-a140-39d10efdb1f2 9.9s: 571st/s, 571send/s, 166327st, 166305send
18:05:46 END 5.1m( 0.00s left), 20000tr (-136.7eval)
trainer a90e08e3-5118-47d2-bc7e-43ea99490c3f 1.1s: 144tr/s, 473recv/s, 20000tr, 172961recv
actor0 df0f2f25-63cf-4f19-a140-39d10efdb1f2 4.1s: 1247st/s, 1245send/s, 171866st, 171835send
[-140.08821872249246, -138.74584086984396, -19.72735545784235, -258.0985731333494, -136.9397254474461, -143.05875950306654, -135.35882010310888, -143.97810783982277, -138.72171898186207, -139.25637593492866]
Pendulumは学習できていないと -1500 ぐらい、学習できていると -300 ぐらいになります。
ちゃんと学習できていますね。
Redisのデータ設計
Redisのデータ設計は以下のような感じです。
task
├ actor
| ├ 0
| | ├ id : 識別用の固有値
| | ├ update_time : 死活監視用の値
| | ├ q_send_count : 経験送信回数
| | └ その他、情報
| |
| ├ 1
| ...
|
├ trainer
| ├ id : 識別用の固有値
| ├ update_time : 死活監視用の値
| ├ q_recv_count : 経験受信回数
| └ その他、情報
|
├ raw
| ├ config : 学習用の設定(binary)
| ├ parameter : parameter(binary)
| └ mq : MQ用
|
├ status : Taskの状態
├ create_time : 死活監視用の値
├ actor_num : Actor数
├ train_count : 学習回数
└ その他、情報
フレームワークの更新によって変わるかもしれませんがこんな感じです。
最初はタスクにもIDを付けて管理をしていましたが、複数のタスクを並列で実行することはないと思い止めました。
なので1度に学習できるタスクは1つです。
クラウドサービス(無料枠)での実行例
使うサービスは以下です。
とりあえず検索して上位に来たフリーサービスを使ってみました。
| role | Service | Link | 登録内容 | プラン |
|---|---|---|---|---|
| Redis | Aiven for Redis | https://aiven.io/ja/redis | メールアドレスのみ | 無料プランの機能と制限 |
| MQ | CloudAMQP | https://www.cloudamqp.com/ | メールアドレスのみ | Plans & Pricing |
| Trainer | Google Colaboratory | https://colab.research.google.com/?hl=ja | Googleサービス | よくある質問 |
| Actor | LocalPC | なし | 自分のPC | |
| Client | LocalPC | なし | 自分のPC |
Aivenの無料プランはRedisへの読み書きに特に制限はないようで問題はなさそうです。
CloudAMQPの無料枠はメッセージ回数に制限があります。(1M Max MSGs/month)
強化学習の性質上メッセージを頻繁に送受信するので月1_000_000回は少し気になる内容です。
一応Aivenサービスだけでも実行はできます。
ただメッセージの転送速度が遅すぎて…、ちょっと学習は難しいかもしれません。(Memoryがほぼ更新されなくなるので学習ばかり進み、オフライン強化学習みたいな学習になります)
各サービスで特に難しい設定はなかったので登録方法は省略します。
以下実行コードの例です。
・Google Colab の実行コード例
# srlをインストール
!git clone -b v0.13.3 https://github.com/pocokhc/simple_distributed_rl.git
%cd simple_distributed_rl
!pip install .
# 足りないライブラリを追加
!pip install gymnasium redis pika
# --- Trainerの実行
from srl.runner.distribution import trainer_run_forever, RedisParameters, RabbitMQParameters
trainer_run_forever(
RedisParameters(url="{rediss://RedisService_URI}"),
RabbitMQParameters(url="{amqps://RabbitMQ_URI}"),
run_once=True, # 1回で終わらす
)
・ローカル環境でのActorの実行コード例
from srl.runner.distribution import actor_run_forever, RedisParameters, RabbitMQParameters
actor_run_forever(
RedisParameters(url="{rediss://RedisService_URI}"),
RabbitMQParameters(url="{amqps://RabbitMQ_URI}"),
)
・Clientの実行コード例
import srl
from srl.algorithms import dqn
from srl.runner.distribution import RedisParameters
rl_config = dqn.Config()
rl_config.hidden_block.set_mlp((64, 64))
rl_config.memory.set_proportional_memory()
rl_config.memory.capacity = 5000
runner = srl.Runner("Pendulum-v1", rl_config)
# 分散学習を実施
runner.train_distribution(
RedisParameters(url="{rediss://RedisService_URI}"),
actor_num=1,
max_train_count=20_000,
)
print(runner.evaluate())
実行結果です。
Redisのリージョン: ap-south-1
RabbitMQのリージョン: ap-northeast
# --- Google Colab のスペック(ランタイムタイプはT4 GPUを選択しています)
!cat /proc/cpuinfo | grep "model name"
model name : Intel(R) Xeon(R) CPU @ 2.00GHz
!python -c "from tensorflow.python.client import device_lib; print(device_lib.list_local_devices())"
physical_device_desc: "device: 0, name: Tesla T4, pci bus id: 0000:00:04.0, compute capability: 7.5"
# --- Trainer
### env: Pendulum-v1, rl: DQN:tensorflow, max train: 20000
09:11:38 trainer: 1.00s( - left), 0tr/s, 0tr, 0mem, Q 0recv/s( 0), 0 send Param 1train is not over.
09:11:43 trainer: 6.01s( - left), 0tr/s, 0tr, 30mem, Q 5recv/s( 30), 4 send Param 1train is not over.
09:11:53 trainer: 16.02s( - left), 0tr/s, 0tr, 167mem, Q 13recv/s( 167), 12 send Param 1train is not over.
09:12:13 trainer: 36.04s( - left), 0tr/s, 0tr, 440mem, Q 13recv/s( 440), 29 send Param 1train is not over.
09:12:53 trainer: 1.3m( - left), 0tr/s, 0tr, 984mem, Q 13recv/s( 984), 63 send Param 1train is not over.
09:14:13 trainer: 2.6m( 7.0m left), 39tr/s, 3195tr, 2063mem, Q 13recv/s( 2063), 129 send Param|loss 0.195|sync 4|lr 0.001
09:16:53 trainer: 5.3m( 3.7m left), 44tr/s, 10256tr, 4227mem, Q 13recv/s( 4227), 261 send Param|loss 0.119|sync 11|lr 0.001
09:20:38 trainer: 9.0m( 0.00s left), 43tr/s, 20000tr, 5000mem, Q 13recv/s( 7296), 448 send Param|loss 2.109|sync 20|lr 0.001
# --- Actor(local PC)
### env: Pendulum-v1, rl: DQN:tensorflow, max train: 20000
18:11:45 actor 0: 1.71s( - left), 298st/s, 510st, 57mem, Q 4send/s( 8), 0 recv Param, 2ep, 200st,-1370.7 -1369.1 -1367.4 re|epsilon 0.100
18:11:50 actor 0: 7.07s( - left), 48st/s, 772st, 319mem, Q 48send/s( 270), 3 recv Param, 3ep, 200st,-1360.0 -1360.0 -1360.0 re|epsilon 0.100
18:12:01 actor 0: 17.70s( - left), 41st/s, 1216st, 734mem, Q 41send/s( 714), 10 recv Param, 6ep, 200st,-1517.6 -1403.9 -1324.3 re|epsilon 0.100
18:12:21 actor 0: 38.09s( - left), 13st/s, 1492st, 1009mem, Q 13send/s( 990), 23 recv Param, 7ep, 200st,-1367.1 -1367.1 -1367.1 re|epsilon 0.100
18:13:02 actor 0: 1.3m( - left), 13st/s, 2050st, 1567mem, Q 13send/s( 1548), 49 recv Param, 10ep, 200st,-1367.9 -1348.4 -1310.8 re|epsilon 0.100
18:14:22 actor 0: 2.7m( - left), 13st/s, 3134st, 2644mem, Q 13send/s( 2632), 102 recv Param, 15ep, 200st,-1562.5 -1220.2 -818.2 re|epsilon 0.100
18:17:04 actor 0: 5.3m( - left), 13st/s, 5308st, 4825mem, Q 13send/s( 4806), 206 recv Param, 26ep, 200st,-1603.8 -1135.8 -515.2 re|epsilon 0.100
18:20:43 actor 0: 9.0m( - left), 13st/s, 8304st, 7805mem, Q 13send/s( 7805), 350 recv Param, 41ep, 200st,-515.6 -261.8 -1.948 re|epsilon 0.100
# --- Client
18:11:38 ACTIVE 1.55s( - left), 0tr (-1489.5eval)
trainer not assigned
actor0 not assigned
18:12:39 ACTIVE 1.0m( - left), 0tr (-1485.3eval)
trainer 91498428-f658-4150-800f-71dd73d91bc7 7.8s: 0tr/s, 12recv/s, 0tr, 756recv
actor0 6e135fef-c436-4dd8-ba5d-6cda67ef4a18 1.8s: 28st/s, 20send/s, 1724st, 1231send
18:13:40 ACTIVE 2.1m( 16.8m left), 1146tr (-503.8eval)
trainer 91498428-f658-4150-800f-71dd73d91bc7 4.0s: 18tr/s, 13recv/s, 1631tr, 1586recv
actor0 6e135fef-c436-4dd8-ba5d-6cda67ef4a18 9.0s: 11st/s, 11send/s, 2453st, 1952send
18:14:41 ACTIVE 3.1m( 5.7m left), 4026tr (-1013.7eval)
trainer 91498428-f658-4150-800f-71dd73d91bc7 10.4s: 47tr/s, 13recv/s, 4026tr, 2420recv
actor0 6e135fef-c436-4dd8-ba5d-6cda67ef4a18 6.4s: 14st/s, 14send/s, 3332st, 2832send
18:15:43 ACTIVE 4.1m( 4.6m left), 6931tr (-1380.5eval)
trainer 91498428-f658-4150-800f-71dd73d91bc7 6.6s: 47tr/s, 13recv/s, 6931tr, 3240recv
actor0 6e135fef-c436-4dd8-ba5d-6cda67ef4a18 2.6s: 14st/s, 14send/s, 4202st, 3701send
18:16:44 ACTIVE 5.1m( 4.6m left), 9308tr (-133.0eval)
trainer 91498428-f658-4150-800f-71dd73d91bc7 13.9s: 38tr/s, 13recv/s, 9308tr, 4066recv
actor0 6e135fef-c436-4dd8-ba5d-6cda67ef4a18 10.9s: 13st/s, 14send/s, 5059st, 4574send
18:17:45 ACTIVE 6.1m( 2.8m left), 12156tr (-754.9eval)
trainer 91498428-f658-4150-800f-71dd73d91bc7 10.5s: 46tr/s, 13recv/s, 12156tr, 4900recv
actor0 6e135fef-c436-4dd8-ba5d-6cda67ef4a18 7.5s: 12st/s, 11send/s, 5799st, 5305send
18:18:45 ACTIVE 7.1m( 1.8m left), 14962tr (-249.9eval)
trainer 91498428-f658-4150-800f-71dd73d91bc7 4.4s: 46tr/s, 13recv/s, 14962tr, 5727recv
actor0 6e135fef-c436-4dd8-ba5d-6cda67ef4a18 3.4s: 14st/s, 14send/s, 6676st, 6179send
18:19:47 ACTIVE 8.2m( 1.2m left), 17329tr (-125.6eval)
trainer 91498428-f658-4150-800f-71dd73d91bc7 11.7s: 38tr/s, 13recv/s, 17329tr, 6545recv
actor0 6e135fef-c436-4dd8-ba5d-6cda67ef4a18 10.7s: 14st/s, 14send/s, 7551st, 7050send
18:20:42 END 9.1m( 0.00s left), 20000tr (-124.4eval)
trainer 91498428-f658-4150-800f-71dd73d91bc7 4.6s: 47tr/s, 13recv/s, 20000tr, 7304recv
actor0 6e135fef-c436-4dd8-ba5d-6cda67ef4a18 1.6s: 13st/s, 13send/s, 8303st, 7802send
[-233.55487579695182, -117.99547059219913, -1.1689260317070875, -124.46434442827012, -2.021443920501042, -250.50689019204583, -126.15856504357362, -131.82061177663854, -229.98156812184607, -127.53283957118401]
リージョンが離れているので仕方ないですが、batchのやりとりに時間がかかっています。
ちなみにCloudAMQPですが、この学習でメッセージ回数は15109回(無料制限の約1.5%ほど)増えていました。
長くなったので記事を分けます。
次:【強化学習】クラウドサービスを利用した分散強化学習(kubernetes編)