この記事は自作している強化学習フレームワーク SimpleDistributedRL の解説記事です。
フレームワークのタイトルにも入れている分散強化学習についての解説です。
はじめに
プログラムを並列処理させて早くしようというのはよくある話で、それを強化学習にも応用しようというのは自然な流れです。
ただ、強化学習では学習したパラメータを元にアクションを決めるので単純に並列処理させることはできません。
分散強化学習の流れとして、GORILA・A3C・Ape-Xのアーキテクチャを紹介し、最後に本フレームワークのアーキテクチャを紹介します。
GORILA(General Reinforcement Learning Architecture)
論文:Massively Parallel Methods for Deep Reinforcement Learning
GORILLAではないので注意です(笑)
(Oの位置がおかしいあたり名前で遊んでますねw)
分散強化学習を実装して成果をだした論文としては多分初出です。
提案されたアーキテクチャは以下です。
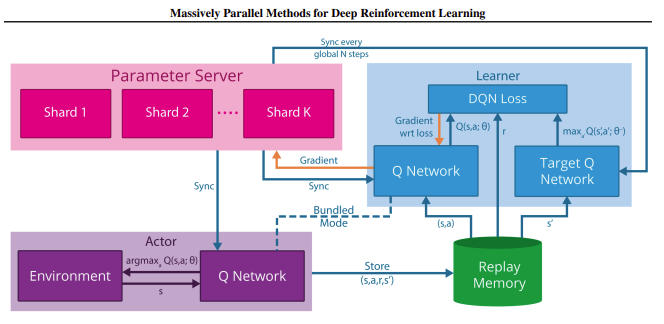
各役割を箇条書きします。
- Actor
- Actorは複数インスタンス化され、それぞれが独自の環境を持つ
- 各Actorは環境から経験を取得し、メモリ(ReplayMemory)に経験を送る
- 定期的にパラメータサーバからQ-Networkのパラメータを同期
- ReplayMemory
- 2種類の形態が考えられる
- 1、Actor毎にローカルにメモリを持つ方法(Actor数分メモリが出来る)
- 2、グローバルメモリを1つ持つ方法(通信のオーバーヘッドがかかるデメリットあり)
- Learner
- Learnerは複数インスタンス化される
- 各Learnerはローカルメモリー又はグローバルメモリからミニバッチを取得し、勾配をパラメータサーバに送る
- 定期的にパラメータサーバからQ-Networkのパラメータを同期
- Parameter server
- 非同期確率的勾配降下アルゴリズム(ASGD: asynchronous stochastic gradient descent algorithm)で更新
- 各マシンでパラメータを保持し、各マシンで勾配を元にパラメータを更新
参考
・averaged stochastic gradient descentのご紹介
本記事用に調べたのですが、Actor/Learner/Parameter 3つとも並列処理ができる構成だったんですね…
拡張性はすごいけど実装が大変そう…
A3C
論文:Asynchronous Methods for Deep Reinforcement Learning
アーキテクチャのみ取り上げます。A3C/A2Cは別の記事を上げる予定です。
A3Cは基本 GORILA と同じですが、以下の変更点があります。
- パラメータサーバとLearner達を同じマシン(1台)の複数CPUに変更
- これによりHogwild!(※1)という高速化手法が使える
- 通信のオーバーヘッドもなくなる
- ActorとLearnerは1対1で対応し、それぞれが学習サイクルを回し、共有パラメータ(パラメータサーバ)を更新する
- ReplayMemoryを廃止
- 複数Actorがいるので環境の探索範囲が広くて多彩
- それぞれのActorは異なる探索ポリシーを持つことができる
- これにより複数のActorによる経験の取得が、ReplayMemoryの代わりになる
- ReplayMemoryの廃止によりOn-policy(学習の方策と経験を収集する方策が同じ)なアルゴリズムにも適用できる
(簡単に言うと、価値ベースと方策ベース両方のアルゴリズムに適用できる)
(そのままだとReplayMemoryは方策ベースのアルゴリズムでは使えない) - 実際の更新は複数経験をためてミニバッチ形式にして更新する
(これにより各Actor-Learner間による共有パラメータの上書き確率を下げる)
- ReplayMemoryを廃止
※1、確率的勾配降下法(SGD)の並列処理改善による高速化手法らしいです。
参考
・HOGWILD! 論文要約
・HOGWILD!: A Lock-Free Approach to Parallelizing Stochastic Gradient Descent(論文)
Ape-X
論文:Distributed Prioritized Experience Replay(論文)
Rainbowでも成果を見せた Prioritized Experience Replay(優先度付き経験再生)を分散強化学習で実現した論文となります。
(GORILA,A3Cの流れも含まれています)
提案されたアーキテクチャは以下です。
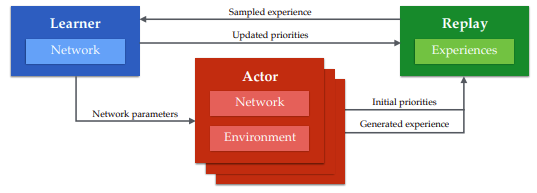
- Actor
- GORILAと同じで環境から経験を取得しメモリに送信
- 複数インスタンス、各Actorに1CPUが割り当てられる
- Learner
- メモリからミニバッチを取得しパラメータを更新
- 1Learner
- 1GPU
- Replay(メモリ)
- 1メモリ(優先度を計算する必要があるため)
大きな違いはメモリと共有パラメータ(とLearner)が1つになったことでしょう。
メモリは優先順位を付けるために1カ所にまとめています。
GORILAではLearnerは勾配のみを計算し、共有パラメータへの反映はパラメータサーバが行っています。
ですので、Learner側のミニバッチ計算とパラメータへの反映が並列で実行可能でした。
Ape-XではここをまとめてLearnerで処理するようにしています。
ここの利点が論文から正確に読み取れた自信がないのですが、勾配はすぐ古くなるのに対し、経験はすぐには古いデータにならないので、システム全体を見ると多少の待ち時間を犠牲にしてもバッチ処理を優先させ、学習効率とスループットを高めているとの事です。
Priorityの計算
Rainbow の Prioritized Experience Replay ではメモリに経験を入れる時、必ず使われるように優先度を一番高くして追加していました。
しかし、分散学習では大量に経験が来て新しい経験だらけになってしまいます。
そこで追加する前にActor側で優先度を計算して追加するように変更しています。
SimpleDistributedRL
本フレームワークでの実装です。
基本はApe-Xと同じです。
より実装に向けた具体的なアーキテクチャになっています。
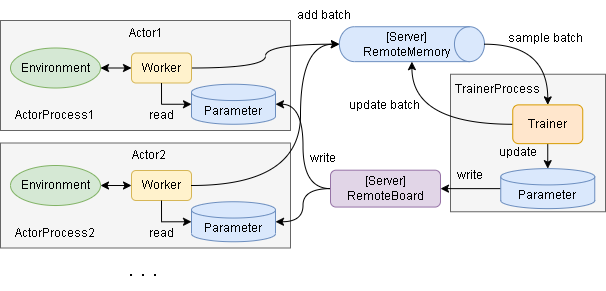
基本的な構成は以下です。
- Actor
- 複数インスタンス作成でき、インスタンス毎にCPUが割り当て可能
- 各Actorは独立で動き、非同期でメモリにバッチを送信
- Boardを見て、もしパラメータが更新されていたら自分のパラメータを更新する
- Trainer(Learner)
- 1Trainer(GPUに割り当て可能)
- メモリからミニバッチを取得し、ひたすら学習する
- 定期的にBoardにパラメータを書き込む
- RemoteMemory
- サーバとして実装
- バッチの受信とミニバッチの送信は非同期に実施
- RemoteBoard
- サーバとして実装
- Blackboardアーキテクチャパターンがベースです(※2)
- 書き込みは非同期に実行
※2:方向が逆なので厳密な意味としてはPub/Subを採用したほうが良さそうですが、素直に実装できたので採用しています
最初はキュー等を色々試していたのですが、RemoteMemory/RemoteBoardとのやりとりで待ち(非同期処理のロック等)が発生するとどうしても都合が悪く、この形になりました。
(例えばキューだとput中にgetはできずにputが終わるまで待ちが発生する)
また、この形はpythonだと multiprocessing.Manager で簡単に実装ができたのも大きいです。
また、まだ試していませんが、Manager はサーバプロセスとしての非同期も実現しているので、別PCからネットワーク経由でもアクセス可能との事です。
なのでこの構成のまま、各ActorとTrainerを別PCで学習する事も可能です(フレームワーク上はまだ実装していません)
実装
フレームワーク上の実装はこちら、分散処理のみを書いた最小コードのサンプルはこちらです。
記事のコードはメインロジックのみでそれ以外の細かいところ(例外処理等)は省略しています。
RemoteBoard
実装自体は簡単で以下2つです。
1、Trainerからもらったパラメータを保存
2、更新があるかどうかを知らせる(Actor側の実装もあり)
2はActor側にも実装が含まれてしまっているので完全に分離はできていません…
class Board:
def __init__(self):
self.params = None
self.update_count = 0
def write(self, params):
self.params = params
self.update_count += 1
def get_update_count(self):
return self.update_count
def read(self):
return self.params
get_update_count はActor側で更新があるかどうか判定する時に使います。
各Actorがそれぞれ判定する必要があるので回数を数える実装になっています。
RemoteMemory
中身の実装に指定はありません。
注意点としてはManagerでサーバプロセス化するので関数しか使えなくなる点です。
(なので length も __len__ の実装ではなく関数で実装)
例として ExperienceReplayBuffer の実装だと以下です。
import random
from collections import deque
class RemoteMemory():
def __init__(self, capacity):
self.buffer = deque(maxlen=capacity)
def length(self) -> int:
return len(self.buffer)
def add(self, batch: Any) -> None:
self.buffer.append(batch)
def sample(self, batch_size: int):
return random.sample(self.memory, batch_size)
Actor
multiprocessing でプロセス化をするので関数で実装します。
def _run_actor(remote_memory, remote_board):
# remote_memoryとremote_board はサーバプロセス化後のインスタンスが入っています
env = Envを作成
parameter = Parameterを作成
worker = Workerを作成(parameter と remote_memory を使用)
prev_update_count = 0
# episode loop
while True:
env.reset()
worker.on_reset(env)
# 1 episode
while not env.done:
# 1step
# この中でWorkerは remote_memory に経験を送る(非同期)
action = worker.policy(env)
env.step(action)
worker.on_step(env)
# remote_board で更新があるか確認
# 更新回数が前回より増えていれば更新ありとする
update_count = remote_board.get_update_count()
if update_count != prev_update_count:
# parameterを更新(非同期)
prev_update_count = update_count
params = remote_board.read()
if params is not None:
parameter.restore(params)
Trainer
Worker/Trainerという単語は論文ではなくRLlibからきていたり…。
同じくmultiprocessingでプロセス化をするので関数で実装しています。
def _run_trainer(remote_memory, remote_board):
# remote_memoryとremote_board はサーバプロセス化後のインスタンスが入っています
parameter = Parameterを作成
trainer = Trainerを作成(parameter と remote_memory を使用)
# ハイパーパラメータ(学習を送る間隔)
send_interval_by_train_count = 100
train_count = 0
# 無限ループ
while True:
# 仮で10000回学習したら終了とする
if train_count > 10000:
break
# 学習
# この中で、remote_memory からミニバッチを取得(非同期)
trainer.train()
train_count += 1
# 一定学習毎に Board にパラメータを送る(非同期)
if train_count % send_interval_by_train_count == 0:
remote_board.write(parameter.backup())
# 最後に学習結果を送信
remote_board.write(parameter.backup())
main
上で定義したもろもろをmultiprocessingで動かします。
import multiprocessing as mp
from multiprocessing.managers import BaseManager
# Managerクラスを作成
class MPManager(BaseManager):
pass
def main():
# actor数
actor_num = 2
# Manager登録
MPManager.register("RemoteMemory", RemoteMemory)
MPManager.register("Board", Board)
# Managerプロセスを起動
with MPManager() as manager:
# --- サーバプロセス作成
remote_memory = manager.RemoteMemory()
remote_board = manager.Board()
# --- actor プロセス作成
actors_ps_list = []
for actor_id in range(actor_num):
params = (remote_memory, remote_board)
ps = mp.Process(target=_run_actor, args=params)
actors_ps_list.append(ps)
# --- trainer プロセス作成
params = (remote_memory, remote_board)
trainer_ps = mp.Process(target=_run_trainer, args=params)
# --- 各プロセスの並列実行を開始
[p.start() for p in actors_ps_list]
trainer_ps.start()
# trainerプロセスが終わるまで待つ
trainer_ps.join()
# 学習後の結果を受け取る、remote_boardから最後のパラメータを取得する
parameter = Parameterを作成
params = remote_board.read()
parameter.restore(params)
ハイパーパラメータ
フレームワーク上のハイパーパラメータです。
@dataclass
class Config:
# actor数です。
actor_num: int = 1
# TrainerがBoardにパラメータを書き込む間隔(学習回数)
trainer_parameter_send_interval_by_train_count: int = 100
# ActorがBoardに確認しに行く間隔(step数)
actor_parameter_sync_interval_by_step: int = 100
# 各プロセスのCPU/GPU割り当て
allocate_main: str = "/CPU:0"
allocate_trainer: str = "/GPU:0"
allocate_actor: Union[List[str], str] = "/CPU:0"
multiprocessing による実行の注意点
メイン関数は if __name__ == '__main__': の中に記述しないといけないようで、グローバルに記述すると以下のエラーがでました。
RuntimeError:
An attempt has been made to start a new process before the
current process has finished its bootstrapping phase.
This probably means that you are not using fork to start your
child processes and you have forgotten to use the proper idiom
in the main module:
if __name__ == '__main__':
freeze_support()
...
The "freeze_support()" line can be omitted if the program
is not going to be frozen to produce an executable.
if __name__ == '__main__':の中で実行しましょう。
実行/比較
分散学習しない場合とする場合で比較してみました。
アルゴリズムはDQNです。
import matplotlib.pyplot as plt
import numpy as np
import srl
from srl import runner
# --- env & algorithm load
import gym # isort: skip # noqa F401
from srl.algorithms import dqn # isort: skip
def main():
env_config = srl.EnvConfig("Pendulum-v1")
rl_config = dqn.Config(hidden_block_kwargs=dict(hidden_layer_sizes=(64, 64)))
config = runner.Config(env_config, rl_config)
# --- train
parameter, remote_memory, history1 = runner.train(
config,
timeout=60 * 10,
enable_evaluation=False,
)
rewards = runner.evaluate(config, parameter, max_episodes=100)
print(f"Average reward for 100 episodes: {np.mean(rewards)}")
# --- dist
parameter, remote_memory, history2 = runner.mp_train(
config,
timeout=60 * 10,
enable_evaluation=False,
)
rewards = runner.evaluate(config, parameter, max_episodes=100)
print(f"Average reward for 100 episodes: {np.mean(rewards)}")
# --- plot
plt.xlabel("time")
plt.ylabel("reward")
for name, h in [("sequence", history1), ("mp", history2)]:
df = h.get_df()
df = df.groupby("time").mean()
plt.plot(df["episode_reward0"].rolling(20).mean(), label=name)
plt.grid()
plt.legend()
plt.tight_layout()
plt.show()
if __name__ == "__main__":
main()
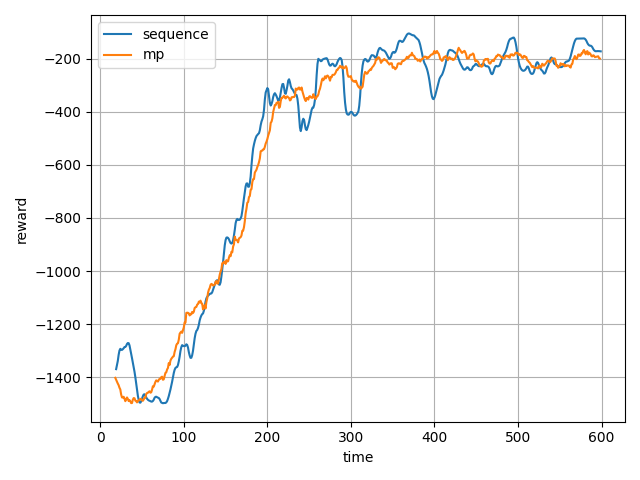
実行した私のPCのスペックは以下です。(CPU/GPU共に1個です)
- CPU: Core i7-8700 3.2GHz
- GPU: NVIDIA GeForce GTX 1060 3GB
このレベルだと分散処理の恩師はほとんどありませんね(画像処理レイヤーもないので
GPUの効果もほとんどありません、たぶんCPUの方が早いかも)
ちなみにApe-Xの論文だと360actorです。(360CPU使用)
360個のCPUとか個人ではちょっと実験できないレベルですね…