はじめに
最近の機械学習の発展はすごいですね。
特に大規模言語モデル(LLM;Large Language Model)の発展が目覚ましく、ChatGPTをはじめ目に見える形で成果が出始めています。1
この技術の進歩に置いて行かれないようにLLMを勉強しつつ強化学習に実装してみました。
記事としては前半はLLMの利用、後半は強化学習のDQNにLLMを組み込んだ実装となります。
PythonからLLMの利用
LLMの利用はBERTでもお世話になったHugging Faceを使います。
ドキュメントがかなり充実しており、チュートリアルをベースに進めてみました。
また今回実行している環境は以下です。
OS : Windows11
Python: 3.12.2
GPU : GeForce RTX3060(memory 12GB)
CUDA : 12.1.1 (Torchに合わせています)
0. 準備
必要なライブラリです。
一応venvでPython環境を作り直してみています。
また、使うモデルによっては別に必要なライブラリがあります。(適宜記載)
# Torch: https://pytorch.org/get-started/locally/
# Stable(2.2.2) CUDA12.1
> pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
> python -c "import torch; print(torch.cuda.is_available())"
True
# Transformers
> pip install transformers
> python -c "import transformers; print(transformers.__version__)"
4.39.3
1. モデルの選定
各モデルの概要はドキュメントにあるのでそちらを参考にしつつ選びました。(ドキュメントは英語版しかなさそう)
https://huggingface.co/docs/transformers/main/en/index
API → MODELS
テキスト以外にもいろんなモデルがありますね。
今回はマルチモーダルの Image-Text to Text である LLaVA-NeXT というモデルを利用したいと思います。
LLaVA-NeXTの概要は以下から確認できます。
実際のモデルは以下から検索できます。
ただ見てわかる通り膨大なモデルがあります…。
本記事ではLLaVA-NeXTの中でも以下のモデルを利用したいと思います。
このモデルですが、参考にしている論文は2023/10/5に発表されたもののようでかなり新しいモデルだと思われます。
他のモデルもですが、コードベースで使い方が書かれており、かなり使いやすい印象を受けました。
では実際に使ってみます。
2. モデルの動作確認
Model card のコードそのままで動きました。
ただ警告がいくつか出てたので細かい部分を修正しています。
一応チュートリアルも参考:https://huggingface.co/docs/transformers/ja/llm_tutorial
import os
import time
import torch
from PIL import Image
from transformers import BitsAndBytesConfig, LlavaNextForConditionalGeneration, LlavaNextProcessor
model_name = "llava-hf/llava-v1.6-mistral-7b-hf"
image = Image.open(os.path.join(os.path.dirname(__file__), "img1.png"))
prompt = "[INST] <image>\nWhat is shown in this image? [/INST]"
device = "cuda" if torch.cuda.is_available() else "cpu"
# --- 1. modelとprocessorをダウンロード
# 初回はかなり時間がかかります(20GBほど?)
#
# ・量子化しないとメインメモリ32GBあっても足りなかった
# load_in_4bit=Trueを使うと以下の警告が出るので警告に従っています
# The `load_in_4bit` and `load_in_8bit` arguments are deprecated and will be removed in the future versions. Please, pass a `BitsAndBytesConfig` object in `quantization_config` argument instead.
quantization_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.float16)
model = LlavaNextForConditionalGeneration.from_pretrained(
model_name,
torch_dtype=torch.float16,
low_cpu_mem_usage=True, # これを入れていないとGPU12GBでも足りない
# load_in_4bit=True,
quantization_config=quantization_config,
)
processor = LlavaNextProcessor.from_pretrained(model_name)
# モデル情報
print(model)
print(model.config)
# --- 2. 推論
t0 = time.time()
inputs = processor(prompt, image, return_tensors="pt").to(device)
output = model.generate(**inputs, max_new_tokens=100)
print(f"かかった時間 : {time.time() - t0}s")
# --- 3. 結果を出力
generated_text = processor.decode(output[0], skip_special_tokens=True)
print(generated_text)
max_new_tokens は出力量を決めるオプションらしく任意の数を指定できます。
以下実行時に追加したライブラリ
# ImportError: Using `low_cpu_mem_usage=True` or a `device_map` requires Accelerate: `pip install accelerate`
> pip install accelerate
# importlib.metadata.PackageNotFoundError: No package metadata was found for bitsandbytes
> pip install bitsandbytes
・出力結果
入力画像は以下で「What is shown in this image?」と質問しています。

かかった時間 : 4.9148108959198s
[INST]
What is shown in this image? [/INST] The image shows a pixel art style depiction of a character, which appears to be a cat, standing in the center of a grid with circular puddles. The background has a grassy texture, and there are two additional elements: a wooden crate in the top right corner and a dark, circular object in the bottom right corner. The overall aesthetic suggests it could be from a video game or a similar form of digital art.
※日本語訳
この画像は、円形の水たまりのあるグリッドの中心に猫のように見えるキャラクターが立っているピクセル アート スタイルの描写を示しています。 背景には草のようなテクスチャがあり、右上隅にある木箱と右下隅にある暗い円形のオブジェクトという 2 つの追加要素があります。 全体的な美しさは、ビデオゲームまたは同様の形式のデジタルアートからのものである可能性を示唆しています。
すごい精度!
強化学習へ
強化学習への転用はいくつか考えられますが、一番シンプルに大規模モデルの出力層の特徴量をそのままDQNに使う事を考えます。
DQNに関しては過去の記事を見てください。
イメージは以下です。
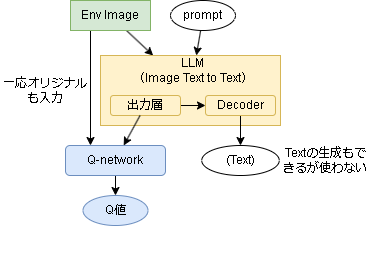
環境の現在の状態(画像)を入力とし、LLMの出力層をQネットワークに利用します。
以下にLLMに関するコードを抜粋します。
コード全体は後述してあります。
また、足りていないライブラリは以下です。
# SRL用
> pip install pygame opencv-python
> pip install git+https://github.com/pocokhc/simple_distributed_rl@v0.15.2
# 翻訳(バージョン指定しないと最新が取得できなかった)
> pip install googletrans==4.0.0rc1
SRLは強化学習用の自作フレームワークで以下で公開しています。
1. プロンプト
入力に使うプロンプトはアクションを聞くような文言にしています。
デフォルトでは以下にしています。
使う環境によって内容は変えたほうがいいかもしれません。
prompt: str = "What should I do first in this image? Please answer in 200 characters."
2. モデル
DQNで使うモデルを定義します。
入力は Image と LLMの特徴量 の2つです。
class QNetwork(nn.Module):
def __init__(self, action_num, llm_out_size):
super().__init__()
# DQNのimage層 (1, 84, 84)
filters = 32
self.image_layers = nn.ModuleList(
[
nn.Conv2d(1, filters, 8, 4, 3, padding_mode="replicate"),
nn.ReLU(inplace=True),
nn.Conv2d(filters, filters * 2, 4, 2, 2, padding_mode="replicate"),
nn.ReLU(inplace=True),
nn.Conv2d(filters * 2, filters * 2, 3, 1, 1, padding_mode="replicate"),
nn.ReLU(inplace=True),
nn.Flatten(),
]
)
img_out_size = 64 * 11 * 11
self.hidden_layers = nn.ModuleList(
[
nn.Linear(img_out_size + llm_out_size, 512),
nn.ReLU(inplace=True),
nn.Linear(512, action_num),
]
)
def forward(self, x):
x1 = x[0]
for h in self.image_layers:
x1 = h(x1)
x = torch.cat([x1, x[1]], dim=-1)
for h in self.hidden_layers:
x = h(x)
return x
class Parameter(RLParameter):
def __init__(self, *args):
super().__init__(*args)
# ハイパーパラメータ
prompt = self.config.prompt
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# --- LLM
model_name = "llava-hf/llava-v1.6-mistral-7b-hf"
quantization_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.float16)
self.model = LlavaNextForConditionalGeneration.from_pretrained(
model_name,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
quantization_config=quantization_config,
)
self.model.eval()
self.processor = LlavaNextProcessor.from_pretrained(model_name)
# LLM入力用のプロンプトを作成
self.prompt = f"[INST] <image>\n{prompt} [/INST]"
# 出力サイズを知りたいので仮で実行してサイズを取得
x = self.compute_lm(np.zeros((1, 336, 336, 3))) # (batch, img_h, img_w, ch)
out_size = x.shape[-1]
# --- Q network
action_num = self.config.action_space.n
self.q_online = QNetwork(action_num, out_size).to(self.device)
self.q_target = QNetwork(action_num, out_size).to(self.device)
self.q_target.eval()
self.q_target.load_state_dict(self.q_online.state_dict())
def compute_lm(self, img, render: bool = False):
"""LLMによる推論を実行する
renderフラグが立っている場合はテキストも生成する
"""
with torch.no_grad():
img = torch.Tensor(img).to(self.device)
inputs = self.processor(self.prompt, img, return_tensors="pt").to(self.device)
#
# generateに「output_logits=True,return_dict_in_generate=True」を追加するとlogitsも返してくれる
# 元の出力は outputs.sequences に、logitsは outputs.logits に保存されている
# outputs.logitsがなぜか配列(中間層のデータ?出力が複数?)なので0番目を利用(もしかしたら-1が出力かも)
#
outputs = self.model.generate(
**inputs,
max_new_tokens=50,
pad_token_id=32001,
output_logits=True,
return_dict_in_generate=True,
)
x = outputs.logits[0].to("cpu").detach().numpy()
if render:
generated_text = self.processor.decode(outputs.sequences[0], skip_special_tokens=True)
return x, generated_text
return x
3. Worker
推論部分です。
Q-network用に画像をリサイズして渡しています。
また学習とは関係ないですが、render用に画像の出力と日本語への翻訳をしています。
class Worker(RLWorker):
def on_reset(self, worker) -> InfoType:
self.x = self._create_feat(worker)
self.prev_x = self.x
return {}
def _create_feat(self, worker):
# 画像を(84,84,1)のグレー画像に変換
q_img = helper.image_processor(
worker.state,
SpaceTypes.COLOR,
SpaceTypes.GRAY_3ch,
(84, 84),
shape_order="CHW",
)
q_img = q_img.astype(np.float16) / 255.0
# LLM用に画像を(336,336)にリサイズ
# これはやらなくてもprocessorで勝手にやってくれるかも
lm_img = helper.image_processor(
worker.state,
SpaceTypes.COLOR,
SpaceTypes.COLOR,
(336, 336),
shape_order="HWC",
)
lm_img = lm_img.astype(np.uint8)
# LLMを通して特徴量を取得
# renderの場合はテキストも生成する
if self.rendering:
z, self.generated_text = self.parameter.compute_lm(lm_img[np.newaxis, ...], render=True)
self.generated_text = self.generated_text.split("[/INST]")[1]
else:
z = self.parameter.compute_lm(lm_img[np.newaxis, ...])
return [q_img, z[0]]
def policy(self, worker):
# ε-greedy法でアクションを決定(コードは省略)
return action
def _pred_single_q(self) -> np.ndarray:
# Q networkからQ値を予測
with torch.no_grad():
q = self.parameter.q_online(
[
torch.Tensor(self.x[0][np.newaxis, ...]).to(self.parameter.device),
torch.Tensor(self.x[1][np.newaxis, ...]).to(self.parameter.device),
]
)
q = q.to("cpu").detach().numpy()
return q[0]
def on_step(self, worker):
# self._create_feat(worker)で特徴量を作り、memoryに送信(コードは省略)
return {}
def render_terminal(self, worker, **kwargs) -> None:
# 翻訳して表示する部分のみ抜粋
# self.generated_textに生成テキスト(英語)が入っています
text = self.generated_text
# --- 翻訳
from googletrans import Translator
translator = Translator()
ja_text = translator.translate(text, src="en", dest="ja").text
print(ja_text)
コード全体(Google Colaboratory)
Google Colaboratory でも実行してみました。
もし動かす場合はデバイスはGPUを選んでください。CPUだとメモリ不足で動きませんでした。
コード全体
折りたたんでいます。
使用コード
※SRLがv0.15.2のコードです。バージョンが進むと動かない可能性があります。
import copy
import random
from dataclasses import dataclass
import numpy as np
import srl
import torch
import torch.nn as nn
import torch.optim as optim
from srl.base.define import InfoType, RLBaseTypes, SpaceTypes
from srl.base.rl.config import RLConfig
from srl.base.rl.parameter import RLParameter
from srl.base.rl.registration import register
from srl.base.rl.trainer import RLTrainer
from srl.base.rl.worker import RLWorker
from srl.rl.functions import helper
from srl.rl.memories.experience_replay_buffer import ExperienceReplayBuffer, RLConfigComponentExperienceReplayBuffer
from transformers import BitsAndBytesConfig, LlavaNextForConditionalGeneration, LlavaNextProcessor
@dataclass
class Config(RLConfig, RLConfigComponentExperienceReplayBuffer):
prompt: str = "What should I do first in this image? Please answer in 200 characters."
# Q parameters
lr: float = 0.001
batch_size: int = 32
discount: float = 0.99
epsilon: float = 0.1
target_model_update_interval: int = 100
def get_base_action_type(self) -> RLBaseTypes:
return RLBaseTypes.DISCRETE
def get_base_observation_type(self) -> RLBaseTypes:
return RLBaseTypes.IMAGE
def get_framework(self) -> str:
return "torch"
def get_name(self) -> str:
return "DQN_LM"
register(
Config(),
__name__ + ":Memory",
__name__ + ":Parameter",
__name__ + ":Trainer",
__name__ + ":Worker",
)
class Memory(ExperienceReplayBuffer):
pass
class QNetwork(nn.Module):
def __init__(self, action_num, llm_out_size):
super().__init__()
# DQNのimage層 (1, 84, 84)
filters = 32
self.image_layers = nn.ModuleList(
[
nn.Conv2d(1, filters, 8, 4, 3, padding_mode="replicate"),
nn.ReLU(inplace=True),
nn.Conv2d(filters, filters * 2, 4, 2, 2, padding_mode="replicate"),
nn.ReLU(inplace=True),
nn.Conv2d(filters * 2, filters * 2, 3, 1, 1, padding_mode="replicate"),
nn.ReLU(inplace=True),
nn.Flatten(),
]
)
img_out_size = 64 * 11 * 11
self.hidden_layers = nn.ModuleList(
[
nn.Linear(img_out_size + llm_out_size, 512),
nn.ReLU(inplace=True),
nn.Linear(512, action_num),
]
)
def forward(self, x):
x1 = x[0]
for h in self.image_layers:
x1 = h(x1)
x = torch.cat([x1, x[1]], dim=-1)
for h in self.hidden_layers:
x = h(x)
return x
class Parameter(RLParameter):
def __init__(self, *args):
super().__init__(*args)
# ハイパーパラメータ
prompt = self.config.prompt
# --- LLM
model_name = "llava-hf/llava-v1.6-mistral-7b-hf"
if torch.cuda.is_available():
self.device = "cuda"
quantization_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.float16)
self.model = LlavaNextForConditionalGeneration.from_pretrained(
model_name,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
quantization_config=quantization_config,
)
else:
self.device = "cpu"
self.model = LlavaNextForConditionalGeneration.from_pretrained(
model_name,
low_cpu_mem_usage=True,
)
self.model.eval()
self.processor = LlavaNextProcessor.from_pretrained(model_name)
# LLM入力用のプロンプトを作成
self.prompt = f"[INST] <image>\n{prompt} [/INST]"
# 出力サイズを知りたいので仮で実行してサイズを取得
x = self.compute_lm(np.zeros((1, 336, 336, 3))) # (batch, img_h, img_w, ch)
out_size = x.shape[-1]
# --- Q network
action_num = self.config.action_space.n
self.q_online = QNetwork(action_num, out_size).to(self.device)
self.q_target = QNetwork(action_num, out_size).to(self.device)
self.q_target.eval()
self.q_target.load_state_dict(self.q_online.state_dict())
def compute_lm(self, img, render: bool = False):
"""LLMによる推論を実行する
renderフラグが立っている場合はテキストも生成する
"""
with torch.no_grad():
img = torch.Tensor(img).to(self.device)
inputs = self.processor(self.prompt, img, return_tensors="pt").to(self.device)
#
# generateに「output_logits=True,return_dict_in_generate=True」を追加するとlogitsも返してくれる
# 元の出力は outputs.sequences に、logitsは outputs.logits に保存されている
# outputs.logitsがなぜか配列(中間層のデータ?出力が複数?)なので0番目を利用(もしかしたら-1が出力かも)
#
outputs = self.model.generate(
**inputs,
max_new_tokens=50,
pad_token_id=32001,
output_logits=True,
return_dict_in_generate=True,
)
x = outputs.logits[0].to("cpu").detach().numpy()
if render:
generated_text = self.processor.decode(outputs.sequences[0], skip_special_tokens=True)
return x, generated_text
return x
def call_restore(self, data, from_cpu: bool = False, **kwargs) -> None:
if self.config.used_device_torch != "cpu" and from_cpu:
self.q_online.to("cpu").load_state_dict(data)
self.q_target.to("cpu").load_state_dict(data)
self.q_online.to(self.device)
self.q_target.to(self.device)
else:
self.q_online.load_state_dict(data)
self.q_target.load_state_dict(data)
def call_backup(self, to_cpu: bool = False, **kwargs):
if self.config.used_device_torch != "cpu" and to_cpu:
return copy.deepcopy(self.q_online).to("cpu").state_dict()
else:
return self.q_online.state_dict()
class Trainer(RLTrainer):
def __init__(self, *args):
super().__init__(*args)
self.optimizer = optim.Adam(self.parameter.q_online.parameters(), lr=self.config.lr)
self.criterion = nn.HuberLoss()
self.device = self.parameter.device
self.parameter.q_target.to(self.device)
self.parameter.q_online.to(self.device)
def train(self) -> None:
if self.memory.is_warmup_needed():
return
batchs = self.memory.sample(self.config.batch_size)
state, n_state, onehot_action, reward, undone = zip(*batchs)
onehot_action = torch.FloatTensor(onehot_action).to(self.device)
reward = torch.FloatTensor(reward).to(self.device)
undone = torch.FloatTensor(undone).to(self.device)
x1 = torch.Tensor([s[0] for s in state]).to(self.device)
x2 = torch.Tensor([s[1] for s in state]).to(self.device)
n_x1 = torch.Tensor([s[0] for s in n_state]).to(self.device)
n_x2 = torch.Tensor([s[1] for s in n_state]).to(self.device)
with torch.no_grad():
n_q = self.parameter.q_online([n_x1, n_x2])
n_q_target = self.parameter.q_target([n_x1, n_x2])
maxq = n_q_target.gather(1, torch.argmax(n_q, dim=1, keepdim=True)).squeeze(1)
target_q = reward + undone * self.config.discount * maxq
# --- torch train
self.optimizer.zero_grad()
q = self.parameter.q_online([x1, x2])
q = torch.sum(q * onehot_action, dim=1)
loss = self.criterion(q, target_q.detach())
loss.backward()
self.optimizer.step()
# --- targetと同期
if self.train_count % self.config.target_model_update_interval == 0:
self.parameter.q_target.load_state_dict(self.parameter.q_online.state_dict())
self.train_count += 1
class Worker(RLWorker):
def __init__(self, *args):
super().__init__(*args)
self.translator = None
def on_reset(self, worker) -> InfoType:
self.x = self._create_feat(worker)
self.prev_x = self.x
return {}
def _create_feat(self, worker):
# 画像を(84,84,1)のグレー画像に変換
q_img = helper.image_processor(
worker.state,
SpaceTypes.COLOR,
SpaceTypes.GRAY_3ch,
(84, 84),
shape_order="CHW",
)
q_img = q_img.astype(np.float16) / 255.0
# LLM用に画像を(336,336)にリサイズ
# これはやらなくてもprocessorで勝手にやってくれるかも
lm_img = helper.image_processor(
worker.state,
SpaceTypes.COLOR,
SpaceTypes.COLOR,
(336, 336),
shape_order="HWC",
)
lm_img = lm_img.astype(np.uint8)
# LLMを通して特徴量を取得
# renderの場合はテキストも生成する
if self.rendering:
z, self.generated_text = self.parameter.compute_lm(lm_img[np.newaxis, ...], render=True)
self.generated_text = self.generated_text.split("[/INST]")[1]
else:
z = self.parameter.compute_lm(lm_img[np.newaxis, ...])
return [q_img, z[0]]
def policy(self, worker):
# ε-greedy法でアクションを決定
if random.random() < self.config.epsilon:
action = random.choice([a for a in range(self.action_space.n)])
else:
q = self._pred_single_q()
action = int(np.argmax(q))
return action, {}
def _pred_single_q(self) -> np.ndarray:
# Q networkからQ値を予測
with torch.no_grad():
q = self.parameter.q_online(
[
torch.Tensor(self.x[0][np.newaxis, ...]).to(self.parameter.device),
torch.Tensor(self.x[1][np.newaxis, ...]).to(self.parameter.device),
]
)
q = q.to("cpu").detach().numpy()
return q[0]
def on_step(self, worker):
self.prev_x = self.x
self.x = self._create_feat(worker)
if not self.training:
return {}
"""
[
state,
n_state,
onehot_action,
reward,
undone,
]
"""
batch = [
self.prev_x,
self.x,
helper.one_hot(worker.prev_action, self.action_space.n),
worker.reward,
int(not worker.terminated),
]
self.memory.add(batch)
return {}
def render_terminal(self, worker, **kwargs) -> None:
# policy -> render -> env.step
q = self._pred_single_q()
maxa = np.argmax(q)
_newline = 60
print("- image text -")
print(f"({self.config.prompt})")
print("\n".join(self.generated_text[i : i + _newline] for i in range(0, len(self.generated_text), _newline)))
try:
if self.translator is None:
from googletrans import Translator
self.translator = Translator()
_newline = 40
s = self.translator.translate(self.generated_text, src="en", dest="ja").text
s = str(s)
print("\n".join(s[i : i + _newline] for i in range(0, len(s), _newline)))
except Exception as e:
print(f"translate error: {e}")
print()
print("- q table -")
def _render_sub(a: int) -> str:
return f"{q[a]:7.5f}"
helper.render_discrete_action(int(maxa), self.action_space.n, worker.env, _render_sub)
実行サンプル
学習ですが時間がかかりすぎて…
ただ、テキスト生成が面白かったので出力だけをいくつかのせておきます。
(学習はなしです)
実行サンプル(Grid)
promptを"猫が次に移動する場所を200文字で教えてください。"に変更してみました。
フレームワークの機能として rl_config.observation_mode=image を設定すると入力がrenderの結果になります。
def main1():
env_config = srl.EnvConfig("Grid")
rl_config = Config(
prompt="Please tell me in 200 characters where the cat should move next.",
epsilon=0.9,
)
rl_config.observation_mode = "image" # 入力を画像にする
runner = srl.Runner(env_config, rl_config)
# runner.train(max_episodes=1) # これで学習できるけど…
runner.animation_save_gif("Grid.gif", max_steps=30, render_interval=1000)
main1()
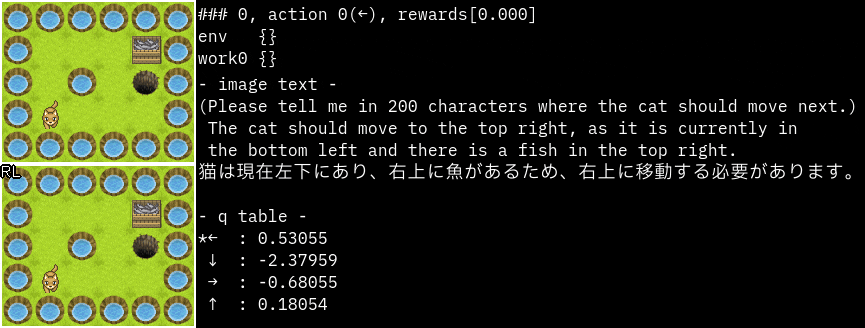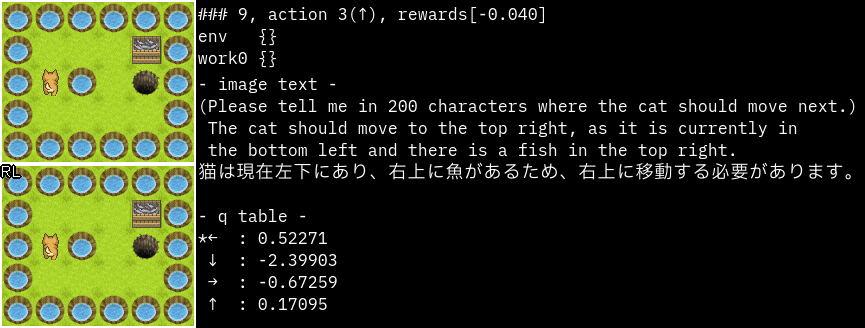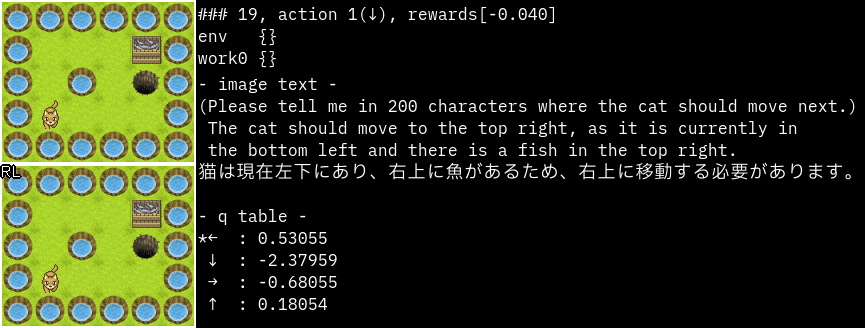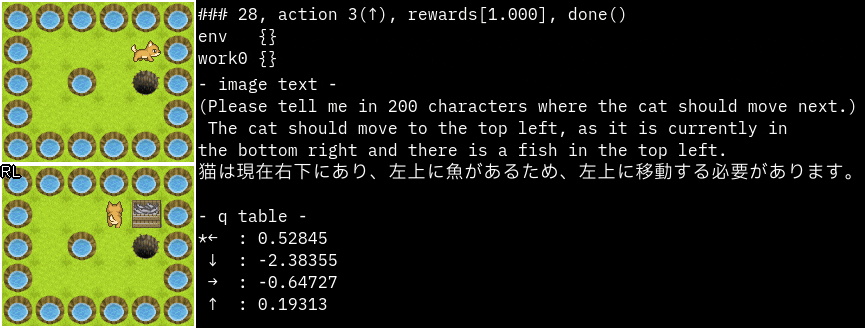
かなり的確な指示ですね。
実行サンプル(Atari Breakout)
Breakoutです。
promptを"バーを左右どちらに動かしたほうがいいのか200文字以内で教えてください。"に変更してみました。
※Atariは入力がデフォルトで画像形式なので rl_config.observation_mode の設定はしていません
※Atari環境ですが、py3.12.2ではインストールできなかったので別途py3.10.11の環境で実行しています。
def main2():
env_config = srl.EnvConfig(
"ALE/Breakout-v5",
kwargs=dict(frameskip=9, repeat_action_probability=0, full_action_space=False),
)
rl_config = Config(
prompt="Please tell me in 200 characters or less whether it is better to move the bar to the left or right.",
epsilon=0.9,
)
runner = srl.Runner(env_config, rl_config)
runner.animation_save_gif(
"Breakout.gif",
max_steps=30,
render_scale=2,
render_interval=1500,
)
main2()
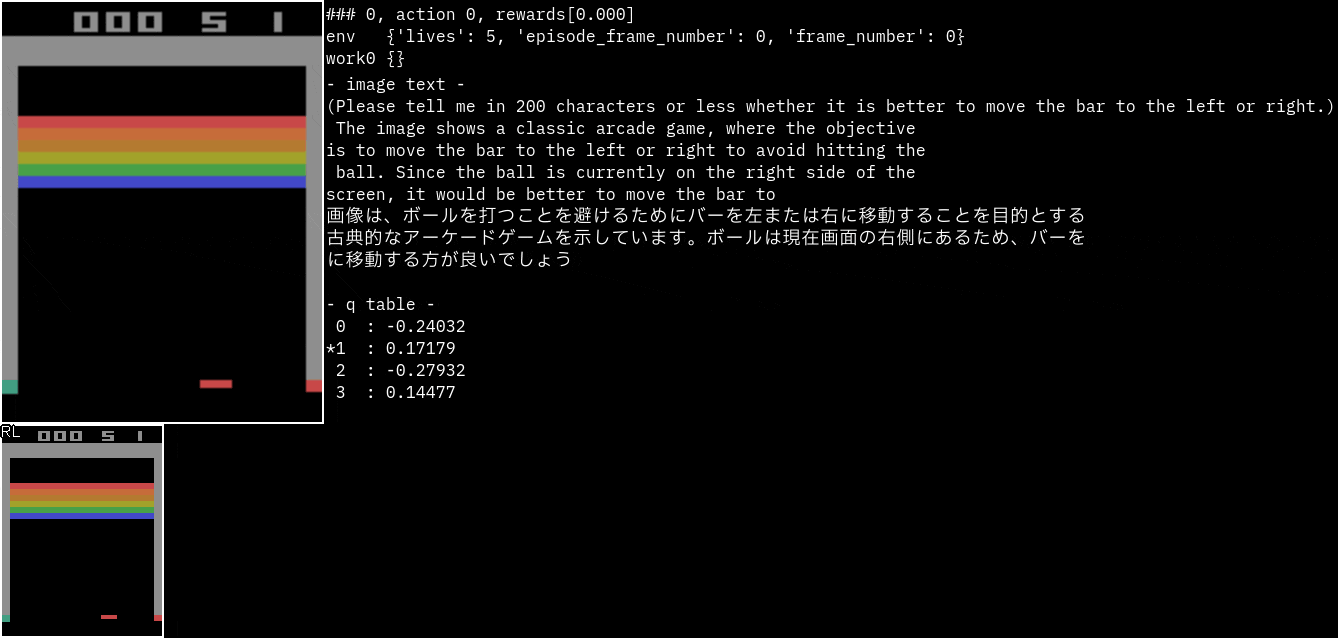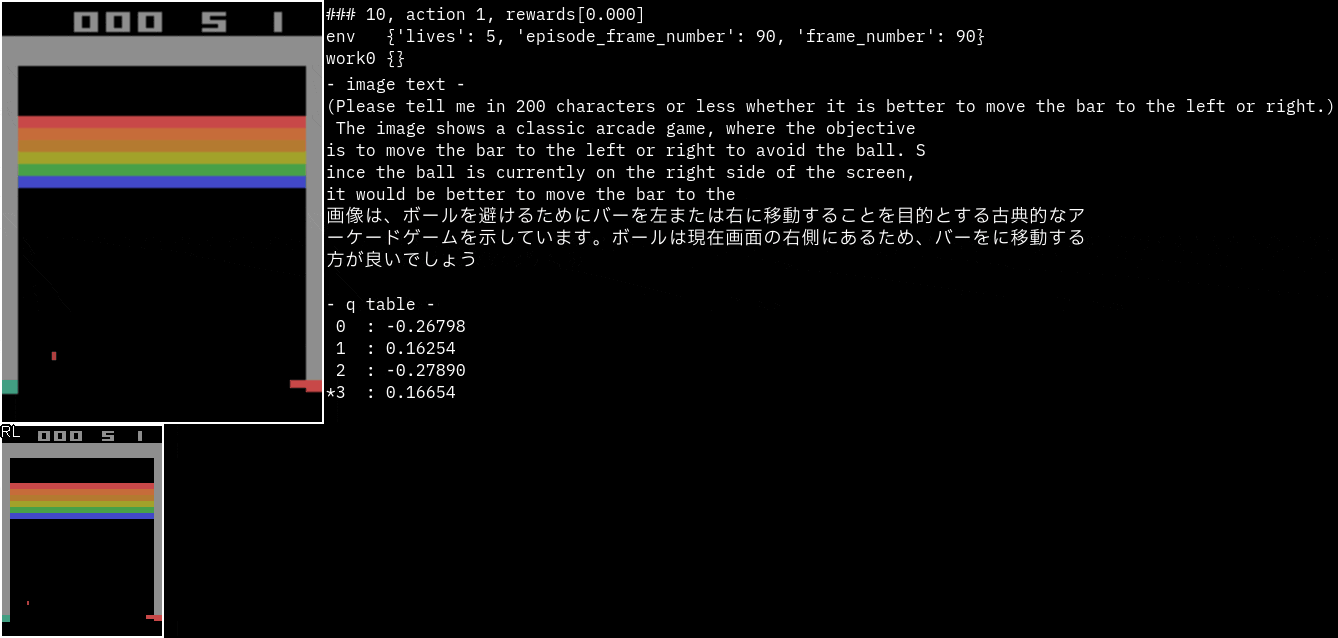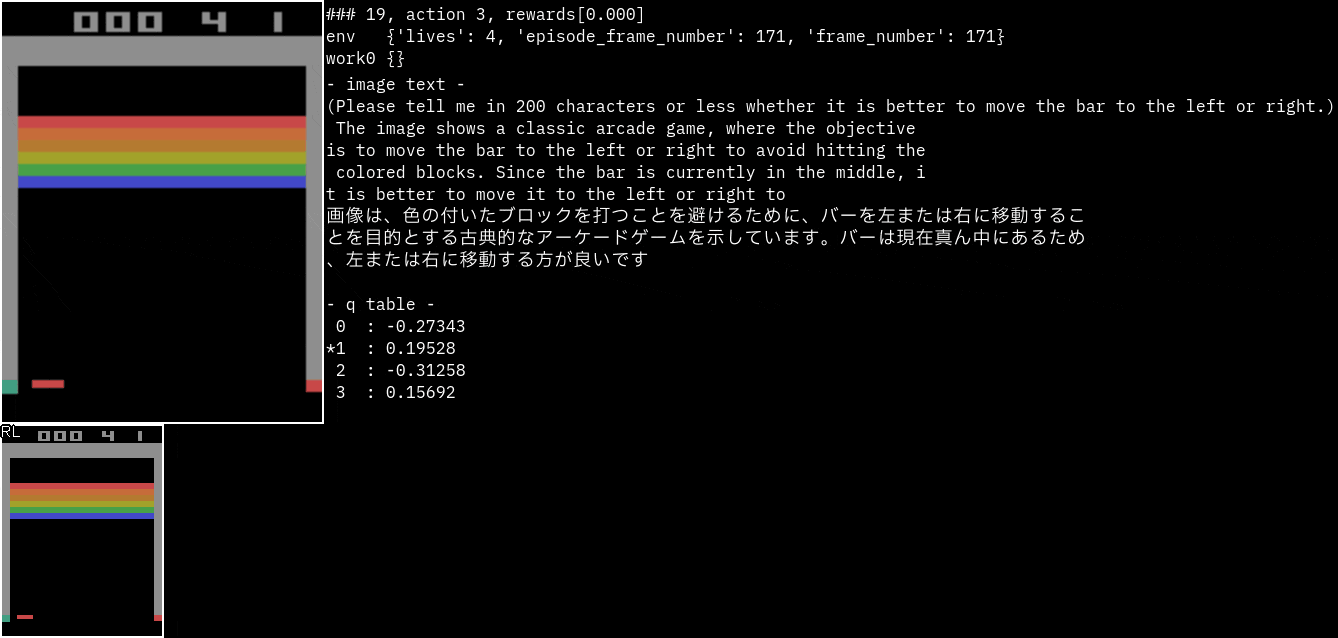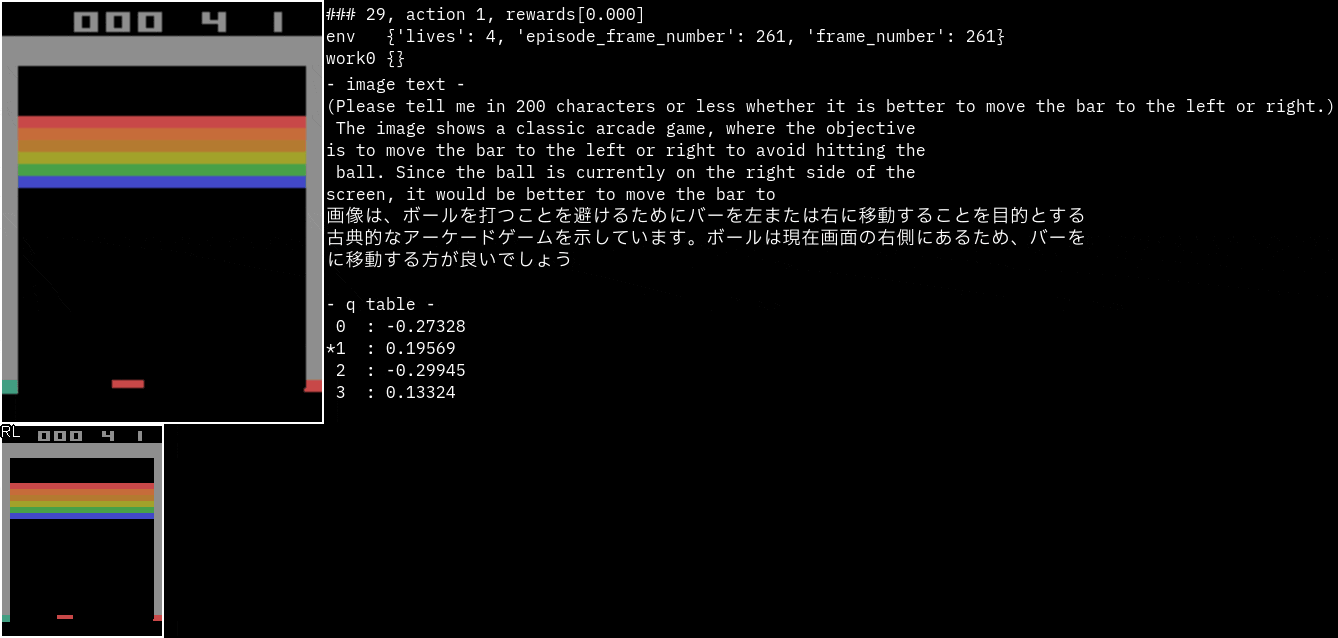
なぜかバーがボールを避けるように指示しています。
実行サンプル(Atari MontezumaRevenge)
最後にMontezumaRevengeを試してみました。
プロンプトは変えていません。
def main3():
env_config = srl.EnvConfig(
"ALE/MontezumaRevenge-v5",
kwargs=dict(frameskip=9, repeat_action_probability=0, full_action_space=False),
)
rl_config = Config(epsilon=0.9)
runner = srl.Runner(env_config, rl_config)
runner.animation_save_gif(
"MontezumaRevenge.gif",
max_steps=30,
render_scale=2,
render_interval=1500,
)
main3()
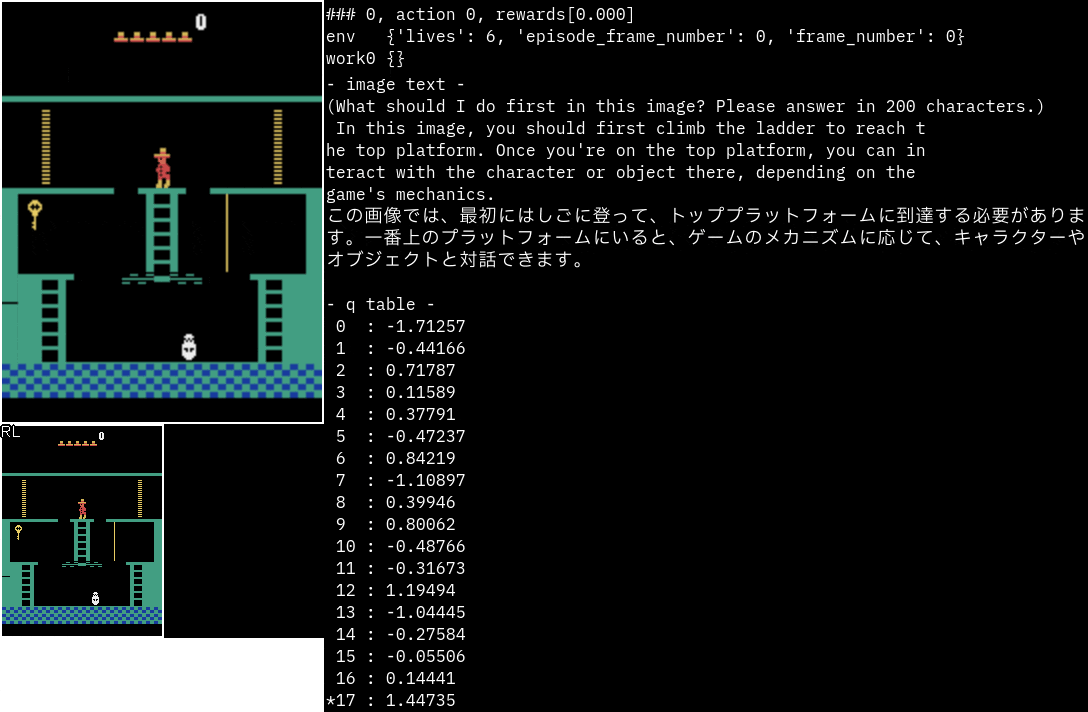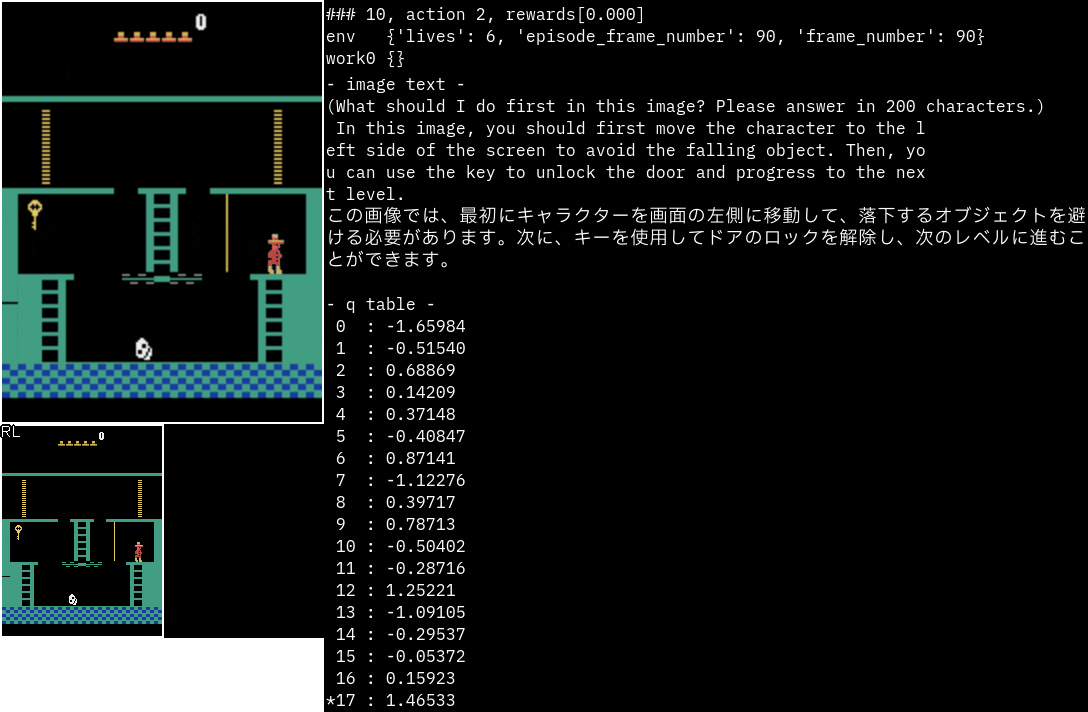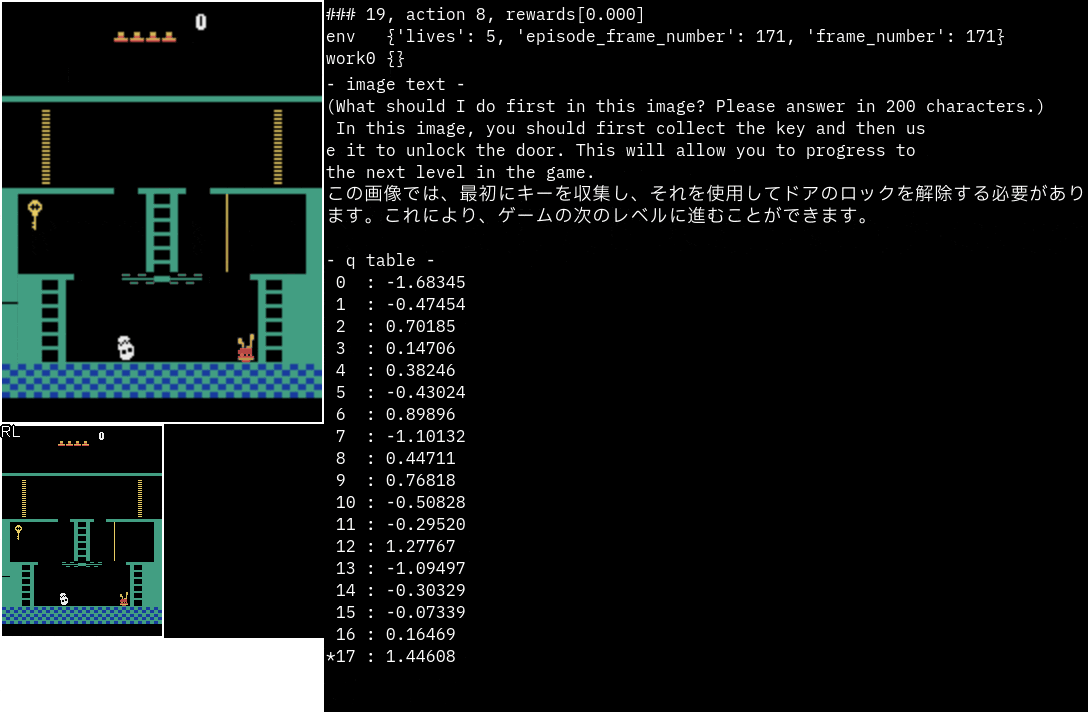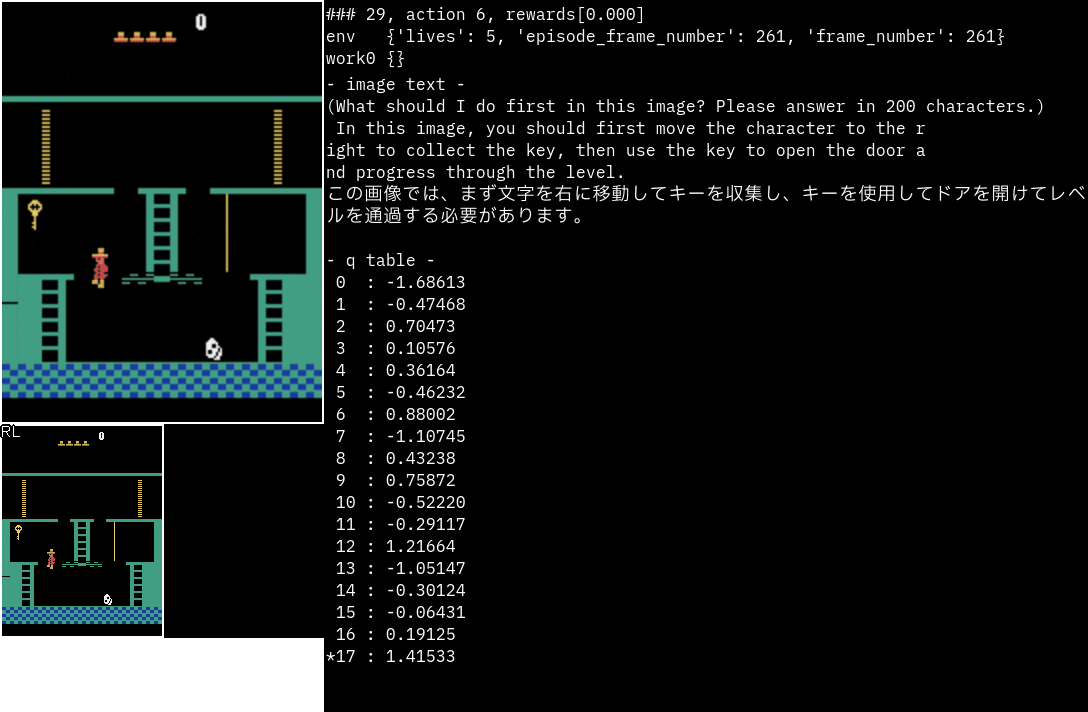
かなり的確に次の動作指示を出している印象です。
次のエリアへの行き方まで書かれています。
指示通りに動けるかが今後の課題ですね。
おまけ(moon)
moonというゲームのスラ子チャッチを見てみました。
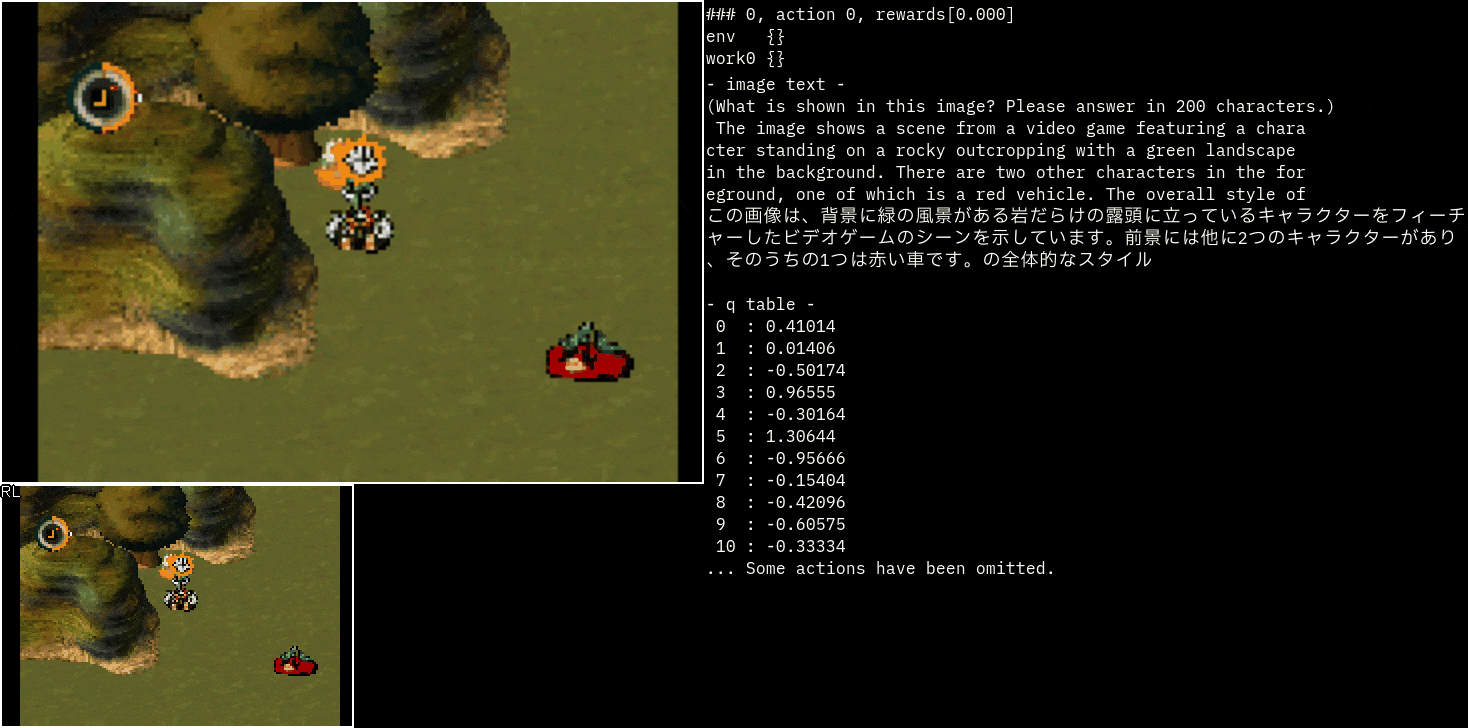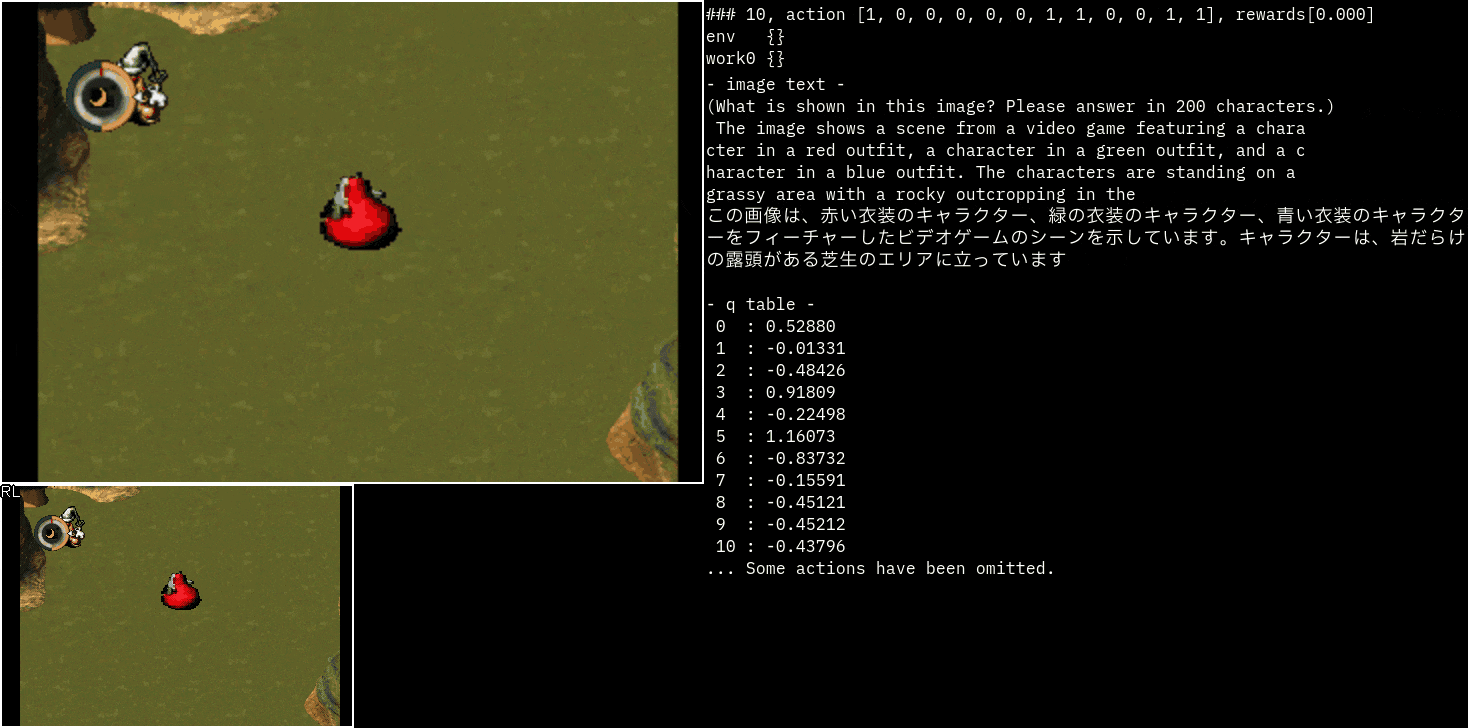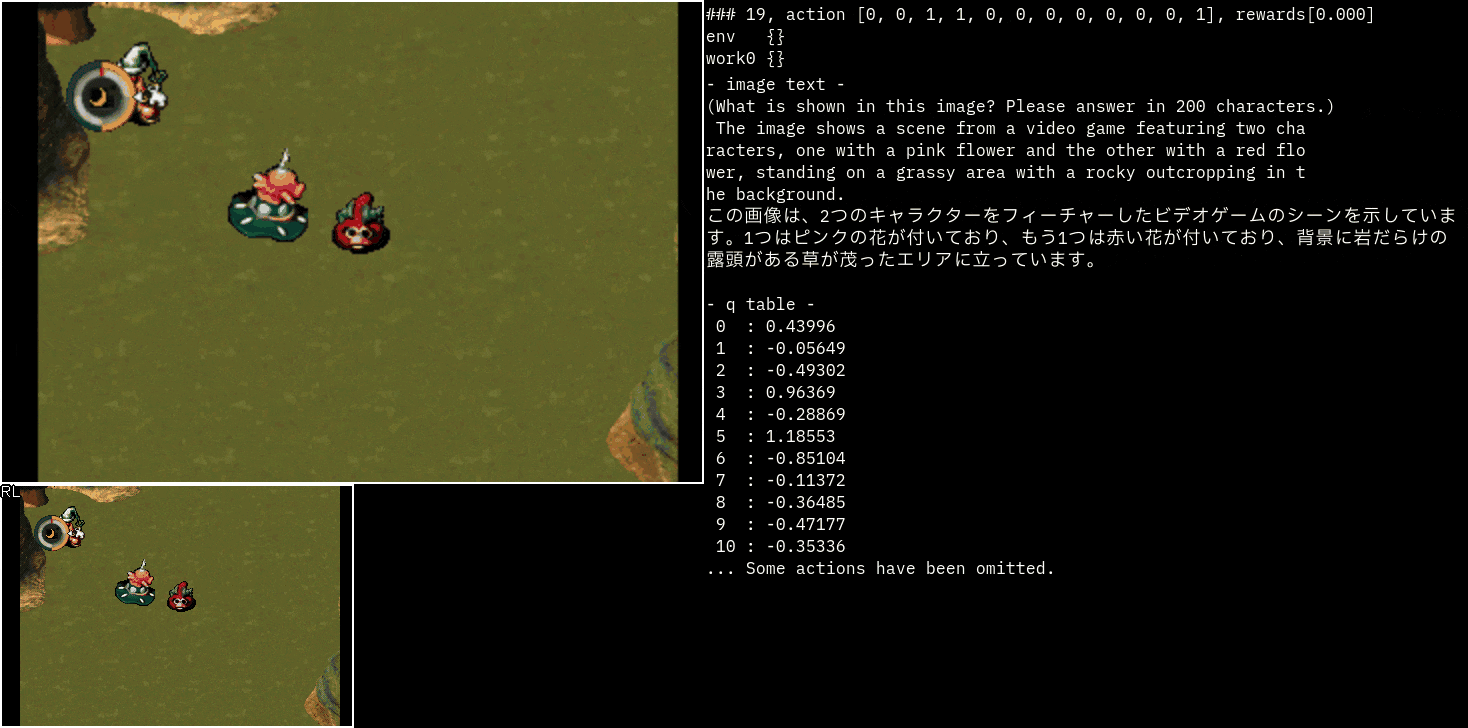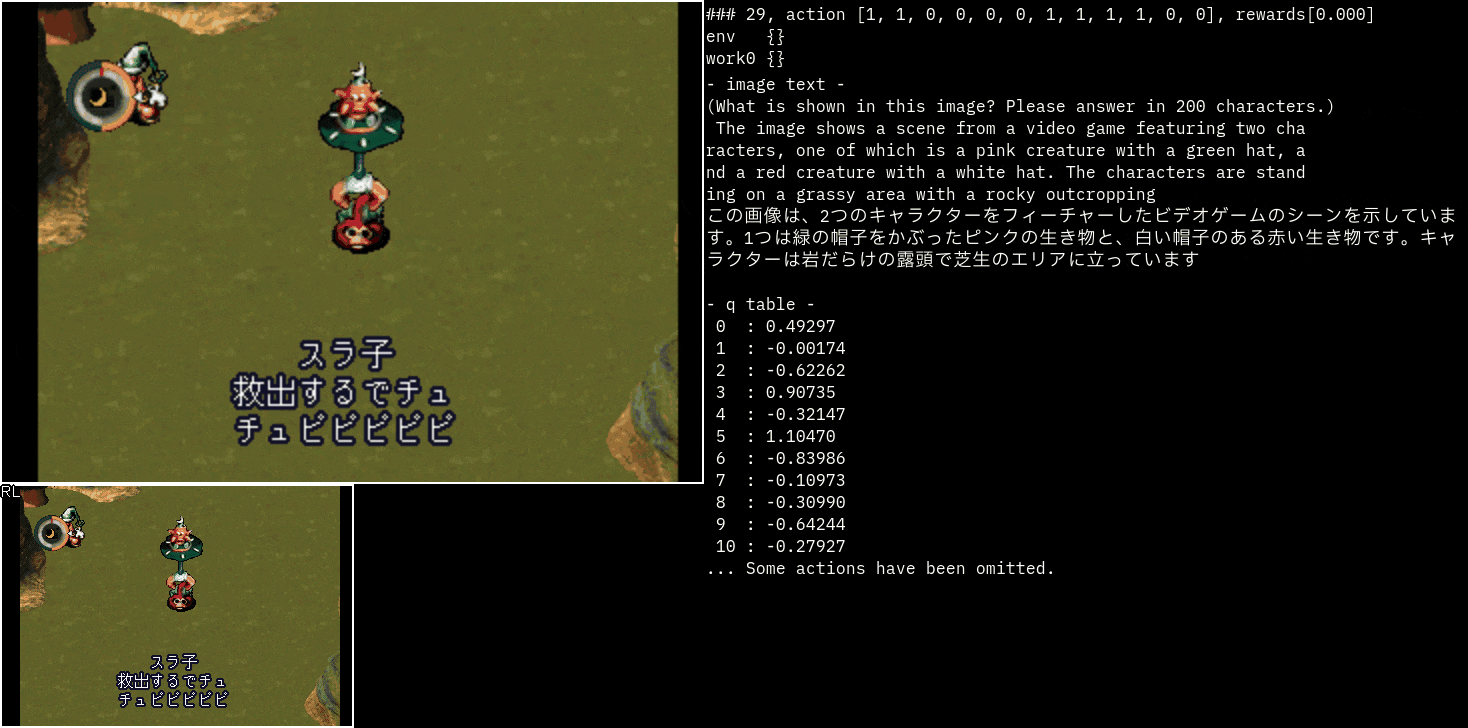
説明を見るだけでも面白いですね!
この精度だと他の利用方法を考えたくなります。
最後に
LLMがここまで簡単に実行できたのが衝撃的でした。
強化学習への組み込みはなんちゃってな感じになっちゃいましたが、この精度が衝撃的でせっかくなので記事にしました。
ただ速度は課題ですね、アイデア次第で対応できそうですが…。
-
大規模"言語"モデルといいつつ言語以外も扱い始めてますね。大規模モデルと言った方が正確なような ↩