NITEが公開している、製品起因の火災事故に関するデータを用いて、集計・分析していきたいと思います。
データの収集
NITE(独立行政法人 製品評価技術基盤機構)が公開しているデータセットを用いて、分析します。
NITEでは、数万件の製品事故情報をHP上でcsv形式で提供しています。
今回は、「火災」という文字列を含む製品事故に限定して収集します。
このように、検索条件を入力すると、
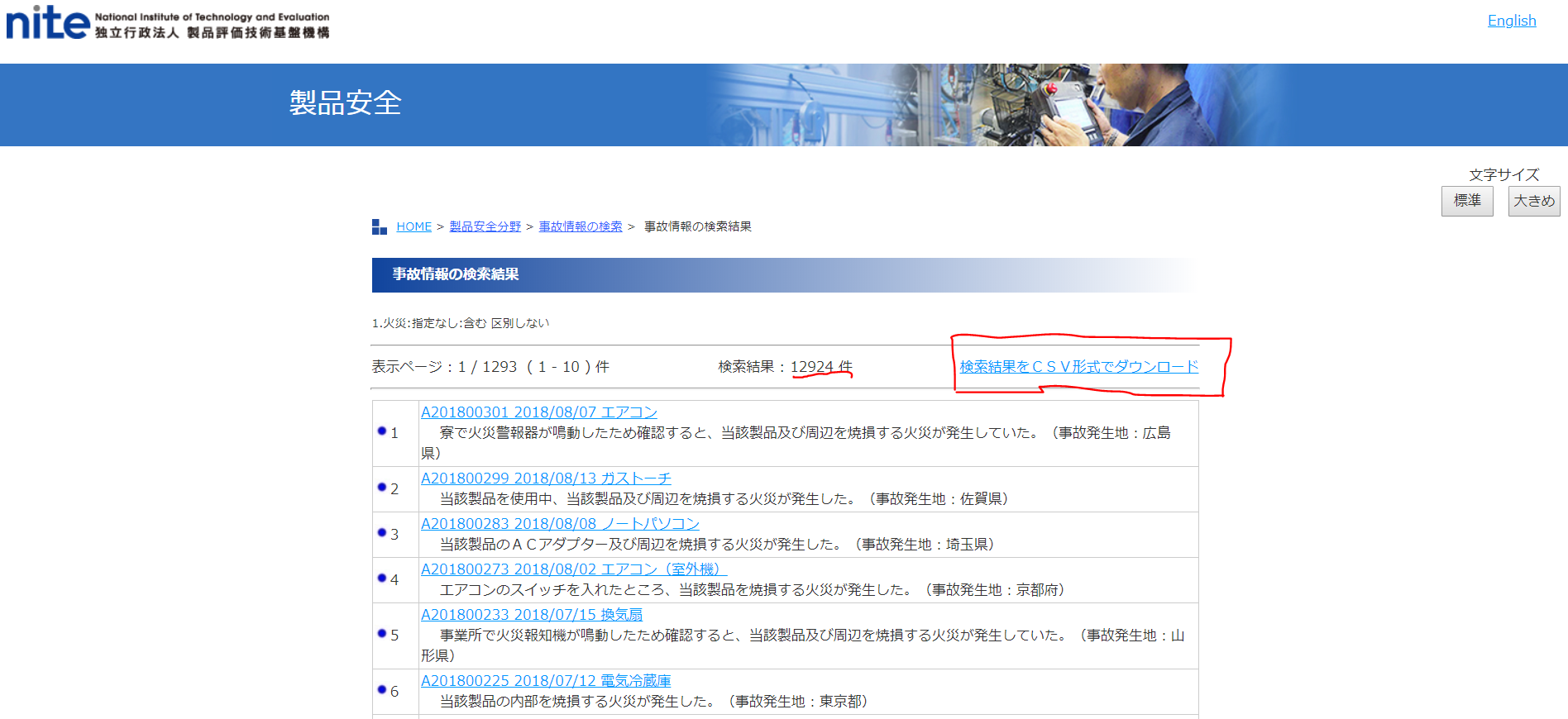
検索結果が返ってきます。
「火災」という文字列を含む製品事故は、12924件存在でした。
今回は、こちらのデータセットを対象に分析を進めたいと思います。
データの集計・分析(対象全データ)
pythonのpandas-profilingを使います。
詳しい使い方については、こちらの記事を御覧ください。
# データの読み込み
import pandas as pd
df_fire = pd.read_csv('accident_fire.csv', encoding="cp932")
# pandas-profilingによる集計・可視化
import pandas_profiling as pp
pp.ProfileReport(df_fire)
以下で集計結果を確認します。
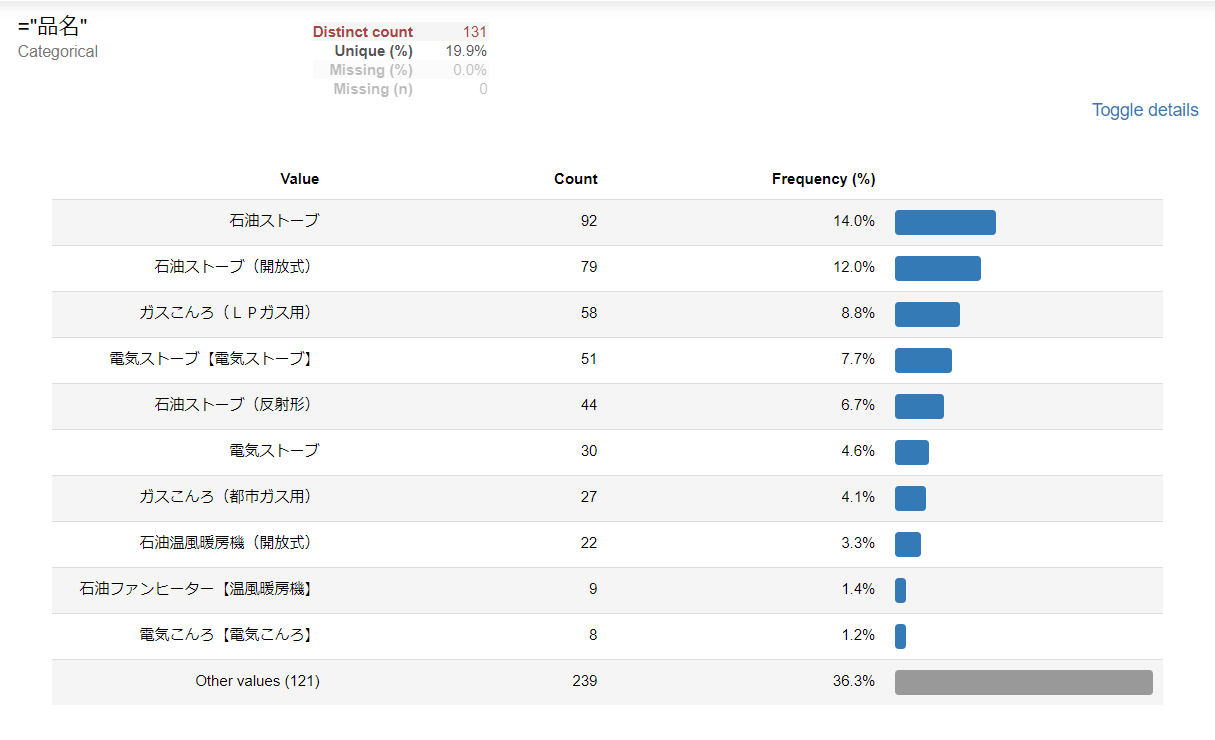
品名
ガスこんろ・石油ストーブが多く、石油給湯機・エアコンが続いています。
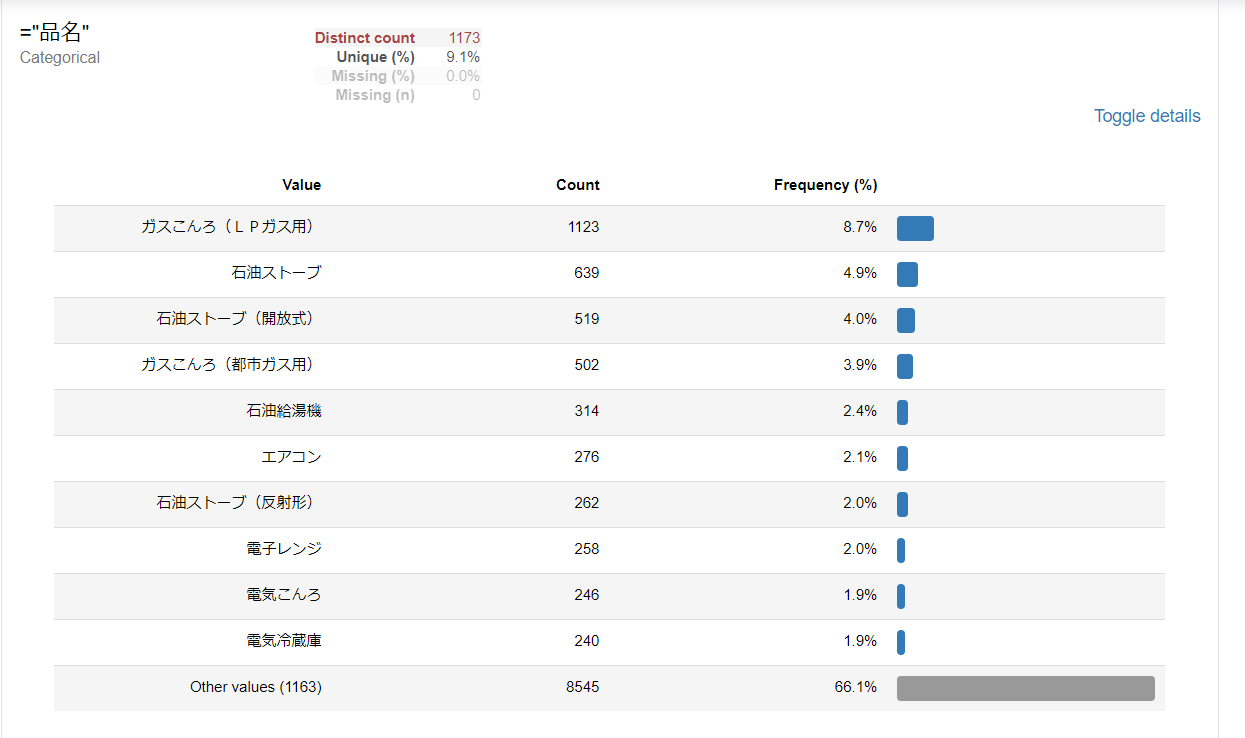
被害の種類
「火災」という文字列を含む事故を対象に絞ったので、火災が1位となりました。
次いで、拡大被害(製品破損にとどまらず、周囲の製品や建物などにも被害を及ぼすこと)、軽症、製品破損と続きます。
そして第5位に死亡がランクインしました。
但し、NITEが報告を受けているものは重大な事故の情報が多いと考えられるので、実際に死亡に至るような製品事故の割合は、グラフ中の数字よりは少ないのではないかと推測します。
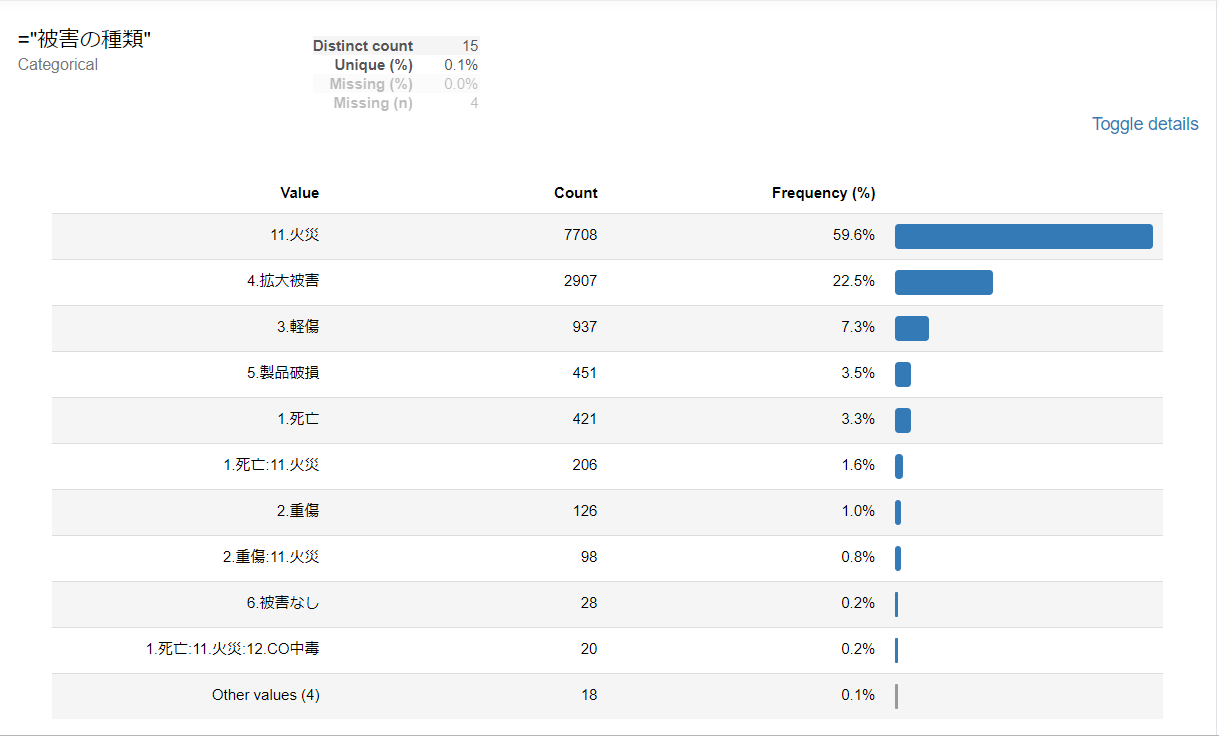
事故原因区分
凡例がないと分かりにくいので、凡例付きで列挙します。
1位 -- 記載なし
2位 E2 消費者の不注意
3位 E1 消費者の誤使用
4位 F2 その他製品に起因しないか、又は使用者の感受性に関係するもの
5位 G1 原因不明
6位 D1 業者の設置・施工不良
7位 E3 消費者の設置・施工不良
8位 A2 製造不良
9位 F1 製品には起因しない偶発的事故
10位 C1 経年劣化
:
中項目でEに該当する事故、すなわち消費者の責任で発生する事故が多いことが分かります。
事故原因(自由記述)
後に紹介する方法1に従い、文章中から重要なキーワードを抽出した後に、後に紹介する方法2に従い、重要なキーワードをユーザー定義語に追加。ユーザー定義語を考慮した形態素解析結果をWordCloudを用いて可視化します。WordCloudを用いた可視化については、こちらの記事で説明しています。

事故原因のキーワードを可視化してみました。
事故原因の詳細を検索するヒントになりそうなキーワードが出力されていることを確認できました。
(分析結果を利用した、キーワード検索の例は後に紹介する検索例で説明する)
データの集計・分析(死亡事故に限定した場合との比較)
次いで、死亡事故に絞って、同様に集計・分析した後、対象全データと比較します。
df_death = df_fire[df_fire["=\"被害の種類\""].str.contains('死亡', na=False)]
print(len(df_death))
<出力結果>
659
659件の死亡事故のデータを抽出できました。
df_death = df_fire[df_fire["=\"被害の種類\""].str.contains('死亡', na=False)]
print(len(df_death))
以下で集計結果を確認します。
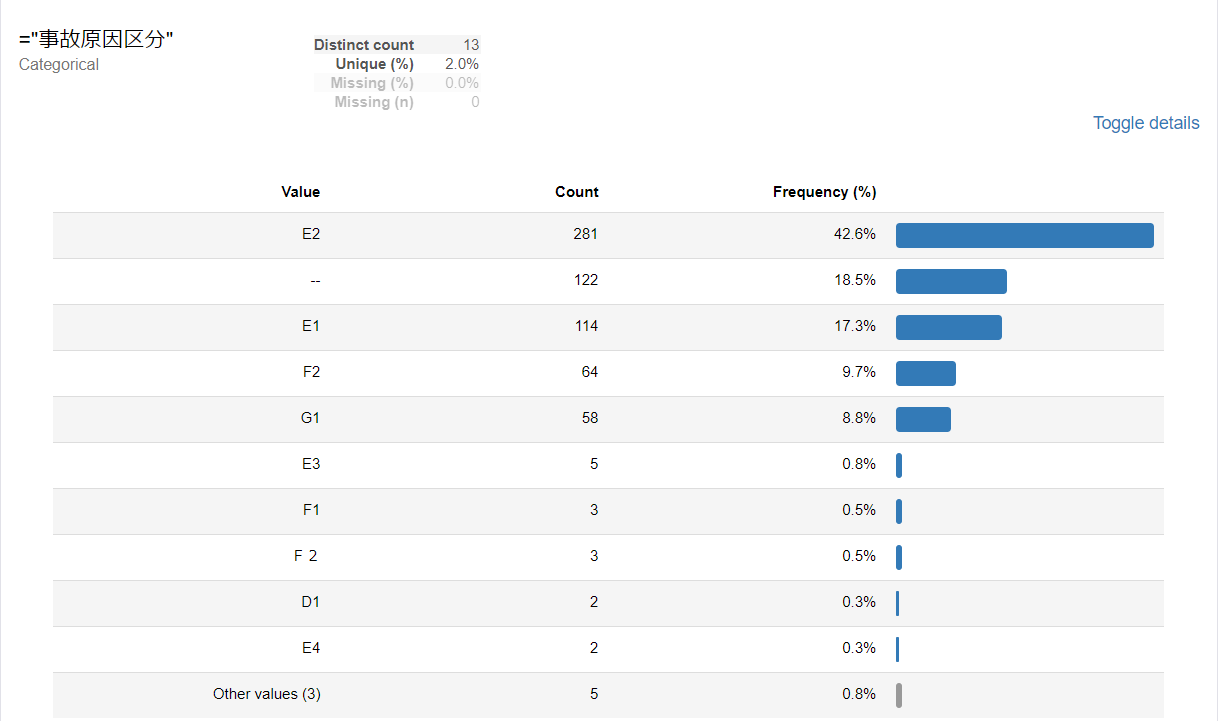
品名
火災事故のデータ全体と比較して、ストーブ(石油・電気)が原因となる場合は、死亡事故となる割合が高いことが分かります。
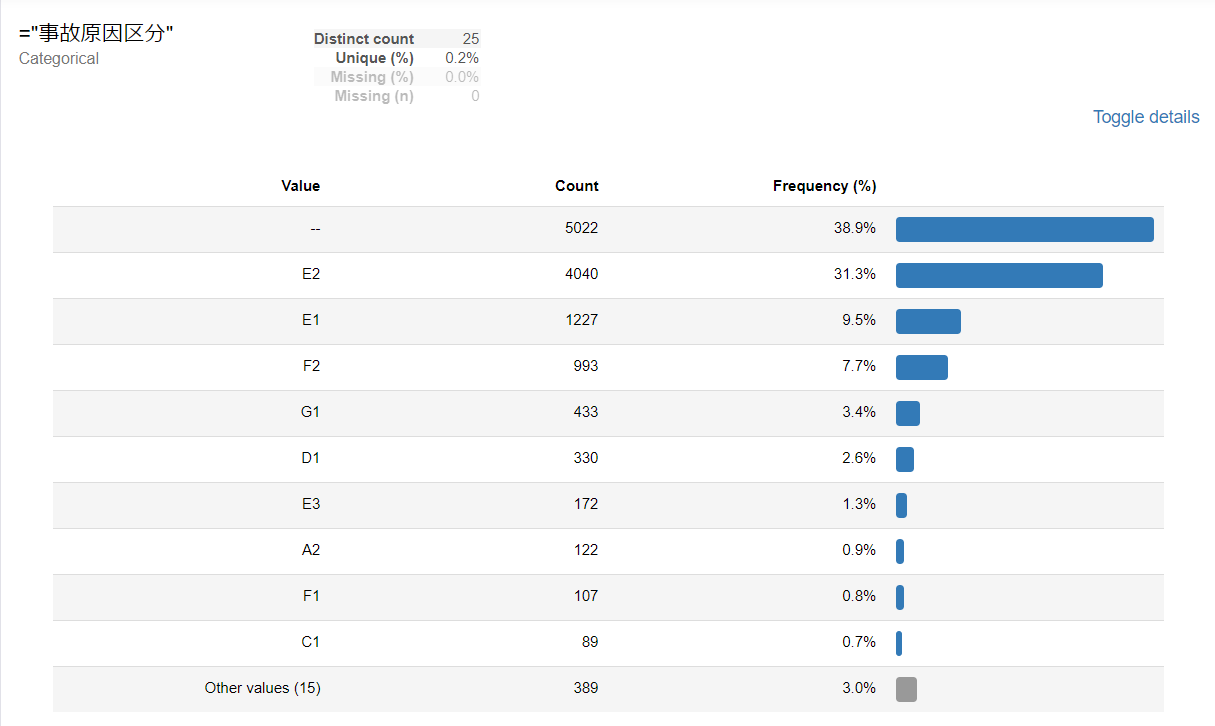
事故原因区分
1位 E2 消費者の不注意
2位 -- 記載なし
3位 E1 消費者の誤使用
4位 F2 その他製品に起因しないか、又は使用者の感受性に関係するもの
5位 G1 原因不明
6位 E3 消費者の設置・施工不良
7位 F1 製品には起因しない偶発的事故
8位 F2 その他製品に起因しないか、又は使用者の感受性に関係するもの
9位 D1 業者の設置・施工不良
10位 E4 消費者の修理不良
:
通常の火災事故と同様、消費者の責任で発生する死亡事故が多いことが分かります。
事故原因(自由記述)
文章中から重要なキーワードを抽出した後に、重要なキーワードをユーザー定義語に追加。ユーザー定義語を考慮した形態素解析結果をWordCloudを用いて可視化します。

火災による死亡事故事例の事故原因のキーワードを可視化しました。
次いで、対象データ全体と比較して、出現頻度の高かったキーワードを分析します。
# 対象データ全体と比較した、死亡事故事例での出現頻度の割合をrate_dictに登録
rate_dict = {}
for k,v in freq_dict.items():
if k in freq_dict_d:
if freq_dict_d[k] >= 5: # 死亡事故での出現頻度5回以上のキーワードに限定
rate_dict[k] = freq_dict_d[k] / v * 100
# 出力
for k, v in sorted(rate_dict.items(), key=lambda x: -x[1]):
print(str(k) + ": " + str(v))
<出力結果>
併用: 100.0
死亡: 88.88888888888889
不自由: 71.42857142857143
ウレタン: 62.5
着衣: 54.285714285714285
電気ストーブ: 42.10526315789473
繊維状: 40.0
反射: 38.46153846153847
ベット: 38.46153846153847
ハロゲンヒーター: 35.714285714285715
反射板: 33.33333333333333
寝具: 31.666666666666664
布団等: 30.434782608695656
寝室: 30.0
ベッド: 29.629629629629626
居間: 28.07017543859649
接近: 26.31578947368421
繊維: 25.64102564102564
ハンガー: 24.137931034482758
毛布: 24.074074074074073
:
ウレタンなどの燃えやすい素材に引火するケース、着衣に火がつくケース、寝室で火災が発生するケースなどで通常より死亡事故が発生しやすいことを予想させる結果となりました。
まとめと今後
NITEの製品事故データから、火災事故に関するデータを抽出し、集計・分析しました。
再発防止に関する情報が比較的少なかった(特に消費者起因の事故について)ものの、事故の状況、原因、対策が登録されている、非常に興味深いデータでした。
今後は、NITE以外がソースの事故・事件データを収集・集計・分析していきたいと思います。
参考
NITE:事故情報の検索
https://www.nite.go.jp/jiko/jiko-db/accident/search/?m=jiko&a=page_index
TermExtractで手軽にキーワード抽出 for Python
https://qiita.com/EastResident/items/0cdc7c5ac1f0a6b3cf1d
Janomeのユーザー辞書を作る(python,自然言語処理,エネルギー基本計画)
http://eneprog.blogspot.com/2018/08/janomepython.html
データの集計は、ExcelよりPython使ったほうが100倍早い(pandas-profiling, pixiedust)
[https://qiita.com/pocket_kyoto/items/8d1fbcbca5d5dfd1dbd5]
(https://qiita.com/pocket_kyoto/items/8d1fbcbca5d5dfd1dbd5)
「停電」に関するツイートをpythonで収集して、WordCloudで可視化してみた
https://qiita.com/pocket_kyoto/items/0f43c9fdce87bddd31cf
補足
方法1.TermExtractライブラリを用いた重要キーワードの抽出
こちらのサイトの方法に従い、TermExtractを用いて重要キーワードを抽出しています。
↓元サイトより多少変更を加えたソースで重要キーワードを抽出しました。
import termextract.janome
import termextract.core
import collections
def ExtractKeyWord(series): # Series型のデータを入力として、重要キーワードを出力する
sentence_list = series.values.tolist()
sentence_list = map(str, sentence_list)
all_sentence = "\n".join(sentence_list)
t = Tokenizer()
tokenize_text = t.tokenize(all_sentence)
# 複合語を抽出し、重要度を算出
frequency = termextract.janome.cmp_noun_dict(tokenize_text)
LR = termextract.core.score_lr(frequency,
ignore_words=termextract.mecab.IGNORE_WORDS,
lr_mode=1, average_rate=1
)
term_imp = termextract.core.term_importance(frequency, LR)
data_collection = collections.Counter(term_imp)
importance_dict = {}
for cmp_noun, value in data_collection.most_common():
importance_dict[termextract.core.modify_agglutinative_lang(cmp_noun)] = value
return importance_dict
importance_dict = ExtractKeyWord(df_fire["=\"事故原因\""])
【importance_dictの中身】
Key, Value
当該製品, 26158422.319493666
製品, 8655061.583882578
使用, 1931641.2818950107
電源コード, 1568525.4953621936
ガスこんろ, 1404777.3039520064
:
重要キーワードの多くが複合名詞であることに着目し、文章中で頻出する複合名詞を抽出しています。
方法2.形態素解析器janomeへのユーザー定義語の追加
こちらのサイトの方法に従い、形態素解析器janomeに、ユーザー定義語を追加した上で、形態素解析を実行します。
↓元サイトより多少変更を加えたソースでユーザー定義語ファイルを作成しました。
import csv
default=["-1","-1","1000","名詞","一般","*","*","*","*","%s","*","*"]
datas = []
for k,v in importance_dict.items():
data = [k] + default
data[10] = k
datas.append(data)
with open("user_keywords.csv", "w") as f:
writer = csv.writer(f, lineterminator="\n")
writer.writerows(datas)
上記のスクリプトを実行することで、ユーザー定義語を、janomeで読み込み可能な形式でファイル出力することができます。
↓ user_keywords.csv
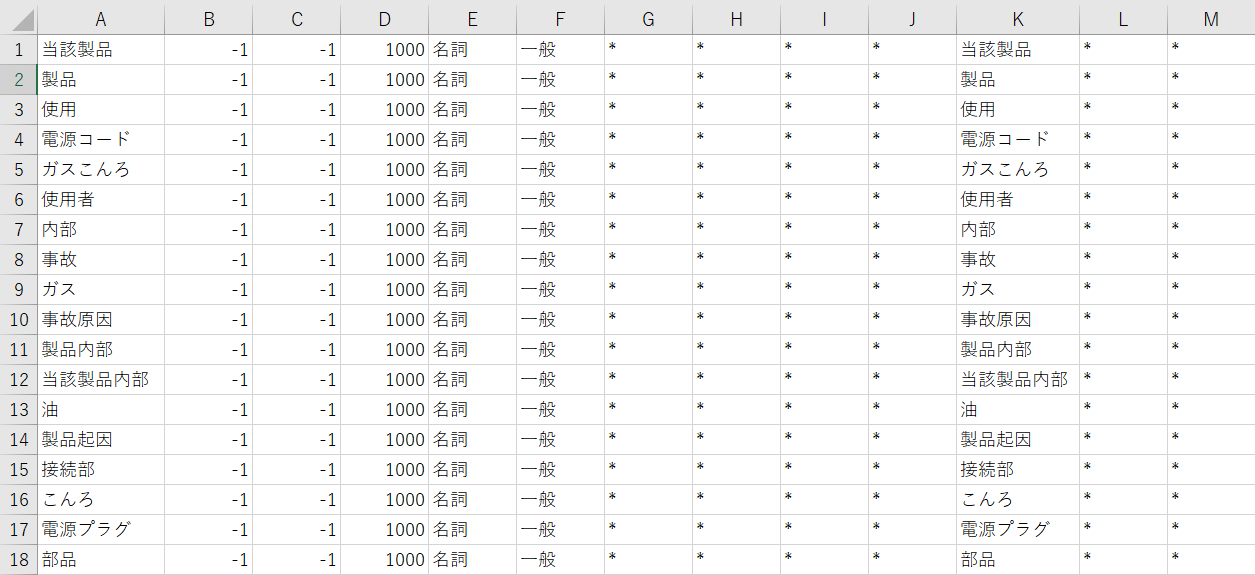
生成したユーザー定義語ファイル(user_keywords.csv)は、janomeのTokenizerを定義する際に、ファイルパスを指定することで読み込み可能です。
ユーザー定義語を考慮した形態素解析の一例を下記に示します。
sentence_list = df_fire["=\"事故原因\""].values.tolist()
sentence_list = map(str, sentence_list)
t = Tokenizer("user_keywords.csv", udic_enc='cp932')
for text in sentence_list:
words=[]
tokens = t.tokenize(text)
for word in tokens:
if word.part_of_speech.split(',')[0] == "名詞":
words.append(word.surface)
print(words)
【wordsの出力例】
['事故', '原因', '当該', '製品', 'ファンモーター', 'の', '製造工程', '上', '不具合', 'ファンモーター', '内蔵', '電子部品', 'チップコンデンサー', 'ショート', '短絡故障', '過大電流', '電気', '回路', 'こと', 'ファン', 'モーター', '発熱', '発火', '出火', 'もの']
['当該', '製品', 'ガスボンベ取付け部', 'の', '固定', 'ネジ', '締め付け', '不良', 'ため', '取付け部', 'すき間', 'ガス', '漏れ', 'バーナー', '火', '引火', '火災', 'もの', '推定']
['当該', '製品', 'AC', 'アダプター', 'DCプラグ樹脂', '燃剤', '使用', '赤リン', 'の', '耐水性', '不具合', 'ため', '湿度', 'の', '影響', 'リン酸', '端子', '金属', '銅', '溶出', '端子', '間', '短絡', '異常', '発熱', '出火', 'もの', '推定']
:
一部分離している箇所はあるものの、「ファンモーター」「製造工程」「チップコンデンサー」「短絡故障」など、通常の形態素解析では出現しない複合名詞の重要キーワードを考慮して解析できていることが分かります。
検索例
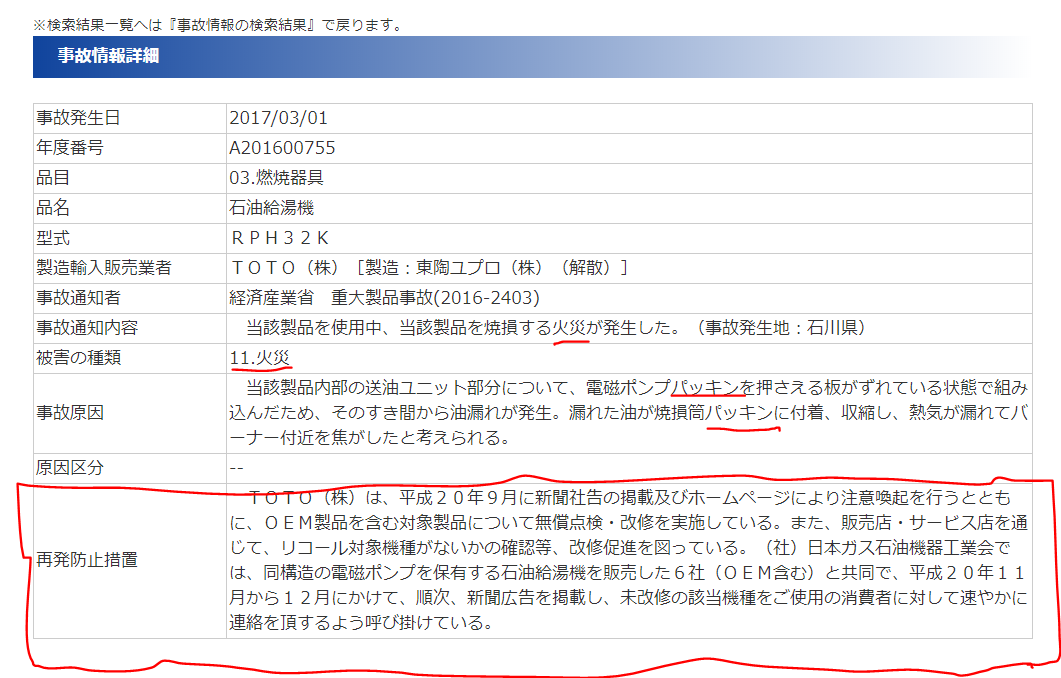
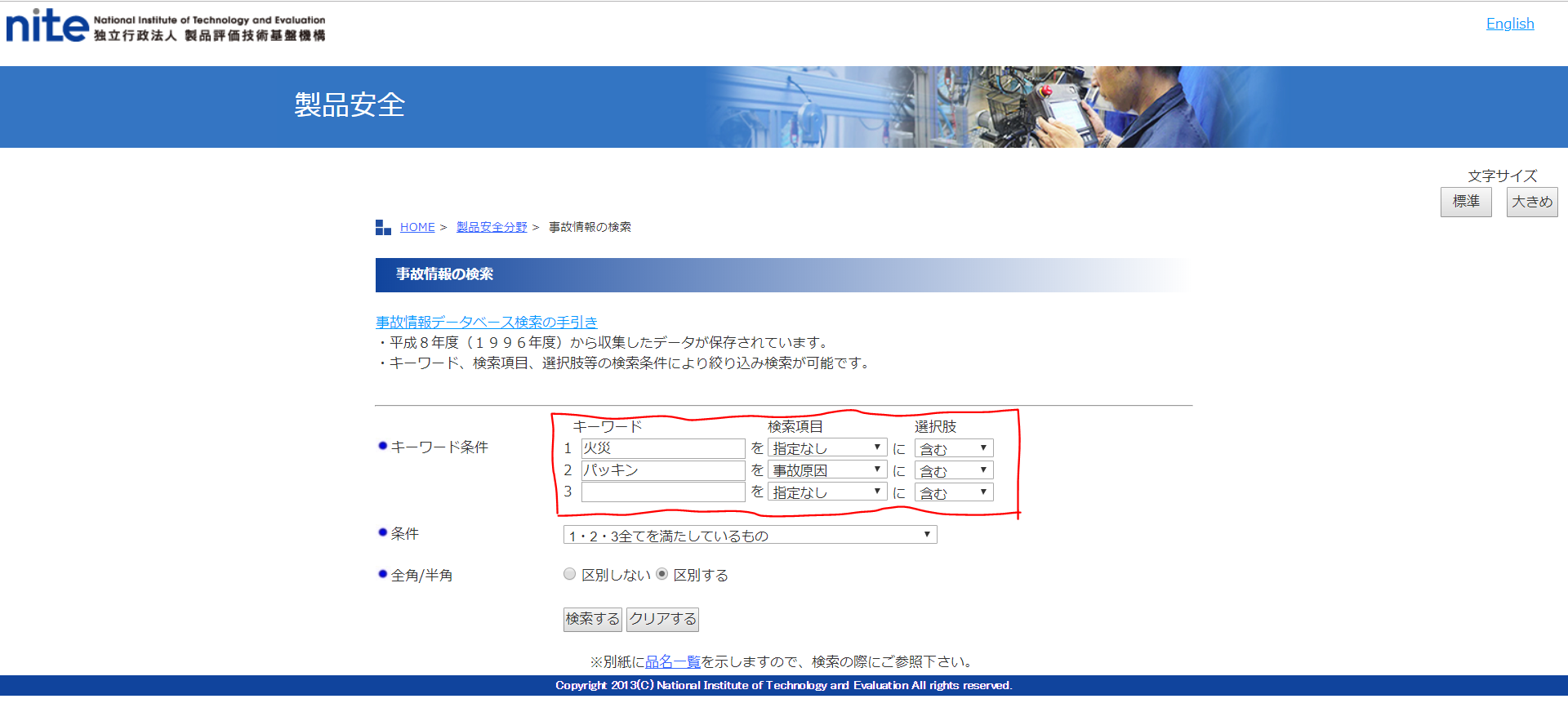
例えば、「火災」という文字列を含む製品事故の中から、「パッキン」という単語を事故原因に含む事例をNITEのHPから一覧取得してみます。
↓このように検索条件を入力すると、
↓このように条件を満たす検索結果(281件)が得られます。
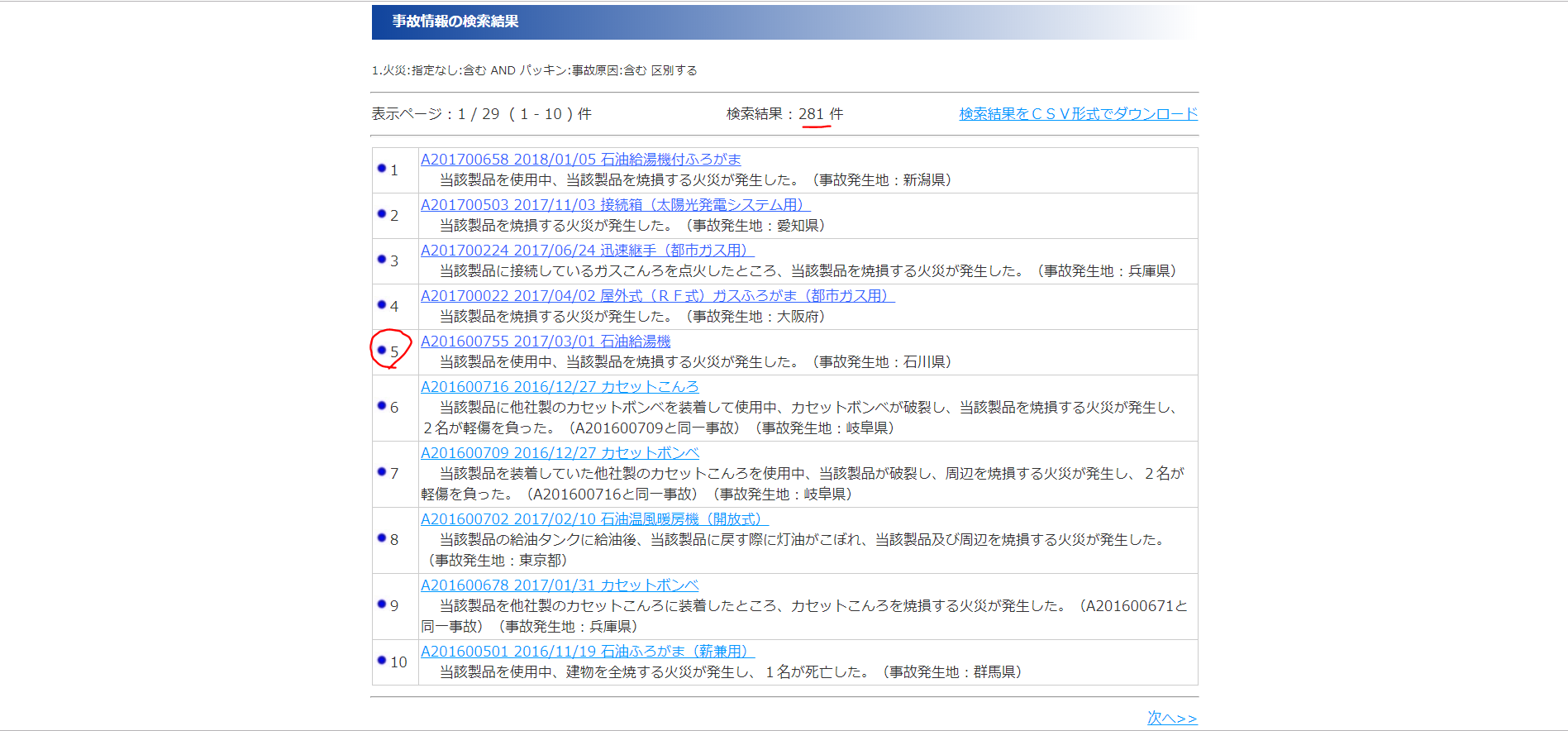
↓検索結果の1つを表示すると、具体的な事例を確認できます。例えば、「パッチン」を事故原因に含む事例の再発防止措置を確認できます。