Pythonのpandas-profilingと、pixiedustの2つのライブラリを使うと、データの集計・グラフの作成が、感動的なほど早く終わることを実感したので共有します。
Excelでデータ集計・グラフ作成した場合と比較すると、体感で100倍くらい早く終わります(誇張ではなく)
Pythonで爆速でデータ集計する方法(体感所要時間:5分)
前提:
以下の環境が整備されていることは、前提とします。
- Pythonのインストール(約30分)
- データ分析に必要な各種ライブラリのインストール(約30分)
→numpy, matplotlib, pandas, jupyter など
→Anacondaをインストールすれば、Pythonと各種ライブラリは同時にインストールされます。
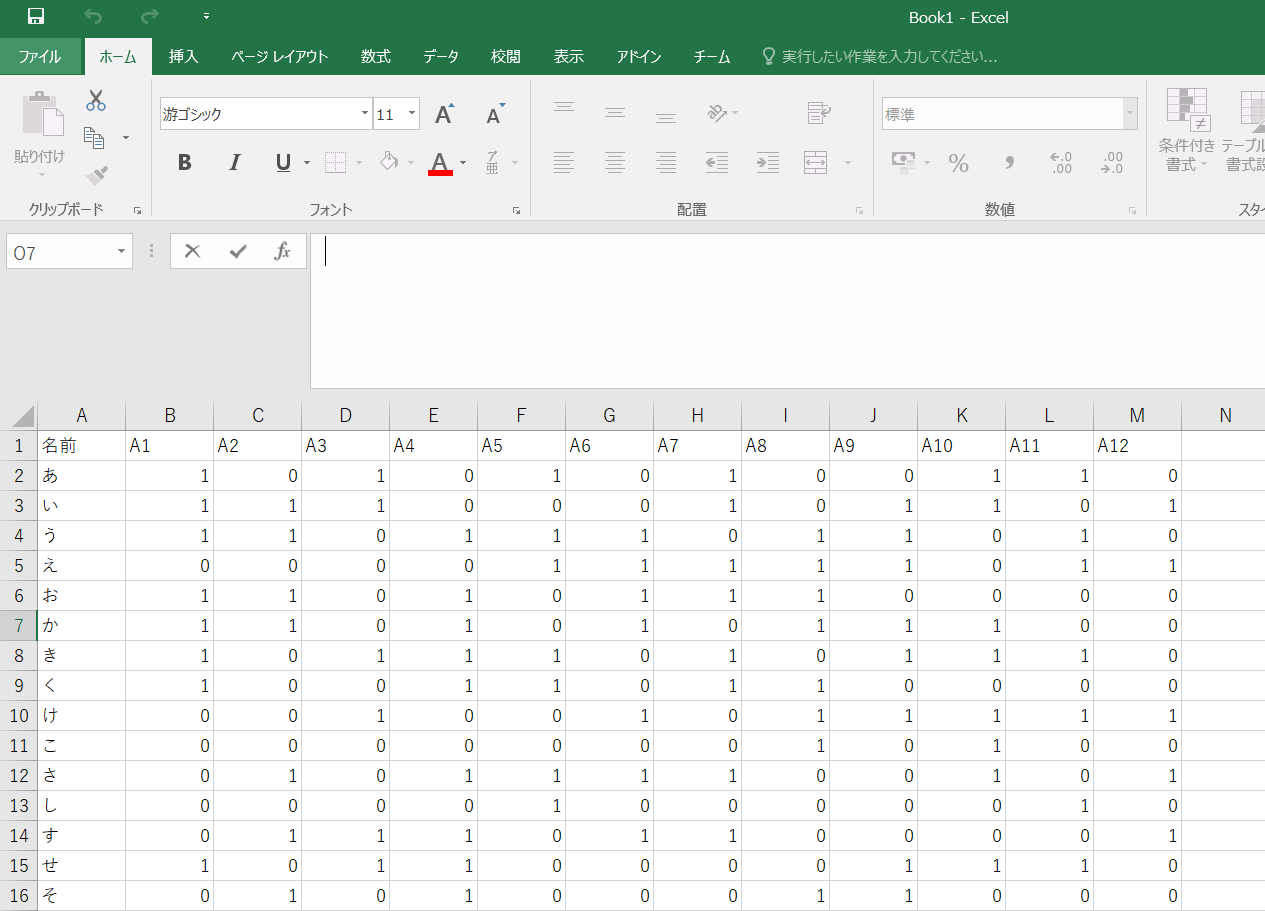
また、集計対象である、テーブル形式のcsvデータは既に用意されているものとします。
↓Excelで表示すると、こんな感じのデータのことです。
手順:
①pandas-profilingと、pixiedustをインストールする(約2分)
pipでインストールできます。
特に面倒な感じはなく、一発で入りました。
pip install pandas-profiling
pip install pixiedust
②jupyter notebookを開く(約1分)
csvファイルがあるディレクトリにコマンドラインで移動して、
jupyter notebookを開きます。
※ちなみに、jupyter notebookを使うか否かでも、体感所要時間は3倍くらい違う
cd (移動先ディレクトリ)
jupyter notebook
jupyter notebookを開くと、こんな感じです↓
個人的には、以下の機能が通常のpythonと比較して、特に便利だなと感じます。
- ブロック毎に処理を実行できる
- 通常のpythonだと、実行するたびにデータを読み込むことになり、時間がかかる
- グラフの描画結果などが残る
- 描画したグラフなどが、notebook上で残るので、分析の流れを忘れにくい
- Markdownでメモが書ける
- 考察など書いておくと、後で見返しやすい
- HTML、PDFなどで容易に共有できる
- jupyterをインストールしていない人にも、簡単に結果共有できる
③数行スクリプトを書く → 実行(約2分)
以下のコードを書いて実行すると、結果が出力されます。
import pandas as pd
import pandas_profiling as pp
import pixiedust as px
df = pd.read_csv('hoge.csv')
pp.ProfileReport(df)
px.display(df)
信じられない人もいるかもしれませんが、これでお終いです。
これだけで、研究室での発表、顧客との商談、社内での対策会議を行うのに十分な情報を準備できます。
この手順を踏むだけで、以下の集計結果が得られます。
結果:
pandas_profilingにより得られる結果
①Overview(概要)
データの素性に関する概要情報が得られます。
以下のように出力されます。
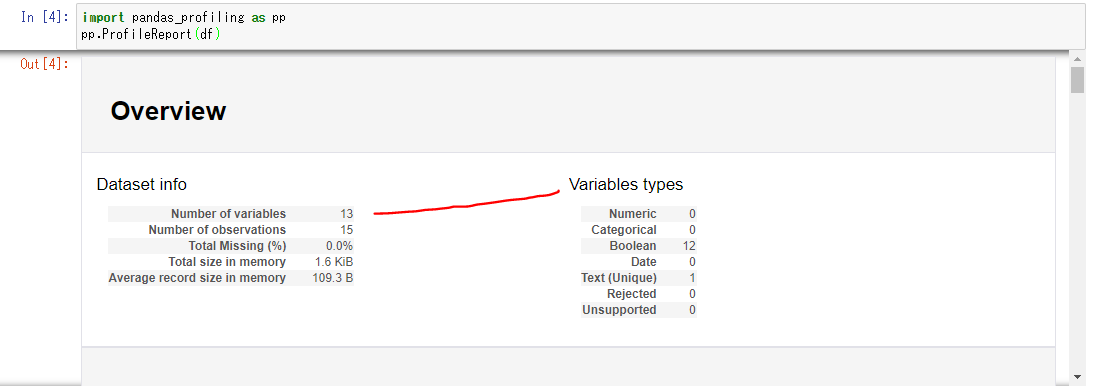
■Dataset info
| 項目名 | 内容 |
|---|---|
| Number of variables | 変数の数 |
| Number of observations | サンプル数 |
| Total Missing(%) | 欠損率?(詳細不明) |
| Total size in memory | データサイズ |
| Average record size in memory | 1レコードあたりのデータサイズ |
「Variables types」には、自動判定された各変数の型が出力されます。
また、入力データによって、以下のようなWarningが出るケースがあります。(手元で確認したケースのみ)
・A1列とA2列は、相関係数が非常に高い(≒相関係数1)
・A3列は、全体の3%のデータが欠損である
・A4列は、記載が多岐に渡る(105のユニークな値が存在する)
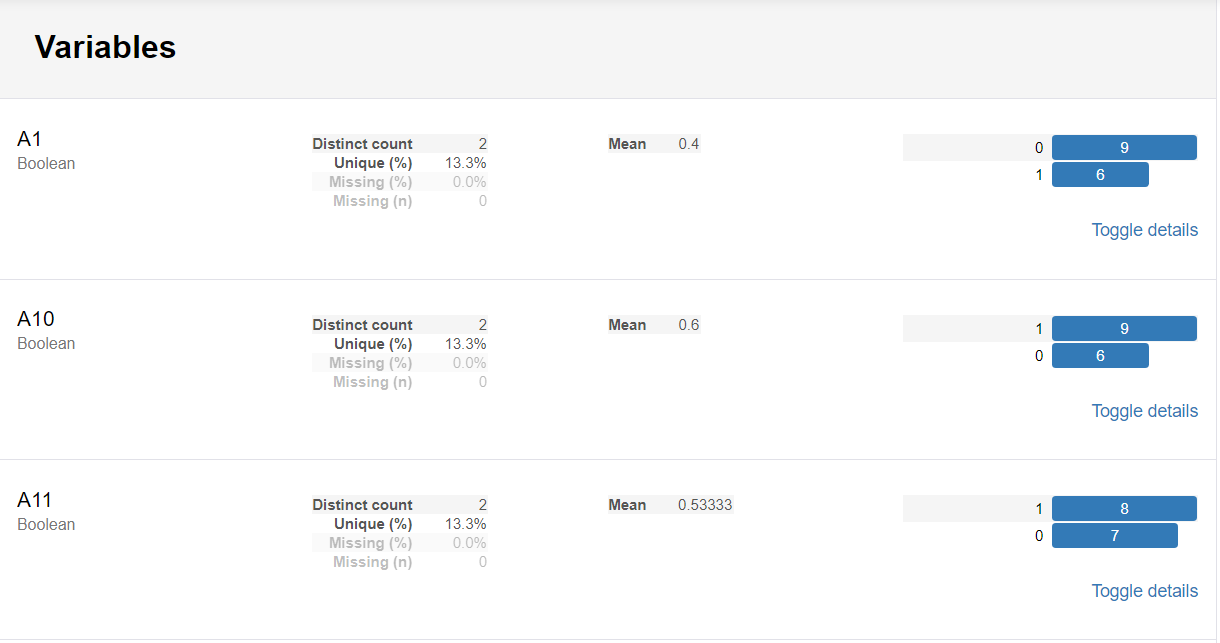
②Variables(変数ごとの統計量)
以下のように、クラス数、平均値、頻度分布などが集計されます。
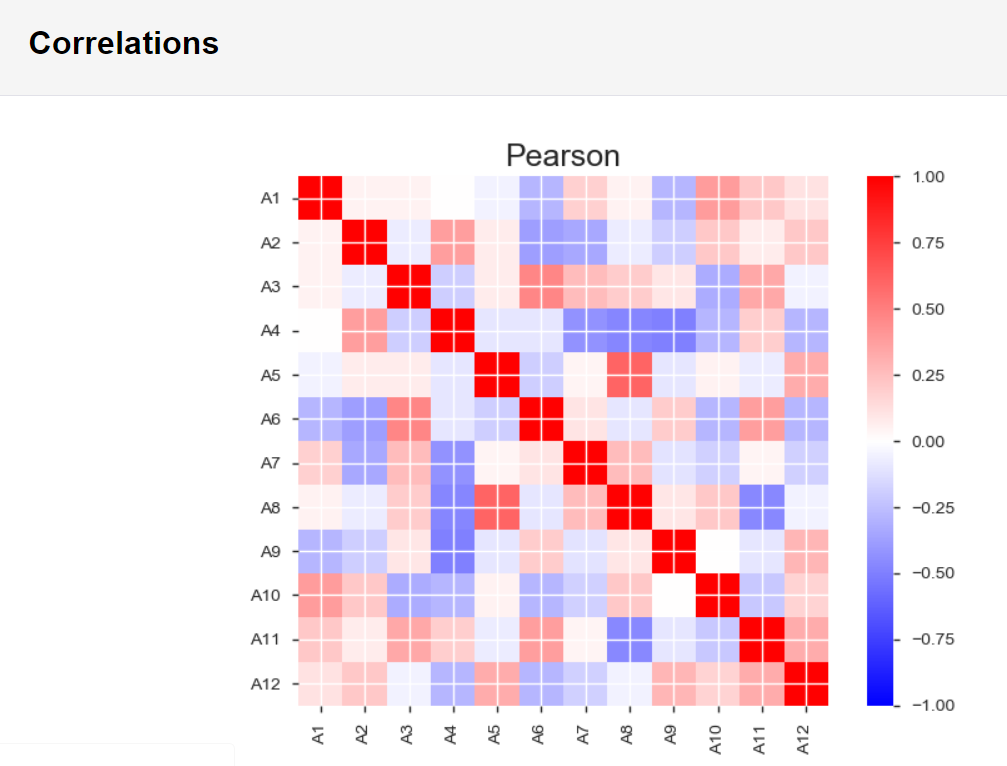
③Correlations(変数ごとの相関関係)
以下のように、変数の相関関係が可視化されます。対角線は自己相関なので、赤(=1)となります。
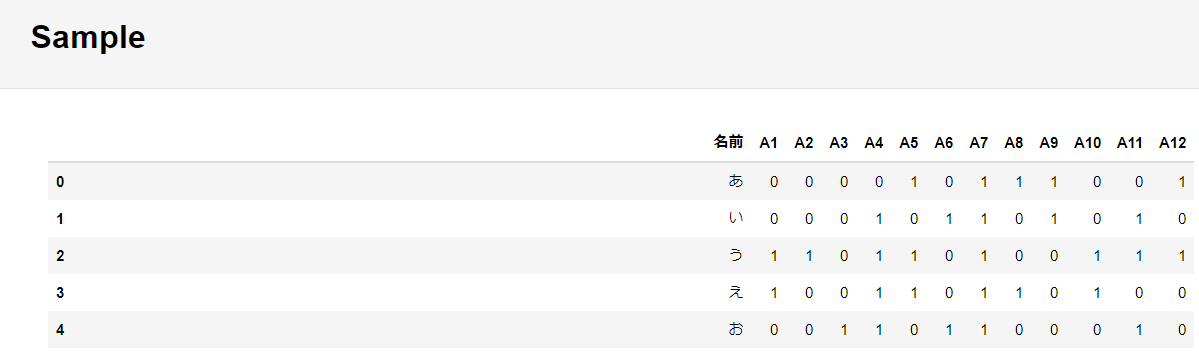
④Sample(変数ごとの相関関係)
以下のように、5件のサンプルデータの実際の入力値が出力されます。
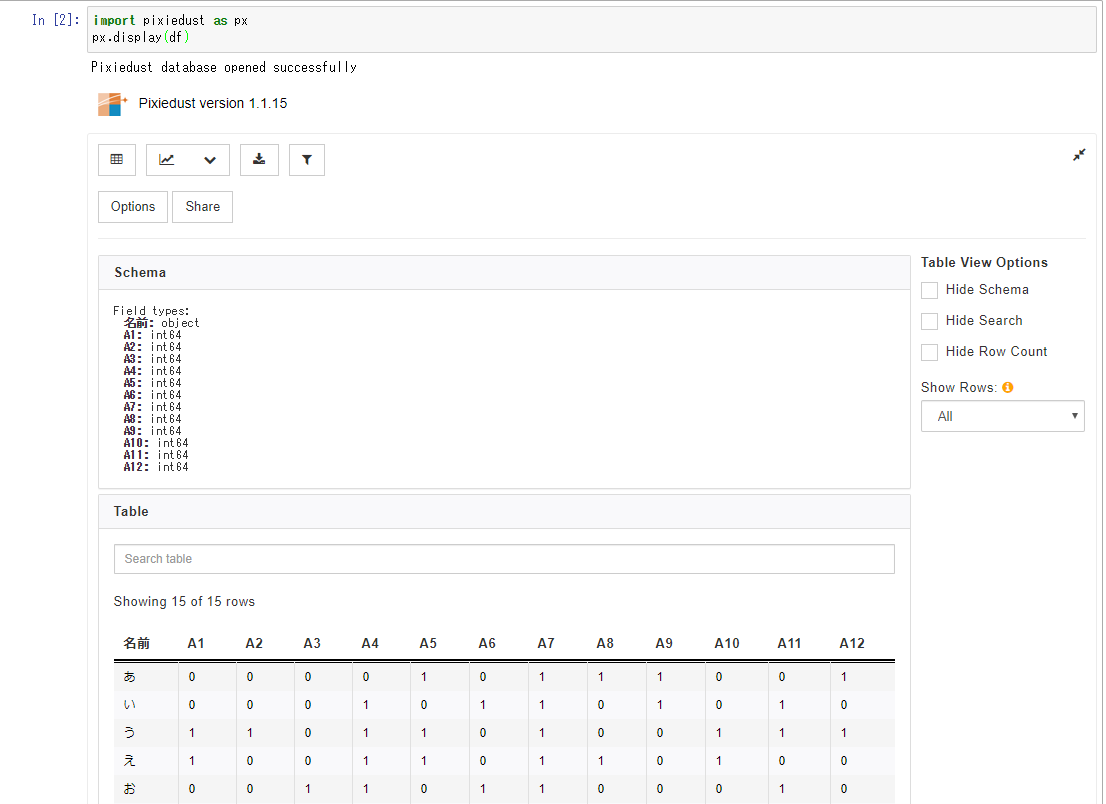
pixiedustにより得られる結果
①Sheme(変数型)とTable(データテーブル)
以下のように、各変数の型と、データテーブルが初期では表示されます。
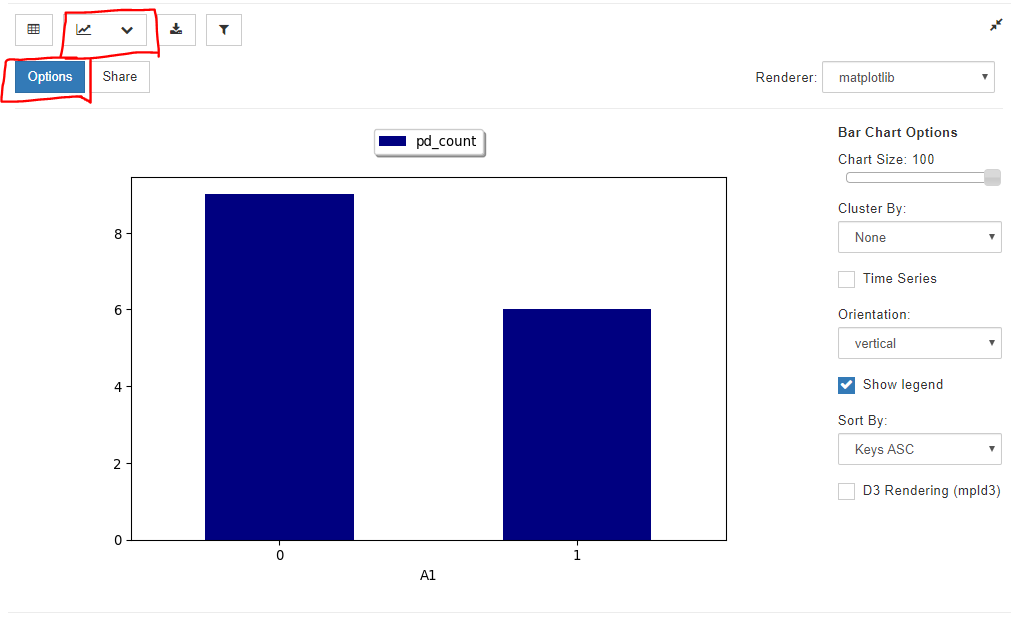
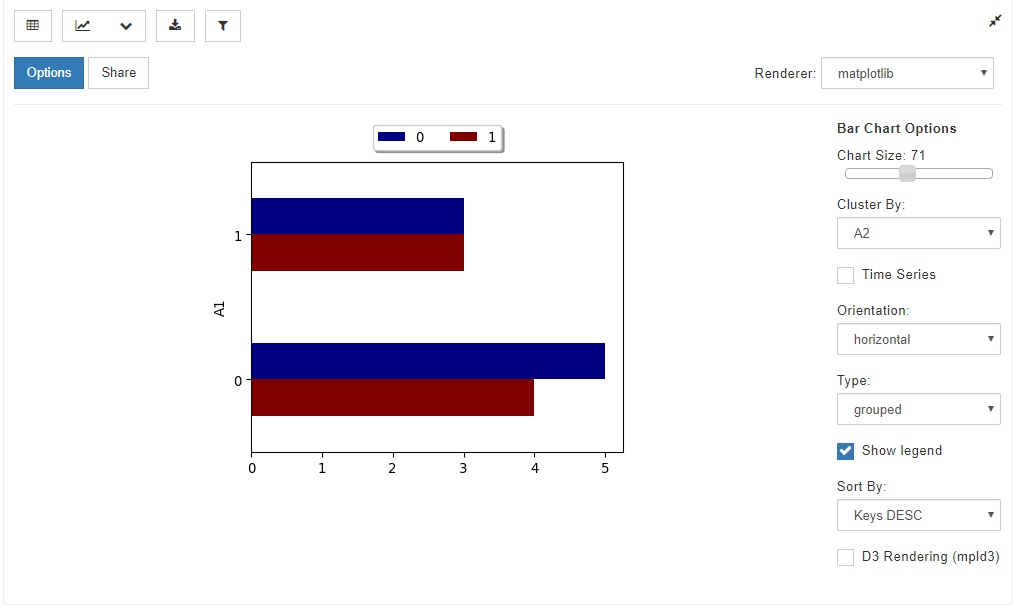
②棒グラフ
グラフアイコンで、Bar Chartを選択し、Optionsで集計したい変数を選択すると、棒グラフを作成できます。
例えば、以下のような操作が可能です。
- グラフのダウンロード
- 他の変数でのフィルタリング
- グラフ領域の大きさのコントロール(Chart size)
- 他の変数でのグルーピング(Cluster by)
- グラフ表示方向(Orientation)
- 凡例有無
- 昇順、降順の指定(Sort by)
この操作の組み合わせにより、以下のようなグラフも作成可能です。
③折れ線グラフ
グラフアイコンで、Line Chartを選択し、Optionsで集計したい変数を選択すると、折れ線グラフを作成できます。
※今回用意した仮のデータセットでは、折れ線グラフで表示すべき変数が無いため、例示は割愛します。
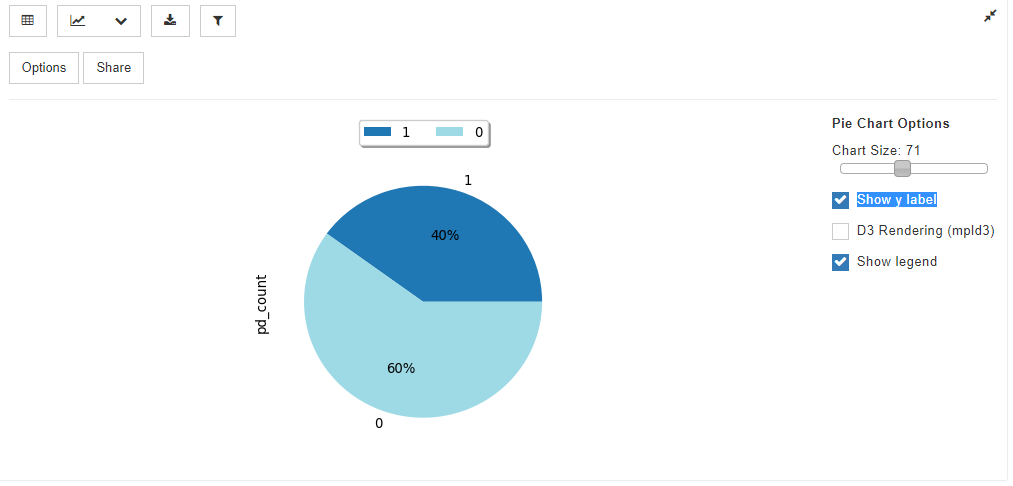
④円グラフ
グラフアイコンで、Pie Chartを選択し、Optionsで集計したい変数を選択すると、円グラフを作成できます。
⑤散布図
グラフアイコンで、Scatter Plotを選択し、Optionsで集計したい変数を2つ選択すると、散布図を作成できます。
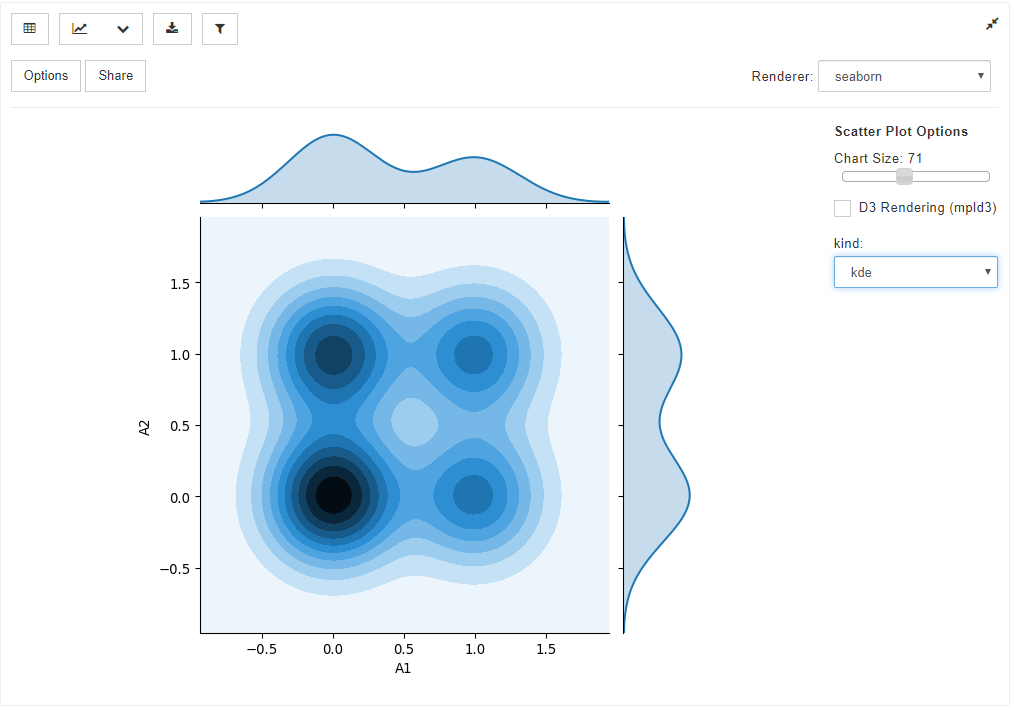
通常の散布図だけでなく、上記のような点の密度を考慮した散布図も容易に作成可能です。
⑥ヒストグラム
グラフアイコンで、Histgramを選択し、Optionsで集計したい連続値の変数を選択すると、ヒストグラムを作成できます。
※今回用意した仮のデータセットでは、ヒストグラムで表示すべき変数が無いため、例示は割愛します。
⑦地図上へのプロット
グラフアイコンで、Mapを選択し、Optionsで集計したい変数を選択すると、マップ上にデータをプロットできます。
※この機能については、未検証です。
以上、爆速でデータ集計できました!
但し、ケース・バイ・ケースで他の方法が良いこともあるので、この方法以外も紹介し、感覚的なメリット・デメリットを共有したいと思います。
Pythonで地道にデータ集計する方法(体感所要時間:3時間)
前提:
以下の環境が整備されていることは、やはり前提となります。
- Pythonのインストール
- データ分析に必要な各種ライブラリのインストール
手順:
①jupyter notebookを開く(約1分)
説明は割愛
②pandas等で、データを読み込み、各変数それぞれでグラフ描画(1変数あたり約5分)
ここでは、df["hoge"] ~ のように1変数ずつ取り出して、
value_counts()関数とか、matplotlibとか使って可視化していきます。
メリット:
- グラフの描画に、こだわりたい場合には向いている
デメリット:
- データの変数が多い場合、確認がとても面倒。
BIツールでデータ集計する方法(体感所要時間:30分 ※但し有料)
前提:
- BIツールを利用できる環境にあること
- 無料試用版は2週間~2ヶ月程度で、その後は有料版に移行するケースが多い
- まあまあ高価な場合が多い(年間10万円以上)
手順:
①BIツールで、データを読み込む(約1分)
経験上、サクッとできます。
②BIツールでグラフ描画・集計(1変数あたり約1分)
このあたりも、直感的に操作できるUIが備わっているので、割とサクッとできます。
但し、1変数ずつ自分でグラフ描画・集計する必要がある場合が多いです。
メリット:
- 割と簡単に集計・可視化ができて、グラフの見映えの調整も比較的容易
- 集計・可視化結果を組織内で共有したい場合などには、非常に便利
デメリット:
- BIツールは便利に使えるレベルのものは大体有料
- BIツールに慣れていないと操作に意外と手こずる
Excelでデータ集計する方法(体感所要時間:10時間)
手順:
①シートにデータを貼り付ける(約1分)
説明は割愛
②集計用のテーブルを作成し、数式群を書く(1変数あたり約10分)
VLOOKUPとかSUMIFとかCOUNTIFとか。。
ザ・職人芸
③集計用のテーブルより、グラフを作成する(1変数あたり約10分)
値の選択、凡例の指定、色調整など、操作が妙に複雑。
ヒストグラムや散布図が絶望的に作りにくい。
苦行。。
メリット:
- 官公庁系では、Excelグラフの需要が高い
- 見映えに相当こだわりたい時に、カスタマイズが比較的容易(?)
- ピボットテーブルや、VBAを使いこなせれば多少楽(?)
デメリット:
多いので割愛
まとめ
Pythonライブラリのpandas-profiling, pixiedustを使った集計・可視化を是非試してみてください!