教師有りLDAモデルを使って、何か面白いことができないか調べてみたいと思います。
今回は、そもそも日本語での教師有りLDAモデルの解説記事が少なかったようなので、参考になったVikash Singh氏の英語版の記事の流れに沿って、半教師有りLDA(ガイド付きLDA)を解説していきたいと思います。
【元記事】
「How our startup switched from Unsupervised LDA to Semi-Supervised GuidedLDA」
LDA(トピックモデル)とは何か?
ニュース記事のような文章を、「政治」「スポーツ」「科学」などのトピックに分けるモデルを、トピックモデルと呼びます。LDAはトピックモデルを構築するための手法の一つです。
以下で例を見ていきます。

この6つの文章を読み、以下のようにトピックに分類することは、人間にとっては難しくないはずです。
- 1.と5.は「オバマ大統領」「選挙」「ナレンドラ・モディ(インドの首相)」などの単語を含むことから「政治」トピック
- 2.と4.は「クリケットチーム」「ワールドカップ」「FIFA」などの単語を含むことから「スポーツ」トピック
- 3.と6.は「アインシュタイン」「ノーベル賞」「物理」「生物」などの単語を含むことから「科学」トピック
それでは、コンピューターには、どのように教えれば良いでしょう?
この時に用いられるモデルがトピックモデルであり、その中でもLDAは最も人気のある方法の一つです。
通常のトピックモデルは、教師なし学習に分類されます。
トピックモデルでは、「出現する単語群が、どのようにグルーピングされるか?」を、大量の文章から学習します。
先程の例の場合、以下のような3つのグループに単語群が分かれることを期待します。

ちなみに、トピックモデルは教師なし学習であるため、「政治(politics)」「スポーツ(Sports)」「経済(Science)」のようなトピックの名称は自動で付与されません。学習後に人手で付与することが一般的です。
一旦、このような分類が完成すれば、新規の文章に自動でトピックを付与することが可能になります。
例えば、以下のような文章があったとします。

この文章には「ノーベル賞」という単語が含まれるので、「科学」トピックであると特定することが可能になります。
注: 「単語群が、どのようにグルーピングされるか?」を学習する際には、ベイズ確率が用いられます。ある単語$ w $が与えられた時に、トピック$ t $に所属する確率$ p(t|w)$を推定するのです。詳細は、参考[2][3]などをご覧ください。
ガイド付きLDAとは何か?
トピックモデルは教師なし学習モデルです。
教師なし学習でトピックを生成する場合、本来分離したい「宇宙(Space)」と「IT(Tech)」というトピックが1つに結合してしまう、あるいは本質的に同じ内容のトピックが複数に分離してしまう、などの問題が生じます。
先ほどの例に倣うと、以下のような状況となります。

問題が生じた時、教師有り学習では、問題の原因に関してデバック検証することが可能です。
特徴量生成、学習に用いたデータ量、損失関数、距離の測定方法、サンプリングなど原因を切り分けて検証することができます。
しかし、教師なし学習では、問題の原因に関するデバックは非常に困難となります。
この問題を解決するために、予約語(seed word)をあらかじめトピックに設定するというアイディアを、ガイド付きLDAでは採用しています。これにより、予約語の所属確率がトピック毎で分離するように学習させることで、教師なしLDAのモデル構築をガイドすることができます。
例えば、以下のようにトピック毎に予約語を設定します。

このガイド付きLDAは、非常に単純で直感的なアイディアですが、先行研究は非常に少ないようです。
予約語と類似の概念を提唱している論文はあります(参考[4])。
どうすれば、LDAをガイド付きLDAにできる?
ここでは、ガイド付きLDAへの拡張方法を極力シンプルに説明します。
興味のない人は、ガイド付きLDAの使い方まで飛ばしてください。
通常のLDAでは、単語を発生させるトピックが**潜在的に(Latent)存在し、複数のトピックの寄与により文章(=単語の集合)が生成されるものと考えます。学習前の段階では事前情報がないため、それぞれの単語はトピックにランダムに割り当てられている(Allocation)**と仮定します。このとき、初期状態での単語のトピックへの割り当ては、事前分布として用いられるディリクレ分布(Dirichlet)のパラメータ$ \alpha $でコントロールされます。$ \alpha $の値が大きい場合、単語のトピックへの割り当ては均一となり、$ \alpha $の値が小さい場合、割り当てに歪みが発生します(補足[1])。
以降では、初期状態での単語のトピックへの割り当てが均一な場合を例に説明します。
初期状態の後、LDAは単語のトピックへの所属確率を、非常に単純な方法で単語一つずつ順に推定します。
仮に「Blue Origin」という航空宇宙企業の名が新たに単語として加わったとしましょう。LDAでは、「Blue Origin」という単語のトピックへの所属確率を推定する際、他の単語のトピックへの所属確率は全て正確に推定されているものと仮定します。そして「Blue Origin」と共起する単語のトピックへの所属確率から、「Blue Origin」のトピックへの所属確率を推定します。この時、「Blue Origin」という単語は「NASA」や「SpaceX」と共起することが予想されるため、「Blue Origin」は「NASA」や「SpaceX」と同一のトピックに所属する単語であることが学習されます。このプロセスを、着目する単語を順に変えながら収束するまで十分な回数繰り返します。
ガイド付きLDAでは、初期状態での単語のトピックへの割り当てを恣意的に設定できるようにしています。
予約語により何が変わるか?
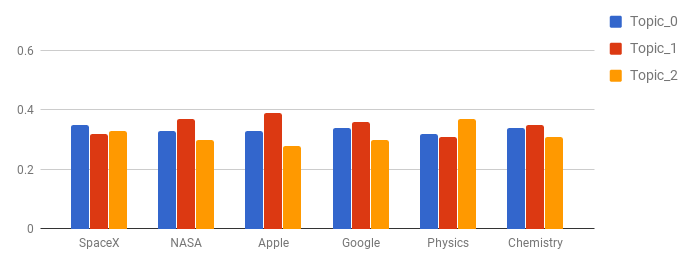
「NASA」「SpaceX」という単語が、トピック0に収束するように予約語を設定してみます。予約語の信頼度(seed_confidence)のパラメータを0~1で変更することで、予約語に対する重みが調整可能です。以降では、seed_confidenceを0.1に設定した場合で説明します。この時、予約語に設定される重みが10%増となります。
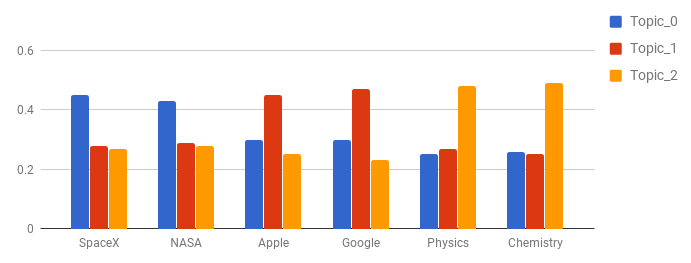
この例では、「NASA」「SpaceX」をトピック0に、「Apple」「Google」をトピック1に、「Physics」「Chemistry」をトピック2に設定しています。
こうすることで、「NASA」「SpaceX」およびそれと共起する語がトピック0に収束しやすくなることが前述のLDAの説明からイメージできるかと思います。これはトピック1、トピック2についても同様です。
ガイド付きLDAの使い方
ガイド付きLDA(GuidedLDA)は、オープンソースのPythonライブラリとしてGitHubに公開しています。ライセンスは、Mozilla Public License 2.0です。
このライブラリは、pipでインストールが可能です(補足[2])。
pip install guidedlda
ライブラリの利用方法は極めて単純です。
seed_topicsという辞書型の変数のキーにword_id、値にtopic_idをそれぞれ代入し、model.fit()で学習するだけです。
seed_topics = {
'NASA': 0, 'SpaceX': 0,
'Apple': 1, 'Google': 1,
'Physics': 2, 'Chemistry': 2,
}
model.fit(X, seed_topics=seed_topics, seed_confidence=0.15).
seed_confidenceを0~1の範囲で指定し、seed_topicsの辞書を用意し、document term matrix形式の学習用データを用意すれば動かすことができます。
利用方法の詳細は、GuidedLDAの公式ドキュメントに記載があります。
まとめと今後
Vikash Singh氏の英語版の記事の流れに沿って、教師なしLDAとガイド付きLDAの2つを解説しました。
次回は、実際にGuidedLDAのライブラリを用いた分析に取り組んで見たいと思います。
補足
[1]
ディリクレ分布は、多項分布の共役事前分布です。
ある単語$ w $が所属するトピック$ t $が確率的に決まると考えると、サイコロを振った時にtの目が出る確率を表現するような分布(=多項分布)と同じ構造を持つことが分かります。但し、サイコロの例とは異なり、単語$ w $のトピック$ t $への真の所属確率は、トピック毎に偏りがあることが予想されます。
この状況下で、限られた情報(学習データ)を用いてトピック$ t $への所属確率の分布(=多項分布)を推定することが求めれます。限られた情報で、多項分布の真の形状をそれっぽく表現することができるのが、多項分布の共役事前分布であるディリクレ分布です。
共役事前分布は、データ数が増えた時に、より真の分布形状に近づくように更新可能という嬉しい性質も持っているため、解析上の利便性がとても高いのが特徴です。
[2]
Anaconda3をWindows10にインストールした状態で、pip installしてみましたが、私の環境では初め上手くいきませんでした。しかし、pipのバージョンを9.0.1から18.0にアップグレードしたら上手くいきました。
参考:
[1] How our startup switched from Unsupervised LDA to Semi-Supervised GuidedLDA
https://medium.freecodecamp.org/how-we-changed-unsupervised-lda-to-semi-supervised-guidedlda-e36a95f3a164
[2] Topic modeling made just simple enough.
https://tedunderwood.com/2012/04/07/topic-modeling-made-just-simple-enough/
[3] 自然言語処理による文書分類の基礎の基礎、トピックモデルを学ぶ
https://qiita.com/icoxfog417/items/7c944cb29dd7cdf5e2b1
[4] Incorporating Lexical Priors into Topic Models
http://www.aclweb.org/anthology/E12-1021
[5] Guided LDA(GitHub)
https://github.com/vi3k6i5/guidedlda