低レイヤを知りたい人のためのCコンパイラ作成入門 (以下 コンパイラブック) を一通り読んでCコンパイラを作ってみました。
この本はまだ完全でなく(2020/09/01現在)、例えば構造体の実装の説明などは文章としては存在せず、この本の参照実装である chibicc を写経がてら作っていきました。
(実際には今現在進行中の @rui さんの Cコンパイラ作成のオンラインコースを始めます の参加者のみに現状は公開されているchibiccよりもうちょっと改善されたcコンパイラ実装が参照実装だそうです)
もともと構文解析とかはちょっと興味があったりして、qiitaでも
みたいな記事は書いていたんですが、あんまりややこしいパーサーは書いたことがなくて、アセンブラとかはほぼ初心者な状態ではじめました。
で、6月頃から初めてコツコツやっていたんですが、お盆休みとこの土日でガッとやりきってセルフホストできるところまで出来て久々に色々理解できた感があったので非常にいい経験でした。(メインは写経でしたけど・・・)
コードは
においています。
方針
作るにあたって下記のような方針をきめました。
-
コンパイラブック に説明がある部分
- 基本的には写経はせず本の内容を理解して自分で書いてみる。どうしてもわからないところは chibicc のソースを理解できるまで読んでみる
-
コンパイラブック に説明がない部分
chibicc自体が教育用に 意味のあるコミット単位になるようにrebaseされてコミットをおいやすくしてくれているのでコンパイラブックの内容を一通り実装して以降はchibiccのコミットログを追うことにしました。- まずchibiccのコミットメッセージを見て内容を予想する。
- その予想に従ってコードを書いてみる
- 取り敢えず実装出来た場合
- コミット内容を確認してみて全然検討違いだったらコミット内容を読み解いて再実装する
- コミットログを見ても全然わからない場合(やっぱりこのケースが多かった)
- コミット内容を確認して、理解してから写経する
- 理解した内容は極力コメントに残していく
結果
結果としては、写経成分多めではあるもののすごい為になったと感じています。
やっていて記憶に残っているものをざっと書くと
- Cの変数や型の宣言の異様さがパーサを書くとよくわかった
- Cの構文上ローカル変数とグローバル変数は似てるが、実装は全然違うことがわかった。特に初期化式。
- 変数やtypedefされた型の定義とスコープの管理がよくわかった。
- 関数呼び出しの裏でスタックフレームがどういう風に構築されているかわかった
- C可変長引数の挙動がやっとわかった
- 全然思ってたのと違ったswitch文のパース
- x86-64のアセンブラが結構読めるようになった
- スタックマシンの考え方が理解できるようになった
などなど、大小ありますがすごく勉強になりました。以下、上記の補足を。
(ただし、コンパイラ一般とかではなく、今回作ったコンパイラに関しての補足になります)
Cの変数や型の宣言の異様さがパーサを書くとよくわかった
これは本当に難しかったです。パーサのコードを読み解くのが本当に大変でした。
この辺のコメントです。
このパーサを書くことでわかったcのおもしろ宣言たち。下記は全部合法でコンパイルも実行もできます。
// 下記のxは全部ただのlong型
int long long x;
long int long x;
long long int x;
long long x;
// typedefは何回どこに現れても一つのtypedefとみなされる。
// 下記のtypedefは long を hoge という型で使えるようになる宣言
typedef typedef long typedef hoge;
// typedef struct { ... } piyo; 的な書き方をすることが多いと思うが、 typedefの位置はどこでいいため下記のような書き方もできる。
struct hoge {
int x;
} typedef piyo;
// 何も型を指定せずにtypedefに識別子を与えるとint型をその名前でも使えるようにする、という意味になる
// 下記は int を foo という型で使えるようになる宣言
typedef foo;
// これに至ってはほとんど意味がなくて、不完全型の無名構造体へのポインタ変数hogeを定義している。
// sizeof(hoge)で8(64bit環境)バイトがかえってくるぐらいしか意味がない。
struct *hoge;
行き当たりばったりで増築されてきたcコンパイラの実装が仕様となって今の形に、とruiさんが言っていたのがよく分かる感じでした。
Cの構文上ローカル変数とグローバル変数は似てるが、実装は全然違うことがわかった。特に初期化式。
cの構文的にはグローバル変数と、ローカル変数の構文は下記のようによく似ています。
// グローバル変数
int global_var1 = 123 + 456;
int *global_var2 = &global_var1;
void func1() {
// ローカル変数
int local_var1 = 234 + 567;
int *local_var2 = &local_var1;
}
ただ、生成されるアセンブラは全然異なり
-
グローバル変数
- .bss .dataセクションに置かれる
- 初期化式がある場合 .data セクション、ない場合(=ゼロ初期化)は .bss に置かれます。その差は
https://github.com/pocari/compilerbook-9cc/blob/first-self-host/codegen.c#L833
ということのようです。
- 初期化式がある場合 .data セクション、ない場合(=ゼロ初期化)は .bss に置かれます。その差は
- コードが実行される前に初期化されるので、初期化式はコンパイル時に決まる式のみ設定可能
- 定数式の計算(配列の初期化式とか構造体の初期化式も内容が定数式なら可能)
- 別のグローバル変数へのポインタ
- 初期化式は単にそのセクションに静的に設定されるバイト列
- グローバル変数の初期化式は、変数に代入する、というよりも、その変数のメモリイメージを生成してやる、という感じのため、例えば構造体のアラインメントによってメンバーとメンバーの間に空いた隙間を明示的にゼロ埋めする必要があります。
https://github.com/pocari/compilerbook-9cc/blob/first-self-host/parser.c#L704
の辺りのコメントに残しました。
- グローバル変数の初期化式は、変数に代入する、というよりも、その変数のメモリイメージを生成してやる、という感じのため、例えば構造体のアラインメントによってメンバーとメンバーの間に空いた隙間を明示的にゼロ埋めする必要があります。
- .bss .dataセクションに置かれる
-
ローカル変数
- スタック上にその関数のベースポインタからのオフセットで管理される
- なので、生成したアセンブラからはローカル変数名は全部消えていて、ただのrbpから何バイトの位置にあるか?だけで管理されます。
- 初期化式は、変数宣言の後にその初期化式を代入するようなコードが生成される
例)
int x = 12; int y = 34;というコードがあったら、単に、
int x; { x = 12; } int y; { y = 34; }というコードにコンパイルされます。
ちなみに、この初期化式のパースが個人的にはとても大変で理解するのにすごく時間がかかりました。
https://github.com/pocari/compilerbook-9cc/blob/first-self-host/parser.c#L1618
の辺りのコメントにあるようなことを読み解いてわかるようになりました。でも、ここはちょっとまだ怪しい。 - スタック上にその関数のベースポインタからのオフセットで管理される
変数やtypedefされた型の定義とスコープの管理がよくわかった。
https://github.com/pocari/compilerbook-9cc/blob/first-self-host/parser.c#L5
の辺りのコメントに残しました。
これはコンパイラの実装によって大きく異なると思いますが、chibicc でのパース中のスコープとかの管理はリンクリスト(chibiccは本当にリンクリストをいろんなところでうまく使っている)をうまく使ってわかりやすかったです。
パーサの中にlocals, globals, var_scope, tag_scope という変数、スコープ管理の変数をつかって管理されています。
-
locals
現在パース中の関数の中にある変数(関数の仮引数も含む)をスコープとは関係なく全部保持するリンクリスト。なお、仮引数の左から順、関数の出てきた順の逆順のリンクリストで管理されています。 -
globals
こちらはあまり凝ったことはしていなくて単にグローバル変数を保持しています。 -
var_scope
- この変数が現在のスコープから見えるローカル変数やtypedefの定義、グローバル変数をリンクリストで管理していて、新しいスコープが作られるたびにその時点までのvar_scopeを保存しておいて、スコープが終わったら保存していたvar_scopeで上書きすることで、その間につくった変数たちをスコープから外すことができます。なるほどと思いました。
-
tag_scope
- こちらはvar_scopeと同じような考え方で struct/enum のtag名のスコープ管理をしています。
関数呼び出しの裏でスタックフレームがどういう風に構築されているかわかった
これは基本的なことだと思いますが、アセンブラとかあまりしらないので、なるほどーということばかりでした。
- プロローグ/エピローグで rbp, rspをどういう風に管理してスタックフレームを作り出しているか
- ローカル変数をどのように管理しているか
- 可変長引数の場合に、関数側、関数呼び出し側、コンパイラがどのように協調してスタックを使っているか(後述)
などがわかるようになりました。
C可変長引数の挙動がやっとわかった
printfとかで使われているやつですね。今までおまじない的に、 va_list va_start とかを使っていましたが、コンパイラを作ることで挙動がよくわかりました。
しかもこの可変長引数の実装はなんと chibicc では動かない状態でコミットされている(今進行中のcコンパイラの実装では動いているそうです)のがわかりました。
どうしてもsegvするので、twitterで聞いてみたり、gccでアセンブラをはいて挙動を確認したりしてやっと動くようになりました。これは本当に大変でした。
動きとしては、通常のcコンパイラと今回のコンパイラでは挙動が少し違います。
-
普通のコンパイラ
va_startは関数ではなくてマクロで実装されてることがおおいようでコンパイラ組込み(つまりコンパイラごとに実装が違う)の__builtin_va_start関数に展開されます。 -
今回作ったコンパイラ
プリプロセッサの実装がないので、va_startも普通のcの関数になっていて、 其の中で今回のコンパイラの組込み関数__builtin_va_startを呼ぶ形になっています(chibiccがそうなっていた)
で、なぜ組み込み関数なるものを使うかというと、 可変長引数を使うために引数の数やスタック上のどの部分に可変長引数があるかを va_list 構造体に設定するのですが、可変長引数の場合のみ特別なスタックのレイアウトをコンパイラが設定しているため、コンパイラでそのスタックのメモリレイアウトにあわせて va_list 構造体に値を設定する必要があるからです。
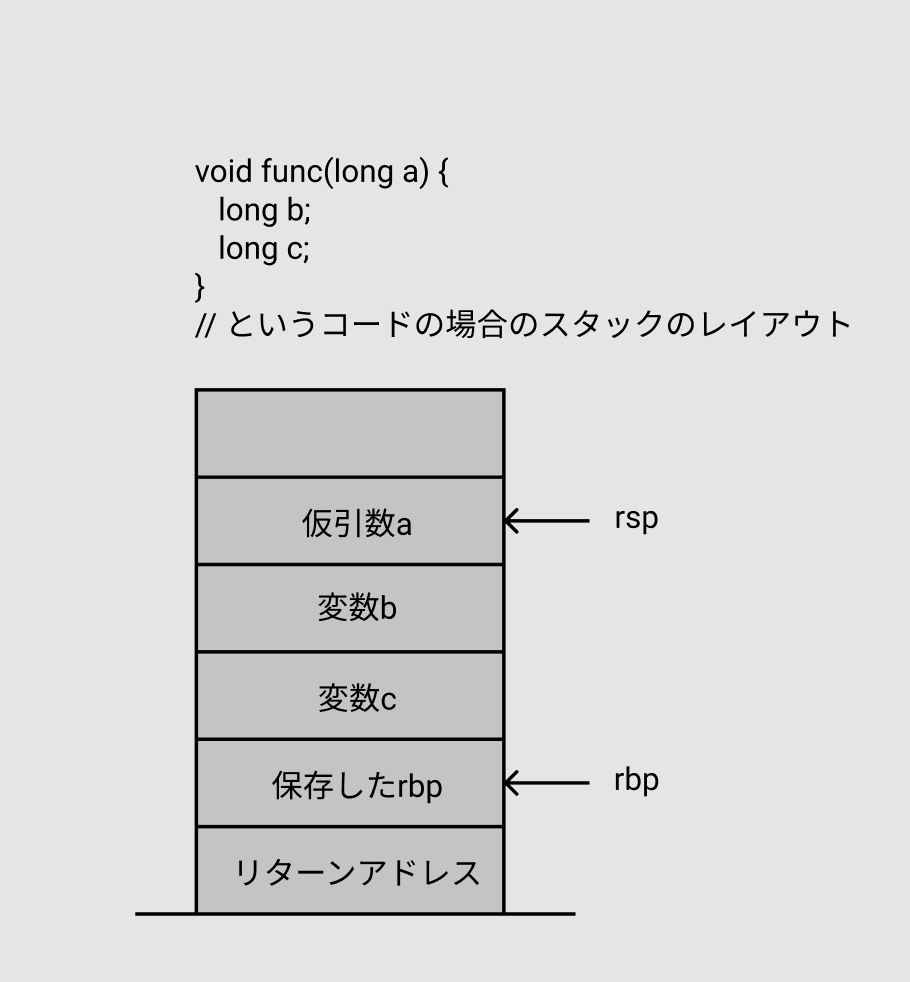
普通の関数のスタックフレームと、可変長引数引数を使う関数のスタックフレームはそれぞれ下記のようになります。(上がスタックの伸びる方向==アドレスの小さい方向)
-
普通の関数
-
可変長引数の関数
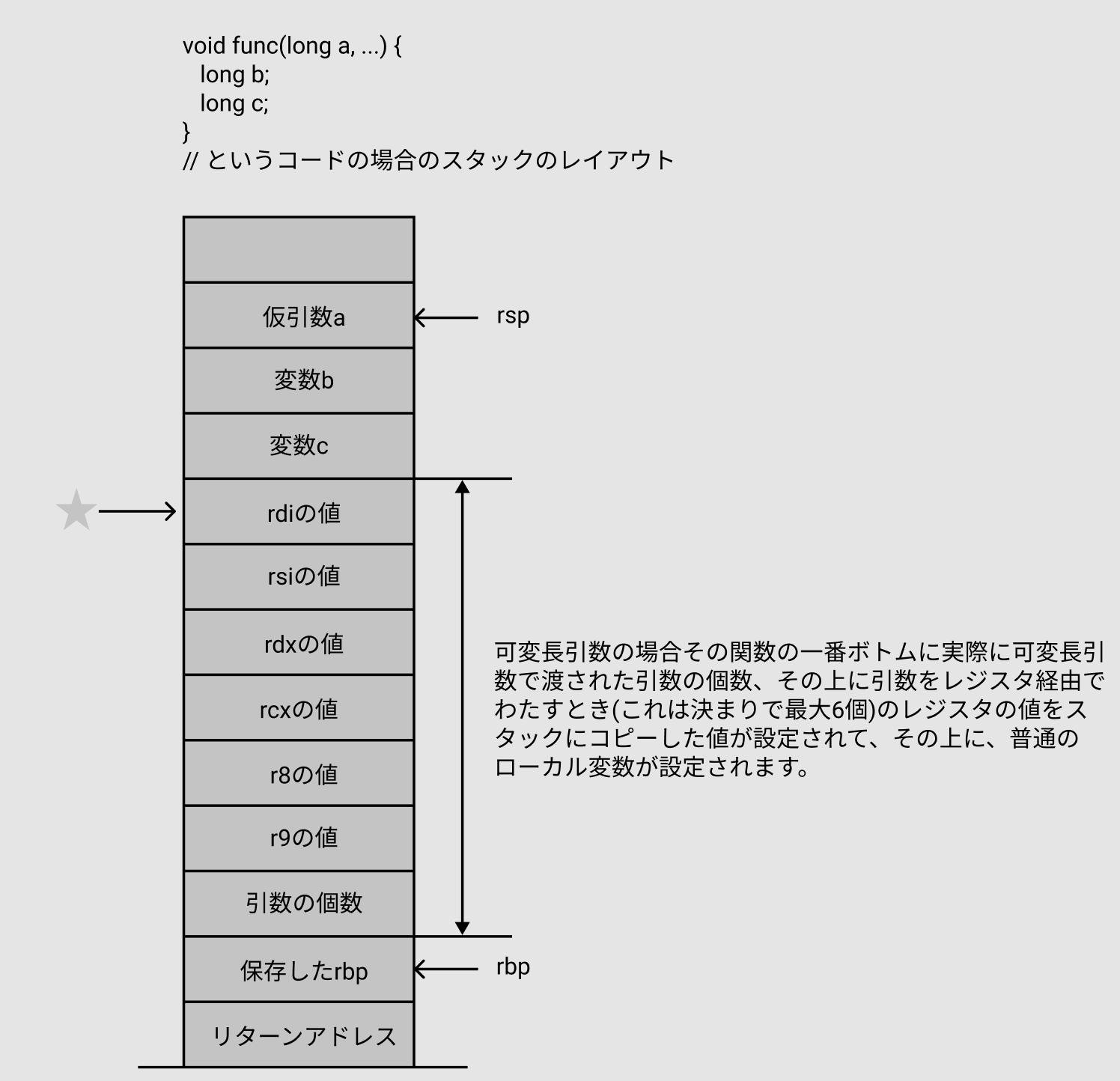
可変長引数の場合はスタックがこうなっていることを前提に va_start により、 va_list が設定されると期待します。
va_listとは下記のような構造体です。
struct va_list {
int gp_offset;
int fp_offset;
void *overflow_arg_area;
void *reg_save_area;
};
今回のコンパイラは関数の引数はレジスタ渡し可能な最大6個までなので(1)、全部で何個引数があるかと、レジスタの値がコピーされたスタックの先頭のアドレスがどこか?というのがわかればスタックからたどることが出来ます。
それに必要なのが,gp_offset, reg_save_areaで、それぞれ下記を設定します。
- gp_offset
- 引数の個数のうち、何個目までが実引数か?要は
...の前に何個引数があるのか * 8バイト を設定します。
例えば、void func(int a, int b, ...);のような関数の場合、...の前に2つの変数があるので、 2 * 8 =16 byteを設定します。
- 引数の個数のうち、何個目までが実引数か?要は
- reg_save_area
- レジスタの値をコピーしたスタック領域の先頭アドレス・・・・つまり、上記の図でいう
☆のアドレスが設定されます。
- レジスタの値をコピーしたスタック領域の先頭アドレス・・・・つまり、上記の図でいう
- fp_offset
- これは浮動小数点を使ってない場合は、理由はよくわかりませんが
48を固定で入れておくと良さそうだったのでそうしました。
- これは浮動小数点を使ってない場合は、理由はよくわかりませんが
さて、ここで躓いたのですが、 今回 va_start はマクロでなく、通常の関数で定義されています。すると、 ある可変長引数の関数xのなかで va_start 関数を呼ぶと関数xのスタックフレームの上に、更にva_startの新しいスタックフレームが作られてしまいます。
そのva_startの中でva_startを呼んだ関数x側のスタック領域を読んでva_listに設定しないといけません。このため、va_startのrbpが指しているアドレスに入っている、呼び出し元関数xのrbpのアドレスを取得してこれをもとに計算することにしました。
(今思えばva_list自体を組込みにしてもよかったのかもしれない・・・)
以上を考慮して動くようになったのが下記の部分です。
https://github.com/pocari/compilerbook-9cc/blob/first-self-host/codegen.c#L443-L465
gccが吐く可変長引数のアセンブラとかは、浮動小数点の考慮などもあり、もっと複雑になっています。
全然思ってたのと違ったswitch文のパース
switch 文は chibicc でも随分あとになってから実装されるのですが、当初僕は switch の後に 条件式 (expr) が来て { の後に case const_var: が来て・・・というパースが行われるのかと思っていましたが、全然違いました。
switch文の構文はbnfでいうと
switch "(" expr ")"
です。なんと case も default もありません。そう、通常よく見るc言語のswitch文とは関数の中身を構成する複数の文(stmt)の連なりの中にたまたま 実は switch(expr) の後に ブロックステートメントが一つあるだけということです。
また、そのブロックステートメントの中にたまたま case や default があり、たまたまbreakなどがある、ただそれだけです(もちろんパーサ自体がswitch以外の部分でcaseなどがでてきたらエラーにはします)
なので、下記のようなコードも(警告は出ますが)gccでも、Cのコードとしては合法で実行も可能です。
// 中身のないswitchも書ける
switch(hoge);
// switchの後にたまたまブロックステートメントがくるだけなので、任意のブロックステートメントを書くことができる
// switch文中のcase10: のラベルまでの式も一応コード生成されますが、常にswitchの後にhogeの値によって、case10とかのラベルにジャンプするコードが生成されるので、全く通ることはありません。が、合法です。
int hoge = 10;
switch (hoge) {
int x = 0;;
printf("hello, world\\n");
case 10:
printf("case 10\\n");
break;
case 20:
printf("case 20\\n");
break;
}
x86-64のアセンブラが結構読めるようになった
出力がアセンブラなので当然ですが、ジャンプするコードとか最初よくわからなかったですが、ずっと書いてたらよくわかってきました。
でも、いまでもmov系の演算対象のサイズを考慮した処理とx86-64特有の事情で、特別にこの命令をつかわないといけない系というのはまだ良くわからないです。
スタックマシンの考え方が理解できるようになった
今回のコード生成部分はスタックマシンです。例えば x = 1 + 2; というコードがあると
- まず 変数x のアドレスをスタックに積みます。
- 次に 1 をスタックに積みます。
- 次に 2 をスタックに積みます。
- スタックの先頭から2つ数値を取り出して足したものをスタックに積みます。
- スタックの先頭から値Xを取り出し、さらにもう一つ取り出した値を変数のアドレスとみなして、そのアドレスに値Xを設定します。
こんな感じで、常にスタックに入れる操作と出す操作+演算で計算していく感じです。
これはとてもわかりやすくてよかったです。
感想
写経成分多めとはいえ、自分のコンパイラ(第1世代)で自分がコンパイル(第2世代を生成)できたときはかなり感動でした。
まだ第2世代コンパイラで自分をコンパイルして第3世代コンパイラを作ろうとするとなぜかパースでエラーになる2ので、まだ色々バグはありそうですが、第一世代コンパイラ用につくっていた 各種サンプルのcソースを第2世代でコンパイルして実行すると正常に動いたので、それになりには動いている、という状態ではありそうです。
こういう本が無料でよめるのはすごいですね、つい6月ぐらいまでほとんど何も知らない状態だったのに、一応ここまでコンパイラ作れたのはとても良い経験でした。ということでこの本と、chibiccのソースコードを読むのはすごいおすすめです。