Parsletで正規表現
以前、rubyで、簡単な構文解析的なものを行いたいことがあって、Parsletというライブラリを勉強しました。
Parsletで構文解析する[その1]
Parsletで構文解析する[その2]
Parsletで構文解析する[その3]
その後、 正規表現技術入門を読んでいて正規表現をparsletでパースして、正規表現のマッチができたらお面白そうだなーと思って試してみました。
概要
- 正規表現をParsletを使ってparseして構文木をつくる
- 構文木から正規表現のマッチ用のVMのバイトコードを組み立てる
- 組み立てたバイトコードでマッチを行う
の3つのフェーズがあり、Parsletが関連するのは 1. の構文木をつくるところまでなのですが、作った構文木が実際に有用かどうかは、それを使って何かするところまで試さないとよくわからないので、上記の本を読みながらいろいろ試してみました。
そもそも正規表現のパーサーは、例えばこの記事で使っている言語、rubyの組み込みの正規表現ライブラリ(onigumo)とかでもホスト言語でライブラリを使わずに(c言語)で手動でパーサで書いていたりと、今回のように別途パースするライブラリを使うようなものではなさそうですが、この記事のスタンスはあくまでも勉強用という感じです。
前提
正規表現はいろいろ機能がありますが、今回は最低限の文法だけを採用して
- 連結(
ab等) - 0回以上の繰り返し(
a*) - 1回以上の繰り返し(
a+) - 選択(
a|b) - 括弧 (
(ab)+) - 特殊記号(
*+|など) の\によるエスケープ
だけ実装し、マッチする対象の文字列の先頭から見てマッチする文字列があるかどうか?を試す感じで実装しています。
(部分一致でもなく、完全一致でもなく、文字列の先頭から少なくとも正規表現にまっちする文字列があるかどうか?だけで判断しています。
マッチさせる位置を調整するだけで、部分一致にも完全一致にもできるかなとおもい、一旦この程度の精度で試しています。)
その他補足
Parsletの構文定義部分はあまり難しくなくて、演算子の優先度的に 選択の | を優先度下げるように処理されるようにするぐらいでした。それよりも、Parsletのパース結果から、意味のある構文木に組み立てるところが、いつもどおり(?)大変だったのと、VMの命令列を作ったりするところが初めてだったので難しかったです。
上記のようにもともとParsletを使って面白そうなものを作ってみよう、だったのですが、思いの外、参考にした正規表現技術入門 が詳細にかかれており、VM形式で正規表現をマッチするときの、命令列とその解釈の概要も勉強になったのでそこも含めて記事にまとめてみます。
正規表現の構文解析
今回の正規表現の文法を再掲すると
- 連結(
ab等) - 0回以上の繰り返し(
a*) - 1回以上の繰り返し(
a+) - 選択(
a|b) - 括弧 (
(ab)+) - 特殊記号(
*+|など) の\によるエスケープ
が目標です。これをparsletで下記のように記述してみました。
require 'parslet'
module MyRegexp
class RegexpParser < Parslet::Parser
# 正規表現全体
# aa | bb を解析する 「| bb」はない場合もある
rule(:regexp) {
(
list.as(:left) >> (op_branch >> list.as(:right)).repeat
).as(:branch)
}
# 連結と繰り返し
# abcdや、 a*b+ をパース
rule(:list) {
(
(exp >> op_star).as(:star) |
(exp >> op_plus).as(:plus) |
exp
).repeat(1).as(:list)
}
# 文字または括弧をパース
# "(" + 正規表現 + ")" や、
# 繰り返し記号などをエスケープした場合に文字として扱う対応(a\* など)や
# 通常の一文字、のパース
rule(:exp) {
(
str('(') >> regexp >> str(')') |
(str('\\') >> any.as(:escaped)).as(:escaped_char) |
match(/[^*+|)(]/).as(:char)
)
}
# 演算子のパース
rule(:op_branch) { str('|') }
rule(:op_star) { str('*') }
rule(:op_plus) { str('+') }
root(:regexp)
end
end
パースしてみる
今回の文法要素が全部入った正規表現 (a|c)*\*b+ をパースしてみます。
[1] pry(main)> require_relative 'my_regexp/regexp_parser'
=> true
[2] pry(main)> parser = MyRegexp::RegexpParser.new
=> REGEXP
[3] pry(main)> parser.parse('(a|c)*\*b+')
=> {:branch=>{:left=>{:list=>[{:star=>{:branch=>[{:left=>{:list=>[{:char=>"a"@1}]}}, {:right=>{:list=>[{:char=>"c"@3}]}}]}}, {:escaped_char=>{:escaped=>"*"@7}}, {:plus=>{:char=>"b"@8}}]}}}
出力を整形して対応する箇所を # hogehoge で補足すると
{:branch=> # 正規表現全体 (a|c)*\*b+
{:left=>
{:list=> # 連結 "()*", "\*", "b+" の部分
[{:star=> # 0回以上繰り返し "()*"
{:branch=> # 選択 a|c の部分
[{:left=>{:list=>[{:char=>"a"@1}]}}, # 文字 a の部分
{:right=>{:list=>[{:char=>"c"@3}]}}]}}, # 文字 c の部分
{:escaped_char=>{:escaped=>"*"@7}}, # エスケープされた*の部分
{:plus=>{:char=>"b"@8}}]}}} # 1回以上のbの繰り返しの部分 b+
となります。文法を制限しているので結構簡単でした。
ASTを作ってみる
ASTのノード
前回の電卓と同じく、このparsletの出力を Parslet::Transform を使って、今回の処理用のASTを構築します。
ASTの内容は 正規表現技術入門 も参考にしつつ、下記のようなノードを考えました。
- Node型
ノードの共通の親クラス
class Node
end
- Char型
一つの文字を表すノード
class Char < Node
attr_reader :char
def initialize(c)
@char = c
end
end
- List型
連結を表すノード
class List < Node
attr_reader :car, :cdr
def initialize(car, cdr)
@car = car
@cdr = cdr
end
end
Listはちょっと分かりづらそうなので補足しておきます。
連結は「正規表現の並び」を表していて、例えば文字 a の次に文字 b がきてその次に文字 c がくる正規表現は abc ですが、このようなものを表すためのオブジェクトとしてListを使っています。
Listのcar, cdrを List(car, cdr) と表すとすると abc は
List(List(a, b), c) みたいなオブジェクトのグラフになります。四則演算のときの左結合の構文木で表すと、
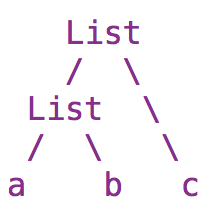
みたいな感じで保持しています。
- Branch型
選択を表すノード a|b みたいな正規表現を保持します。
class Branch < Node
attr_reader :left, :right
def initialize(left, right)
@left = left
@right = right
end
end
- Star型
0回以上の繰り返しを表すノード a* みたいな正規表現です。
class Star < Node
attr_reader :exp
def initialize(exp)
@exp = exp
end
end
- Plus型
1回以上の繰り返しを表すノード a+ みたいな正規表現です。
class Plus < Node
attr_reader :exp
def initialize(exp)
@exp = exp
end
end
ASTへの変換
前回の四則演算のときのように単純なルールから構成していきます。
先程のparsletの出力を再掲すると
{:branch=> # 正規表現全体 (a|c)*\*b+
{:left=>
{:list=> # 連結 "()*", "\*", "b+" の部分
[{:star=> # 0回以上繰り返し "()*"
{:branch=> # 選択 a|c の部分
[{:left=>{:list=>[{:char=>"a"@1}]}}, # 文字 a の部分
{:right=>{:list=>[{:char=>"c"@3}]}}]}}, # 文字 c の部分
{:escaped_char=>{:escaped=>"*"@7}}, # エスケープされた*の部分
{:plus=>{:char=>"b"@8}}]}}} # 1回以上のbの繰り返しの部分 b+
となり、
{:char=>"a"@1} や、 {:escaped_char=>{:escaped=>"*"@7}} は a や * などの一つの文字ですので、 Char 型に変換できます。
escaped を Char に変換しているので、 escaped_char の simple(x) は Charのオブジェクト になるので、そのまま x を返します。
module MyRegexp
class RegexpTransformer < Parslet::Transform
rule(char: simple(:x)) { Char.new(x.to_s) }
rule(escaped: simple(:x)) { Char.new(x.to_s) }
rule(escaped_char: simple(:x)) { x }
end
end
これで先程の正規表現をtransformすると、
{:branch=>
{:left=>
{:list=>
[{:star=>{:branch=>[{:left=>{:list=>[a]}}, {:right=>{:list=>[c]}}]}},
*,
{:plus=>b}]}}}
のようになります(Char型はinspectで 文字そのものとして表記されるように調整してます)
これを見ていると、一番下にある {:plus=>b} (bはChar型) なども単純に Plus 型に変換できそうなので、 Star も合わせて
rule(plus: simple(:x)) { Plus.new(x) }
rule(star: simple(:x)) { Star.new(x) }
も追加して再度試します。
{:branch=>
{:left=>
{:list=>
[{:star=>{:branch=>[{:left=>{:list=>[a]}}, {:right=>{:list=>[c]}}]}},
*,
(+ b)]}}}
最後の b+ が (+ b) になりました。(Plus型もinspectで (+ 文字) になるように調整してます。Starも同様)
この結果をみると、 {:list=>[a]} なども、 Node型の配列になっていそうなので、 parsletの sequence(:x) としてtransformできそうなので、定義します。
これは、配列をList型の(木構造)に畳み込むので、前回と同様injectで畳み込みます。
また、injectの仕様で、1件の場合は、ブロック中身が実行されずに単純にその1件を返します。この1件はNode型のオブジェクトなので、ちょうどいいですね。
rule(list: sequence(:x)) {
# injectは引数なしで、要素数1の場合、x[0]を返すのでいずれにせよNodeオブジェクトが返る
x.inject do |acc, n|
List.new(acc, n)
end
}
↑も追加して再実行します。
{:branch=>
{:left=>
{:list=>[{:star=>{:branch=>[{:left=>a}, {:right=>c}]}}, *, (+ b)]}}}]
すると、 {:list=>[a]} だったものが、 畳み込まれて、かつ要素が1だったので、単純に Char(a) になり、 {:left=>a} になりました。すると、 left や right も、 simple(:x) の場合はそのまま返せば良さそうです。
rule(left: simple(:x)) { x }
rule(right: simple(:x)) { x }
も加えて再実行。
{:branch=>{:left=>{:list=>[{:star=>{:branch=>[a, c]}}, *, (+ b)]}}}
{:branch=>[a, c]} は、四則演算のときの二項演算と同じパースルールなので、変換も同じように畳み込みます。
パースルールの部分は
list.as(:left) >> (op_branch >> list.as(:right)).repeat
となっており、前回の四則演算のとき同様、 (op_branch >> list.as(:right)).repeat が存在すれば、 left も含めた配列になるし、 leftしかない場合、要素1の配列ではなく、 leftそのものがマッチします。それを考慮して、下記のように畳み込みます。
rule(branch: subtree(:x)) {
case x
# (op_branch >> list.as(:right)).repeat が存在する場合
when Array
x.inject do |left, right|
Branch.new(left, right)
end
else
# leftしかなかった場合
x
end
}
これも加えて再実行します。
[(* (B a c)) * (+ b)]]
これで、parsletの出力結果は全部なくなり、ASTの各種Nodeのみに変換できました。
(Branch型は、 (B left, right) List型は、 List((list(a, b), c) 等が [a b c] と表記されるように調整しています)
上記をまとめると、Transformクラスは下記のようになります。
module MyRegexp
class RegexpTransformer < Parslet::Transform
rule(char: simple(:x)) { Char.new(x.to_s) }
rule(escaped: simple(:x)) { Char.new(x.to_s) }
rule(escaped_char: simple(:x)) { x }
rule(plus: simple(:x)) { Plus.new(x) }
rule(star: simple(:x)) { Star.new(x) }
rule(left: simple(:x)) { x }
rule(right: simple(:x)) { x }
rule(list: sequence(:x)) {
# injectは引数なしで、要素数1の場合、x[0]を返すのでいずれにせよNodeオブジェクトが返る
x.inject do |acc, n|
List.new(acc, n)
end
}
rule(branch: subtree(:x)) {
case x
when Array
x.inject do |left, right|
Branch.new(left, right)
end
else
x
end
}
end
end
次は、このASTを使って、 VMの命令列にコンパイルするのと、その命令列で実際に文字列とマッチするところを実装します。
その2に続く