本記事はJupyter 上で Scala で書いたアプリを動かすようにすることを目的としています。
なぜ、Scala?
Jupyter を使うなら、Python で良いじゃないか!と思われる方も多いかと思います。
しかし、すでにある Scala で書かれた資産(コード)があって、
そのアプリに追加することを前提にした何らかのコードを書きたいとか、
Scala が好きなんだ!とか、
Scala を始めてみたいとか、
人生色々、会社理由も色々あると思います。
(まぁ、単純に筆者が Scala が好きで、Spark-Shell辛いけど、わざわざ、pyspark のAPIを覚えるの面倒だからという理由だったります。)
環境
以下の環境が事前に整っている前提です。
必須
Python
3系
sbt
1.0.3
(試してはいませんが、0.13系でも大丈夫じゃないかと)
Scala
2.12.2
(何で2.12系にしたのやら・・・2.11系で動くはずです)
Jupyter Scala
0.4.2(2017/11/14 時点での最新)
Jupyter kernel
0.4.1(2017/11/14 時点での最新)
Java
OpenJDK 8
(Java 8なら、Oracle JDK8 でも良いはず。今回はAmazon EMRに近付けたいため、EMRデフォルトのOpen JDKをyum installしています)
任意
OS
Amazon Linux 2017.03 の Docker image
(別に Python と JVMM が動くなら何でも良いです。Windows の場合は適宜、パスやコマンドをWindows のものに読み替えてください)
Spark
2.2.0
※ Jupyter 上で Scala を動かすだけであれば不要です。Spark アプリを動かすために構築した際の手順のため、Spark を動かすための設定を行っていたりします。
Docker周り
Jupyter 上で Scala を動かすだけであれば不要です。
今回は Amazon EMR に近い環境としたかったため、docker-compose を使って、
Spark クラスターを構築し、master ノード上で Jupyter を建てて、ホストからアクセスするようにしています。
- Docker CE 17.09.0 (多分、docker-ceならどのバージョンでも大丈夫かと)
- docker-compose
構築手順
Jupyter をインストールする
JupyterLab とかはお好みでと言ったところでしょうか
Spark を使わなければ、jupyter, notebook(or jupyterlab), py4j あたりがあれば良いのかお知れません(py4jも必須かは怪しいかも)
pip install jupyter
pip install notebook
pip install jupyterlab
pip --no-cache-dir install pandas pyspark
pip install py4j jupyter-spark lxml
pip install --upgrade beautifulsoup4 html5lib
jupyter nbextension install --py jupyter_spark
jupyter serverextension enable --py jupyter_spark
jupyter nbextension enable --py jupyter_spark
jupyter nbextension enable --py widgetsnbextension
jupyter serverextension enable --py jupyterlab --sys-prefix
pip install scipy scikit-learn pygments && \
pip3 install scipy scikit-learn pygments pandas pyspark ipykernel ipython
sbt をインストールする
今回のは、Dockerfile で Docker Image を構築しているため、sudo なり doas を行っていませんが、必要に応じて適宜、sudo なり doas を行なってください。
##
# Dockerfile では
# ENV SBT_HOME /usr/local/sbt
# ENV PATH ${PATH}:${SBT_HOME}/bin
# と記述
##
echo "export SBT_HOME=/usr/local/sbt" >> .bashrc
echo "export PATH=${PATH}:${SBT_HOME}/bin" >> .bashrc
export SBT_VERSION=1.0.3
curl -sL "https://github.com/sbt/sbt/releases/download/v${SBT_VERSION}/sbt-${SBT_VERSION}.tgz" | tar -xz -C /usr/local
Jupyter kernel/Jupyter Scala をインストールする
# Jupyter Scala のインストール
curl -sL "https://github.com/jupyter-scala/jupyter-scala/archive/v0.4.2.tar.gz" | tar -xz -C /usr/local && \
cd /usr/local/ && \
ln -s jupyter-scala-0.4.2 jupyter-scala && \
cd jupyter-scala && \
sbt publishLocal
# Jupyter Kernel のインストール
curl -sL "https://github.com/jupyter-scala/jupyter-kernel/archive/v0.4.1.tar.gz" | tar -xz -C /usr/local &&\
cd /usr/local/ && \
ln -s jupyter-kernel-0.4.1 jupyter-kernel && \
cd jupyter-kernel && \
sbt publishLocal
# 仕上げ
# Windows の場合は https://github.com/jupyter-scala/jupyter-scala/blob/master/jupyter-scala.ps1 を使えば良さそう
# /root 配下じゃ無くても良さそう
curl -sL "https://raw.githubusercontent.com/alexarchambault/jupyter-scala/master/jupyter-scala" -o /root/jupyter-scala.sh && \
chmod 744 /root/jupyter-scala.sh && \
sed -e "s/2.11.11/2.12.4/gi" /root/jupyter-scala.sh && \
/root/jupyter-scala.sh && \
rm -f /root/jupyter-scala.sh
これで Jupyter を起動すると以下のように、Jupyter 上で Scala が使えるようになります。
※ JupyterLab の起動画面
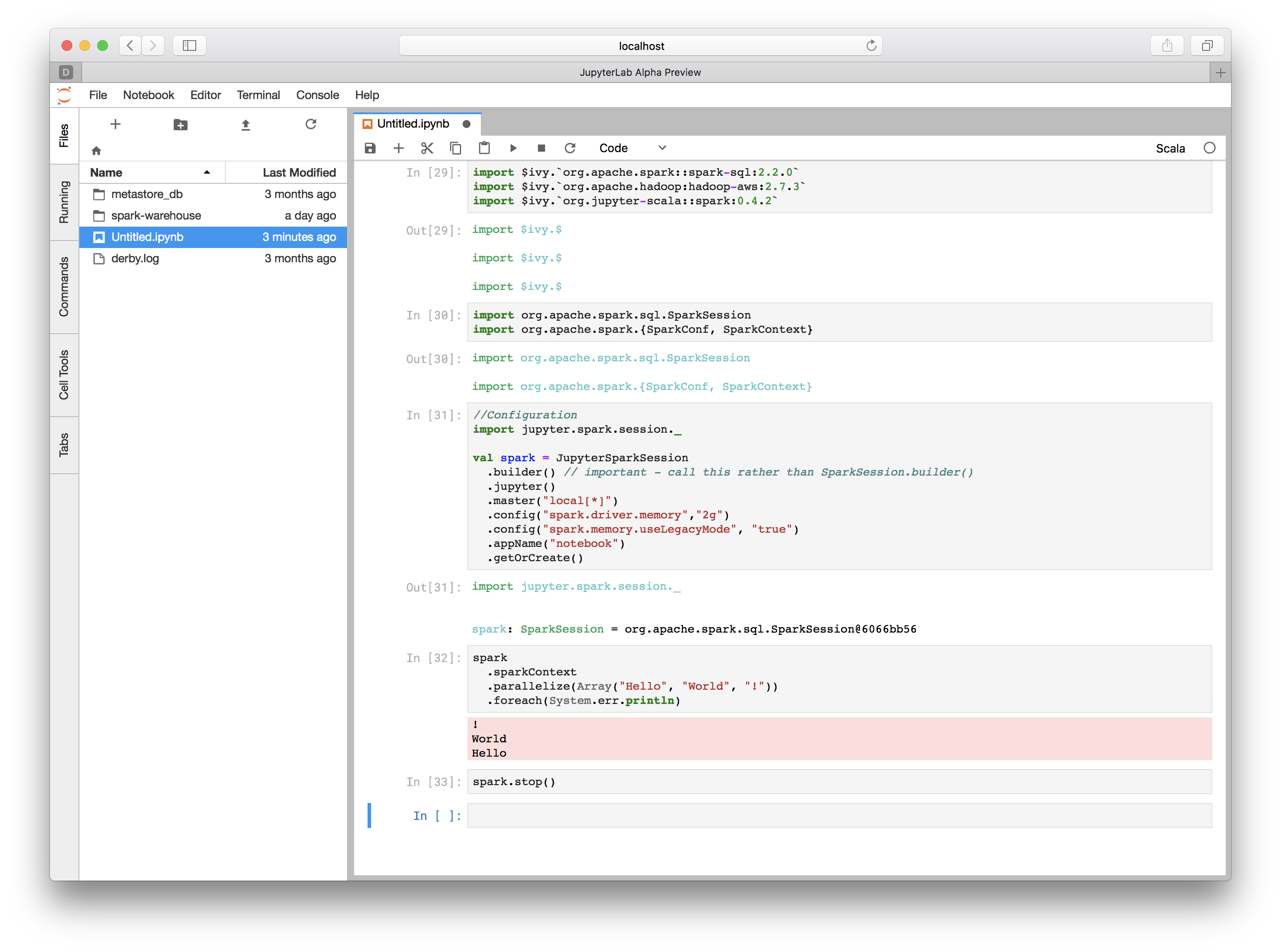
動かしてみる
それぞれのセルに、以下のようなコードを記述してみました。
import $ivy.`org.apache.spark::spark-sql:2.2.0`
import $ivy.`org.apache.hadoop:hadoop-aws:2.7.3`
import $ivy.`org.jupyter-scala::spark:0.4.2`
import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf, SparkContext}
//Configuration
import jupyter.spark.session._
val spark = JupyterSparkSession
.builder() // important - call this rather than SparkSession.builder()
.jupyter()
.master("local[*]")
.config("spark.driver.memory","2g")
.config("spark.memory.useLegacyMode", "true")
.appName("notebook")
.getOrCreate()
spark
.sparkContext
.parallelize(Array("Hello", "World", "!"))
.foreach(System.err.println)
spark.stop()
依存ライブラリの参照
以下のように記述する
$ivy.`group::artifact:version`
参考:https://github.com/jupyter-scala/jupyter-scala#spark
まとめ
sbt と Jupyter kernel/Jupyter Scala をインストールすればよい。
余談
職場などで、proxy を通す場合
https://github.com/jupyter-scala/jupyter-scala/issues/21
のとおり実施したら動作せず。
以下のように、argv セクションに追加したら動作しました
{
"language" : "scala",
"display_name" : "Scala",
"argv" : [
"java",
"-noverify",
"-Dhttp.proxyHost=...",
"-Dhttp.proxyPort=...",
"-Dhttps.proxyHost=...",
"-Dhttps.proxyPort=...",
"-jar",
"/root/.local/share/jupyter/kernels/scala/launcher.jar",
"launch",
"-r",
"sonatype:releases",
"-r",
"sonatype:snapshots",
"-i",
"ammonite",
"-I",
"ammonite:org.jupyter-scala:ammonite-runtime_2.11.11:0.8.3-1",
"-I",
"ammonite:org.jupyter-scala:scala-api_2.11.11:0.4.2",
"org.jupyter-scala:scala-cli_2.11.11:0.4.2",
"--",
"--id",
"scala",
"--name",
"Scala",
"--quiet",
"--connection-file",
"{connection_file}"
]
}