はじめに
「PDFを編集したいけど、ファイルを知らないサーバーにアップロードするのは不安...」
この問題を解決するために、ファイルを一切サーバーに送信しないPDF編集サイトと画像編集サイトを作りました。
- PDF Tools: https://www.pdftools-free.com/
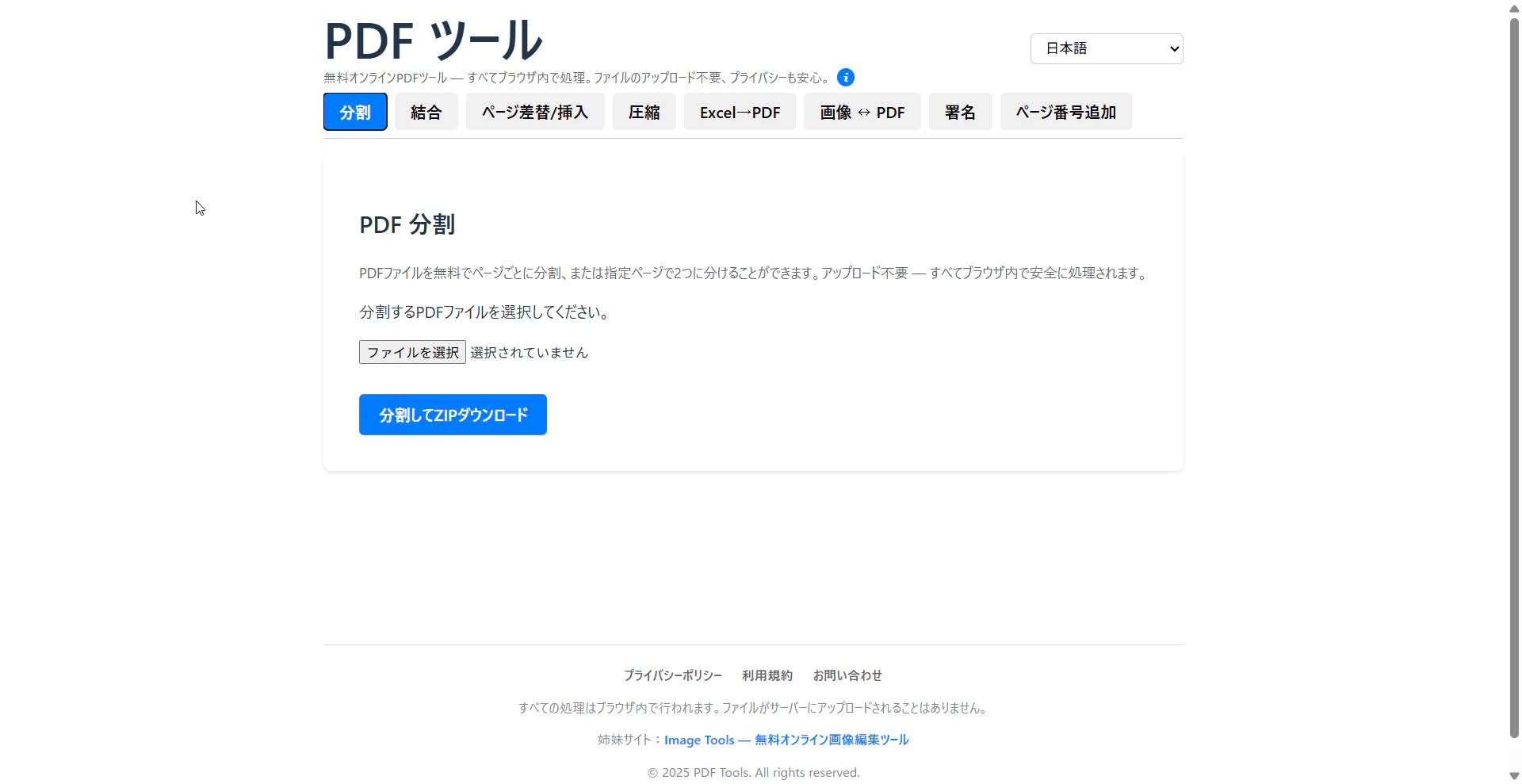
- Image Tools: https://www.imagetools-free.com/
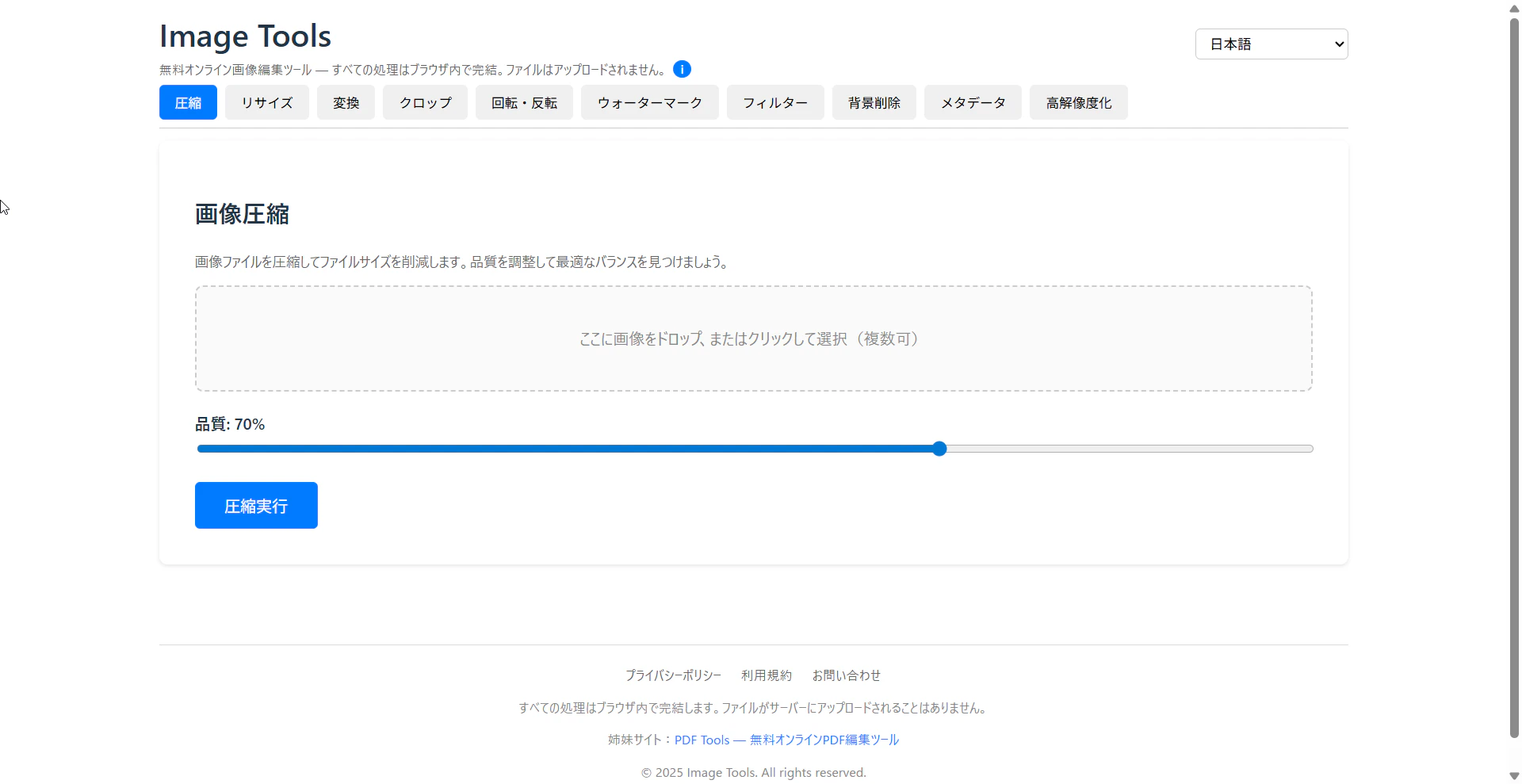
すべての処理がブラウザ内のJavaScriptで完結します。この記事では両サイトの技術的な実装について紹介します。
何ができるか
PDF Tools(8ツール)
| ツール | 説明 | 主要ライブラリ |
|---|---|---|
| Split | PDFを分割 | pdf-lib, JSZip |
| Merge | 複数PDFを結合 | pdf-lib |
| Replace/Insert | ページ差替・挿入 | pdf-lib |
| Compress | 圧縮 + グレースケール変換 | pdfjs-dist, pdf-lib |
| Excel to PDF | Excel変換 | ExcelJS, jsPDF, html2canvas |
| Image ↔ PDF | 画像⇄PDF双方向変換 | pdf-lib, pdfjs-dist, JSZip |
| Sign | PDF署名 | pdfjs-dist, pdf-lib |
| Add Page Numbers | ページ番号追加 | pdf-lib |
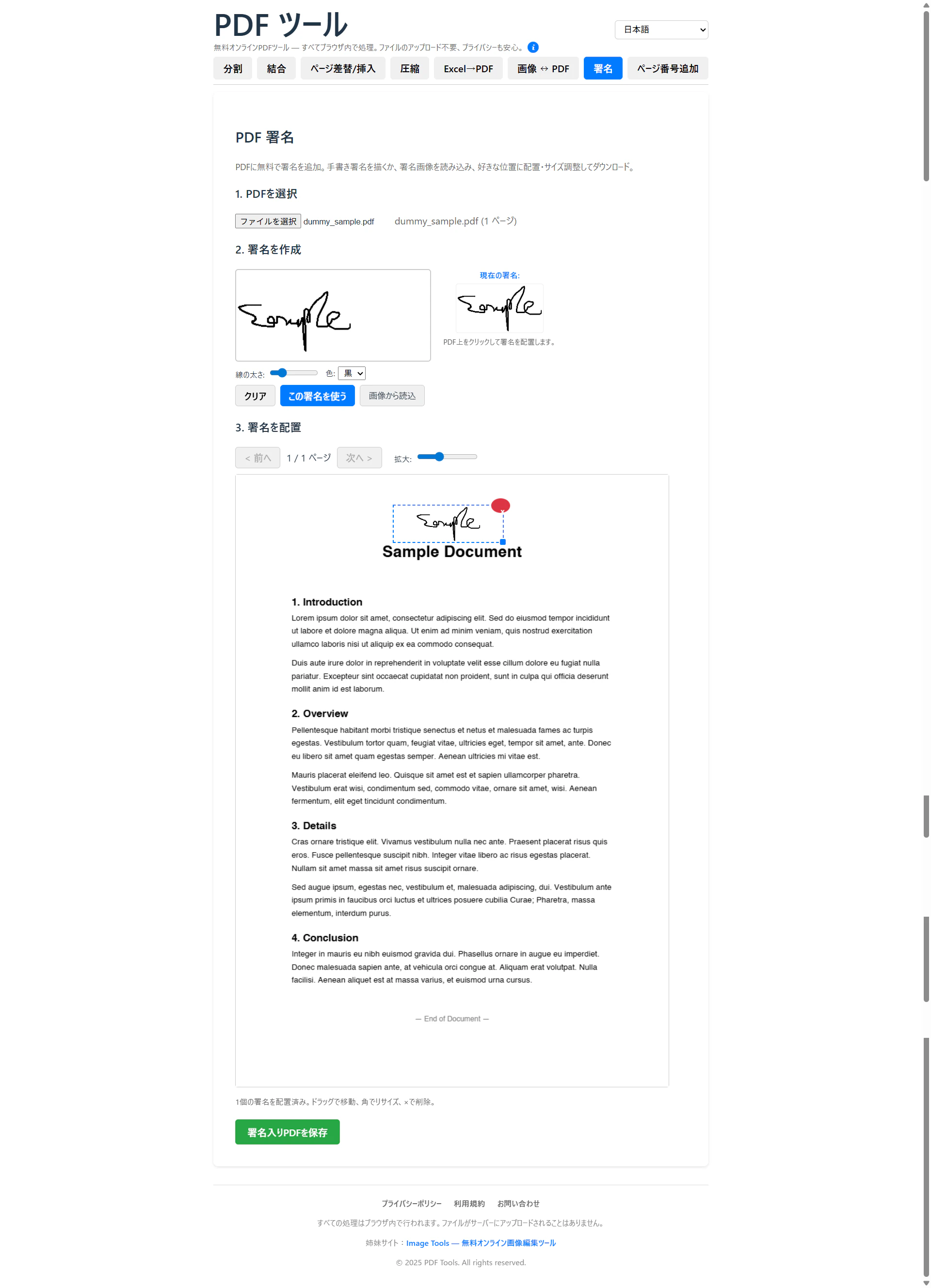
Image Tools(10ツール)
| ツール | 説明 | 技術 |
|---|---|---|
| Compress | 画像圧縮 | Canvas API |
| Resize | リサイズ | Canvas API |
| Convert | 7形式変換(BMP/GIF/ICO含む) | Canvas + カスタムエンコーダ |
| Crop | ドラッグ選択で切り抜き | Canvas API |
| Rotate/Flip | 回転・反転(自由角度対応) | Canvas API |
| Watermark | テキスト/画像透かし(一括処理対応) | Canvas API |
| Filter | 6種フィルター | CSS Filters |
| Background Removal | AI背景除去 | @imgly/background-removal (ONNX) |
| Metadata | EXIF + AI生成情報表示 | exifr + カスタムPNGパーサー |
| Upscale | AI高解像度化(2x/4x) | TensorFlow.js + ESRGAN |
技術スタック
PDF Tools — React 19 + Vite 7
├── pdf-lib ... PDF操作(結合、分割、署名、ページ番号)
├── pdfjs-dist ... PDF描画(圧縮、画像変換で使用)
├── ExcelJS ... Excelファイル解析
├── jsPDF ... Excel→PDF変換
├── html2canvas ... HTML→Canvas変換
├── JSZip ... ZIP生成
└── file-saver ... ダウンロード処理
Image Tools — React 19 + Vite 7
├── Canvas API ... 圧縮、リサイズ、切り抜き、回転、透かし
├── CSS Filters ... フィルター処理
├── @imgly/background-removal ... AI背景除去(ONNX Runtime)
├── @tensorflow/tfjs ... AI高解像度化エンジン
├── upscaler + @upscalerjs/esrgan-medium ... ESRGANモデル
├── exifr ... EXIF情報解析
├── JSZip ... ZIP生成(一括処理時)
└── file-saver ... ダウンロード処理
こだわった点
1. コードスプリッティングで初回ロードを91%削減
PDF Tools の最初のビルドでは初回ロードが 2,775KB ありました。これを 248KB まで削減しました。
React.lazy() による動的インポート
// 各ツールを遅延読み込み — 選択したタブだけロードされる
const SplitMode = lazy(() => import('./components/SplitMode'));
const MergeMode = lazy(() => import('./components/MergeMode'));
const CompressMode = lazy(() => import('./components/CompressMode'));
// ...
Vite の manualChunks でライブラリを分離
PDF Tools:
// vite.config.js
manualChunks: {
'pdfjs': ['pdfjs-dist'],
'excel-pdf': ['exceljs', 'jspdf', 'html2canvas'],
'pdf-lib': ['pdf-lib'],
}
Image Tools ではAI系ライブラリが特に巨大なので、さらに細かく分離:
// vite.config.js
manualChunks: {
'react-vendor': ['react', 'react-dom'],
'jszip': ['jszip'],
'bg-removal': ['@imgly/background-removal'], // ONNX Runtime含む
'exifr': ['exifr'],
'tfjs': ['@tensorflow/tfjs'], // ~2MB
'upscaler': ['upscaler', '@upscalerjs/esrgan-slim', '@upscalerjs/esrgan-medium'],
}
これにより、例えば「圧縮」だけ使うユーザーにはTensorFlow.jsのチャンクはロードされません。
2. Canvas APIだけで実現する画像処理
Image Tools の画像処理は、外部ライブラリを使わず Canvas API だけで実装しています。
圧縮 — quality パラメータの活用
const canvas = document.createElement('canvas');
canvas.width = img.naturalWidth;
canvas.height = img.naturalHeight;
const ctx = canvas.getContext('2d');
ctx.drawImage(img, 0, 0);
// quality: 0〜1 で JPEG/WebP の圧縮率を制御
canvas.toBlob((blob) => {
// 圧縮後のblobを取得
}, 'image/jpeg', 0.7); // 70% 品質
回転 — 自由角度対応の座標計算
90度回転は単純ですが、自由角度回転ではキャンバスサイズの再計算が必要です:
// 自由角度回転 — 画像が切れないようにキャンバスを拡張
const rad = angle * Math.PI / 180;
const sin = Math.abs(Math.sin(rad));
const cos = Math.abs(Math.cos(rad));
// 回転後に必要なキャンバスサイズ(対角線を考慮)
canvas.width = Math.ceil(w * cos + h * sin);
canvas.height = Math.ceil(w * sin + h * cos);
ctx.translate(canvas.width / 2, canvas.height / 2);
ctx.rotate(rad);
ctx.drawImage(img, -w / 2, -h / 2);
フィルター — CSS Filters をCanvasに適用
const filterString = `brightness(${filters.brightness}%)
contrast(${filters.contrast}%)
saturate(${filters.saturate}%)
blur(${filters.blur}px)
sepia(${filters.sepia}%)
grayscale(${filters.grayscale}%)`;
ctx.filter = filterString; // drawImage時に自動適用
ctx.drawImage(img, 0, 0);
ctx.filter を使えば、ピクセル単位の操作をせずにCSS Filtersと同じ効果を画像ファイルに焼き込めます。
透かし — バッチ処理時の相対サイズ計算
複数画像に一括で透かしを入れる場合、画像サイズが異なるため、フォントサイズを**画像の短辺に対する%**で指定できるようにしました:
// 短辺の10%をフォントサイズにする
const shortSide = Math.min(canvas.width, canvas.height);
const fontSize = Math.round(shortSide * fontSizePct / 100);
// タイル状に透かしを敷き詰める
for (let y = -diag; y < diag; y += gap) {
for (let x = -diag; x < diag; x += gap) {
ctx.fillText(text, x, y);
}
}
3. カスタムバイナリエンコーダで7形式変換
Canvas API の toBlob() は JPEG/PNG/WebP/AVIF に対応していますが、BMP・GIF・ICO には対応していません。これらは自作のバイナリエンコーダで実装しました。
BMP エンコーダ
function canvasToBmp(canvas) {
const ctx = canvas.getContext('2d');
const { width, height } = canvas;
const imageData = ctx.getImageData(0, 0, width, height);
// BMPは行サイズが4バイト境界にパディングされる
const rowSize = Math.ceil((width * 3) / 4) * 4;
// BMPファイルヘッダ(14B) + BITMAPINFOHEADER(40B) + ピクセルデータ
const fileSize = 54 + rowSize * height;
const buffer = new ArrayBuffer(fileSize);
// ピクセルデータ: RGBA → BGR変換 + 上下反転
for (let y = height - 1; y >= 0; y--) {
for (let x = 0; x < width; x++) {
const srcIdx = (y * width + x) * 4;
bytes[dstIdx] = data[srcIdx + 2]; // B
bytes[dstIdx + 1] = data[srcIdx + 1]; // G
bytes[dstIdx + 2] = data[srcIdx]; // R
}
}
return new Blob([buffer], { type: 'image/bmp' });
}
BMPはRGB→BGRの並び替えと、ピクセルデータが下から上に格納される仕様があり、手動で変換が必要です。
GIF エンコーダ(LZW圧縮付き)
// 1. 色の量子化(256色以内にする)
// 2. パレット構築
// 3. LZW圧縮でエンコード
// 4. GIF89aフォーマットで出力
const lzwData = lzwEncode(indexedPixels, minCodeSize);
// 辞書が4096エントリを超えたらリセット
GIFの最大の課題は 256色制限。元画像の色を量子化してパレットにマッピングする処理を自前で実装しています。
4. AI機能もブラウザ内で完結
背景除去 — ONNX Runtimeでブラウザ推論
const { removeBackground } = await import('@imgly/background-removal');
const blob = await removeBackground(file, {
progress: (key, current, total) => {
const pct = Math.round((current / total) * 100);
setStatusMsg(`処理中: ${pct}%`);
},
});
// → 透過PNGが返る
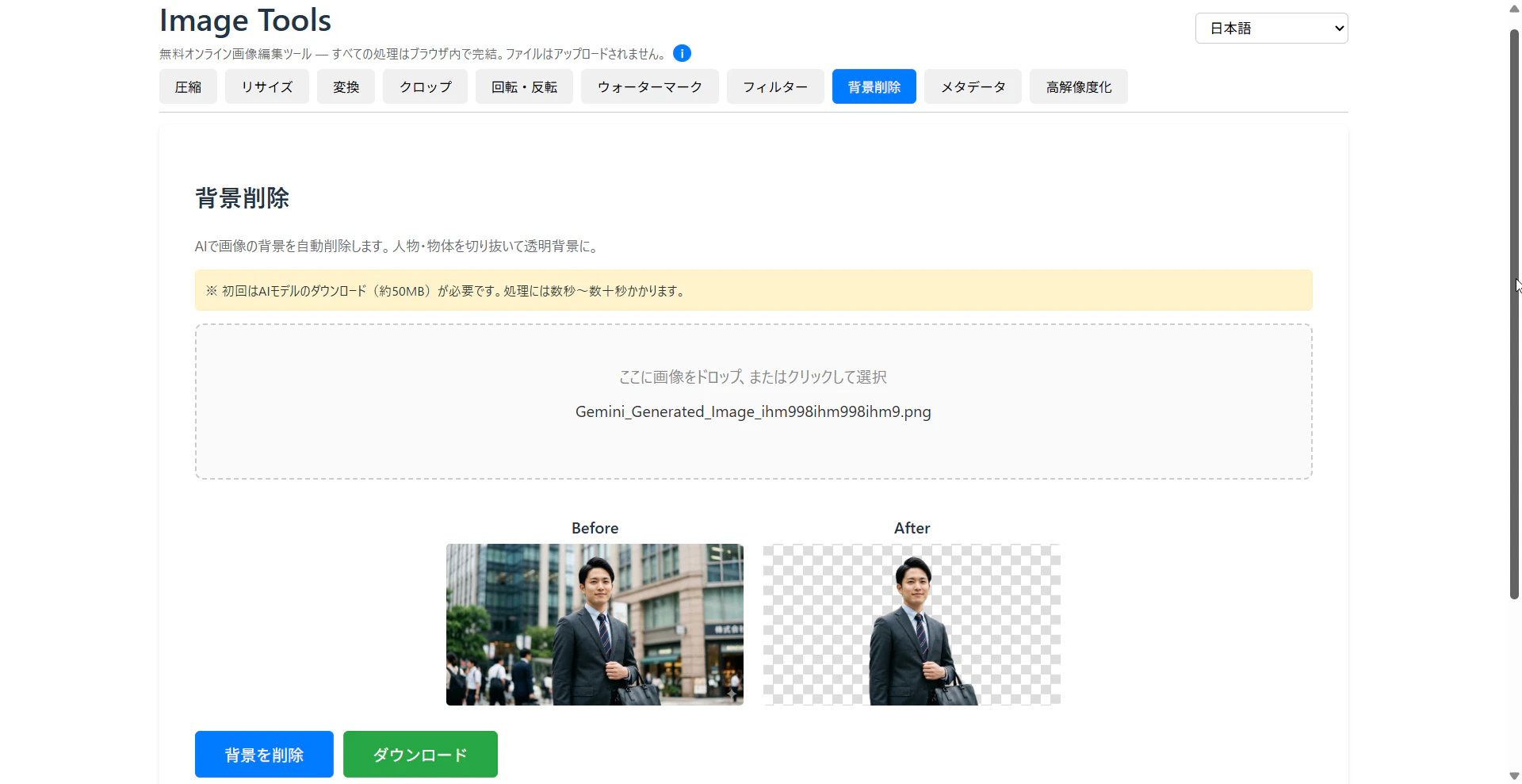
初回使用時に約50MBのONNXモデルがダウンロードされますが、ブラウザキャッシュに保存されるため2回目以降は即座に処理が始まります。
高解像度化 — TensorFlow.js + ESRGAN
const tf = await import('@tensorflow/tfjs');
const Upscaler = (await import('upscaler')).default;
// 2x or 4x でモデルを切り替え
const model = scale === 4
? (await import('@upscalerjs/esrgan-medium/4x')).default
: (await import('@upscalerjs/esrgan-medium/2x')).default;
const upscaler = new Upscaler({ model });
const result = await upscaler.upscale(img, {
patchSize: 64, // 64pxタイルで分割処理(メモリ節約)
padding: 4, // タイル間のオーバーラップ(継ぎ目防止)
});
ポイント: patchSize: 64 で画像を小さなタイルに分割して推論することで、GPUメモリ不足を回避しています。大きな画像でもOOMにならずに処理できます。
5. PNGメタデータからAI生成情報を検出
MetadataツールではEXIF情報だけでなく、Stable Diffusion・ComfyUI・NovelAI の生成パラメータも表示できます。
function parsePngTextChunks(buffer) {
// PNGシグネチャを検証
const sig = [137, 80, 78, 71, 13, 10, 26, 10];
// チャンクを順に読み取る
while (offset < buffer.byteLength - 12) {
const length = view.getUint32(offset);
const type = String.fromCharCode(...typeBytes);
if (type === 'tEXt') {
// テキストチャンク: keyword + null + text
} else if (type === 'iTXt') {
// 国際テキストチャンク: keyword + null + 圧縮フラグ + 言語タグ + text
}
offset += 12 + length; // 4(長さ) + 4(タイプ) + データ + 4(CRC)
}
}
function detectAiMetadata(chunks) {
for (const chunk of chunks) {
// "parameters" → Stable Diffusion (AUTOMATIC1111)
// "prompt" or "workflow" (JSON) → ComfyUI
// "comment", "source" → NovelAI
}
}
PNGファイルの tEXt / iTXt チャンクにAI生成ツールがメタデータを埋め込むので、これをバイナリレベルで解析しています。
6. 5言語対応を独自i18nで実装
react-i18next などのライブラリを使わず、シンプルな独自実装にしました。
// i18n.js — 翻訳辞書(約1,000行)
const translations = {
en: {
'app.title': 'PDF Tools',
'split.button': 'Split & Download ZIP',
// ...
},
ja: {
'app.title': 'PDF ツール',
'split.button': '分割してZIPダウンロード',
// ...
},
// vi, id, zh も同様
};
// LanguageContext.jsx — プレースホルダー置換対応
const t = (key, ...args) => {
const str = translations[lang]?.[key] || translations.en[key] || key;
return str.replace(/\{(\d+)\}/g, (_, i) => args[Number(i)] ?? '');
};
// 使用例: t('bgRemove.progress', 75) → "処理中: 75%"
ブラウザ言語の自動検出で、初回アクセス時に適切な言語を表示:
const browserLang = (navigator.language || '').toLowerCase();
if (browserLang.startsWith('ja')) return 'ja';
if (browserLang.startsWith('vi')) return 'vi';
if (browserLang.startsWith('id') || browserLang.startsWith('ms')) return 'id';
if (browserLang.startsWith('zh')) return 'zh';
return 'en';
7. alert() を使わない — カスタムToast UI
alert() はブラウザをブロックしてUXが悪いので、ライブラリなしでToast通知を自作しました。
// ToastContext.jsx
const showToast = (message, type = 'success') => {
const id = Date.now();
setToasts(prev => [...prev, { id, message, type }]);
setTimeout(() => removeToast(id), 3000); // 3秒で自動消去
};
8. メモリ管理 — Object URLの適切な解放
画像処理ツールではメモリリークに注意が必要です。URL.createObjectURL() で作成したURLは使用後に必ず解放します:
const url = URL.createObjectURL(file);
img.src = url;
img.onload = () => {
// 処理実行
URL.revokeObjectURL(url); // 即座にメモリ解放
};
AI高解像度化ではTensorFlow.jsのテンソルも明示的にdisposeする必要があります。
SPAのSEO対策
React SPAは <div id="root"></div> だけのHTMLなので、Googleクローラーがコンテンツを読めない問題があります。
対策として <noscript> タグ内に全ツールの説明文を静的HTMLで配置しました:
<noscript>
<div>
<h1>PDF Tools - Free Online PDF Editor</h1>
<h2>Split PDF</h2>
<p>Split PDF files into individual pages...</p>
<!-- 全ツール分 -->
</div>
</noscript>
加えて、JSON-LD 構造化データも追加しています:
<script type="application/ld+json">
{
"@type": "WebApplication",
"name": "PDF Tools",
"featureList": ["Split PDF", "Merge PDF", ...],
"inLanguage": ["en", "ja", "vi", "id", "zh"]
}
</script>
コスト
| 項目 | 費用 |
|---|---|
| ホスティング(Vercel)× 2サイト | 無料 |
| ドメイン 2つ(Cloudflare) | 年 $20.92(約3,200円) |
| SSL証明書 | 無料(Cloudflare) |
| ライブラリ | すべてOSS、無料 |
| AIモデル | ブラウザ配信、無料 |
| 合計 | 月約267円 |
サーバーサイド処理がないので、ユーザーが増えてもサーバーコストが増えません。目標は Google AdSense で月267円以上の収益を出して、ドメイン代を回収することです。
まとめ
- pdf-lib と pdfjs-dist の組み合わせで、ほぼすべてのPDF操作がブラウザ内で可能
- Canvas API だけで圧縮・リサイズ・回転・切り抜き・透かし・フィルターを実現
- カスタムバイナリエンコーダでBMP/GIF/ICO変換も対応(Canvas非対応フォーマット)
- TensorFlow.js + ONNX Runtime でAI背景除去・高解像度化もクライアントサイドで動作
- PNGチャンク解析でStable Diffusion等のAI生成メタデータを検出
- コードスプリッティングで初回ロードを91%削減
- 独自i18nで5言語対応(ライブラリ不使用で軽量)
「ファイルをアップロードしたくない」というニーズは意外と多く、プライバシーを重視する人や、低速回線環境(東南アジアなど)のユーザーに特に刺さります。
ぜひ使ってみてください!フィードバックお待ちしています。
- PDF Tools: https://www.pdftools-free.com/
- Image Tools: https://www.imagetools-free.com/