「NetflixはSparkでペタバイト級の集計をやってるらしいですね〜」(2015年の発表)
「AWSのEMRとかGCPのDataprocあたりでSpark環境を用意してみました。ふふん」
「とりまクラスタ立ててみましたけど、全然パフォーマンスでないんですけど?」
「っていうか何が起きてるかよく分からないし……分散処理とか馴染みないし……」
という感じの方が、とりあえずSpark SQLの実行計画やWeb UIの情報をざっくり読みとってチューニングできるようになるための道筋を示すことが本記事の目的です。
Sparkの良い解説記事は沢山あるものの話題が多岐に渡り初心者は迷子になりやすいので、それらの主要図を引用しながら駆けぬけていく感じでいきます><
Cluster Manager
Sparkはクラスターの上でデータを処理しますが、その管理はクラスターマネージャー(リソースマネージャー)に依存しています。クラスタマネージャーとして選択できるのは次の4つです。
- Standalone
- Apache Mesos
- Hadoop YARN
- Kubernetes
Cluster Mode Overview - Spark 3.0.0 Documentation
「Standalone」はその名の通りSparkに内蔵されているクラスターマネージャーです。
「Apache Mesos」「Hadoop YARN」はどちらもApacheのOSSです。Sparkもそうですね。
YARNのアーキテクチャ図を引用するので雰囲気を感じてください。詳しくは『YARN の紹介 – IBM Developer』がお勧めです。
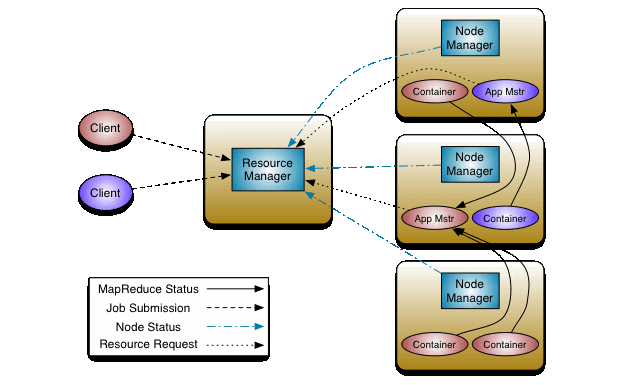
Apache Hadoop YARN – Apache Hadoop
Sparkはこういったクラスターマネージャを通じて、ジョブを実行します。
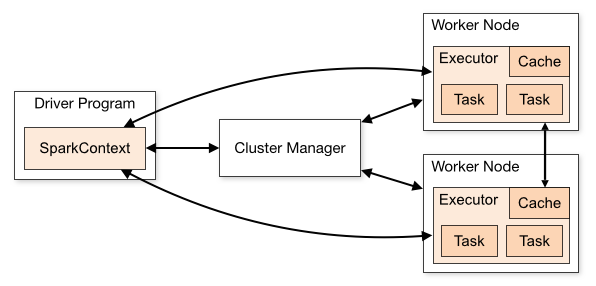
Cluster Mode Overview - Spark 3.0.0 Documentation
Worker Nodeというのは実際にデータを扱うマシンだったりインスタンスのことです。Driver ProgramやCluster Managerを実行するものは、この図には描かれてないですがMaster Nodeと呼ばれたりします。
一般的にMaster Nodeは単一障害点になりますが、EMRやDataprocでは複数Node用意して高可用性を保つ機能も用意されていたりします。
複数のマスターノードを持つ EMR クラスターの起動 - Amazon EMR
高可用性モード - Dataproc ドキュメント - Google Cloud
また実行中にWorker Nodeを追加する自動スケーリングも用意されています。
カスタムポリシーによる自動スケーリングをインスタンスグループに使用する - Amazon EMR
クラスタの自動スケーリング - Dataproc ドキュメント - Google Cloud
クラスターマネージャーは spark.master で設定・確認できます。よくある初歩的なミスは、クラスター環境を組んだのに spark.master がローカル開発時のまま local になっていてMaster NodeでしかSparkが動いていなかったというものです。
その他の設定はクラスターマネージャーに依るので公式ドキュメントを参照してください。
Cluster Managers - Configuration - Spark 3.0.0 Documentation
なお、従来は「Hadoop YARN」を使うのが標準的だったかと思うのですが、Spark 2.3頃から今を時めく「Kubernetes」対応が始まっていて、これからはSpark on Kubernetesの導入例が増えていきそうです。
すでにKubernetesの環境を持っていて、マシンリソース管理を纏めたいのであれば試す価値は充分にあると思います。ベンチマーク上では、すでにYARNと同等のパフォーマンスが出ているそうです。
Kubernetes で Spark パフォーマンスを最適化する - Amazon Web Services ブログ
Executor
さて、前の図にExecutorというものがありました。
これの実体はYARNだとContainer、KubernetesだとPodになります。そしてこの中にJVM(Java仮想マシン)が立って、タスクが実行されていくことになります。メモリレイアウトを見ると分かりやすいので引用します。
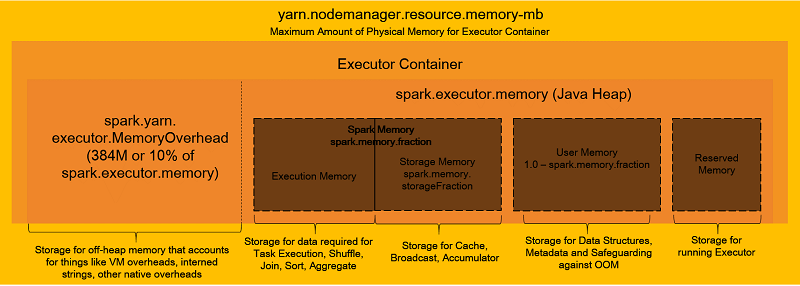
Amazon EMR で Apache Spark アプリケーションのメモリをうまく管理するためのベストプラクティス - Amazon Web Services ブログ
Sparkはなるべくインメモリでデータを処理するので、都度ファイルを読み書きする素のHadoopより高速なのですが、そのためのメモリ領域があることも見てとれますね。また処理しながら中間データのメモリを解放するため、JVMのGC (Garbage Collection)がそれなりに起きるであろうことも想像が付くと思います。
GCに馴染みのない方には、かなり古いですが次の記事が入門としてお勧めです。Eden領域はロマン。
ガベージコレクタの仕組みを理解する - チューニングのためのJava VM講座(後編) - @IT
Executorは1 Nodeに複数立てることができて、spark.dynamicAllocation.enabledが有効な場合は実行中にExecutorが自動で増えたり減ったりする様子をWeb UIで眺めることができます。
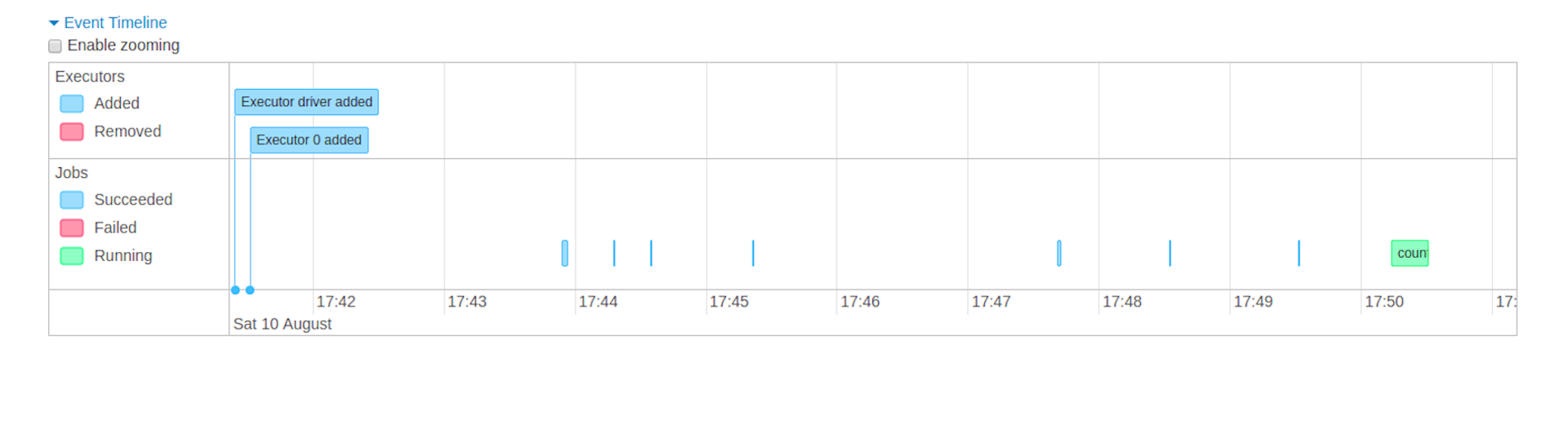
Jobs Tab - Web UI - Spark 3.0.0 Documentation
Executorに限らずSparkの設定はなかなか悩ましいところですが、まずはデフォルトないしは推奨設定にしておいてクエリレベルのチューニングに取り組んだ方がいいと思います。
MapReduce
これまで見てきたようなクラスター環境で行う分散処理の基礎モデルとして、MapReduceというものがあります。ちなみにGoogleの元論文『MapReduce: Simplified Data Processing on Large Clusters』の第一著者は『全盛期のJeff Dean伝説』というネタがある程のレジェンドです。
次の図は、HadoopにおけるMapReduceについてのものなのですが、Sparkでも大きな考え方は同じなので引用します。
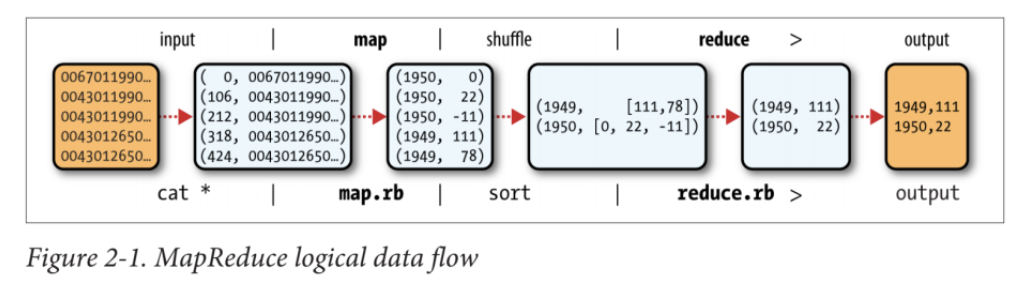
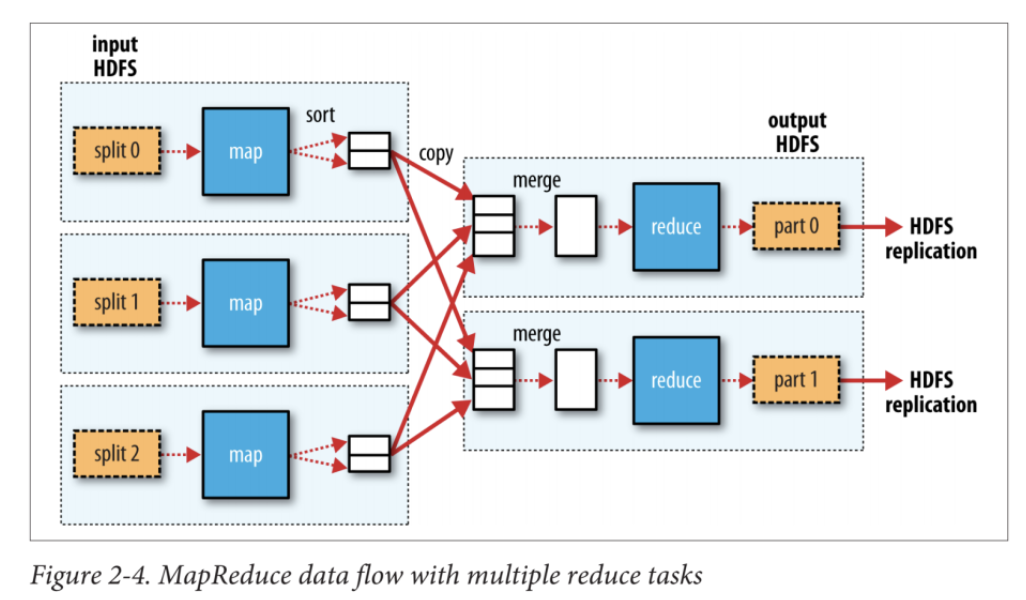
Hadoop: The Definitive Guide [Book] - O'Reilly
「Map」「Reduce」は関数型プログラミングに慣れていれば、ScalaやPythonなどで同名のメソッドを使ったことがあるでしょうから、イメージが付きやすいと思います。「Shuffle」はデータのパーティションをシャッフルして作りなおす必要がある操作で、このときWorker Node間で通信が行われます。
SQLと対応付けてみると、だいたいこんな感じです。
| MapReduce | SQL |
|---|---|
| Input | FROM |
| Map | SELECT、WHERE、HAVING |
| Shuffle | JOIN、GROUP BY、ORDER BY |
| Reduce | SUMなどの集約関数 |
| Output | INSERT |
※ 正確には後述のように、JoinはアルゴリズムによってShuffleしなかったりします。
「Input」「Map」「Shuffle」「Reduce」「Output」どのフェーズもボトルネックになりえるので、どの操作がどのフェーズで行われていてCPU・メモリ・I/O・ネットワークへの負荷がどのくらい掛かっているのか、を把握するのがパフォーマンスチューニングのポイントになってきます。
場合によっては、クラスタをスケールアップしたりスケールアウトすることになるかもしれません。
Dataset (DataFrame) / RDD
ここまで分散処理の考え方を見てきたのですが、集計クエリを書くときはデータがどうパーティショニングされているかなどは意識せずに、論理的なデータを扱いたいですね。そこで登場するのがみんな大好き表形式DataFrameです。
PythonのPandasを使っている方なら親しみのある用語で、実際PySparkでは .toPandas() でSparkのDataFrameをPandasのDataFrameに変換することができます。ちなみにこのデータ変換はApache Arrowで効率化よく行うことができて、Apache Arrowの主要メンバーにはPandasの作者Wes McKinneyがいたりします。
PySpark Usage Guide for Pandas with Apache Arrow - Spark 3.0.0 Documentation
(翻訳)Apache Arrowと「pandasの10項目の課題」
SparkではDataFrameより汎用的なものとしてDatasetがあって、実際 Dataset[T] の行データを表す型変数 T が Row である場合のエイリアスとして DataFrame は定義されています。
type DataFrame = Dataset[Row]
org/apache/spark/sql/package.scala#L46
Row は任意のスキーマの行を表すことができるクラスなので DataFrame だけでも事足りるのですが、 行データを表す型変数 T は Row だけでなくScalaのcase classも使えます。そうすると行単位の処理をよりScalaらしく簡潔に書くことができて、さらに型情報でスキーマを表すことができる利点があります。そのため型安全……と言いたいところですが、ちょっとややこしい事情があって詳しくは過去記事を参照してください。
SparkのDataFrame/Datasetって型安全なの?
さて、Datasetに対する操作はメソッドチェーンな書き方とSQLな書き方があります。C#のLINQに似てますね。
ds.groupBy($"a")
.agg(sum($"b") as "b_sum")
ds.createGlobalTempView("table")
spark.sql("""
SELECT
a,
SUM(b) AS b_sum
FROM
global_temp.table
GROUP BY
a""")
こうして発行されたクエリを、実際のクラスター環境でどうMapReduce的に分散処理するか計画を立てるのが、Spark SQLの実行エンジンです。これには沢山のステップがあるのですが、フローチャートを見ると分かりやすいので引用します。
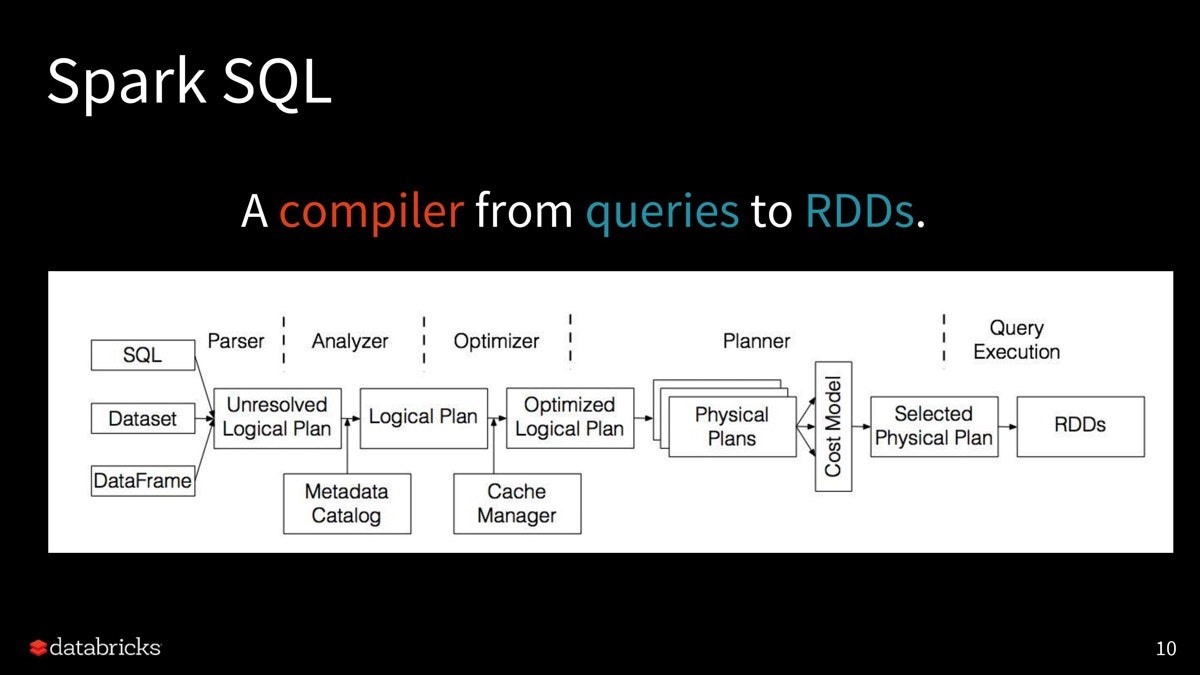
Apache Sparkコミッターが教える、Spark SQLの詳しい仕組みとパフォーマンスチューニング Part1 - ログミーTech
ここでDatasetに対するクエリから作られた最終的な実行計画 (Selected Physical Plan)が何を操作しているかというと、それはRDD (Resilient Distributed Dataset)というデータ構造になります。
Datasetがなかった昔のSparkではRDD操作をユーザーが直接コーディングしていたのですが、JoinなどのShuffle時に自力でKey-Value形式への変換処理などを書く必要があったそうで、Spark SQLの実行エンジンはそれらを自動でやってくれるすごいやつなのですね。もちろん万能ではないので、後述するJoin Hintなどで戦略を与えた方がいい場合もありますが、RDDを直接扱うべきシチュエーションはまず無いと思います。
ただ、Sparkの中でRDDは生きているので、耐障害性などの利点はそのままDataset操作にも引き継がれているというわけです。このおかげで、たとえばEMRでWorker Nodeにスポットインスタンスを使用していたとして処理中にインスタンスが中断されたとしても、そのインスタンスが抱えていたデータは残りのWorker Nodeによって再生成が試みられます。
この仕組みについては、次のスライドが分かりやすいので引用します。
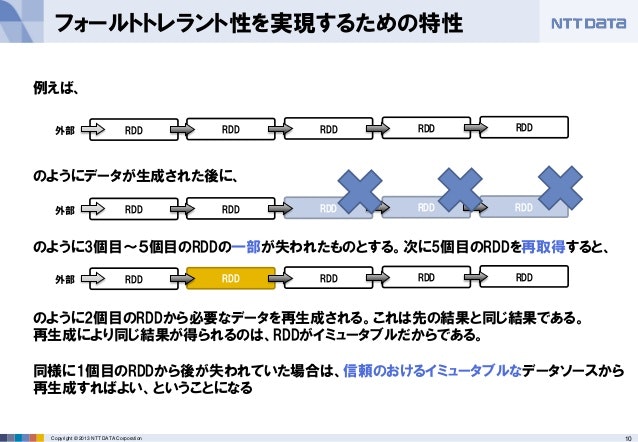
Apache Sparkのご紹介 (後半:技術トピック) - SlideShare
Application / Job / Stage / Task
Sparkがどのような実行計画で分散処理するか知るための手がかりとして、実行前ならばEXPLAIN、実行後であればWeb UIがあります。Web UIではJob、Stage、Taskといった実行単位が見えますね。
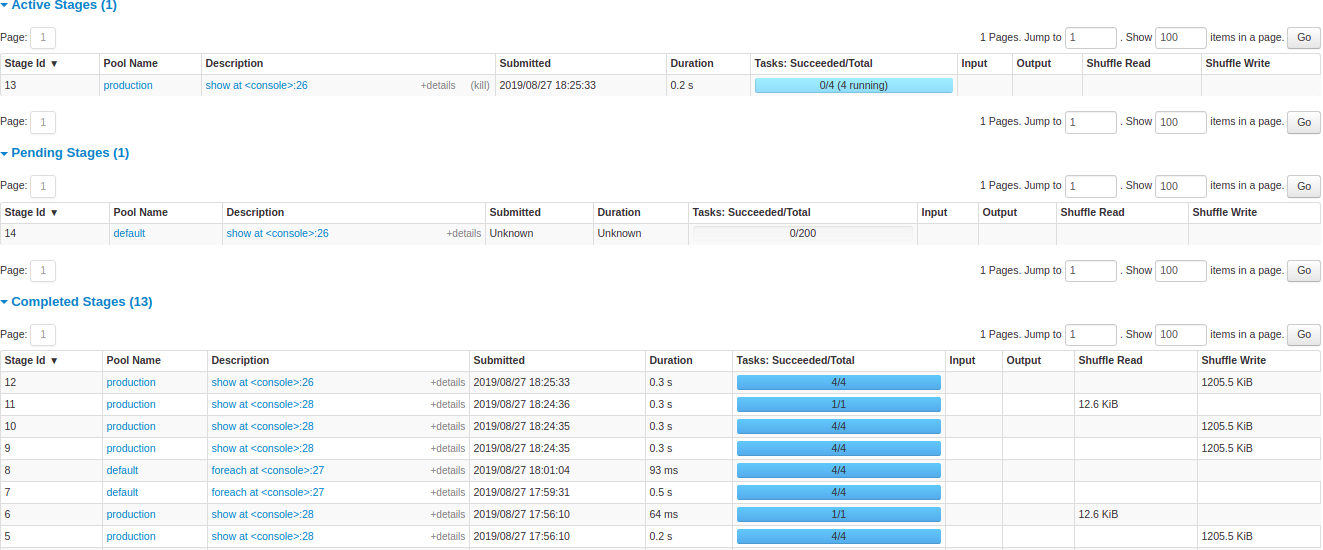
Stages Tab - Web UI - Spark 3.0.0 Documentation
これは次のような階層構造になっています。
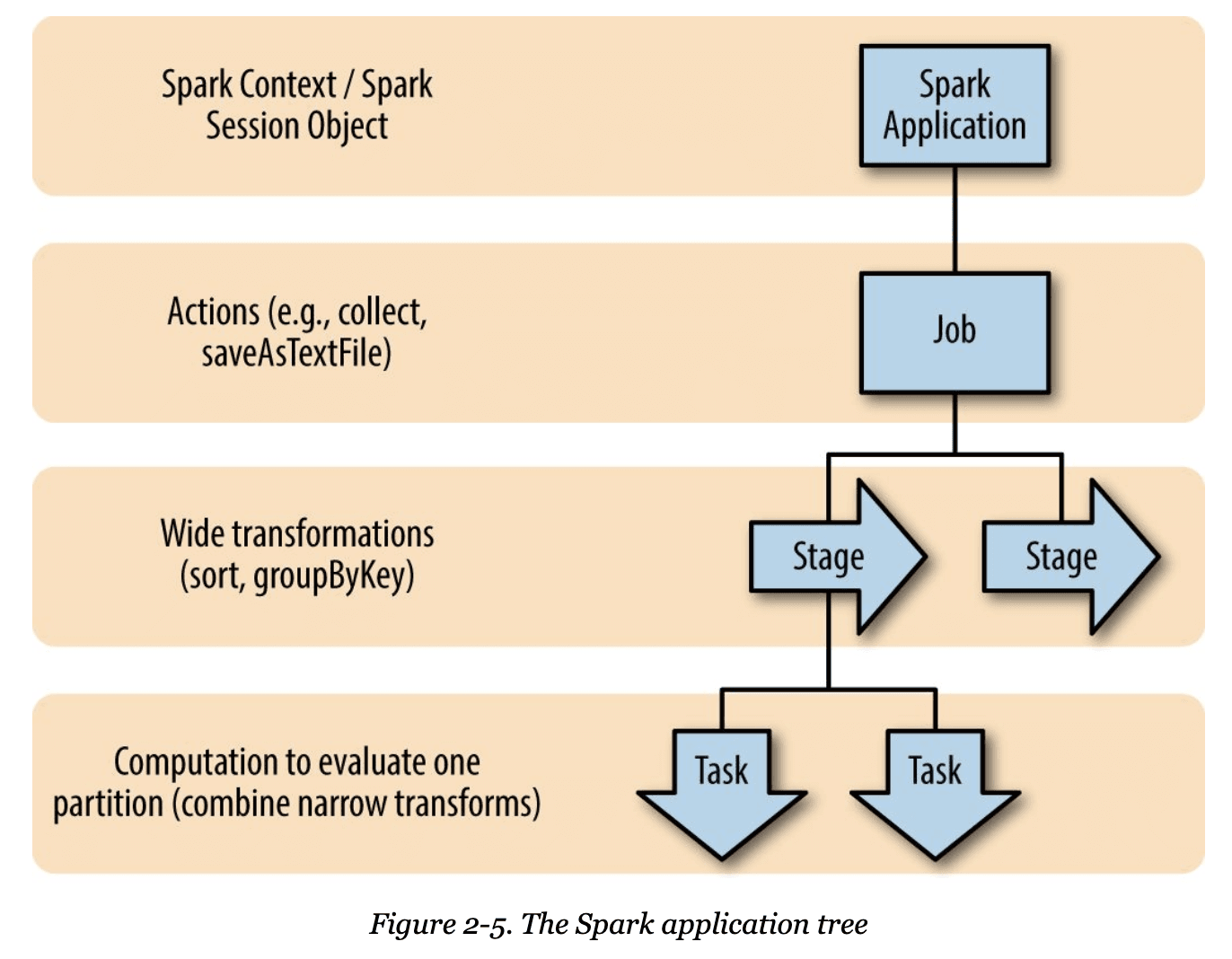
High Performance Spark [Book] - O'Reilly
まず抑えておくべきポイントは、Sparkのデータ処理は遅延評価ということです。
ではどのタイミングで評価が走るかというと、それはActionと呼ばれるメソッドを呼んだ時です。これはDatasetの外の世界に出るような操作、すなわち collect してScalaのArrayに変換したり write して外部ストレージに出力したりしたりする操作が該当します。
このActionごとに、これまで書かれたDataset操作を辿ったDAG (有向非巡回グラフ)が構築されて、その一纏まりをJobと呼びます。
Jobは、パーティションごとの実行単位であるTaskで構成されているのですが、その間にStageという実行単位があります。これはNode間で待ち合わせをしないといけないShuffleで区切られるもので、つまりStage内ではパーティションの並列処理ができるようになっています。RDDの元論文から引用します。
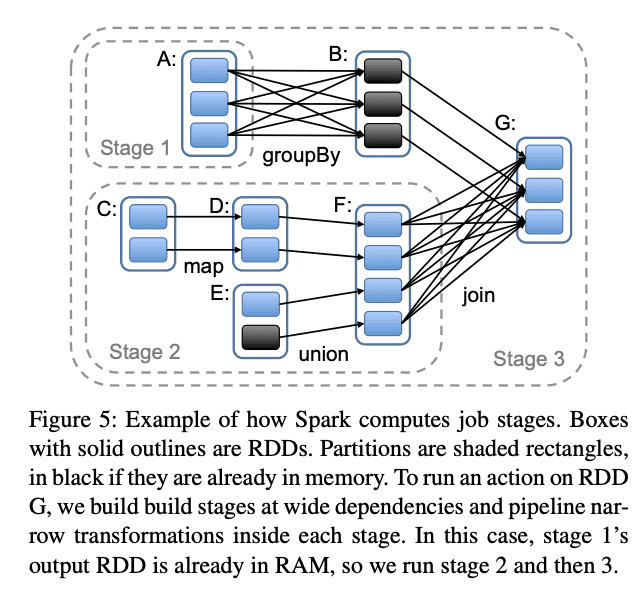
Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing
実際に構築されたDAGはWeb UIで眺めることができます。これが複雑なグラフになってくると、なんだかすごく高級な集計をやった気になれますね……!
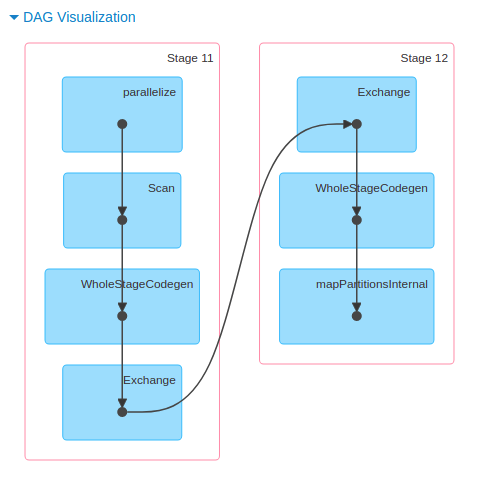
Jobs detail - Web UI - Spark 3.0.0 Documentation
Cache
ここまででSpark SQLの分散処理を理解するための基本的な用語・概念は一通りさらえたかなと思うのですが、では実際のパフォーマンスチューニングで初めに検討した方がいいのは何かというと、それはキャッシュ機能の活用になります。具体的には ds.cache() や ds.persist(MEMORY_AND_DISK) のようにしてキャッシュできます。
公式ドキュメントでも真っ先に言及されていますね。
Caching Data In Memory - Performance Tuning - Spark 3.0.0 Documentation
キャッシュを検討するべき明らかなサインは、コード上に何度も使い回すようなDatasetが現れた時です。
このあたりはPandasのDataFrameと感覚の異なるところで、Sparkは遅延評価なのでコード上ではサブクエリを共通化したつもりでも、実行されるDAGでは次のスライドのように分裂することがあります。
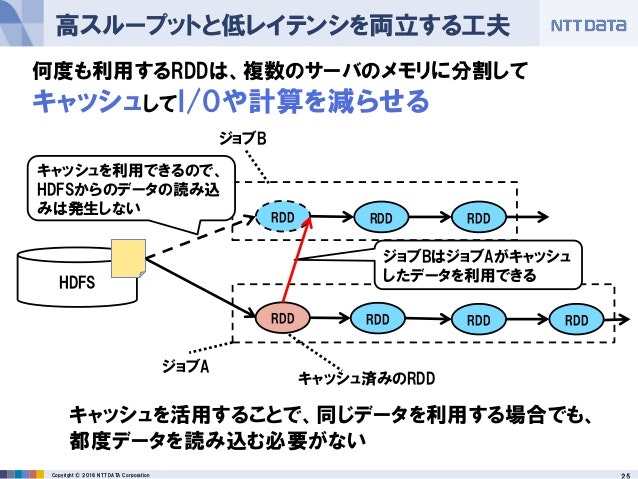
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料) - SlideShare
他の効用として、キャッシュはRDD再生成のためのセーブポイントになるので、重い処理中に不安になったら仕掛けておくこともあります。
もちろんキャッシュしすぎもよくなくて保存先のメモリなりストレージを食うので、Web UIを眺めて圧迫感を覚えたら ds.unpersist() や spark.sqlContext.clearCache() によるキャッシュのクリアも検討しましょう。

Storage Tab - Web UI - Spark 3.0.0 Documentation
Join
お待たせしました。Spark SQLチューニングの華、Joinアルゴリズムです!
└(´ー`┌)└(´ー`)┘(┐´ー`)┘ヤンヤヤンヤ♪
まず代表的なJoinアルゴリズムといえば、Shuffle Hash Joinです。
イメージとしては次のスライドが分かりやすく、それぞれJoinキーのハッシュ値を計算してShuffleを行い、転送先のパーティションでハッシュ値を元にJoinします。
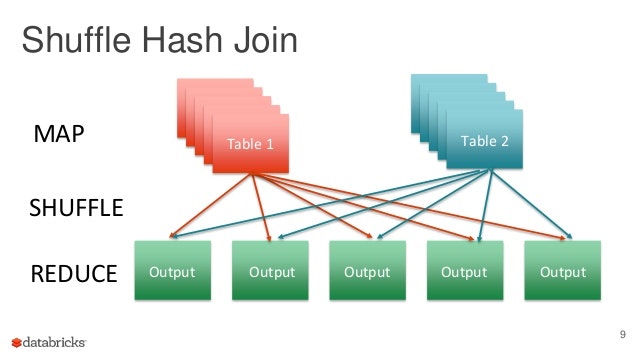
Optimizing Apache Spark SQL Joins
ここで気をつけないといけないのは、Joinキーによってデータサイズが著しく偏っている場合です。Shuffle後のパーティション配置がアンバランスになって並列性が落ちているようであれば、状況によってはJoinキーの再検討をした方がいいかもしれません。
並列性の確認はWeb UIのタイムラインを眺めたり、NodeごとのCPU・メモリ使用率を眺めたりします。
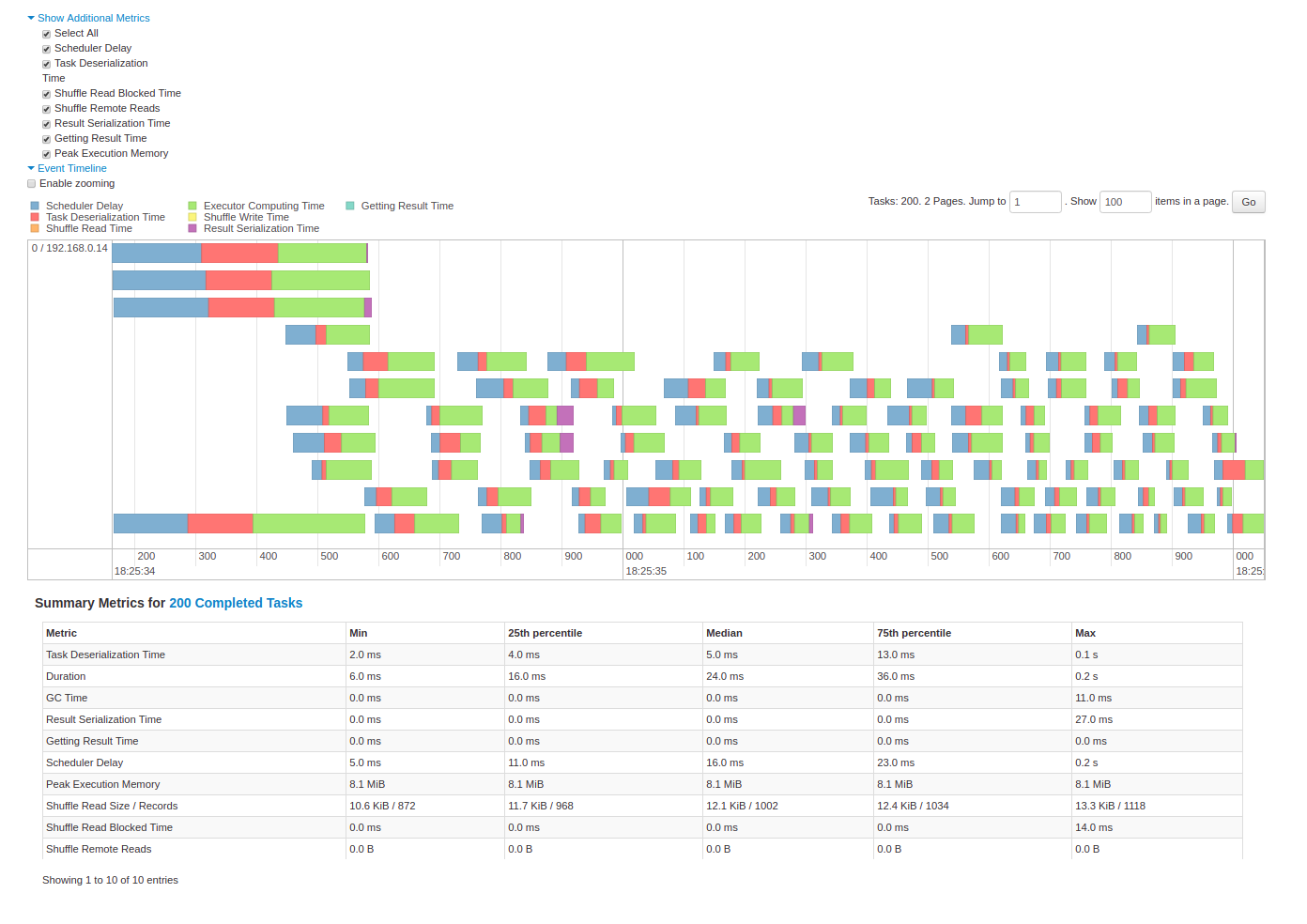
Stage detail - Web UI - Spark 3.0.0 Documentation
また、片方のデータ量が小さい場合にはそれをブロードキャストしてしまったのち、もう片方のパーティションごとにHash Joinしてしまった方が速い時があります。時間と空間のトレードオフですね。
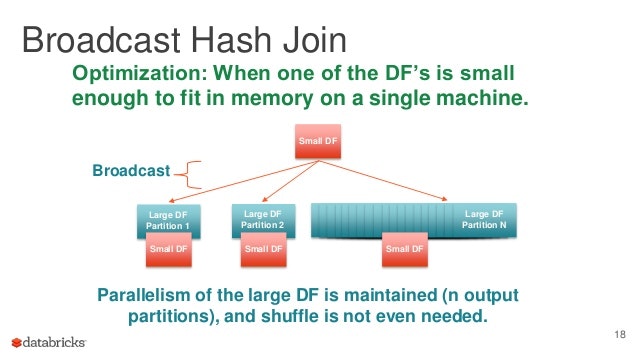
Optimizing Apache Spark SQL Joins
では、Spark SQLはブロードキャストした方がいいのかどう判断しているかというと、ANALYZE TABLEの結果などを元に推定したデータサイズがspark.sql.autoBroadcastJoinThresholdを超えるかどうか、をチェックしています。詳しい推定方法については実装を参照してください。
org/apache/spark/sql/catalyst/plans/logical/statsEstimation
ただ推定値はそれなりに外す場合もあるので、Spark 3からAdaptive Query Executionという機能が追加されました。実行時の統計情報を利用して、Sort Merge JoinをBroadcast Hash Joinに切り替えたりできるそうです。
Converting sort-merge join to broadcast join - Performance Tuning - Spark 3.0.0 Documentation
Spark SQL Adaptive Execution at 100 TB
場合によってはSpark SQLの判断結果がいけてなくて、Joinアルゴリズムを指定したい場合があるとおもいます。その場合はJoin Hintを指定することで誘導することができます。
Join Hints - Hints - Spark 3.0.0 Documentation
Join Hintとアルゴリズムの正確な対応関係はドキュメントに載っていないのですが、実装を追うと次のようになっているみたいです。
なお本記事では紹介しきれてないですが、Hash Joinは速いものの等価条件の時しか使えないので、そのような時は別のアルゴリズムを使う必要があります。それでは遅い場合、不等号条件であっても値を丸めるなどして等価条件に持ちこめないか検討してみてください。
| Hint | EXPLAIN | Join条件 |
|---|---|---|
| broadcast | BroadcastHashJoin | 等価のみ |
| broadcast | BroadcastNestedLoopJoin | 制約なし |
| merge | SortMergeJoin | 等価のみ、ソート可能 |
| shuffle_hash | ShuffledHashJoin | 等価のみ |
| shuffle_replicate_nl | CartesianProduct | 制約なし |
- Hintの実装 org/apache/spark/sql/catalyst/plans/logical/hints.scala
- EXPLAINの実装 org/apache/spark/sql/execution/joins
- Strategyのコメント org/apache/spark/sql/execution/SparkStrategies.scala #L106 #L228
ちなみにアルゴリズムの詳細も実装を追うしかなさそうなのですが、たとえばShuffle Hash Joinについて知りたければ、まずShuffledHashJoinExecクラスを読みます。
protected override def doExecute(): RDD[InternalRow] = {
val numOutputRows = longMetric("numOutputRows")
streamedPlan.execute().zipPartitions(buildPlan.execute()) { (streamIter, buildIter) =>
val hashed = buildHashedRelation(buildIter)
join(streamIter, hashed, numOutputRows)
}
}
org/apache/spark/sql/execution/joins/ShuffledHashJoinExec.scala#L65
ここで buildPlan というのはHash Joinする際にハッシュテーブルを作る方で、 streamedPlan はループを回しながらそのハッシュテーブルとマッチさせる方です。 zipPartitions はそういったHash Joinをパーティションごとにやりなさいと言っているのですが、ではShuffleの気持ちはどこにあるかというと、
override def requiredChildDistribution: Seq[Distribution] =
HashClusteredDistribution(leftKeys) :: HashClusteredDistribution(rightKeys) :: Nil
org/apache/spark/sql/execution/joins/ShuffledHashJoinExec.scala#L49
の部分で指定された HashClusteredDistribution を受けて、子計画の buildPlan や streamedPlan で ShuffleExchangeExec などが引き起こされるようです。
org/apache/spark/sql/execution/exchange/EnsureRequirements.scala#L61
EXPLAINで実行計画を表示すると、こんな感じになるでしょう。
+- ShuffledHashJoin ...
:- ShuffleExchangeExec ....
...
+- ShuffleExchangeExec ...
Data Source
ジョブの中でInputがボトルネックな場合は、Inputを司るData Sourceにもチューニングポイントがあります。
まず知っておくべきはプッシュダウンという手法で、これはフィルター処理をなるべくデータソースに近い場所で行い、なる速でデータサイズを削減して高速化しましょうというものです。
What is predicate pushdown? In mapreduce. - Quora
Data Sourceは色んなフィルター処理を行なっていて、たとえばParquetのファイルを読む場合は、
case class ParquetScan(
...
pushedFilters: Array[Filter],
...
partitionFilters: Seq[Expression] = Seq.empty,
dataFilters: Seq[Expression] = Seq.empty) extends FileScan {
org/apache/spark/sql/execution/datasources/v2/parquet/ParquetScan.scala#L35
とあって親クラスFileScanのコメントによると partitionFilters はPartition Pruningに、 dataFilters はFile Listingに使われるようです。実際にどういうフィルター処理が割り当てられたかは、次のスライドのように実行計画で読みとることができます。

Spark SQL - The internal - SlideShare
そして pushedFilters はParquetのライブラリに委譲されるフィルターで、Parquetでは次のスライドのようにRow Groupの統計情報を利用した絞り込みなどができるようです。ちなみにParquetのデータ構造入門には『カラムナフォーマットのきほん 〜データウェアハウスを支える技術〜』がお勧めです。

The Parquet Format and Performance Optimization Opportunities - SlideShare
そのためクエリレベルでもフィルター処理をなるべく前倒しにしたり、Data Sourceが対応している条件でフィルター処理を書きなおすことで実行計画が変わり、Inputが大幅に改善することがあります。
UDF
任意の関数をSpark SQLで実行できるため便利なUDF (User Defined Function)ですが、Spark SQLのネイティブ関数の方が実行最適化されるため、同じ計算ができるのであればネイティブ関数を組み合わせたほうがパフォーマンス上有利です。
https://spark.apache.org/docs/latest/api/java/org/apache/spark/sql/Column.html
https://spark.apache.org/docs/latest/api/java/org/apache/spark/sql/functions.html
なぜそうなるのか試しに array_max の実装を覗いてみましょう。
case class ArrayMax(child: Expression)
extends UnaryExpression with ImplicitCastInputTypes with NullIntolerant {
// ....
override protected def doGenCode(ctx: CodegenContext, ev: ExprCode): ExprCode = {
// ....
ev.copy(code =
code"""
|${childGen.code}
|boolean ${ev.isNull} = true;
|$javaType ${ev.value} = ${CodeGenerator.defaultValue(dataType)};
|if (!${childGen.isNull}) {
| for (int $i = 0; $i < ${childGen.value}.numElements(); $i ++) {
| ${ctx.reassignIfGreater(dataType, ev, item)}
| }
|}
""".stripMargin)
}
override protected def nullSafeEval(input: Any): Any = {
var max: Any = null
input.asInstanceOf[ArrayData].foreach(dataType, (_, item) =>
if (item != null && (max == null || ordering.gt(item, max))) {
max = item
}
)
max
}
}
nullSafeEval は普通のScala実装ですが doGenCode はJavaのコードを生成……しかも子コードの埋め込みなどもしていて、C言語の#defineマクロによるメタプログラミングのようなことをしています。
レコードごとオペレータごとに nullSafeEval のような普通の関数を呼びだす実装だと、ビッグデータ相手では仮想関数テーブルやコールスタックを引くコストすら塵も積もれば山となってしまうため、モジュール化を避けた素朴なコードに変換することでそれらのコストを避け、JVMによるJITのループ展開も期待できるという代物です。さらにこのコード生成はwhole-stage codegenという仕組みにより、できるだけ複数の操作をまとめて一つの大きなJavaのコードにしようとします。ただ大きすぎるとJVMの制限に引っかかるため、その際は分割します。
https://databricks.com/blog/2016/05/23/apache-spark-as-a-compiler-joining-a-billion-rows-per-second-on-a-laptop.html
https://databricks.com/jp/session_na20/understanding-and-improving-code-generation
この仕組みのおかげで、SparkユーザはSQLの高く抽象化された操作を書くだけで、カリカリにチューニングされた職人コードのパフォーマンスを手に入れられるというわけです。凄まじい努力ですね……。
コード生成が行われているかどうかは実行計画で「*」が付いているかどうかで確認できて、付いていない場合はShuffleのようなコード生成対象でない操作か、もしくは nullSafeEval のような普通の関数がインタープリタ実行されているようです。
== Physical Plan ==
*Aggregate(functions=[sum(id#201L)])
+- Exchange SinglePartition, None
+- *Aggregate(functions=[sum(id#201L)])
+- *Filter (id#201L > 100)
+- *Range 0, 1, 3, 1000, [id#201L]
対してUDFは、データ変換をしてUDF呼び出したのちまたデータ変換するため、それなりのオーバーヘッドがあります。
PySparkを使っている場合は、さらにJVMとPythonを行き来するオーバーヘッドがあります。Pandas UDFはApache Arrowでデータを受け渡すためPython UDFより効率は良いですが、それでもScala UDFとは桁違いに遅くなるようです。
https://www.slideshare.net/databricks/a-deep-dive-into-query-execution-engine-of-spark-sql
https://medium.com/quantumblack/spark-udf-deep-insights-in-performance-f0a95a4d8c62
ということでUDFを使いたくなったら、
- Sparkのネイティブ関数の組み合わせで表現できないか検討する。
- 表現できない場合は、なるべくScala(もしくはJava)でUDFを書く。
- 実行速度を切り詰めたい場合は、頑張ってJavaのコード生成まで実装する。