psycopg2ライブラリのソースコード(テストコード含む)からバッチ処理に適したクエリーの作成と実行方法を検討します。
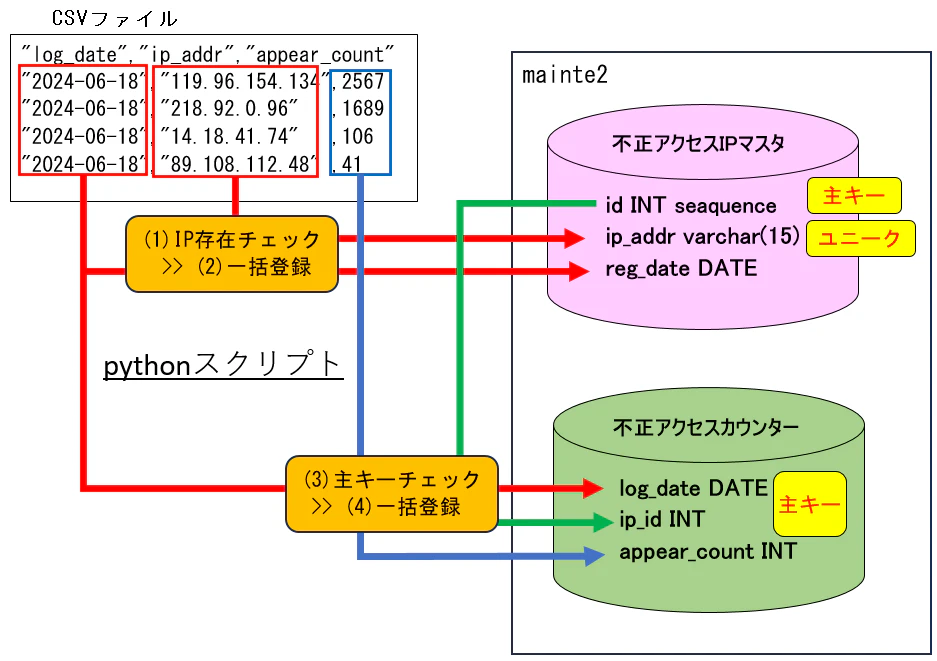
今回紹介するバッチ処理で登録する元ネタとなるデータは下記のようなCSVファイルでこのファイルをもとに2つのテーブルに一括登録するpythonスクリプトを作成します。
"log_date","ip_addr","appear_count"
"2024-06-18","119.96.154.134",2567
"2024-06-18","218.92.0.96",1689
"2024-06-18","14.18.41.74",106
"2024-06-18","89.108.112.48",41
CSVファイルの一括登録処理のイメージは下記のようになります。
動作環境
- Ubuntu 22.04 Desktop
- データベース: PostgreSQL 16 on docker
- python
- version: 3.10.12
プロジェクト専用のpython仮想環境を作成しpythonスクリプトを実行 - pythonライブラリ
psycopg2-binary==2.9.9
- version: 3.10.12
ソースコードのダウンロード
公式ドキュメント
- Psycopg – PostgreSQL database adapter for Python
-
Installation
このページの [Build prerequisites] に ソースコード(GitHub)へのリンクがあるのでそこからソースコードをクローンします。
$ git clone https://github.com/psycopg/psycopg2.git
参照するソースの箇所
参考にするソースの箇所は下記 [lib] と [tests] ディレクトリです
psycopg2/
├── doc
│ └── src
│ ├── _static
│ ├── _templates
│ └── tools
│ └── lib
├── lib # psycopg2 pythonソース
├── psycopg # psycopg2 cのソースコード
├── scripts
│ └── build
└── tests # pythonテストコード
参考にするソースコードは下記の★印になります
lib
├── __init__.py
├── extensions.py
├── extras.py # ★
└── ....py
tests
├── __init__.py
├── test_fast_executemany.py # ★
└── ....py
1. psycopg2のpythonソースコード
バッチ処理に適した関数のソースコード (pydocとコメントを省略したもの) を下記に示します。
※curosr.execute_batch 、curosr.execute_values は version 2.7以上の機能
...一部省略...
# ジェネレータ
def _paginate(seq, page_size):
page = []
it = iter(seq)
while True:
try:
for i in range(page_size):
page.append(next(it))
yield page
page = []
except StopIteration:
if page:
yield page
return
1-1.戻り値を返さない一括処理メソッド cursor.execute_batch
この関数はページング回数分のクエリを1回のリクエストで実行する関数です。
return していないので戻り値を返すことはありません。
def execute_batch(cur, sql, argslist, page_size=100):
for page in _paginate(argslist, page_size=page_size):
sqls = [cur.mogrify(sql, args) for args in page]
cur.execute(b";".join(sqls))
1-1-1.対応するテストクラス TestExecuteBatch
一括登録処理のテストコードのみ抜粋して下記に示します。
class TestExecuteBatch(FastExecuteTestMixin, testutils.ConnectingTestCase):
...一部省略...
def test_many(self):
cur = self.conn.cursor()
psycopg2.extras.execute_batch(cur,
"insert into testfast (id, val) values (%s, %s)",
((i, i * 10) for i in range(1000)))
cur.execute("select id, val from testfast order by id")
self.assertEqual(cur.fetchall(), [(i, i * 10) for i in range(1000)])
def test_pages(self):
cur = self.conn.cursor()
psycopg2.extras.execute_batch(cur,
"insert into testfast (id, val) values (%s, %s)",
((i, i * 10) for i in range(25)),
page_size=10)
# last command was 5 statements
self.assertEqual(sum(c == ';' for c in cur.query.decode('ascii')), 4)
cur.execute("select id, val from testfast order by id")
self.assertEqual(cur.fetchall(), [(i, i * 10) for i in range(25)])
1-2.戻り値を返却可能なメソッド cursor.execute_values
- [引数]
fetch=True※version 2.8で追加された
SQLで指定した戻り値をリスト(戻り値はタブル)で返却します。
この関数のポイントは pre, post = _split_sql(sql) の処理に有ります。
1-2-1のテストコード test_returning()のSQLの場合
insert into testfast (id, val) values %s returning id
分解されたpreとpostの値は下記のようになり、ソースコードではこの間にパラメータのカッコ(コンマ区切り)付きデータ文字列を生成し最終的なSQLを組み立てて実行します。
(A) pre = b'insert into testfast (id, val) values '
(B) post = b' returning id'
パラメータのカッコ(コンマ区切り)付きデータ文字列の生成には、引数のtemplateが使用されます。
-
[引数]
template- None: 位置パラメータで必要なフィールドの個数分"%s"をカンマ区切りで生成する
生成される template (bytes) (例) b'(%s,%s)' - 辞書オブジェクトのキーに対応する文字列を指定
(例) template='(%(id)s, %(val)s)'
- None: 位置パラメータで必要なフィールドの個数分"%s"をカンマ区切りで生成する
-
パラメータからデータ部を生成
-
parts.append(cur.mogrify(template, args))
データ部リストにパラメータからデータを生成し (例) b'(1, 10)' に追加する -
parts.append(b',')
生成したデータに続いてカンマを追加
-
-
parts[-1:] = post
リスト内の最後のカンマ(b',') を postで上書きする
※ parts はバイトのリスト
(例) parts: [b'insert ... values ', b'(0,0), b',', ..., b' returning id'] -
cur.execute(b''.join(parts))
[pre,データ部, post] すべてのパーツを連結してクエリを生成しカーソルで実行する
def execute_values(cur, sql, argslist, template=None, page_size=100, fetch=False):
from psycopg2.sql import Composable
if isinstance(sql, Composable):
sql = sql.as_string(cur)
if not isinstance(sql, bytes):
sql = sql.encode(_ext.encodings[cur.connection.encoding])
pre, post = _split_sql(sql)
result = [] if fetch else None
for page in _paginate(argslist, page_size=page_size):
if template is None:
template = b'(' + b','.join([b'%s'] * len(page[0])) + b')'
parts = pre[:]
for args in page:
parts.append(cur.mogrify(template, args))
parts.append(b',')
parts[-1:] = post
cur.execute(b''.join(parts))
if fetch:
result.extend(cur.fetchall())
return result
1-2-1. 対応するテストクラス TestExecuteValues
一括登録処理のテストコードのみ抜粋して下記に示します。
(1) argslistに辞書オブジェクトを指定する場合は templateを指定
@testutils.skip_before_postgres(8, 2)
class TestExecuteValues(FastExecuteTestMixin, testutils.ConnectingTestCase):
...他のテストは一部省略...
def test_dicts(self):
cur = self.conn.cursor()
psycopg2.extras.execute_values(cur,
"insert into testfast (id, date, val) values %s",
(dict(id=i, date=date(2017, 1, i + 1), val=i * 10, foo="bar")
for i in range(10)),
template='(%(id)s, %(date)s, %(val)s)')
cur.execute("select id, date, val from testfast order by id")
self.assertEqual(cur.fetchall(),
[(i, date(2017, 1, i + 1), i * 10) for i in range(10)])
(2) 戻り値なしでデフォルトのページサイズの場合
def test_many(self):
cur = self.conn.cursor()
psycopg2.extras.execute_values(cur,
"insert into testfast (id, val) values %s",
((i, i * 10) for i in range(1000)))
cur.execute("select id, val from testfast order by id")
self.assertEqual(cur.fetchall(), [(i, i * 10) for i in range(1000)])
(3) 戻り値を取得する場合は "returning 戻り値1, 戻り値2,..." のように指定します
※このテストケースでは位置パラメータ(%s)を使っているので templateは未指定
def test_returning(self):
cur = self.conn.cursor()
result = psycopg2.extras.execute_values(cur,
"insert into testfast (id, val) values %s returning id",
((i, i * 10) for i in range(25)),
page_size=10, fetch=True)
# result contains all returned pages
self.assertEqual([r[0] for r in result], list(range(25)))
1-3. cursor.mogrify メソッドでクエリーを組み立てる
このメソッドを使うとクエリーパラメータと値をバインドした複雑なクエリーを生成することができます。
下記公式ドキュメント
Psycopg 2 documentation The cousor class
このメソッドはcursorのメソッドですがパラメータ付きのクエリーに値をバインドしたSQL(bytes)を生成するだけのものなので、架空のテーブル名とかクエリーパラメータの生成だけを確認することができます。
pythonコンソールからconnectionとcursorを生成します。
(py_psycopg2) $ python
Python 3.10.12 (main, Mar 22 2024, 16:50:05) [GCC 11.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import psycopg2
>>> from psycopg2.extensions import connection, cursor
>>> conn_dict={'host': '192.168.0.101','port': '5432','database': 'exampledb','user': 'developer','password': 'mypasswd'}
>>> conn = psycopg2.connect(**conn_dict)
>>> type(conn)
<class 'psycopg2.extensions.connection'>
>>> cur = conn.cursor()
>>> type(cur)
<class 'psycopg2.extensions.cursor'>
IN句を生成させてみます。
psycopg2ライブラリの機能で IN句 を生成する方法があるのでそれを利用します。
位置パラメータ "%s" にタプル (複数データ) を渡すと
('a1', 'a2', ..., 'aN')のようにカッコ付きのパラメータを生成してくれます。
下記公式ドキュメントで指定方法のサンプルが示されています
Psycopg: Basic module usage : Tuples adaptation
>>> qry = cur.mogrify("ip_addr in %s", (("192.168.0.1","192.168.0.2"),))
>>> qry
b"ip_addr in ('192.168.0.1', '192.168.0.2')"
[注意] 誤ってリストを渡すと ARRAY[] が生成されてしまいます。
>>> qry = cur.mogrify("ip_addr IN %s", (["192.168.0.1","192.168.0.2"],))
>>> qry
"ip_addr IN ARRAY['192.168.0.1','192.168.0.2']"
実行を前提としたSELECTクエリーを生成を確認します。
>>> qry = "SELECT id, ip_addr FROM test.unauth_ip_addr WHERE ip_addr in %s"
>>> qry = cur.mogrify(qry, (("192.168.0.1","192.168.0.2"),))
>>> qry
b"SELECT id, ip_addr FROM test.unauth_ip_addr WHERE ip_addr in ('192.168.0.1', '192.168.0.2')"
確認が終わったら忘れずにそれぞれのオブジェクトをクローズして終了します。
>>> cur.close()
>>> conn.close()
>>> exit()
(py_psycopg2) ~$
下記サイトでmogirfyを使ってexecture_value と同じようなクエリーを生成・実行する方法が紹介されています。
GeeksforGeeks: Python Psycopg2 – Insert multiple rows with one query
上記サイトの内容を参考に execute_values を模倣した関数を作ってみました。
DICT_PARAMS: Tuple[Dict[str, Any], ...] = (
{"ip_addr": "119.96.154.134", "reg_date": "2024-06-18"},
{"ip_addr": "218.92.0.96", "reg_date": "2024-06-18"},
{"ip_addr": "14.18.41.74", "reg_date": "2024-06-18"},
{"ip_addr": "89.108.112.48", "reg_date": "2024-06-18"},
)
def build_insert_rows_query(
con: connection,
logger: Optional[logging.Logger] = None) -> str:
if logger is not None:
logger.debug("DICT_PARAMS:")
for dic_param in DICT_PARAMS:
logger.debug(f"{dic_param}")
try:
cur: cursor
with con.cursor() as cur:
args: str = ",".join(
# curr.mogrify()はバインド後のパラメータの部分SQL生成 ※返却されるのはバイト
# The returned string is always a bytes string.
# 見やすくするために改行("\n")を入れていますが実際には不要
[cur.mogrify("(%(ip_addr)s, %(reg_date)s)", param).decode('utf-8') + "\n"
for param in DICT_PARAMS
]
)
# 末尾の改行1文字を取り除く: {args[:-1]} ※通常は {args}
query: str = f"""
INSERT INTO mainte2.unauth_ip_addr(ip_addr, reg_date)
VALUES {args[:-1]} RETURNING id,ip_addr"""
return query
except (Exception, psycopg2.DatabaseError) as err:
raise err
上記関数を実行したときに生成されたSQLは以下の通りになります。
DEBUG DICT_PARAMS:
DEBUG {'ip_addr': '119.96.154.134', 'reg_date': '2024-06-18'}
DEBUG {'ip_addr': '218.92.0.96', 'reg_date': '2024-06-18'}
DEBUG {'ip_addr': '14.18.41.74', 'reg_date': '2024-06-18'}
DEBUG {'ip_addr': '89.108.112.48', 'reg_date': '2024-06-18'}
INFO
INSERT INTO mainte2.unauth_ip_addr(ip_addr, reg_date)
VALUES ('119.96.154.134', '2024-06-18')
,('218.92.0.96', '2024-06-18')
,('14.18.41.74', '2024-06-18')
,('89.108.112.48', '2024-06-18') RETURNING id,ip_addr
2. テーブル定義
投稿記事用に作成したものを下記に示します。
-- Qiita投稿用テスト用スキーマ
CREATE SCHEMA mainte2;
-- 不正アクセスされたIPアドレス管理テーブル
CREATE TABLE mainte2.unauth_ip_addr(
id INTEGER NOT NULL,
ip_addr VARCHAR(15) NOT NULL,
reg_date DATE NOT NULL
);
CREATE SEQUENCE mainte2.ip_addr_id OWNED BY mainte2.unauth_ip_addr.id;
ALTER TABLE mainte2.unauth_ip_addr ALTER id SET DEFAULT nextval('mainte2.ip_addr_id');
ALTER TABLE mainte2.unauth_ip_addr ADD CONSTRAINT pk_unauth_ip_addr PRIMARY KEY (id);
-- IPアドレスは重複なし
CREATE UNIQUE INDEX idx_ip_addr ON mainte2.unauth_ip_addr(ip_addr);
-- 不正アクセスカウンターテープル
CREATE TABLE mainte2.ssh_auth_error(
log_date date NOT NULL,
ip_id INTEGER,
appear_count INTEGER NOT NULL
);
ALTER TABLE mainte2.ssh_auth_error ADD CONSTRAINT pk_ssh_auth_error
PRIMARY KEY (log_date, ip_id);
ALTER TABLE mainte2.ssh_auth_error ADD CONSTRAINT fk_ssh_auth_error
FOREIGN KEY (ip_id) REFERENCES mainte2.unauth_ip_addr (id);
ALTER SCHEMA mainte2 OWNER TO developer;
ALTER TABLE mainte2.unauth_ip_addr OWNER TO developer;
ALTER TABLE mainte2.ssh_auth_error OWNER TO developer;
3. CSVデータの一括処理
以下で紹介する問合わせ処理、登録処理ではconnectionのクローズ(又はコミット、ロールバック)は呼び出し元のスクリプトで実行します。
3-0. DB接続設定ファイルとDB接続処理モジュール
(1) DB接続設定ファイル
{
"host": "{hostname}.local",
"port": "5432",
"database": "exampledb",
"user": "developer",
"password": "examplepasswd"
}
(2) PostgreSQLデータベース接続生成クラス
- ホスト名の指定有無
- 指定: 指定されたホスト名のPCで稼働しているDBサーバーに接続
- 未指定: ローカルPCで稼働しているDBサーバーに接続
import json
import logging
import socket
from typing import Optional
import psycopg2
from psycopg2.extensions import connection
class PgDatabase(object):
def __init__(self, configfile,
hostname: Optional[str] = None,
logger: Optional[logging.Logger] = None):
self.logger = logger
with open(configfile, 'r') as fp:
db_conf = json.load(fp)
if hostname is None:
hostname = socket.gethostname()
db_conf["host"] = db_conf["host"].format(hostname=hostname)
# default connection is itarable curosr
self.conn = psycopg2.connect(**db_conf)
if self.logger is not None:
self.logger.debug(self.conn)
def get_connection(self) -> connection:
return self.conn
def rollback(self) -> None:
if self.conn is not None:
self.conn.rollback()
def commit(self) -> None:
if self.conn is not None:
self.conn.commit()
def close(self) -> None:
if self.conn is not None:
if self.logger is not None:
self.logger.debug(f"Close {self.conn}")
self.conn.close()
3-1. 不正アクセスIPマスタの登録
予め不正アクセスIPマスタに2件分のデータを登録しておきます。
※dockerコンテナ内のPostgreSQLサーバーで実行
$ docker exec -it postgres-16 bin/bash
4c08a664e90:/# echo "INSERT INTO mainte2.unauth_ip_addr (ip_addr,reg_date) VALUES ('14.18.41.74', '2024-06-18'),('89.108.112.48', '2024-06-18') RETURNING id,ip_addr;" \
| psql -Udeveloper exampledb
id | ip_addr
----+---------------
1 | 14.18.41.74
2 | 89.108.112.48
(2 rows)
4c08a664e90:/# echo "SELECT * FROM mainte2.unauth_ip_addr ORDER BY id;" \
> | psql -Udeveloper exampledb
id | ip_addr | reg_date
----+---------------+------------
1 | 14.18.41.74 | 2024-06-18
2 | 89.108.112.48 | 2024-06-18
(2 rows)
3-1-(1) 登録済みIPアドレスチェック
SQLの定義
SELECT
id,ip_addr
FROM mainte2.unauth_ip_addr
WHERE ip_addr IN %s
from logging import Logger
from typing import Any, Dict, List, Optional, Tuple
import psycopg2
from psycopg2.extensions import connection, cursor
from psycopg2.extras import execute_values
def bulk_exists_ip_addr(conn: connection,
ip_list: List[str],
logger: Optional[Logger] = None) -> Dict[str, int]:
# IN ( in_clause )
in_clause: Tuple[str, ...] = tuple(ip_list)
if logger is not None:
logger.debug(f"in_clause: {in_clause}")
try:
cur: cursor
with conn.cursor() as cur:
cur.execute("""
SELECT
id,ip_addr
FROM mainte2.unauth_ip_addr
WHERE ip_addr IN %s""",
(in_clause,)
)
if logger is not None:
# 下記コードでも正常実行できます
# logger.debug(f"{cur.query.decode('utf-8')}")
# 下記は mypyチェック時のエラー出力回避
if cur.query is not None:
logger.debug(f"{cur.query.decode('utf-8')}")
logger.debug(f"cur.rowcount: {cur.rowcount}")
# IN句で一致したIPアドレスの idとIPアドレスのタプルをすべて取得
rows: List[tuple[Any, ...]] = cur.fetchall()
if logger is not None:
logger.debug(f"rows: {rows}")
# 戻り値: IPアドレスをキーとするIPのIDの辞書
result_dict: Dict[str, int] = {ip_addr: ip_id for (ip_id, ip_addr) in rows}
return result_dict
except (Exception, psycopg2.DatabaseError) as err:
raise err
上記関数を実行したときに生成されたSQLと実行結果は以下の通りです。
DEBUG in_clause: ('119.96.154.134', '218.92.0.96', '14.18.41.74', '89.108.112.48')
DEBUG
SELECT
id,ip_addr
FROM mainte2.unauth_ip_addr
WHERE ip_addr IN ('119.96.154.134', '218.92.0.96', '14.18.41.74', '89.108.112.48')
DEBUG cur.rowcount: 2
DEBUG rows: [(1, '14.18.41.74'), (2, '89.108.112.48')]
3-1-(2) 一括登録関数 (戻り値有り)
今回のサンプルでは不正アクセスカウンターテーブルの登録には、不正アクセスIPマスタに登録したIPアドレスのIDが必要になるので psycopg2.extras.execute_values() を利用します。(psycopg2 version 2.7. 以降)
下記ドキュメントで指定方法のサンプルが示されています
psycopg2.extras – Miscellaneous goodies for Psycopg 2 : Fast execution helpers
戻り値を返却する SQLの定義
(戻り値) 登録時に発行されたID(シーケンス)とIPアドレス
INSERT INTO mainte2.unauth_ip_addr(ip_addr, reg_date)
VALUES %s RETURNING id,ip_addr
- (引数) template の指定
- クエリパラメータが辞書オブジェクト
(例)({'ip_addr':'14.18.41.74','reg_date':'2024-06-18'}, ..., {...})
[必須] template="(%(ip_addr)s, %(reg_date)s)"
- クエリパラメータが辞書オブジェクト
- (引数) fetch=True
def bulk_insert_values_with_fetch(
conn: connection,
qry_params: tuple[Dict[str, Any], ...],
logger: Optional[Logger] = None) -> Dict[str, int]:
if logger is not None:
logger.debug(f"qry_params: \n{qry_params}")
try:
cur: cursor
with conn.cursor() as cur:
rows: List[Tuple[Any, ...]] = execute_values(
cur,
"""
INSERT INTO mainte2.unauth_ip_addr(ip_addr, reg_date)
VALUES %s RETURNING id,ip_addr""",
qry_params,
template="(%(ip_addr)s, %(reg_date)s)",
fetch=True
)
# 実行されたSQLを出力
if logger is not None:
if cur.query is not None:
logger.debug(f"{cur.query.decode('utf-8')}")
logger.info(f"cur.rowcount: {cur.rowcount}")
logger.debug(f"rows: {rows}")
# 戻り値: IPアドレスをキーとするIPのIDの辞書
result_dict: Dict[str, int] = {ip_addr: ip_id for (ip_id, ip_addr) in rows}
return result_dict
except (Exception, psycopg2.DatabaseError) as err:
raise err
未登録のIPアドレス (2件) で実行したときに生成されたSQLと実行結果は以下の通りです。
DEBUG qry_params:
({'ip_addr': '119.96.154.134', 'reg_date': '2024-06-18'}, {'ip_addr': '218.92.0.96', 'reg_date': '2024-06-18'})
DEBUG
INSERT INTO mainte2.unauth_ip_addr(ip_addr, reg_date)
VALUES ('119.96.154.134', '2024-06-18'),('218.92.0.96', '2024-06-18') RETURNING id,ip_addr
INFO cur.rowcount: 2
DEBUG rows: [(3, '119.96.154.134'), (4, '218.92.0.96')]
3-1-(3) executemanyで一括登録 [参考]
まだ execute_values() 又は execute_batch が提供されていなかった時(version 2.6 以下) に一括登録した結果を取得するには下記のように executemany() と execute() を組み合わせていました。
(1) executemany()関数用のSQL定義
INSERT INTO mainte2.unauth_ip_addr(ip_addr, reg_date)
VALUES (%(ip_addr)s, %(reg_date)s)
(2) 登録IDとIPアドレスを取得するSQL定義
SELECT
id,ip_addr
FROM mainte2.unauth_ip_addr
WHERE ip_addr IN %s
executemany 実行後、登録結果を取得するクエリを実行して登録値を取得する。
def bulk_insert_many_with_fetch(
conn: connection,
qry_params: tuple[Dict[str, Any], ...],
logger: Optional[Logger] = None) -> Dict[str, int]:
try:
cur: cursor
with conn.cursor() as cur:
cur.executemany("""
INSERT INTO mainte2.unauth_ip_addr(ip_addr, reg_date)
VALUES (%(ip_addr)s, %(reg_date)s) RETURNING id,ip_addr""",
qry_params
)
# executemany()では最後に実行されたクエリーのみが出力される
if logger is not None:
if cur.query is not None:
logger.debug(f"{cur.query.decode('utf-8')}")
logger.info(f"cur.rowcount: {cur.rowcount}")
# 戻り値を取得する
# クエリーパラメータからIPアドレスのみ取り出す
ip_list: List[str] = [param['ip_addr'] for param in qry_params]
in_clause: Tuple[str, ...] = tuple(ip_list)
cur.execute("""
SELECT
id,ip_addr
FROM mainte2.unauth_ip_addr
WHERE ip_addr IN %s""",
(in_clause,)
)
rows: List[Tuple[Any, ...]] = cur.fetchall()
if logger is not None:
if cur.query is not None:
logger.debug(f"{cur.query.decode('utf-8')}")
logger.debug(f"cur.rowcount: {cur.rowcount}")
logger.debug(f"rows: {rows}")
# 戻り値: IPアドレスをキーとするIPのIDの辞書
result_dict: Dict[str, int] = {ip_addr: ip_id for (ip_id, ip_addr) in rows}
return result_dict
except (Exception, psycopg2.DatabaseError) as err:
raise err
3-1-(2)と同じ条件で実行したときに生成されたSQLと実行結果は以下の通りです。
※わかりやすくするためにコメント(#)を追加しています。
# 登録時のSQL
DEBUG qry_params:
({'ip_addr': '119.96.154.134', 'reg_date': '2024-06-18'}, {'ip_addr': '218.92.0.96', 'reg_date': '2024-06-18'})
# 最後に実行したSQLのみ出力される
DEBUG
INSERT INTO mainte2.unauth_ip_addr(ip_addr, reg_date)
VALUES ('218.92.0.96', '2024-06-18')
# 登録件数
INFO cur.rowcount: 2
# 登録結果の問い合わせ時のSQL
DEBUG
SELECT
id,ip_addr
FROM mainte2.unauth_ip_addr
WHERE ip_addr IN ('119.96.154.134', '218.92.0.96')
DEBUG cur.rowcount: 2
DEBUG rows: [(3, '119.96.154.134'), (4, '218.92.0.96')]
3-1-2. メインスクリプト
上記 3-1-(1)から(3)の関数をテストするメインスクリプトは以下のとおりです。
※実行環境 Linux に依存するコードを含んでいます。
import argparse
import csv
import logging
import os
from dataclasses import asdict, dataclass
from typing import Any, Dict, List, Optional, Tuple
from psycopg2.extensions import connection
from db import pgdatabase
from dao.unauth_ip_addr import (
bulk_exists_ip_addr,
bulk_insert_many_with_fetch, bulk_insert_values_with_fetch
)
# データベース接続情報
DB_CONF_FILE: str = os.path.join("conf", "db_conn.json")
@dataclass(frozen=True)
class RegUnauthIpAddr:
ip_addr: str
reg_date: str
def read_csv(file_name: str,
skip_header=True, header_cnt=1) -> List[str]:
with open(file_name, 'r') as fp:
reader = csv.reader(fp, dialect='unix')
if skip_header:
for skip in range(header_cnt):
next(reader)
# リストをカンマ区切りで連結する
lines = [",".join(rec) for rec in reader]
return lines
if __name__ == '__main__':
logging.basicConfig(format='%(levelname)s %(message)s')
app_logger = logging.getLogger(__name__)
app_logger.setLevel(level=logging.DEBUG)
parser: argparse.ArgumentParser = argparse.ArgumentParser()
# CSVファイル: csv/ssh_auth_error_YYYY-mm-dd.csv
parser.add_argument("--csv-file", type=str, required=True,
help="Batch insert CSV file.")
# insert_type: "values" or "many"
parser.add_argument("--insert-type", type=str,
choices=['many', 'values'],
default='values',
help="Insert type: ['many'|'values'(default)].")
args: argparse.Namespace = parser.parse_args()
# CSVファイルチェック
csv_file: str = args.csv_file
csv_path: str
if csv_file[0] == "~":
# ユーザーディレクトリ
csv_path = os.path.expanduser(csv_file)
else:
csv_path = csv_file
if not os.path.exists(csv_path):
app_logger.error(f"FileNotFound: {csv_path}")
exit(1)
csv_lines: List[str] = read_csv(csv_path)
line_size: int = len(csv_lines)
app_logger.info(f"csv line.size: {line_size}")
if line_size == 0:
app_logger.info("Empty csv record.")
exit(0)
insert_type: str = args.insert_type
# database
db: Optional[pgdatabase.PgDatabase] = None
try:
db = pgdatabase.PgDatabase(DB_CONF_FILE, logger=app_logger)
conn: connection = db.get_connection()
# CSVから取得したIPアドレス(1列目)が登録済みかチェック
ip_list: List[str] = [csv_line.split(",")[1] for csv_line in csv_lines]
exists_ip_dict: Dict[str, int] = bulk_exists_ip_addr(
conn, ip_list, logger=app_logger
)
app_logger.info(f"exists_ip_dict: {exists_ip_dict}")
# 登録済みIPアドレスを除外した追加登録用のレコードリストを作成
fields: List[str]
reg_datas: List[RegUnauthIpAddr] = []
if len(exists_ip_dict) > 0:
for csv_line in csv_lines:
fields = csv_line.split(",")
key_ip: str = fields[1]
registered_id: Optional[int] = exists_ip_dict.get(key_ip)
if registered_id is None:
reg_datas.append(
RegUnauthIpAddr(ip_addr=key_ip, reg_date=fields[0])
)
else:
app_logger.info(f"Registered: {key_ip}")
else:
# 登録済みレコードがない場合はすべて登録 ※初回登録時
reg_datas = [
RegUnauthIpAddr(
ip_addr=csv_line.split(",")[1], reg_date=csv_line.split(",")[0]
)
for csv_line in csv_lines
]
# 追加登録用のレコードリストがあれば登録する
ret_ids: Dict[str, int]
if len(reg_datas) > 0:
# dataclassを辞書のタプルに変換
params: Tuple[Dict[str, Any], ...] = tuple(
[dict(asdict(rec)) for rec in reg_datas]
)
if insert_type == "many":
ret_ids = bulk_insert_many_with_fetch(conn, params, logger=app_logger)
else:
ret_ids = bulk_insert_values_with_fetch(conn, params, logger=app_logger)
app_logger.info(f"registered ids: {ret_ids}")
else:
app_logger.info("No registered record.")
db.commit()
except Exception as exp:
app_logger.error(exp)
if db is not None:
db.rollback()
exit(1)
finally:
if db is not None:
db.close()
(実行例) python仮想環境内のpythonで実行
- [引数] --insert-type xxxx
-
values:bulk_insert_values_with_fetch()関数実行 -
many:bulk_insert_many_with_fetch()関数実行
-
(py_psycopg2) $ python TestBulkInsert_unauth_ip_addr.py \
> --csv-file csv/ssh_auth_error_2024-06-18.csv --insert-type values
3-2. 不正アクセスカウンターテーブルの登録
このテーブルの登録では戻り値が不要なINSERTを実行するので execute_batch() または execute_values() のどちらも使用できます。
予めデータを2件分登録しておきます。
※ mainte2.unauth_ip_addr テーブルは 3-1で予め登録したレコード
$ docker exec -it postgres-16 bin/bash
# mainte2.unauth_ip_addr テーブル
ae2e372c66d9:/# echo "SELECT * FROM mainte2.unauth_ip_addr;" | psql -Udeveloper exampledb
id | ip_addr | reg_date
----+---------------+------------
1 | 14.18.41.74 | 2024-06-18
2 | 89.108.112.48 | 2024-06-18
(2 rows)
# mainte2.ssh_auth_errorテーブルに手動で追加する
ae2e372c66d9:/# echo "INSERT INTO mainte2.ssh_auth_error (log_date,ip_id,appear_count) VALUES ('2024-06-18',1,106),('2024-06-18',2,41);" \
> | psql -Udeveloper exampledb
# 登録済みテーブル確認
ae2e372c66d9:/# echo "SELECT * FROM mainte2.ssh_auth_error;" | psql -Udeveloper exampledb
log_date | ip_id | appear_count
------------+-------+--------------
2024-06-18 | 1 | 106
2024-06-18 | 2 | 41
(2 rows)
3-2-(1) 登録済みレコードチェック
SQLの定義
SELECT
ip_id
FROM
mainte2.ssh_auth_error
WHERE
log_date = %(log_date)s AND ip_id IN %(in_clause)s
クエリーパラメータには辞書オブジェクトのキーを設定。
from logging import Logger
from typing import Any, Dict, List, Optional, Tuple
import psycopg2
from psycopg2.extensions import connection, cursor
from psycopg2.extras import execute_values, execute_batch
def bulk_exists_logdate_with_ipid(
conn: connection,
log_date: str,
ipid_list: List[int],
logger: Optional[Logger] = None) -> List[int]:
# IN ( in_clause )
in_clause: Tuple[int, ...] = tuple(ipid_list, )
if logger is not None:
logger.debug(f"in_clause: \n{in_clause}")
try:
cur: cursor
with conn.cursor() as cur:
cur.execute("""
SELECT
ip_id
FROM
mainte2.ssh_auth_error
WHERE
log_date = %(log_date)s AND ip_id IN %(in_clause)s""",
{'log_date': log_date, 'in_clause': in_clause}
)
# 実行されたSQLを出力
if logger is not None:
if cur.query is not None:
logger.debug(f"{cur.query.decode('utf-8')}")
logger.info(f"cur.rowcount: {cur.rowcount}")
# 戻り値を取得する
# def fetchall(self) -> list[tuple[Any, ...]]
rows: List[Tuple[Any, ...]] = cur.fetchall()
if logger is not None:
logger.debug(f"rows: {rows}")
# 結果が1カラムだけなのでタプルの先頭[0]をリストに格納
result: List[int] = [row[0] for row in rows]
return result
except (Exception, psycopg2.DatabaseError) as err:
raise err
上記関数を実行したときに生成されたSQLと実行結果は以下の通りです。
DEBUG in_clause:
(3, 4, 1, 2)
DEBUG
SELECT
ip_id
FROM
mainte2.ssh_auth_error
WHERE
log_date = '2024-06-18' AND ip_id IN (3, 4, 1, 2)
INFO cur.rowcount: 2
DEBUG rows: [(1,), (2,)]
3-2-(2) execute_batch() 関数の使用
SQL定義
INSERT INTO mainte2.ssh_auth_error(log_date, ip_id, appear_count)
VALUES (%(log_date)s, %(ip_id)s, %(appear_count)s)
クエリパラメータには辞書オブジェクトを設定。
def bulk_insert_batch(
conn: connection,
qry_params: tuple[Dict[str, Any], ...],
logger: Optional[Logger] = None) -> None:
if logger is not None:
logger.debug(f"qry_params: \n{qry_params}")
try:
cur: cursor
with conn.cursor() as cur:
# 戻り値を返さない関数
execute_batch(
cur,
"""
INSERT INTO mainte2.ssh_auth_error(log_date, ip_id, appear_count)
VALUES (%(log_date)s, %(ip_id)s, %(appear_count)s)""",
qry_params)
# 実行されたSQLを出力
if logger is not None:
if cur.query is not None:
logger.debug(f"{cur.query.decode('utf-8')}")
logger.info(f"cur.rowcount: {cur.rowcount}")
except (Exception, psycopg2.DatabaseError) as err:
raise err
上記関数を実行したときに生成されたSQLと実行結果は以下の通りです。
INSERT文が2回連続リクエストされています (DEBUGのあと2回出力されている)
※1 登録件数 cur.rowcount: 正しい登録件数は出力されません
DEBUG qry_params:
({'log_date': '2024-06-18', 'ip_id': 3, 'appear_count': 2567}, {'log_date': '2024-06-18', 'ip_id': 4, 'appear_count': 1689})
DEBUG
INSERT INTO mainte2.ssh_auth_error(log_date, ip_id, appear_count)
VALUES ('2024-06-18', 3, 2567);
INSERT INTO mainte2.ssh_auth_error(log_date, ip_id, appear_count)
VALUES ('2024-06-18', 4, 1689)
# バッチ実行の場合 cur.rowcountは正しい値を返却しない
INFO cur.rowcount: 1
3-2-(3) execute_values() 関数の使用
SQL定義
INSERT INTO mainte2.ssh_auth_error(log_date, ip_id, appear_count)
VALUES %s
デフォルトで fetch=False なのでこの引数は指定しない。
template="(%(log_date)s, %(ip_id)s, %(appear_count)s)"
def bulk_insert_values(
conn: connection,
qry_params: tuple[Dict[str, Any], ...],
logger: Optional[Logger] = None) -> None:
if logger is not None:
logger.debug(f"qry_params: \n{qry_params}")
try:
cur: cursor
with conn.cursor() as cur:
# 登録の戻り値不要
execute_values(
cur,
"""
INSERT INTO mainte2.ssh_auth_error(log_date, ip_id, appear_count)
VALUES %s""",
qry_params,
template="(%(log_date)s, %(ip_id)s, %(appear_count)s)",
)
# 実行されたSQLを出力
if logger is not None:
if cur.query is not None:
logger.debug(f"{cur.query.decode('utf-8')}")
logger.info(f"cur.rowcount: {cur.rowcount}")
except (Exception, psycopg2.DatabaseError) as err:
raise err
上記関数を実行したときに生成されたSQLと実行結果は以下の通りです。
※1 登録件数 cur.rowcount: ページ数(100)を超えた場合は端数の件数が出力されます
DEBUG
INSERT INTO mainte2.ssh_auth_error(log_date, ip_id, appear_count)
VALUES ('2024-06-18', 3, 2567),('2024-06-18', 4, 1689)
INFO cur.rowcount: 2
3-2-(4) executemany() 関数の使用 [参考]
SQL定義
INSERT INTO mainte2.ssh_auth_error(log_date, ip_id, appear_count)
VALUES (%(log_date)s, %(ip_id)s, %(appear_count)s)
クエリーパラメータは辞書オブジェクト
def bulk_insert_many(
conn: connection,
qry_params: tuple[Dict[str, Any], ...],
logger: Optional[Logger] = None) -> None:
if logger is not None:
logger.debug(f"qry_params: \n{qry_params}")
try:
cur: cursor
with conn.cursor() as cur:
cur.executemany("""
INSERT INTO mainte2.ssh_auth_error(log_date, ip_id, appear_count)
VALUES (%(log_date)s, %(ip_id)s, %(appear_count)s)""",
qry_params
)
# executemany()では最後に実行されたクエリーのみが出力される
if logger is not None:
if cur.query is not None:
logger.debug(f"{cur.query.decode('utf-8')}")
logger.info(f"cur.rowcount: {cur.rowcount}")
except (Exception, psycopg2.DatabaseError) as err:
raise err
上記関数を実行したときに生成されたSQLと実行結果は以下の通りです。
※1 INSERT文はリクエストごと1回づつ実行するので、DEBUGで出力されるSQLは一番最後のものが出力されます。
※2 登録件数 cur.rowcount: この関数(executemany)のみ正しい登録件数を出力します。
DEBUG qry_params:
({'log_date': '2024-06-18', 'ip_id': 3, 'appear_count': 2567}, {'log_date': '2024-06-18', 'ip_id': 4, 'appear_count': 1689})
DEBUG
INSERT INTO mainte2.ssh_auth_error(log_date, ip_id, appear_count)
VALUES ('2024-06-18', 4, 1689)
INFO cur.rowcount: 2
3-2-2. メインスクリプト
上記 3-2-(1)から(4) を実行するメインスクリプトは以下のとおりです。
※実行環境 Linux (Ubuntu) に依存するコードを含んでいます。
import argparse
import csv
import logging
import os
from dataclasses import asdict, dataclass
from typing import Any, Dict, List, Optional, Tuple
from psycopg2.extensions import connection
from db import pgdatabase
from dao.unauth_ip_addr import (
bulk_exists_ip_addr, bulk_insert_values_with_fetch
)
from dao.ssh_auth_error import (
bulk_exists_logdate_with_ipid,
bulk_insert_values, bulk_insert_batch, bulk_insert_many
)
# データベース接続情報
DB_CONF_FILE: str = os.path.join("conf", "db_conn.json")
@dataclass(frozen=True)
class RegUnauthIpAddr:
ip_addr: str
reg_date: str
@dataclass(frozen=True)
class SshAuthError:
log_date: str
ip_id: int
appear_count: int
def read_csv(file_name: str,
skip_header=True, header_cnt=1) -> List[str]:
with open(file_name, 'r') as fp:
reader = csv.reader(fp, dialect='unix')
if skip_header:
for skip in range(header_cnt):
next(reader)
# リストをカンマ区切りで連結する
lines = [",".join(rec) for rec in reader]
return lines
if __name__ == '__main__':
logging.basicConfig(format='%(levelname)s %(message)s')
app_logger = logging.getLogger(__name__)
app_logger.setLevel(level=logging.DEBUG)
parser: argparse.ArgumentParser = argparse.ArgumentParser()
# CSVファイル: csv/xxxx_YYYY-mm-dd.csv
parser.add_argument("--csv-file", type=str, required=True,
help="CSV file path.")
# insert_type: "batch" or "many" or "value"(default)
parser.add_argument("--insert-type", type=str,
choices=["batch", "many", "values"],
default="values",
help="Insert type: ['batch'|'many'|'values'(default)].")
args: argparse.Namespace = parser.parse_args()
app_logger.info(args)
# CSVファイルチェック
csv_file: str = args.csv_file
csv_path: str
if csv_file[0] == "~":
# ユーザーディレクトリ
csv_path = os.path.expanduser(csv_file)
else:
csv_path = csv_file
if not os.path.exists(csv_path):
app_logger.error(f"FileNotFound: {csv_path}")
exit(1)
# CSVファイル読み込み
csv_lines: List[str] = read_csv(csv_path)
line_size: int = len(csv_lines)
app_logger.info(f"csv line.size: {line_size}")
if line_size == 0:
app_logger.info("Empty csv record.")
exit(0)
insert_type: str = args.insert_type
# database
db: Optional[pgdatabase.PgDatabase] = None
try:
db = pgdatabase.PgDatabase(DB_CONF_FILE, logger=app_logger)
conn: connection = db.get_connection()
# CSVから取得したIPアドレス(2列目)が登録済みかチェック
ip_list: List[str] = [csv.split(",")[1] for csv in csv_lines]
exists_ip_dict: Dict[str, int] = bulk_exists_ip_addr(
conn, ip_list, logger=app_logger
)
app_logger.info(f"exists_ip_dict: {exists_ip_dict}")
# 登録済みIPアドレスを除外した追加登録用のレコードリストを作成
fields: List[str]
reg_unauth_ip_datas: List[RegUnauthIpAddr] = []
if len(exists_ip_dict) > 0:
# 登録済のIPアドレスに存在しなければ登録用データに追加する
for csv in csv_lines:
fields = csv.split(",")
key_ip: str = fields[1]
registered_id: Optional[int] = exists_ip_dict.get(key_ip)
if registered_id is None:
# 未登録のため追加する
reg_unauth_ip_datas.append(
RegUnauthIpAddr(ip_addr=key_ip, reg_date=fields[0])
)
else:
app_logger.info(f"Registered: {key_ip}")
else:
# 登録済みレコードがない場合はすべて登録 ※初回実行時のみ
reg_datas = [
RegUnauthIpAddr(ip_addr=csv.split(",")[1], reg_date=csv.split(",")[0])
for csv in csv_lines
]
# 新規登録データがあれば不正アクセスIPマスタに一括登録する
# ※当該日のIPアドレスがすべて不正アクセスIPマスタに登録済のケースは有りうる
if len(reg_unauth_ip_datas) > 0:
# dataclassを辞書のタプルに変換
params: Tuple[Dict[str, Any], ...] = tuple(
[asdict(rec) for rec in reg_unauth_ip_datas]
)
# 不正アクセスIPアドレステーブル新規登録
registered_ip_dict: Dict[str, int] = bulk_insert_values_with_fetch(
conn, params, logger=app_logger
)
app_logger.info(f"registered_ip_dict.size: {len(registered_ip_dict)}")
# 新たに一括登録されたIPアドレス-ID辞書を元のIPアドレス-ID辞書に追加する
exists_ip_dict.update(registered_ip_dict)
app_logger.info(f"Updated exists_ip_dict.size:{len(exists_ip_dict)}")
# else:
# すべて登録済なので追加の登録処理なし
# 不正アクセスカウンターテーブルへの一括登録用データリスト
reg_ssh_auth_error_datas: List[SshAuthError] = []
for csv in csv_lines:
fields = csv.split(",")
key_ip: str = fields[1]
# ipアドレスから ip_id を取得する ※基本的にはすべてIDを取得できる想定
ip_id: Optional[int] = exists_ip_dict.get(key_ip)
if ip_id:
reg_ssh_auth_error_datas.append(
SshAuthError(
log_date=fields[0], ip_id=ip_id, appear_count=int(fields[2])
)
)
else:
# このケースはない想定
app_logger.warning(f"{key_ip} is not registered!")
app_logger.info(f"reg_ssh_auth_error_datas.size: {len(reg_ssh_auth_error_datas)}")
# 当該日の ip_id が登録済みかどうかチェック
# ※当該日のデータが追加されるケースを想定。ただし同一データなら追加登録データ無しになる
if len(reg_ssh_auth_error_datas) > 0:
# 先頭レコードから当該日取得
log_date: str = reg_ssh_auth_error_datas[0].log_date
# 登録済チェック用の ip_id リスト生成
ipid_list: List[int] = [int(reg.ip_id) for reg in reg_ssh_auth_error_datas]
exists_ipid_list: List[int] = bulk_exists_logdate_with_ipid(
conn, log_date, ipid_list, logger=app_logger
)
# 未登録の ip_id があれば登録レコード用のパラメータを生成
if len(ipid_list) > len(exists_ipid_list):
rec_params: List[Any] = []
for rec in reg_ssh_auth_error_datas:
if rec.ip_id not in exists_ipid_list:
# 当該日に未登録の ip_id のみのレコードの辞書オブジェクトを追加
rec_params.append(asdict(rec))
else:
app_logger.info(f"Registered: {rec}")
if len(rec_params) > 0:
if insert_type == "many":
bulk_insert_many(conn, tuple(rec_params), logger=app_logger)
elif insert_type == "batch":
bulk_insert_batch(conn, tuple(rec_params), logger=app_logger)
else:
bulk_insert_values(conn, tuple(rec_params), logger=app_logger)
else:
app_logger.info(f"{log_date}: ssh_auth_errorテーブルに登録可能データなし")
# 両方のテーブル登録で正常終了したらコミット
db.commit()
except Exception as exp:
app_logger.error(exp)
if db is not None:
db.rollback()
exit(1)
finally:
if db is not None:
db.close()
(実行例) python仮想環境内のpythonで実行
- [引数] --insert-type xxxx
-
values:bulk_insert_values()関数実行 -
batch:bulk_insert_batch()関数実行 -
many:bulk_insert_many()関数実行
-
(py_psycopg2) $ python TestBulkInsert_ssh_auth_error.py \
> --csv-file csv/ssh_auth_error_2024-06-18.csv --insert-type values
3-3. 一括登録時の実行時間比較
バッチ処理に適した関数を作ったので、大量データでそれぞれの関数の実行時間を比較してみました。
[前提条件]
- 予め 不正アクセスIPマスターは登録済み
- 別なPCで動作しているデータベースサーバーにリクエスト (同一内部ネットワーク)
- 一括登録件数: 1884件
- 実行結果
-
execute_values(): 227ms
cur.rowcount: ページング(100件) の最後の端数件数になります。 -
execute_batch(): 251ms
cur.rowcount: 正しい値を返さない。 -
executemany(): 725ms
唯一この関数を実行した場合のみcur.rowcountは正しい登録件数を返却します。
-
# (1) execute_values(): 227ms
2024-07-24 13:47:08.886 INFO reg_ssh_auth_error.size: 1884
2024-07-24 13:47:08.919 INFO Batch['values'] START.
2024-07-24 13:47:09.146 INFO cur.rowcount: 84
2024-07-24 13:47:09.146 INFO Batch['values'] END.
#
# (2) execute_batch(): 251ms
2024-07-24 13:56:20.128 INFO reg_ssh_auth_error.size: 1884
2024-07-24 13:56:20.144 INFO Batch['batch'] START.
2024-07-24 13:56:20.395 INFO cur.rowcount: 1
2024-07-24 13:56:20.395 INFO Batch['batch'] END.
#
# (3) executemany(): 725ms
2024-07-24 13:58:23.488 INFO reg_ssh_auth_error.size: 1884
2024-07-24 13:58:23.504 INFO Batch['many'] START.
2024-07-24 13:58:24.228 INFO cur.rowcount: 1884
2024-07-24 13:58:24.229 INFO Batch['many'] END.
最後に
今回紹介したCSVデータとデータベースのテーブル定義は、インターネットに公開している自宅サーバー(Ubuntu server 24.04) で sshによる不正アクセスを受けたIPアドレスを集計したシステムをこの投稿記事用に簡略化したもです。
以前(CentOS stream 8 ※2024年05月末日でサポート切れ)は、手作業で auth.log を grep したものをpythonスクリプトで集計し、特にアクセス回数の多いIPアドレスをパケットフィルタリングの対象とした行きあたりばったりの対策しか行っていませんでした。
データベースで管理するようになったことで、不正アクセスするIPアドレスが1日あたりどの位の頻度で何日間連続してアクセスしているかがわかるようになり、効率的なパケットフィルタリングが可能になりました。
※1 一般的に行われているサーバーのセキュリティ対策は実施しています。
ただ残念なのは、今回の記事の元ネタになったシステムが完成したのは運用開始から約4週間後。それまでは従来のやり方でしか対応できなかったことですね。
以下に本番環境で運用しているデータベースで運用開始から3週間分のデータを集計したものを示します。
$ ./dkr_exec_show_unauth_accessed_ip.sh 2024-06-10 2024-06-30
[検索期間] 2024-06-10 〜 2024-06-30
2024-06-24 | 14.18.44.49 | 41
2024-06-26 | 14.18.44.49 | 41
2024-06-28 | 14.18.44.49 | 41
2024-06-20 | 45.10.175.248 | 41
2024-06-21 | 45.10.175.248 | 41
2024-06-22 | 45.10.175.248 | 82
2024-06-24 | 45.10.175.248 | 41
2024-06-14 | 47.242.24.122 | 41
2024-06-19 | 47.242.24.122 | 41
2024-06-26 | 47.242.24.122 | 41
2024-06-12 | 92.118.39.40 | 73
2024-06-13 | 92.118.39.40 | 252
2024-06-14 | 92.118.39.40 | 49
2024-06-12 | 103.77.241.34 | 392
2024-06-13 | 103.77.241.34 | 3269
2024-06-14 | 103.77.241.34 | 3382
2024-06-15 | 103.77.241.34 | 3345
2024-06-16 | 103.77.241.34 | 959
2024-06-20 | 111.67.194.67 | 41
2024-06-23 | 111.67.194.67 | 41
2024-06-24 | 111.67.194.67 | 41
2024-06-26 | 194.50.16.17 | 91
2024-06-27 | 194.50.16.17 | 83
2024-06-28 | 194.50.16.17 | 76
2024-06-30 | 194.50.16.17 | 32
この記事で紹介したソースコードについては下記 GitHub リポジトリで公開しています。
GitHub: pipito-yukio / qiita-posts/python/Psycopg2
本番環境のテーブル定義、シェルスクリプト、pythonスクリプトの全ソースコードは下記 GitHub で公開しています。
GitHub: pipito-yukio / ubuntu_server_tools
「3-3. 一括登録時の実行時間比較」で使用したCSVファイルは下記 GitHub リポジトリで公開しています。
GitHub: pipito-yukio / ubuntu_server_tools / csv