監視モニタリング概要
現状整っているとは言い難いので、他のサービスも含めた監視について考えてみる
全体の流れ
- CloudWatchメトリクス
- CloudWatchイベント
- CloudWatchログ
- APIで状態取得
- 何を監視すべきか
CloudWatchメトリクス
Glueジョブで"Job Metrics"を有効にしてジョブ実行すると、ジョブの各メトリクスが取得でき、CWでグラフ化やアラーム設定も可能
こちらにまとめました。ETL ジョブの CloudWatch メトリクス確認
CloudWatchイベント
現在は5つあります。こちらにまとめました。CloudWatchイベントのGlue関連対応
CloudWatchログ
GlueはCloudWatchに出力します。ログに関してはCloudWatchのログ監視が使えます
出力ログは主にSparkのログを"error"と"output"で2種類です
一般的なCloudWatchのログに対してのアラーム設定手順になります
CloudWatchのログの画面に行く。
"aws-glue/jobs/error"のロググループにチェックを入れ、"メトリクスフィルタ"ボタンをクリック
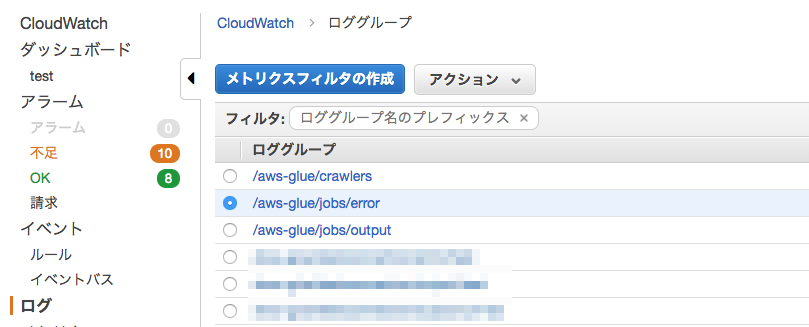
ログメトリクスフィルタの定義の画面です
フィルタする文字列パターンに文字列を入れ"パターンのテスト"をクリックすればフィルタの確認が出来ます。結果は一番下に出力されます。
テストするログデータも変更できます。
画面はテストなので"INFO"でフィルタしています。サンプルから1件フィルタできてることがわかります。
エラーログなのにINFOが出てます。。
確認ができたら右下の"メトリクスの割り当て"をクリックします。
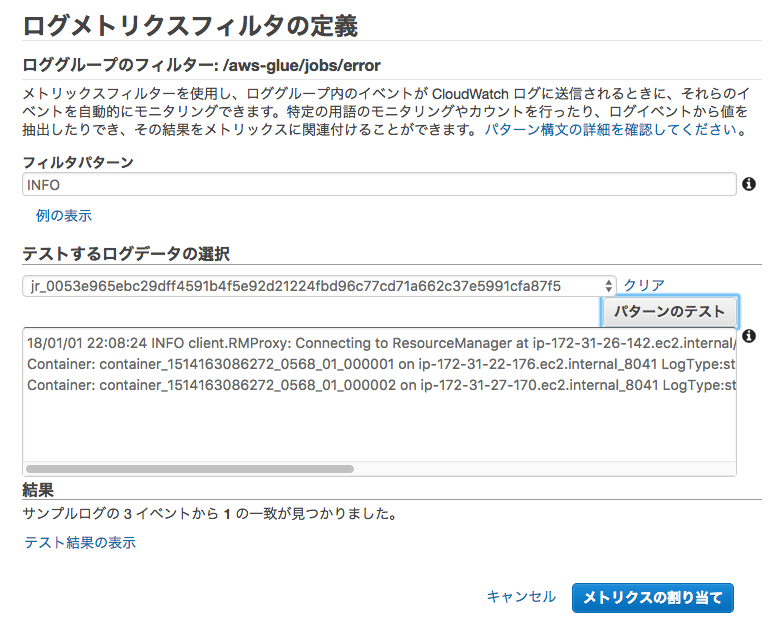
フィルタの名前、メトリクス名などを任意の名前で入力して、右下の"フィルタの作成"をクリックします
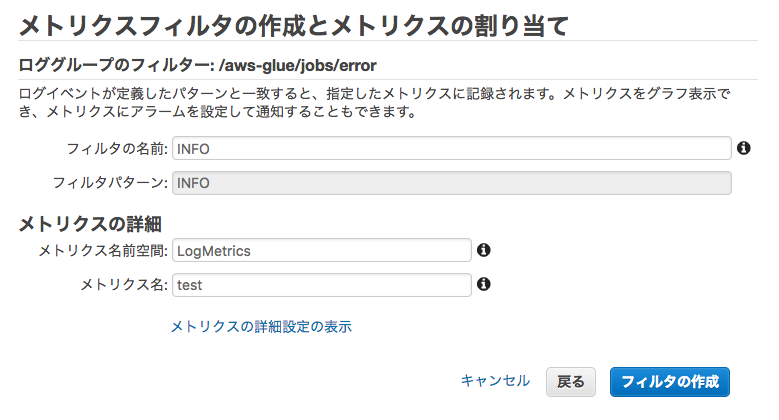
フィルタが作成されました
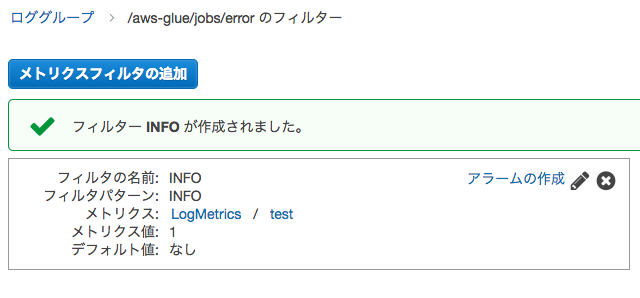
最初のCloudWatchログの画面に行くと、"aws-glue/jobs/error"ロググループの右側に"1フィルタ"となっています
ここをクリックします

右上の"アラームの作成"をクリックします
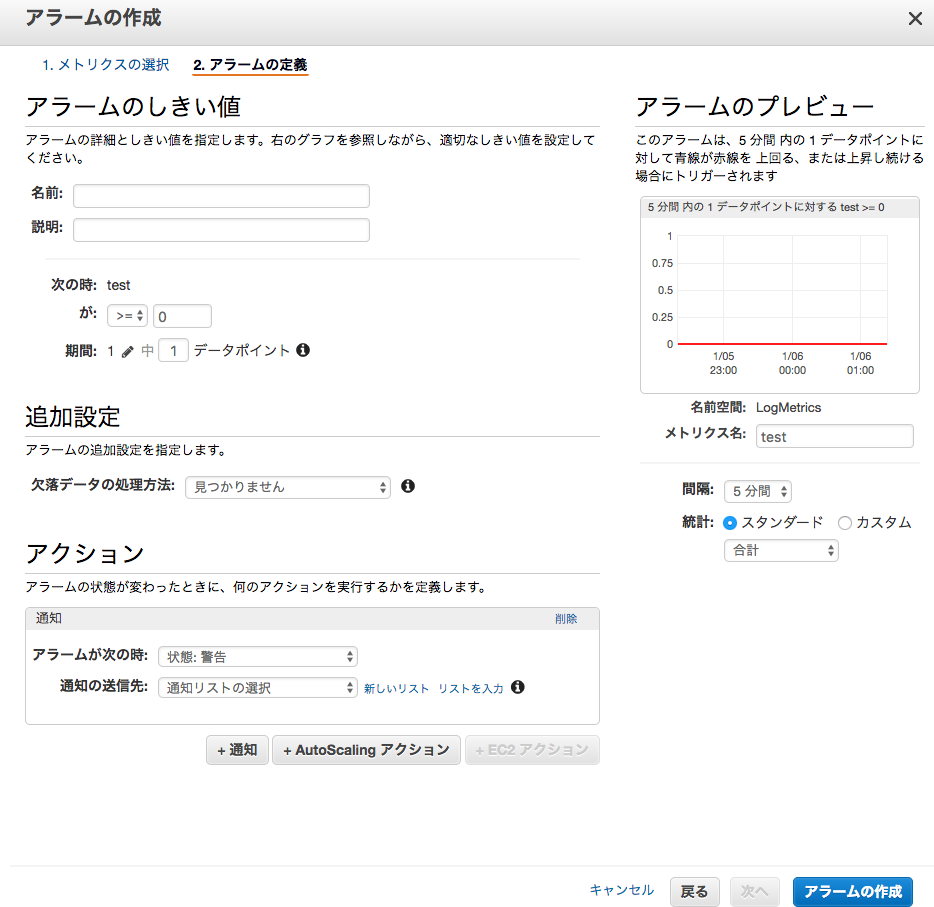
いつものアラーム設定画面となります
APIで状態取得
"Glueの使い方的な③(CLIでジョブ作成)"(以後③と書きます)でも触れたようにAPIにアクセスして状態の取得ができます。他のAWSリソースももちろん同様のことができます。
get系のAPIが使えます
クローラーの状態取得
例えばクローラーのgetで取得できる情報は
$ aws glue get-crawler --name se2_in0
{
"Crawler": {
"CrawlElapsedTime": 0,
"Name": "se2_in0",
"CreationTime": 1514874041.0,
"LastUpdated": 1514874041.0,
"Targets": {
"JdbcTargets": [],
"S3Targets": [
{
"Path": "s3://test-glue00/se2/in0",
"Exclusions": []
}
]
},
"LastCrawl": {
"Status": "SUCCEEDED",
"LogStream": "se2_in0",
"MessagePrefix": "903fa0e1-2874-4b50-a686-660d2da54004",
"StartTime": 1515146760.0,
"LogGroup": "/aws-glue/crawlers"
},
"State": "READY",
"Version": 1,
"Role": "test-glue",
"DatabaseName": "se2",
"SchemaChangePolicy": {
"DeleteBehavior": "DEPRECATE_IN_DATABASE",
"UpdateBehavior": "UPDATE_IN_DATABASE"
},
"TablePrefix": "se2_",
"Classifiers": []
}
}
ここから状態だけを取ってきたければ以下のような感じでステータスを見て成否判定することは出来ます。
$ aws glue get-crawler --name se2_in0 | jq -r .Crawler.LastCrawl.Status
SUCCEEDED
ジョブの状態取得
ジョブも同じ要領ですが、ステータスを得るためにget-job-runにRunIDを渡して上げる必要があります
RunIDはstart-jobでリターン値で得られます
$ aws glue start-job-run --job-name se2_job0
{
"JobRunId": "jr_711b8b157e3b36a1dc1a48c87c5e8b00c509150cc4f9d7d7106009e57f2cac9b"
}
また、get-job-runsでジョブの履歴から取ることもできます
$ aws glue get-job-runs --job-name se2_jobx
{
"JobRuns": [
{
"LastModifiedOn": 1514440793.923,
"StartedOn": 1514440639.623,
"PredecessorRuns": [],
"Attempt": 0,
"JobRunState": "SUCCEEDED",
"JobName": "se2_jobx",
"Arguments": {
"--job-bookmark-option": "job-bookmark-disable"
},
"AllocatedCapacity": 10,
"CompletedOn": 1514440793.923,
"Id": "jr_1b3c00146b02e36e4682f352a084a2fd37931967346b44a7c39ad182347957d3"
},
{
"LastModifiedOn": 1514440548.4,
"StartedOn": 1514440394.07,
"PredecessorRuns": [],
"Attempt": 0,
"JobRunState": "FAILED",
"ErrorMessage": "An error occurred while calling o54.getCatalogSource. No such table: se4.se04_in",
"JobName": "se2_jobx",
"Arguments": {
"--job-bookmark-option": "job-bookmark-disable"
},
"AllocatedCapacity": 10,
"CompletedOn": 1514440548.4,
"Id": "jr_aca8a8c587b0986d040aba7eadc7b216e83db409f842cb9d2912c400b181c907"
}
]
}
取得できたRunIDを使ってステータスを取ります
$ aws glue get-job-run --job-name se2_job0 --run-id jr_dff0ac334e5c5bf3043acc5158f9c3bc1f9c8eae048e053536581278ec34a063
{
"JobRun": {
"LastModifiedOn": 1514875561.077,
"StartedOn": 1514875046.406,
"PredecessorRuns": [],
"Attempt": 0,
"JobRunState": "SUCCEEDED",
"JobName": "se2_job0",
"Arguments": {
"--job-bookmark-option": "job-bookmark-disable"
},
"AllocatedCapacity": 10,
"CompletedOn": 1514875561.077,
"Id": "jr_dff0ac334e5c5bf3043acc5158f9c3bc1f9c8eae048e053536581278ec34a063"
}
}
$ aws glue get-job-run --job-name se2_job0 --run-id jr_dff0ac334e5c5bf3043acc5158f9c3bc1f9c8eae048e053536581278ec34a063 | jq .JobRun.JobRunState -r
SUCCEEDED
ポーリング型とはなりますが、定期的に状態を確認するというやり方もあります
何を監視すべきか
Glueはバッチ処理で多くの場合ジョブフローを形成する中の一部として使われると思います
何を見るべきかはいろんな意見や視点がありますし業務のサービスレベルでも違うので一概に言えないですが、お勧めとして
まずはジョブの成否を見ます。
"CloudWatchイベント"でも述べたように現状Glueジョブのイベントタイプは"全てのステータスチェンジ"の1つしかないので、ジョブが失敗したらアラートを飛ばすということがCloudWatchだけだと出来ません。本記事の"APIで状態取得"で述べたような方法を使って、ジョブ実行した後非同期でステータスを確認する。またはCloudWatchイベントでJobStateChangeのイベントでLambdaを起動してGlueのAPIを叩いてステータス確認するとよりタイムラグない監視になると思います。
多くの場合ジョブフローを形成し、1つのジョブステップを処理の最小単位とするので、その成否の確認はロールバックし易さや業務影響などの考慮が入っています。その単位でジョブの失敗に気づき、そしてより詳細な調査が必要な場合にログを確認していくのが1つのパターンと思います
このジョブフローをサーバーレスで行うサービスにAWSのStepFunctionというサービスがあります。Glueとも相性がいいのでまた今度書いてゆきます
エラーは吐かないが実行時間が長い
これも気づきたいポイントになると思います。
ジョブのスタート時間は取れるので、そこから経過した時間を算出し、通常1時間のジョブが2時間を超えたらアラートを上げる
などもいいと思います。
2018/04/xxにジョブ実行のタイムアウト値が設定できるようになりました。デフォルト48時間が設定されます。
$ aws glue get-job-run --job-name se2_job0 --run-id jr_dff0ac334e5c5bf3043acc5158f9c3bc1f9c8eae048e053536581278ec34a063 | jq .JobRun.StartedOn -r
1514875046.406
ログ監視
上記の監視運用を繰り返していくと、ジョブが失敗してログ調査をしてこのログは検知したいといった知見が溜まっていきます。
その場合は本記事の"CloudWatchログ"でも述べたやり方でログ監視してください。ジョブが失敗することには変わらないですがログのアラートも飛んでくることで既知の問題であることが即座にわかりトラブルシュートが格段に早まります
To Be Continue
- StepFunctionでGlueのジョブフローを作るを書く
こちらも是非
CloudWatchログ監視
http://www.d2c-smile.com/201609137826#a1
Glueの使い方まとめ
https://qiita.com/pioho07/items/32f76a16cbf49f9f712f