GlueContextクラスのtransition_tableを使ってS3のストレージクラスを変更する
この機能のドキュメント
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/aws-glue-api-crawler-pyspark-extensions-glue-context.html
対象のGlueテーブルの実際のS3オブジェクトのストレージクラスをGlacierやIAに変更します。ジョブの最後に必要ならストレージクラスを変更したり、大量データに対しては1つのジョブにしてワークフローの最後に行ったり定期実行するなど良さそう。
ジョブの内容
JupyterNotebookで、GlueテーブルのS3オブジェクトのストレージクラスを変更します。
全体の流れ
- 前準備
- ジョブ実行
- 確認
- その他:transition_s3_path/purge_table/purge_s3_path
前準備
ソースデータ
2つのcsvデータを用意しS3にアップロードしておく。S3ストレージクラスはスタンダードです。
cvlog1.csv
cvlog2.csv
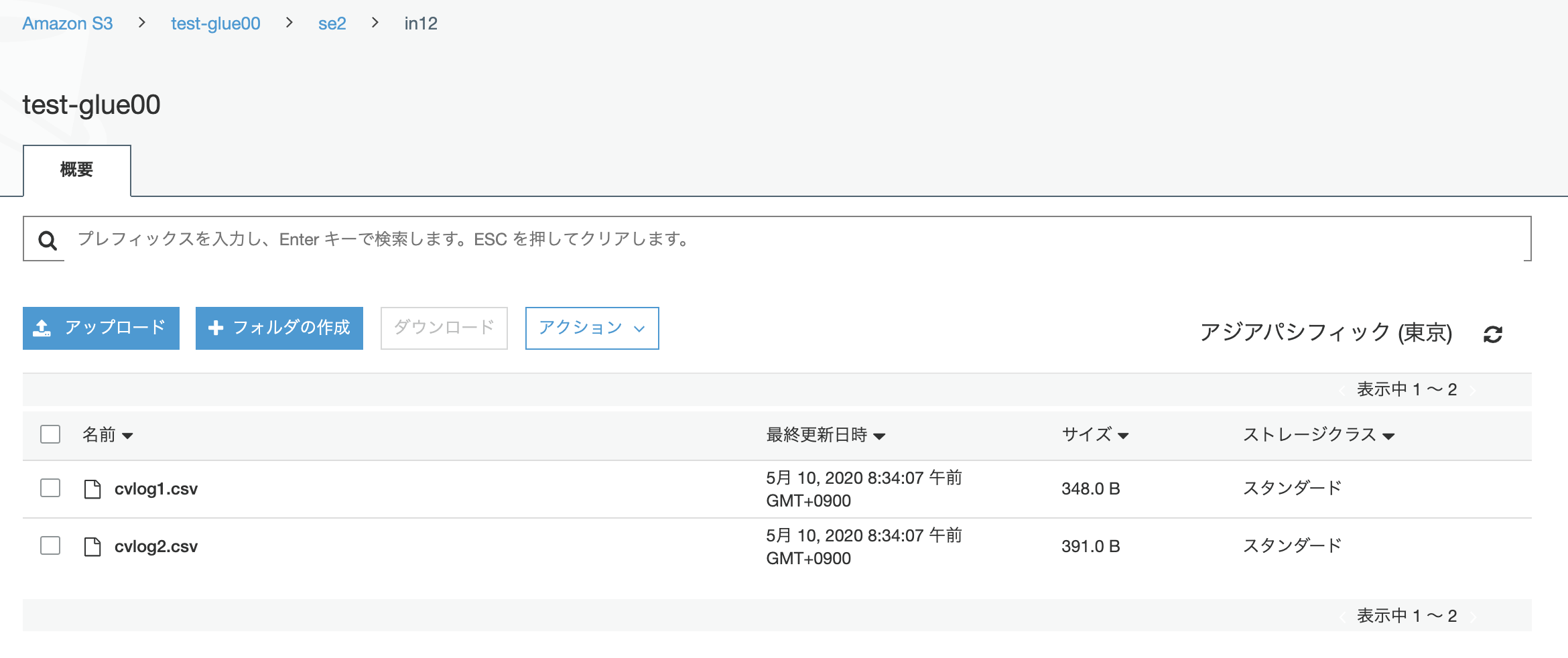
cvlog1.csv
今回データの中身はどうでもいいのですが、一応以下のようなデータが入っています。
deviceid,uuid,appid,country,year,month,day,hour
iphone,11111,001,JP,2017,12,14,12
android,11112,001,FR,2017,12,14,14
iphone,11113,009,FR,2017,12,16,21
iphone,11114,007,AUS,2017,12,17,18
other,11115,005,JP,2017,12,29,15
iphone,11116,001,JP,2017,12,15,11
pc,11118,001,FR,2017,12,01,01
pc,11117,009,FR,2017,12,02,18
iphone,11119,007,AUS,2017,11,21,14
deviceid,uuid,appid,country,year,month,day,hour
other,11110,005,JP,2017,11,29,15
iphone,11121,001,JP,2017,11,11,12
android,11122,001,FR,2017,11,30,20
iphone,11123,009,FR,2017,11,14,14
iphone,11124,007,AUS,2017,12,17,14
iphone,11125,005,JP,2017,11,29,15
iphone,11126,001,JP,2017,12,19,08
android,11127,001,FR,2017,12,19,14
iphone,11128,009,FR,2017,12,09,04
iphone,11129,007,AUS,2017,11,30,14

ジョブ実行
【参考】公式ページから引用↓
glueContext.transition_table("database", "table", "STANDARD_IA", {"retentionPeriod": 1, "excludeStorageClasses": ["STANDARD_IA"], "manifestFilePath": "s3://bucketmanifest/", "accountId": "12345678901", "roleArn": "arn:aws:iam::123456789012:user/example-username"})
JupyterNotebookを起動します。
手順はこの辺を参考にしてもらえたらと
https://qiita.com/pioho07/items/29bd779f84b4add9cf2c
以下のコードでジョブを作成し実行する。内容は"se2_in12"という名前のテーブルのS3オブジェクトのストレージクラスをIAに変更します。
※「retentionPeriod」のオプションの意味がドキュメント見ても分かりづらいのですが、要するに「指定した期間は変換の対象にしません」という意味になります。今回は"retentionPeriod 0"を指定することでいつ実施してもストレージクラスの変換を行いますが、例えば"retentionPeriod 1"と指定すると、オブジェクトのタイムスタンプが1時間経過していなければストレージクラス変換の対象にしません。ストレージクラスだけ変換してもタイムスタンプは更新されます。一定時間経ったオブジェクトだけストレージクラスをIAやGlacierに変換するということができますね。そういうオプションだと思います。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
glueContext.transition_table("se2", "se2_in12", "STANDARD_IA", {"retentionPeriod": 0, "manifestFilePath": "s3://test-glue00/se2/manifest/", "accountId": "<aws account id>", "roleArn": "arn:aws:iam::<aws account id>:role/test-glue"})

パラメータ
-
database – 使用するデータベース。
-
table_name – 使用するテーブルの名前。
-
transition_to – 移行先の Amazon S3 ストレージクラス。
-
options – 削除するファイルとマニフェストファイルの生成のためのファイルをフィルタリングするオプション。
-
retentionPeriod – ファイルを保持する期間を時間単位で指定します。保存期間より新しいファイルは保持されます。デフォルトでは 168 時間(7 日)に設定されています。
-
partitionPredicate – この述語を満たすパーティションは移行されます。これらのパーティションの保存期間内のファイルは移行されません。デフォルトでは "" – 空に設定されます。
-
excludeStorageClasses – excludeStorageClasses セット内のストレージクラスを持つファイルは移行されません。デフォルトは Set() – 空白のセットです。
-
manifestFilePath – マニフェストファイルを生成するためのオプションのパス。正常に移行されたすべてのファイルが Success.csv に記録され、失敗したファイルは Failed.csv に記録されます。
-
accountId – 移行変換を実行する AWS アカウント ID。このトランスフォームには必須です。
-
roleArn – 移行変換を実行する AWS ロール。このトランスフォームには必須です。
-
transformation_ctx – 使用する変換コンテキスト (オプション)。マニフェストファイルパスで使用されます。
-
catalog_id – アクセス中の データカタログ のカタログ ID(データカタログ のアカウント ID)。デフォルトでは、None に設定されています。None のデフォルト値は、サービス内の呼び出し元アカウントのカタログ ID になります。
確認
S3オブジェクトの確認
対象の2つのS3オブジェクトのS3ストレージクラスが、スタンダード->IAに変更されました。

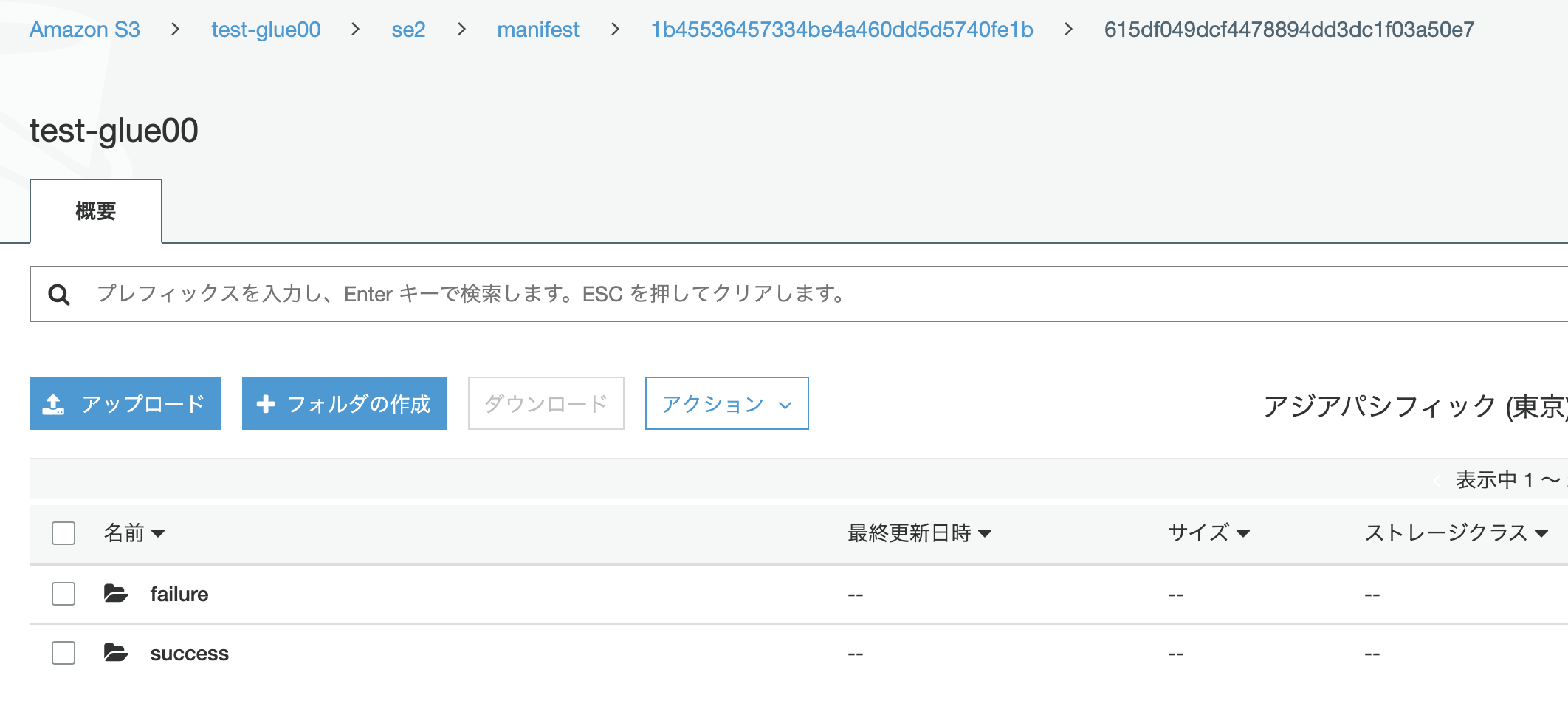
マニフェストファイル確認
test-glue00/se2/manifest/配下にマニフェストファイルとして正常に移行されたすべてのファイルが success配下に、失敗したファイルは failure配下にファイルとして記録されます。
※ドキュメントではsuccess.csvファイルに出力とあるが現状の動作はsuccessフォルダにrun-xxx-part-r-xxxという名前のファイルが出力されます。
成功したのでSUCCESS配下のファイルをS3 Selectで表示してみます。

今回の対象となった「S3バケット、パス/オブジェクト名」が示されてます。

その他:transition_s3_path/purge_table/purge_s3_path
使い方としては今回紹介したtransition_tableとほとんど同じです。オプションなども似ています。
- transition_s3_path
S3パスを指定してS3ストレージクラスの変更
- purge_table
テーブルのオブジェクトの削除
- purge_s3_path
S3パスを指定してオブジェクトの削除
こちらも是非
Glueの使い方まとめ
https://qiita.com/pioho07/items/32f76a16cbf49f9f712f