「Redshift auto copy from s3」はまだPreviewなので、2022/12/05現在の動作としてご覧ください
What's Newの記事
※作業はすべて東京リージョンで実施
事前セットアップ
- S3バケット:demo-redshift-s3copy で作成
- IAMロール:こちらに沿ってdemo-redshift-s3copyjobで作成
- Redshift公式ページにあるTICKITというサンプルデータをダウンロードする。その中のListingテーブル(ファクトテーブル)をテストデータとして使う。s3からRedshiftへのロードを段階的に確認したいため、ダウンロードしたlisting.txtファイルを以下のように分割しておく。
- listing_1.txtは最初の3行だけのファイル
- listing_2.txtはその次の5行だけのファイル
- listing_3.txtはその次の7行だけのファイル
Previw用のRedshift cluster作成
本機能をためすにはPreview用のRedshift Clusterを作る必要があります。クラスタは以下の公式ドキュメントの冒頭の流れで特にハマることなく作成できます
Continuous file ingestion from Amazon S3 (preview)
クラスタ作成手順
2022/12/5 時点での手順は以下の流れでした。
マネコンからRedshiftのページに行き、メニューで「プロビジョニングされたクラスタダッシュボード」をクリックすると、右上に[Create preview cluster]というボタンがあります。それをクリックします。
クラスタ作成時の選択項目は以下です
- 名前: preview(任意)
- preview track: preview_autocopy_2022
- 管理者パスワード: (任意)
- 関連付けられたIAMロール: demo-redshift-s3copyjob (事前に作成したロール)
これくらいでサクッと作れます
auto copy from s3の説明
Continuous file ingestion from Amazon S3 (preview)
Redshiftは、COPY コマンドで指定されたS3パスに新しいファイルが追加されたことを検出し、COPY コマンドが自動的に実行されます。
Redshift は、ロードされたファイルを追跡します。 Redshift は、COPY コマンドごとにバッチ処理されるファイルの数を決定します。結果の COPY コマンドは、システム ビューで確認できます
構文
"job-name"は、COPY ジョブの名前。
[AUTO ON | OFF] は、自動的にロードされるかどうかを示す句でAutoがデフォ。OFFの場合は以下の「COPY JOB RUN」で手動実行できる(未確認)
--コピー ジョブを作成します。 COPY コマンドのパラメーターは、コピー ジョブと共に保存されます。
COPY copy-command JOB CREATE job-name
[AUTO ON | OFF]
--コピー ジョブの構成を変更します。
COPY JOB ALTER job-name
[AUTO ON | OFF]
--コピー ジョブを実行します。保存された COPY コマンド パラメータが使用されます。
COPY JOB RUN job-name
--リスト
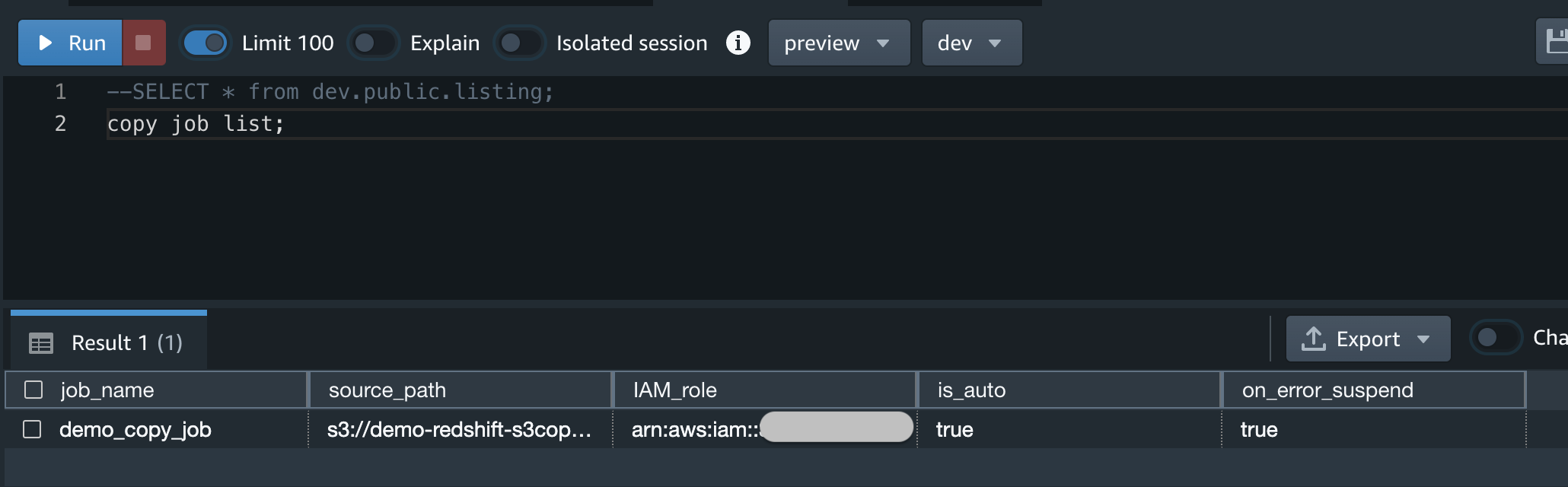
COPY JOB LIST
--コピージョブの詳細
COPY JOB SHOW job-name
--コピージョブの削除
COPY JOB DROP job-name
状態確認
--(Preview)現在定義されている各 COPY JOB の行が含まれています。
select * from sys_copy_job;
--エラー
select * from stl_load_errors;
--トラシュー時の調査データ
select * from stl_load_commits;
--コマンド詳細
select * from sys_load_history;
--コマンドエラー詳細
select * from sys_load_error_detail;
--COPY JOBによってロードされたファイルのリストを取得。<job_id>を置き換えて実行
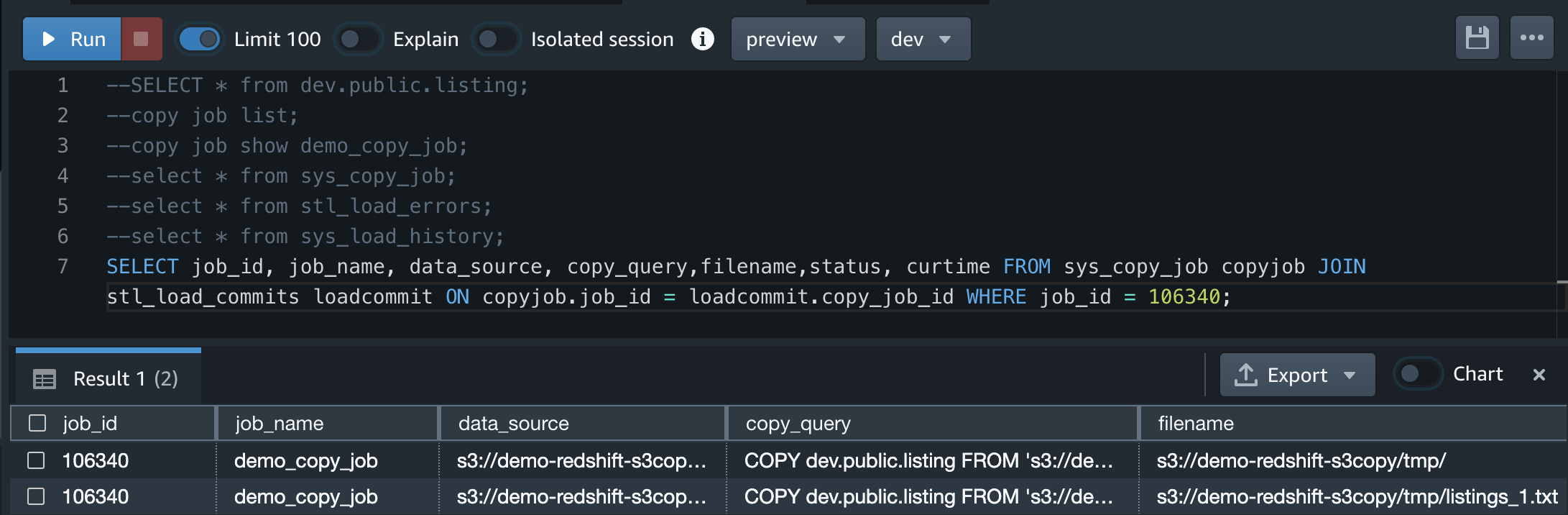
SELECT job_id, job_name, data_source, copy_query,filename,status,
curtime FROM sys_copy_job copyjob JOIN stl_load_commits loadcommit
ON copyjob.job_id = loadcommit.copy_job_id WHERE job_id = <job_id>;
注意点
- COPY コマンドのオプションは、実行時まで検証されません。たとえば、IAM_ROLE または Amazon S3 データ ソースが無効な場合、COPY JOB の開始時にランタイム エラーが発生します。
- COPY JOB は、クラスターに関連付けられたデフォルトの IAM ロールをサポートしていません。 COPY コマンドで IAM_ROLE を指定する必要があります。
- クラスターが一時停止している場合、COPY JOBS は実行されません。
- ロードされた COPY コマンド ファイルとロード エラーを照会するには、STL_LOAD_COMMITS、STL_LOAD_ERRORS、STL_LOADERROR_DETAIL を参照する。
やってみる
以下のコマンド実行は全てRedshift Query Editor v2で実施
1つ目のファイルアップロード確認
Redshiftにlistingテーブルを作成
create table listing( listid integer not null distkey, sellerid integer not null
, eventid integer not null, dateid smallint not null sortkey, numtickets
smallint not null, priceperticket decimal(8,2), totalprice decimal(8,2),
listtime timestamp);
Redshiftにコピージョブを作成。これがメインで、これによってS3からデータロードするジョブが作られる。
COPY dev.public.listing
FROM 's3://demo-redshift-s3copy/tmp'
IAM_ROLE 'arn:aws:iam::xxxxxxxxxxxx:role/demo-redshift-s3copyjob'
JOB CREATE demo_copy_job
AUTO ON;
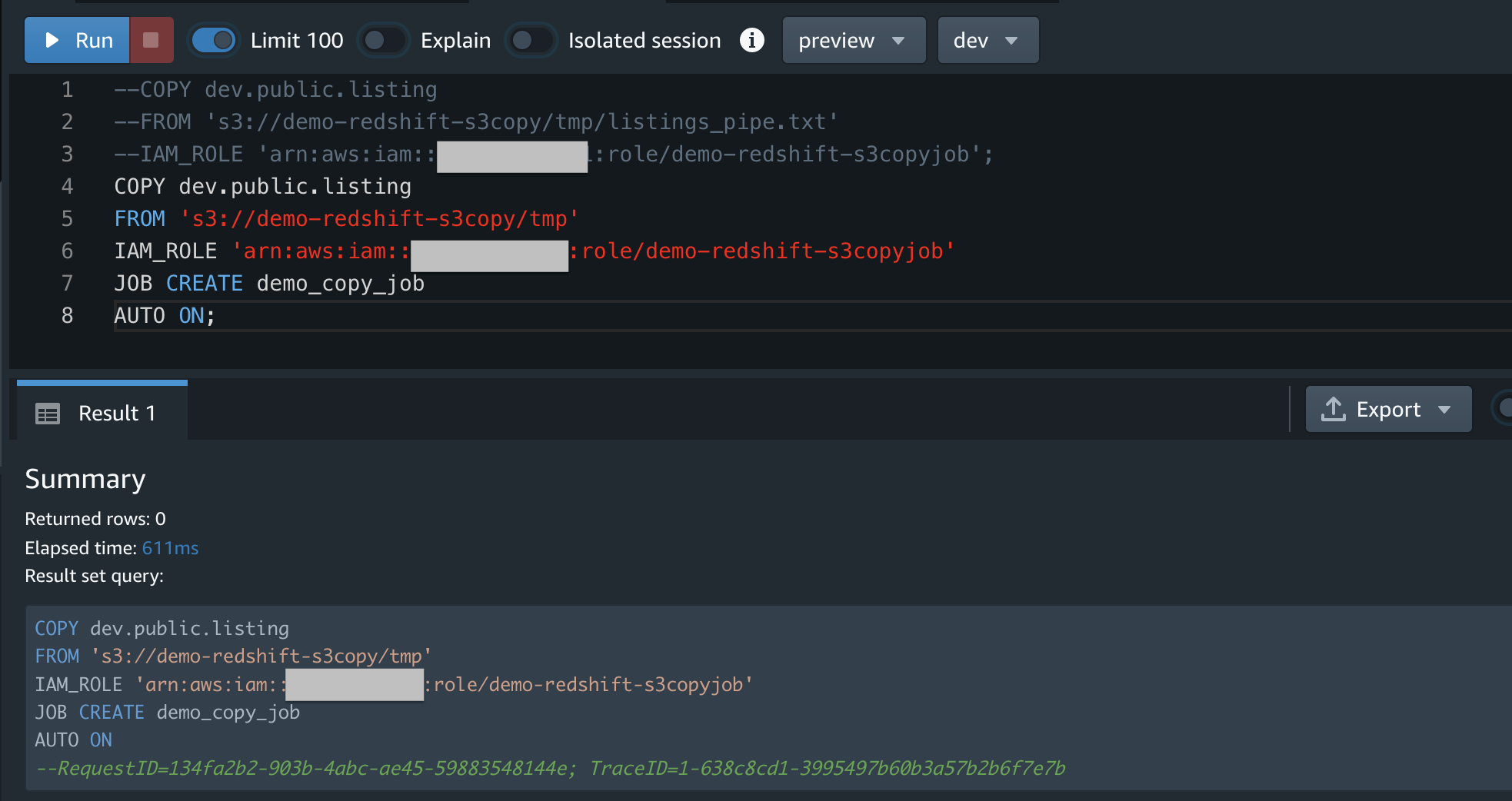
S3にファイルアップロードする前なので、テーブルは空っぽです
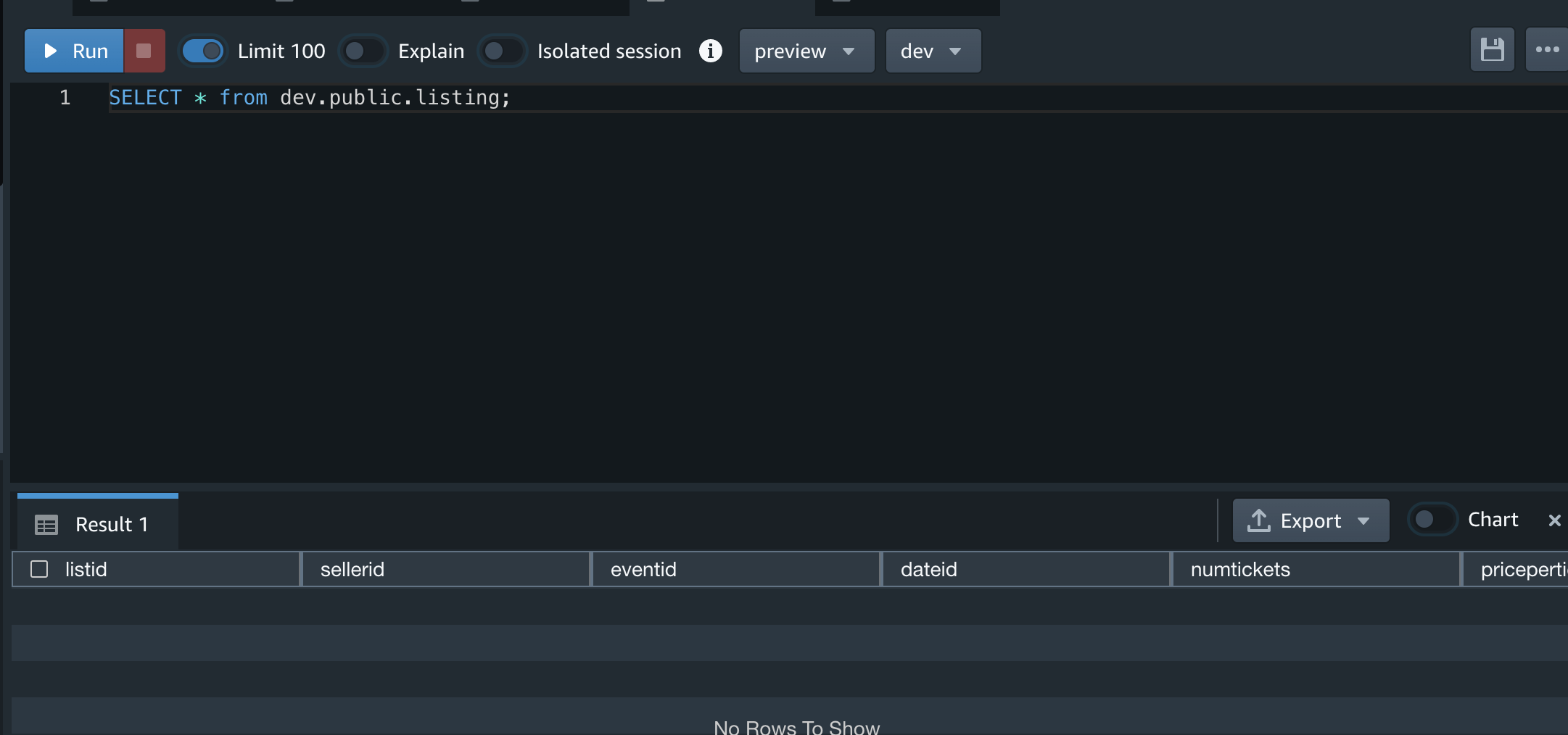
3行だけに分割しておいたlisting_1.txtファイルをアップロード。
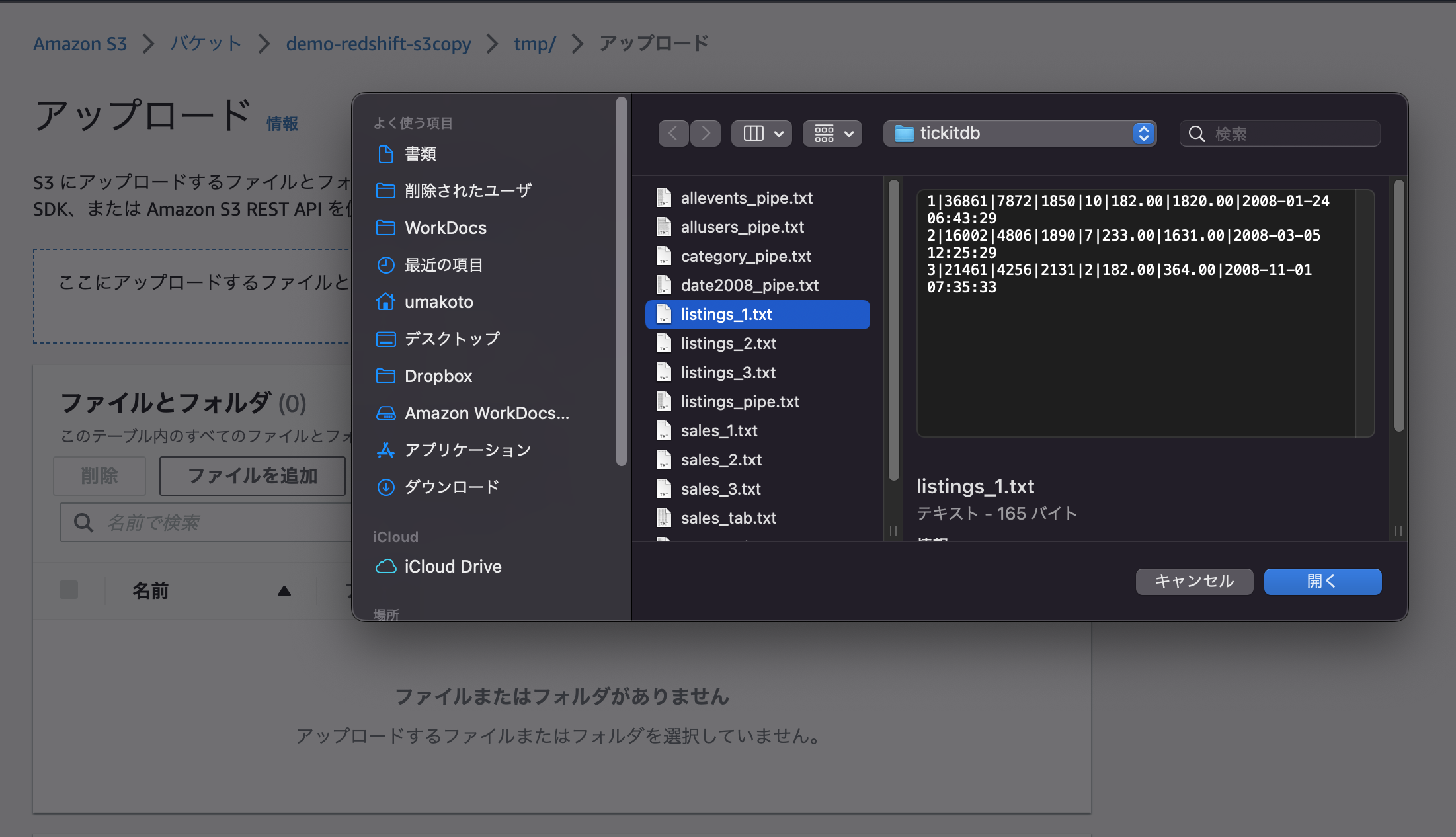
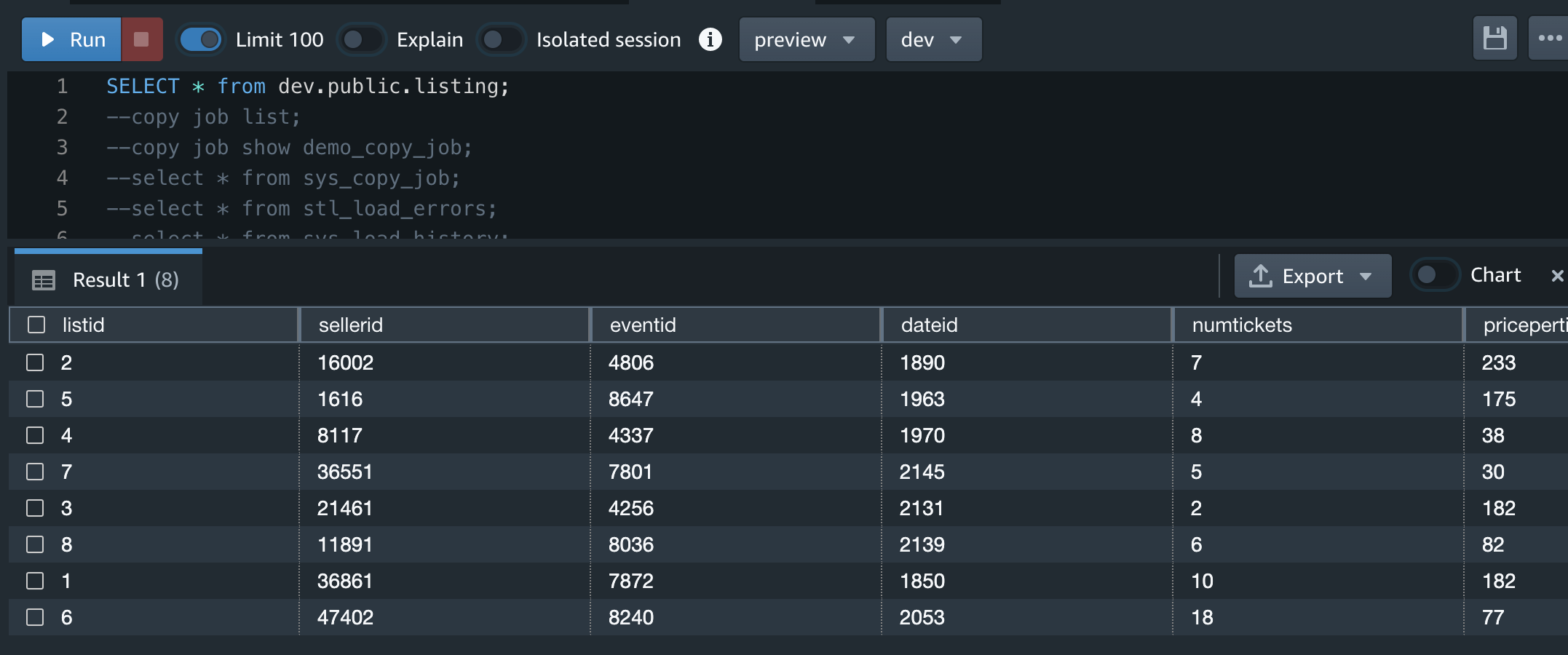
1分後くらいにRedshift側でSelectクエリすることでデータロードが確認出来ました。 これで自動でS3からRedshiftにロードされることが確認できました。
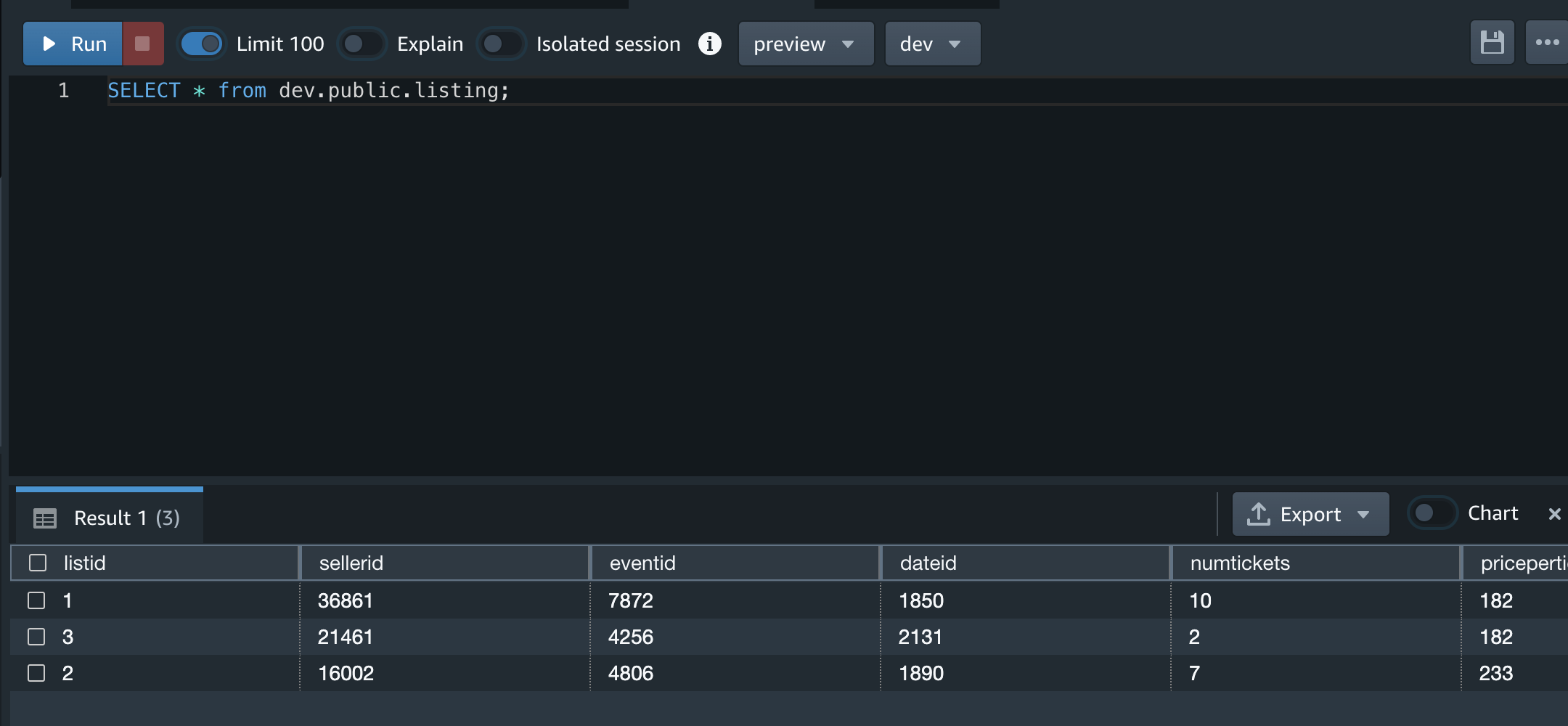
システムビューを確認
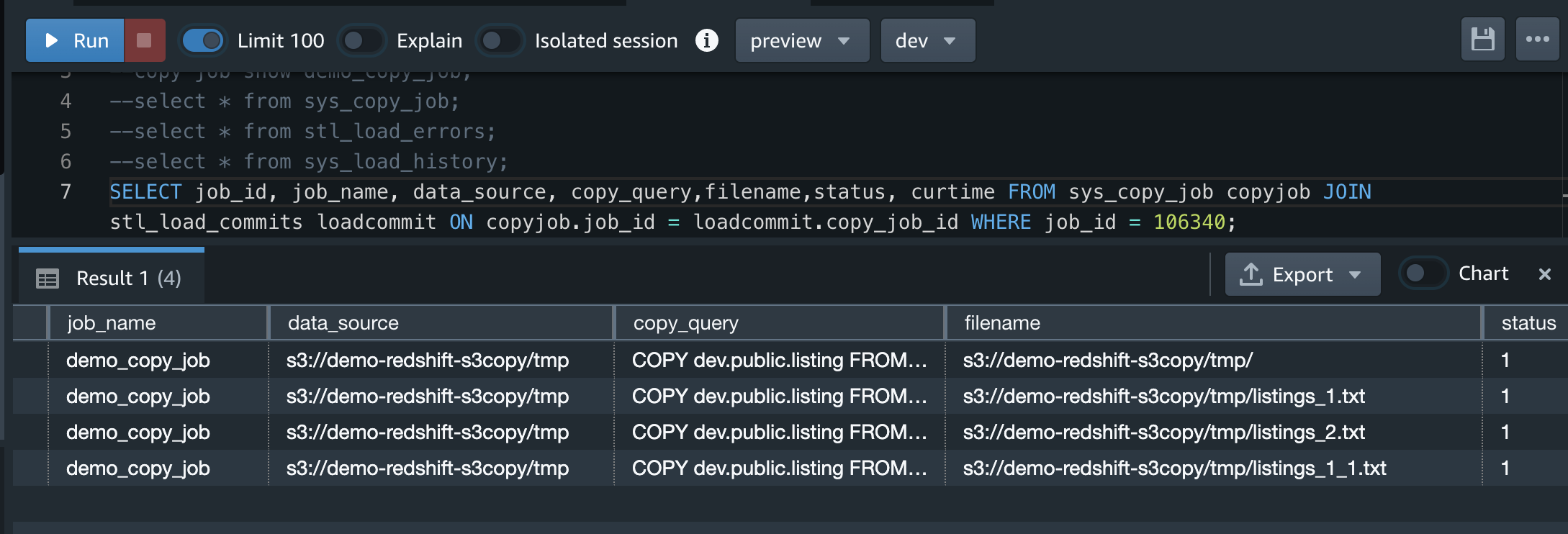
コピージョブ確認。前述のコピージョブ確認コマンドの実行結果を貼っておきます。適宜ジョブの状態確認に活用できます。
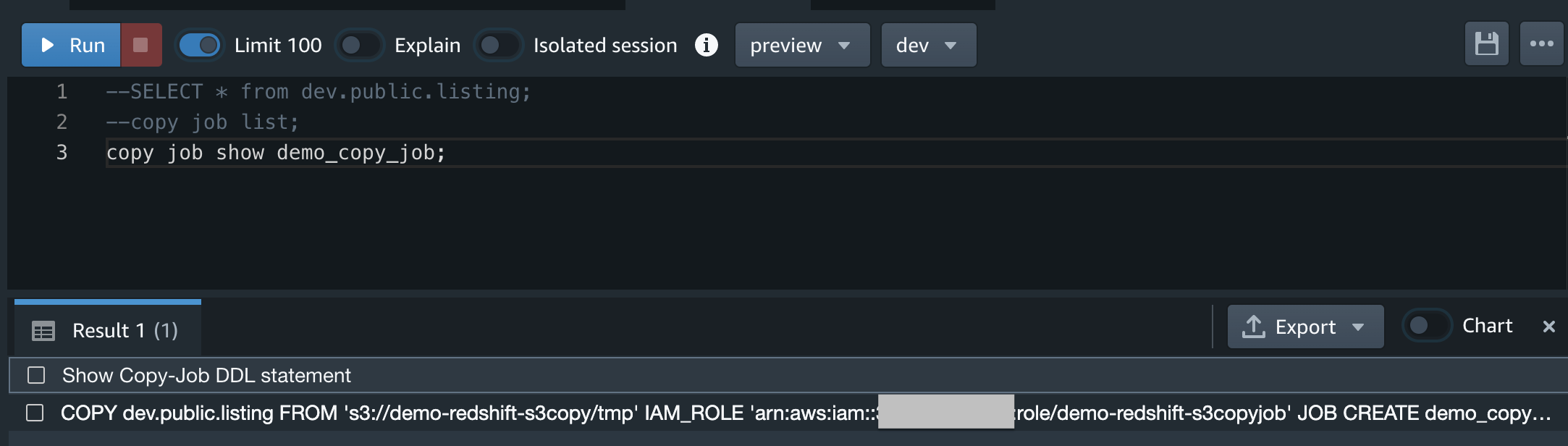
ここでjobidを取得できる
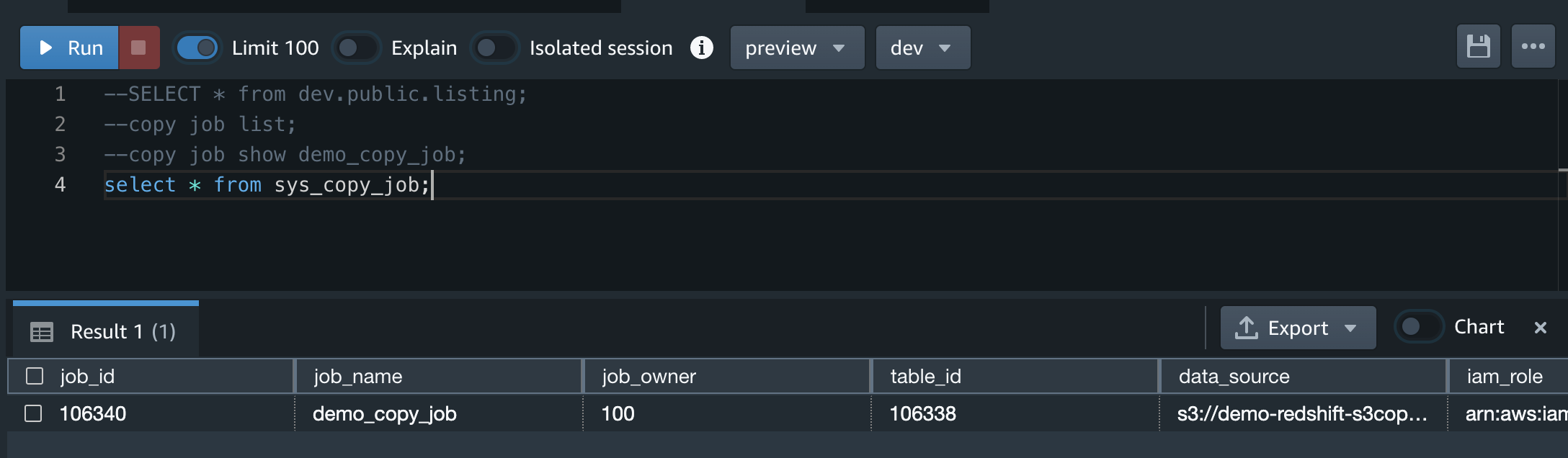
jobidに106340を指定する
2つ目のファイルアップロード
2つ目のlisting_2.txtファイルは5行だけのデータ
1分くらいで反映された
1つ目のファイルを削除してみる
期待値としては、COPY JOBがs3 copyしてるだけだろうから、Redshiftのデータは消えない
まさか同期は取ってくれないだろう
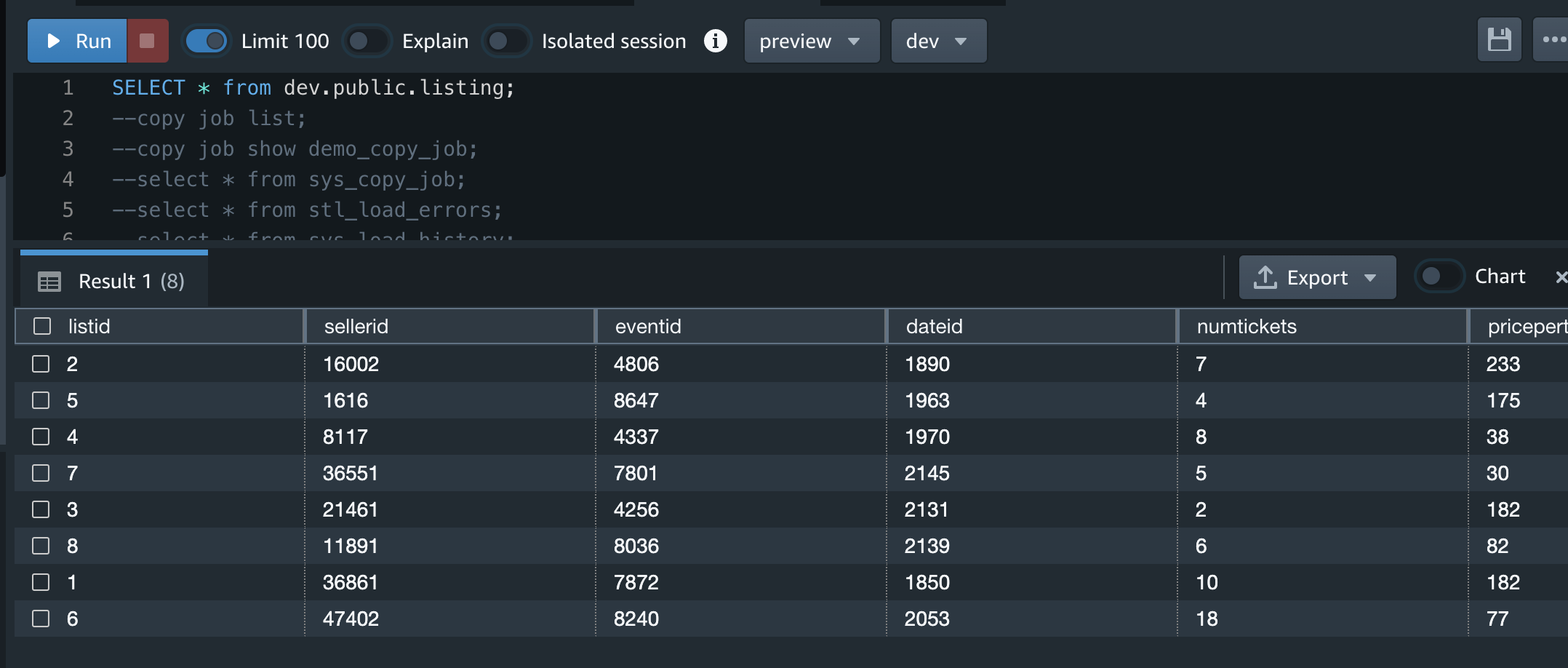
↓S3からlisting_1.txtファイルを削除してみた。
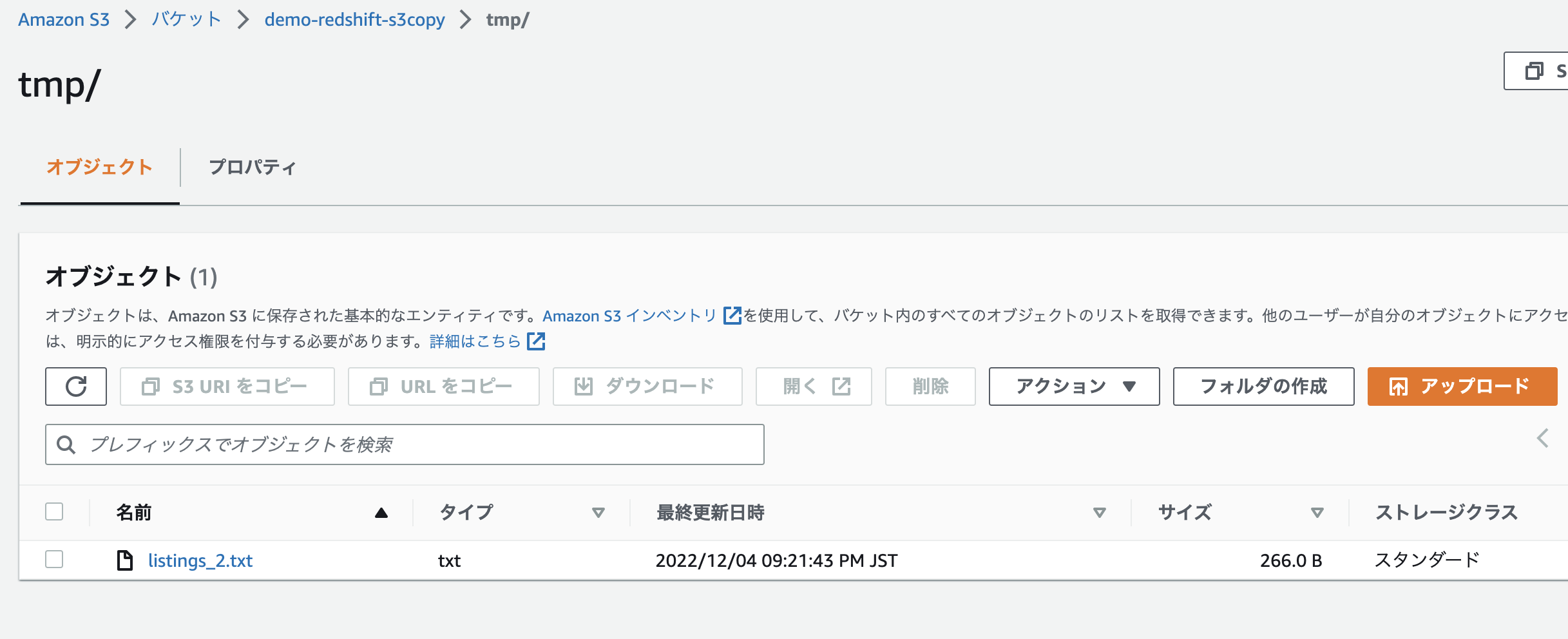
うん。そりゃそうだよねという結果ですが、Redshiftのデータはそのままです
同じファイルが2回アップされたらどうなるか?
再度1つ目のファイルをアップロード
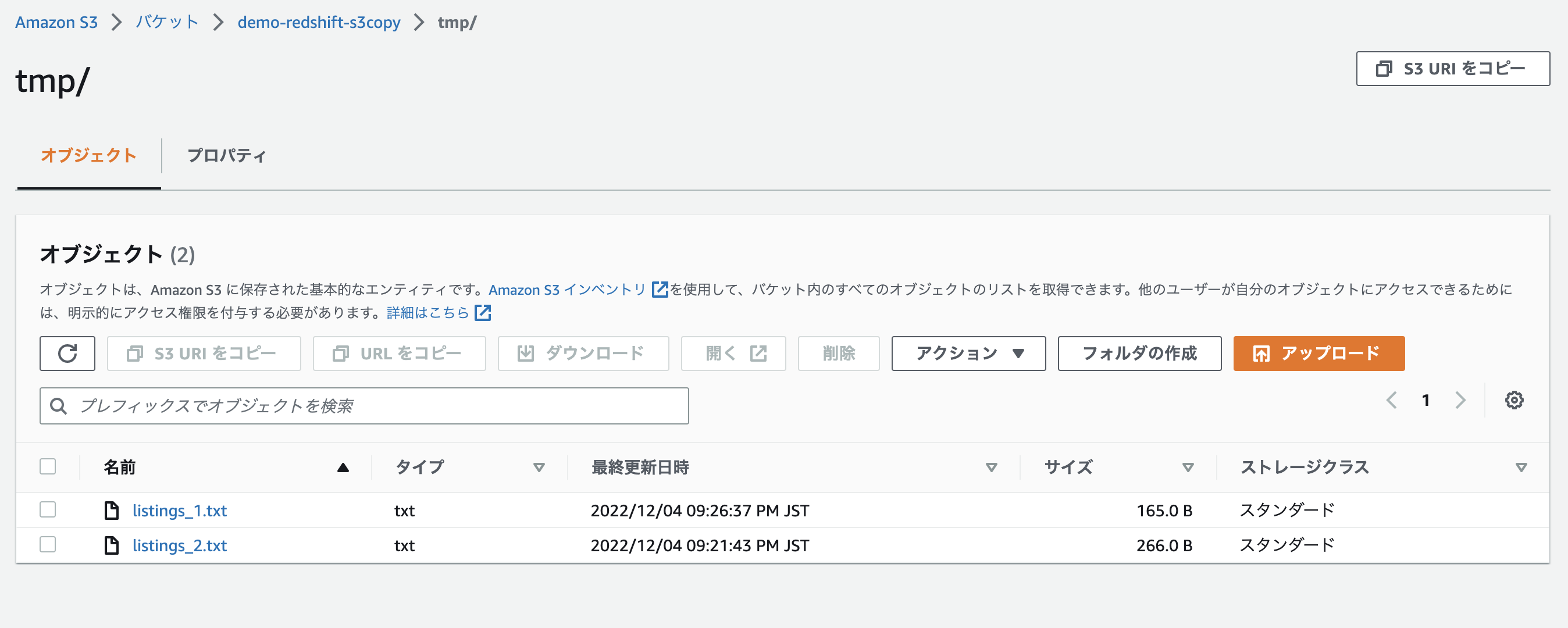
Redshiftにロードされない。これは公式ドキュメントにある「Redshift は、ロードされたファイルを追跡します」のためだと思われる
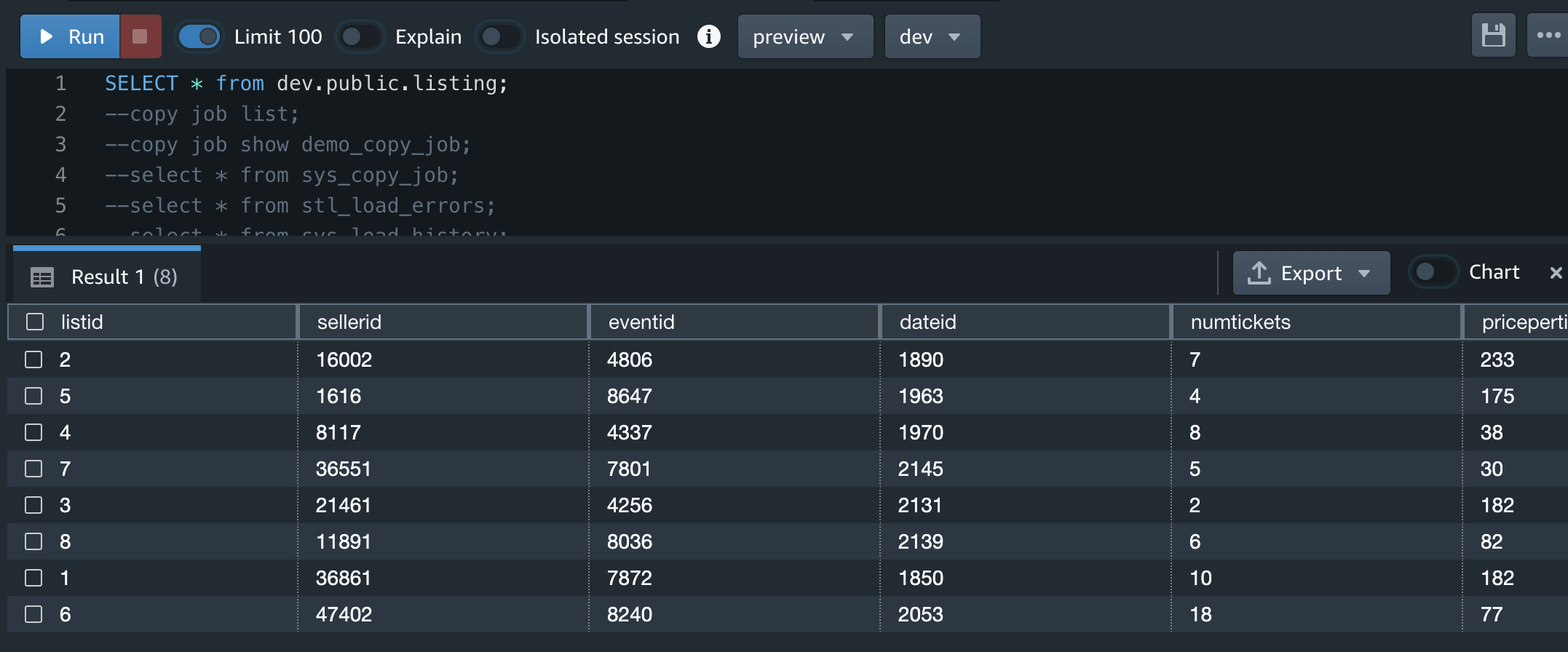
同じファイルだが、ファイル名を変更してアップしたらどうなるか?
期待値としては、Redshiftはロードしたデータをファイル名で追跡してそうなので、ファイル名が異なれば同じデータでもロードされる。
1つ目のファイル名を変更してアップしてみた。
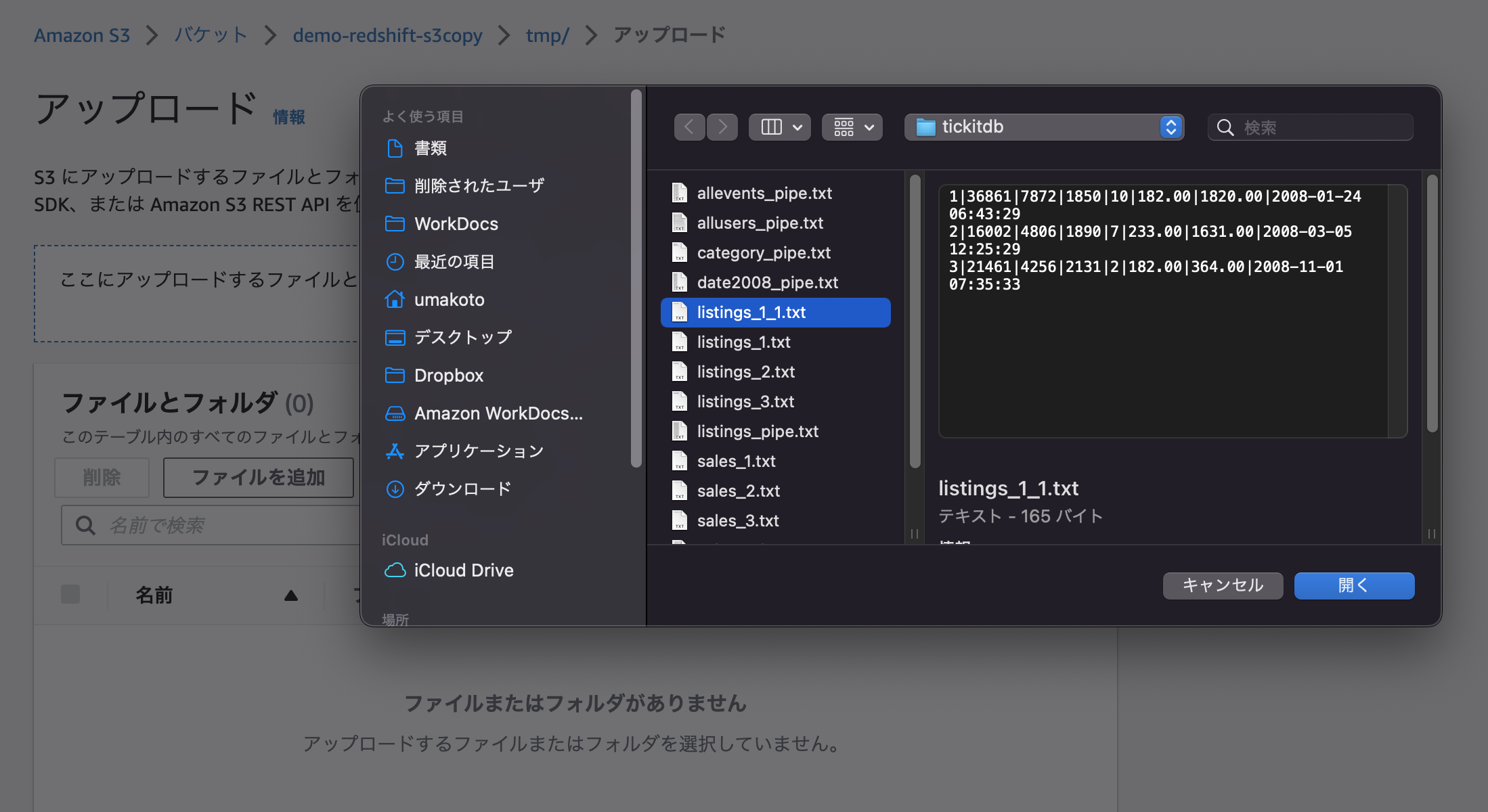
ロードされた
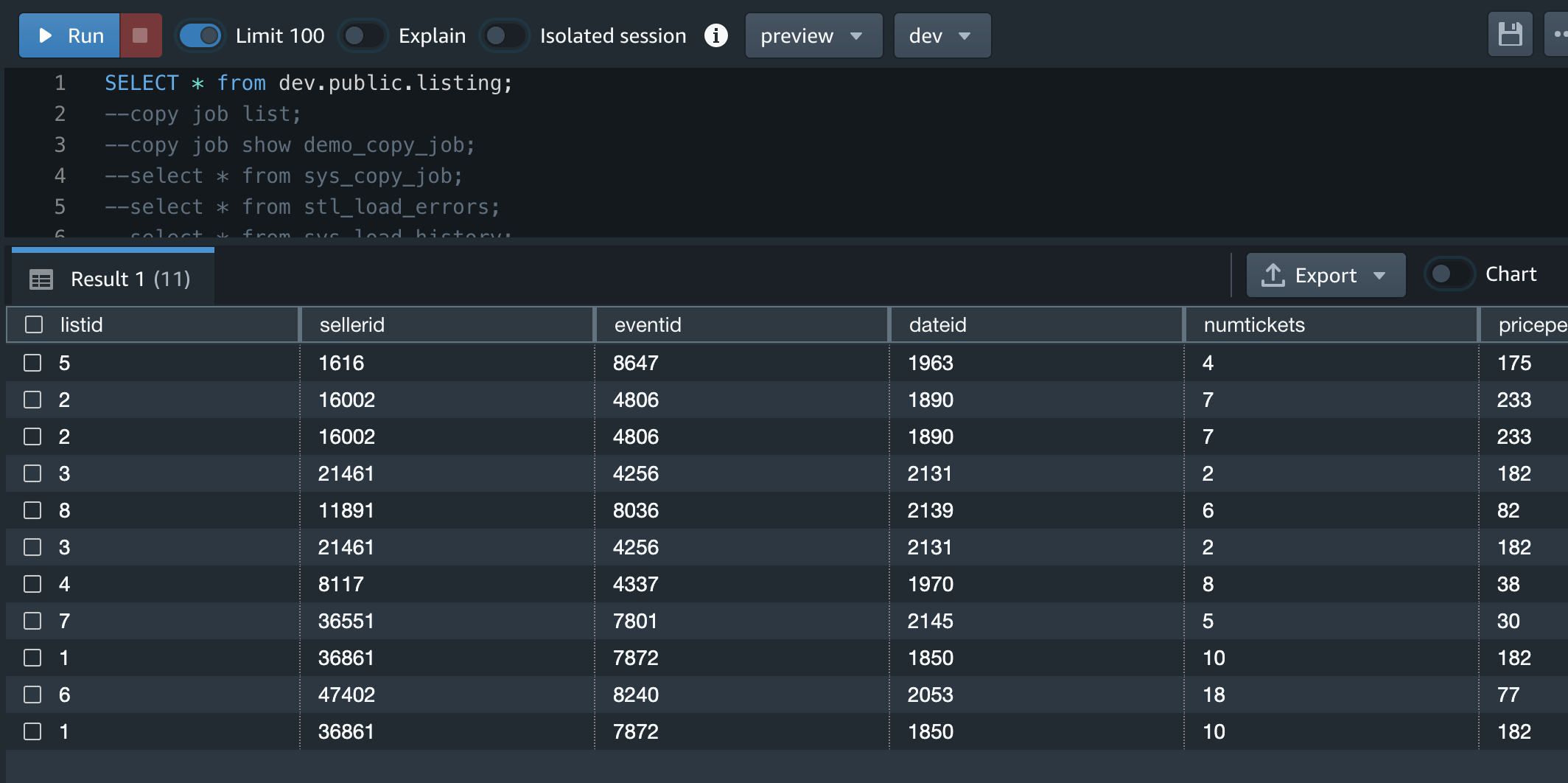
sys_copy_jobからCOPY JOBが保持しているファイル名が確認出来る
大きめのファイルで通常のS3 CopyとCopy Jobでロードの時間の差を確認する
やろうかやるまいか考え中
感想
- 簡単に出来るので、今までs3からredshiftへのロードを手組みしてた人には置き換えることで簡潔になる
- エラーなどはうまいことclondwatchと連携してくれてるとよかった。でも便利!