パーティション分割csv->パーティション分割parquet
ジョブの内容
※"Glueの使い方①(GUIでジョブ実行)"(以後①とだけ書きます)と同様のcsvデータを使います
"パーティション分割されたcsvデータを同じパーティションで別の場所にparquetで出力する"
ジョブ名
se2_job4
クローラー名
se2_in1
se2_out3
全体の流れ
- 前準備
- ジョブ作成と修正
- ジョブ実行と確認
- 出力データのクローラー作成、実行、Athenaで確認
- 別のカラムでパーティション分割
※①のGUIで作成したPySparkスクリプトに最小限の変更を入れる形で進めます
前準備
ソースデータ(19件)
内容としては①と同じデータで、year,month,day,hourのパーティションごとに分けたcsvファイルを配置します。
year,month,day,hourのカラムは削除しています。
元となる①のデータ
deviceid,uuid,appid,country,year,month,day,hour
iphone,11111,001,JP,2017,12,14,12
android,11112,001,FR,2017,12,14,14
iphone,11113,009,FR,2017,12,16,21
iphone,11114,007,AUS,2017,12,17,18
other,11115,005,JP,2017,12,29,15
iphone,11116,001,JP,2017,12,15,11
pc,11118,001,FR,2017,12,01,01
pc,11117,009,FR,2017,12,02,18
iphone,11119,007,AUS,2017,11,21,14
other,11110,005,JP,2017,11,29,15
iphone,11121,001,JP,2017,11,11,12
android,11122,001,FR,2017,11,30,20
iphone,11123,009,FR,2017,11,14,14
iphone,11124,007,AUS,2017,12,17,14
iphone,11125,005,JP,2017,11,29,15
iphone,11126,001,JP,2017,12,19,08
android,11127,001,FR,2017,12,19,14
iphone,11128,009,FR,2017,12,09,04
iphone,11129,007,AUS,2017,11,30,14
今回使う入力データ(19件)
year,month,day,hourのカラムは削除しています
$ ls
cvlog_2017111112.csv cvlog_2017120101.csv cvlog_2017121621.csv
cvlog_2017111414.csv cvlog_2017120218.csv cvlog_2017121714.csv
cvlog_2017112114.csv cvlog_2017120904.csv cvlog_2017121718.csv
cvlog_2017112915.csv cvlog_2017121412.csv cvlog_2017121908.csv
cvlog_2017113014.csv cvlog_2017121414.csv cvlog_2017121914.csv
cvlog_2017113020.csv cvlog_2017121511.csv cvlog_2017122915.csv
$ cat *
deviceid,uuid,appid,country
iphone,11121,001,JP
deviceid,uuid,appid,country
iphone,11123,009,FR
deviceid,uuid,appid,country
iphone,11119,007,AUS
deviceid,uuid,appid,country
other,11110,005,JP
iphone,11125,005,JP
deviceid,uuid,appid,country
iphone,11129,007,AUS
deviceid,uuid,appid,country
android,11122,001,FR
deviceid,uuid,appid,country
pc,11118,001,FR
deviceid,uuid,appid,country
pc,11117,009,FR
deviceid,uuid,appid,country
iphone,11128,009,FR
deviceid,uuid,appid,country
iphone,11111,001,JP
deviceid,uuid,appid,country
android,11112,001,FR
deviceid,uuid,appid,country
iphone,11116,001,JP
deviceid,uuid,appid,country
iphone,11113,009,FR
deviceid,uuid,appid,country
iphone,11124,007,AUS
deviceid,uuid,appid,country
iphone,11114,007,AUS
deviceid,uuid,appid,country
iphone,11126,001,JP
deviceid,uuid,appid,country
android,11127,001,FR
deviceid,uuid,appid,country
other,11115,005,JP
データの場所
year,month,day,hourのパーティションごとに分けたcsvファイルを配置しています
# aws s3 ls s3://test-glue00/se2/in1/year=2017/ --recursive
2018-01-04 09:38:13 0 se2/in1/year=2017/
2018-01-04 09:40:12 0 se2/in1/year=2017/month=11/
2018-01-04 09:40:38 0 se2/in1/year=2017/month=11/day=11/
2018-01-04 09:41:23 0 se2/in1/year=2017/month=11/day=11/hour=12/
2018-01-04 10:19:28 48 se2/in1/year=2017/month=11/day=11/hour=12/cvlog_2017111112.csv
2018-01-04 09:40:42 0 se2/in1/year=2017/month=11/day=14/
2018-01-04 09:41:41 0 se2/in1/year=2017/month=11/day=14/hour=14/
2018-01-04 10:19:45 48 se2/in1/year=2017/month=11/day=14/hour=14/cvlog_2017111414.csv
2018-01-04 09:40:47 0 se2/in1/year=2017/month=11/day=21/
2018-01-04 09:41:55 0 se2/in1/year=2017/month=11/day=21/hour=14/
2018-01-04 10:20:01 49 se2/in1/year=2017/month=11/day=21/hour=14/cvlog_2017112114.csv
2018-01-04 09:40:50 0 se2/in1/year=2017/month=11/day=29/
2018-01-04 09:42:09 0 se2/in1/year=2017/month=11/day=29/hour=15/
2018-01-04 10:20:22 67 se2/in1/year=2017/month=11/day=29/hour=15/cvlog_2017112915.csv
2018-01-04 09:41:01 0 se2/in1/year=2017/month=11/day=30/
2018-01-04 09:42:22 0 se2/in1/year=2017/month=11/day=30/hour=14/
2018-01-04 10:20:41 49 se2/in1/year=2017/month=11/day=30/hour=14/cvlog_2017113014.csv
2018-01-04 09:42:40 0 se2/in1/year=2017/month=11/day=30/hour=20/
2018-01-04 10:20:52 49 se2/in1/year=2017/month=11/day=30/hour=20/cvlog_2017113020.csv
2018-01-04 09:40:16 0 se2/in1/year=2017/month=12/
2018-01-04 09:43:11 0 se2/in1/year=2017/month=12/day=1/
2018-01-04 09:45:16 0 se2/in1/year=2017/month=12/day=1/hour=1/
2018-01-04 10:21:19 44 se2/in1/year=2017/month=12/day=1/hour=1/cvlog_2017120101.csv
2018-01-04 09:43:21 0 se2/in1/year=2017/month=12/day=14/
2018-01-04 09:46:50 0 se2/in1/year=2017/month=12/day=14/hour=12/
2018-01-04 10:22:28 48 se2/in1/year=2017/month=12/day=14/hour=12/cvlog_2017121412.csv
2018-01-04 09:47:01 0 se2/in1/year=2017/month=12/day=14/hour=14/
2018-01-04 10:22:51 49 se2/in1/year=2017/month=12/day=14/hour=14/cvlog_2017121414.csv
2018-01-04 09:43:38 0 se2/in1/year=2017/month=12/day=15/
2018-01-04 09:47:11 0 se2/in1/year=2017/month=12/day=15/hour=11/
2018-01-04 10:23:12 48 se2/in1/year=2017/month=12/day=15/hour=11/cvlog_2017121511.csv
2018-01-04 09:43:42 0 se2/in1/year=2017/month=12/day=16/
2018-01-04 09:47:23 0 se2/in1/year=2017/month=12/day=16/hour=21/
2018-01-04 10:23:34 48 se2/in1/year=2017/month=12/day=16/hour=21/cvlog_2017121621.csv
2018-01-04 09:43:45 0 se2/in1/year=2017/month=12/day=17/
2018-01-04 09:47:38 0 se2/in1/year=2017/month=12/day=17/hour=14/
2018-01-04 10:23:54 49 se2/in1/year=2017/month=12/day=17/hour=14/cvlog_2017121714.csv
2018-01-04 09:47:43 0 se2/in1/year=2017/month=12/day=17/hour=18/
2018-01-04 10:24:12 49 se2/in1/year=2017/month=12/day=17/hour=18/cvlog_2017121718.csv
2018-01-04 09:43:49 0 se2/in1/year=2017/month=12/day=19/
2018-01-04 09:48:04 0 se2/in1/year=2017/month=12/day=19/hour=14/
2018-01-04 10:25:07 49 se2/in1/year=2017/month=12/day=19/hour=14/cvlog_2017121914.csv
2018-01-04 09:47:59 0 se2/in1/year=2017/month=12/day=19/hour=8/
2018-01-04 10:24:56 48 se2/in1/year=2017/month=12/day=19/hour=8/cvlog_2017121908.csv
2018-01-04 09:43:15 0 se2/in1/year=2017/month=12/day=2/
2018-01-04 09:45:44 0 se2/in1/year=2017/month=12/day=2/hour=18/
2018-01-04 10:21:41 44 se2/in1/year=2017/month=12/day=2/hour=18/cvlog_2017120218.csv
2018-01-04 09:43:52 0 se2/in1/year=2017/month=12/day=29/
2018-01-04 09:48:17 0 se2/in1/year=2017/month=12/day=29/hour=15/
2018-01-04 10:25:26 47 se2/in1/year=2017/month=12/day=29/hour=15/cvlog_2017122915.csv
2018-01-04 09:43:18 0 se2/in1/year=2017/month=12/day=9/
2018-01-04 09:46:24 0 se2/in1/year=2017/month=12/day=9/hour=4/
2018-01-04 10:22:02 48 se2/in1/year=2017/month=12/day=9/hour=4/cvlog_2017120904.csv
S3のディレクトリ構成
Glueジョブの入力データは"in1"ディレクトリ配下、出力は"out3"ディレクトリ配下
$ aws s3 ls s3://test-glue00/se2/
PRE in0/
PRE in1/
PRE out0/
PRE out1/
PRE out2/
PRE out3/
PRE script/
PRE tmp/
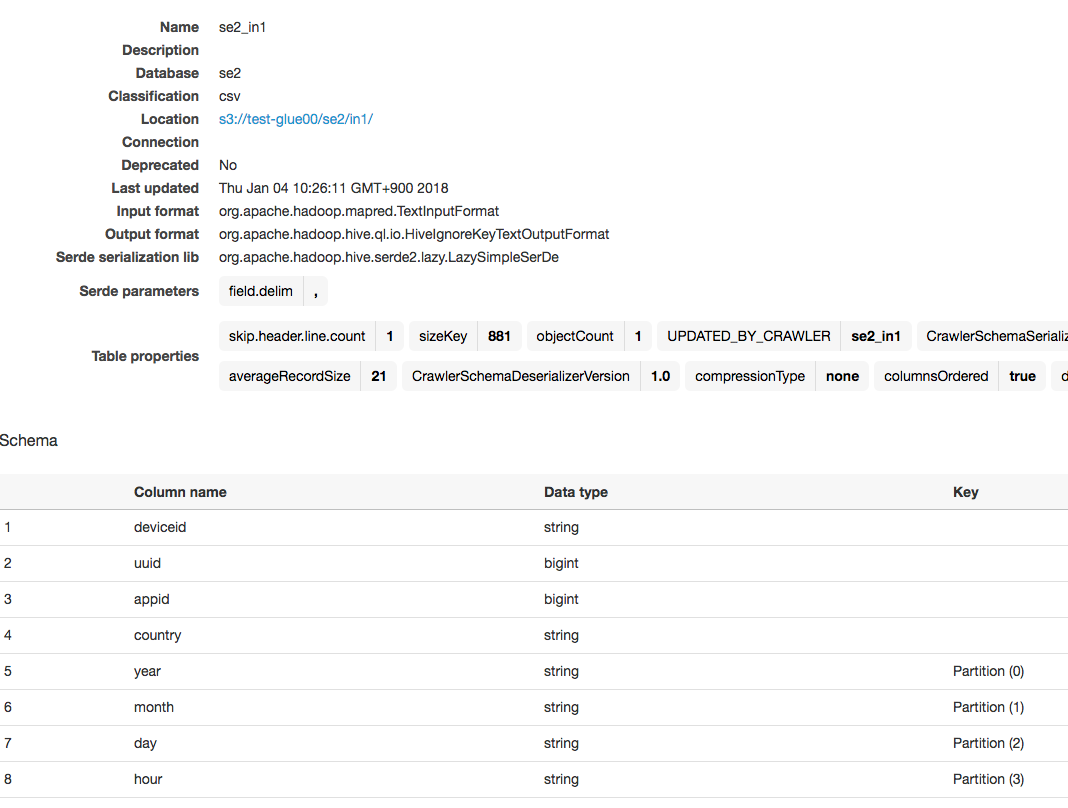
入力テーブルのクローラー
入力データ用に新しくクローラーを作り実行してテーブルを作ります。
出来上がるテーブルの情報は以下です。
ここから、ジョブ作成とPySparkスクリプト修正、出力データのクローラー作成を行っていきます
ジョブ作成と修正
①と同じ手順のGUIのみの操作でse2_job4ジョブを作成
この段階では①とほぼ同じ内容のジョブです
コードは以下になります。
処理内容は"パーティション分割されたcsvデータを同じパーティションで別の場所にparquetとして出力する"です。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
## @type: DataSource
## @args: [database = "se2", table_name = "se2_in1", transformation_ctx = "datasource0"]
## @return: datasource0
## @inputs: []
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "se2", table_name = "se2_in1", transformation_ctx = "datasource0")
## @type: ApplyMapping
## @args: [mapping = [("deviceid", "string", "deviceid", "string"), ("uuid", "long", "uuid", "long"), ("appid", "long", "appid", "long"), ("country", "string", "country", "string")], transformation_ctx = "applymapping1"]
## @return: applymapping1
## @inputs: [frame = datasource0]
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("deviceid", "string", "deviceid", "string"), ("uuid", "long", "uuid", "long"), ("appid", "long", "appid", "long"), ("country", "string", "country", "string")], transformation_ctx = "applymapping1")
## @type: ResolveChoice
## @args: [choice = "make_struct", transformation_ctx = "resolvechoice2"]
## @return: resolvechoice2
## @inputs: [frame = applymapping1]
resolvechoice2 = ResolveChoice.apply(frame = applymapping1, choice = "make_struct", transformation_ctx = "resolvechoice2")
## @type: DropNullFields
## @args: [transformation_ctx = "dropnullfields3"]
## @return: dropnullfields3
## @inputs: [frame = resolvechoice2]
dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3")
## @type: DataSink
## @args: [connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out3"}, format = "parquet", transformation_ctx = "datasink4"]
## @return: datasink4
## @inputs: [frame = dropnullfields3]
datasink4 = glueContext.write_dynamic_frame.from_options(frame = dropnullfields3, connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out3"}, format = "parquet", transformation_ctx = "datasink4")
job.commit()
以下の部分を修正します。
25行目を以下のように修正します
GUIでジョブを作った場合、入力データのパーティションをマッピング対象のカラムとして含めてくれません
入力のパーティションのカラムをマップの対象として追加します
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("deviceid", "string", "deviceid", "string"), ("uuid", "long", "uuid", "long"), ("appid", "long", "appid", "long"), ("country", "string", "country", "string")], transformation_ctx = "applymapping1")
↓↓↓
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("deviceid", "string", "deviceid", "string"), ("uuid", "long", "uuid", "long"), ("appid", "long", "appid", "long"), ("country", "string", "country", "string"), ("year", "string", "year", "string"), ("month", "string", "month", "string"), ("day", "string", "day", "string"), ("hour", "string", "hour", "string")], transformation_ctx = "applymapping1")
35行目の"dropnullfields3"の後に以下を追加
df = dropnullfields3.toDF()
partitionby=['year','month','day','hour']
output='s3://test-glue00/se2/out1/'
codec='snappy'
df.repartition(*partitionby).write.partitionBy(partitionby).mode("append").parquet(output,compression=codec)
toDF:DynamicFrameをDataFrameに変換
write:DataFrameのデータを外部に保存。jdbc, parquet, json, orc, text, saveAsTable
parquetのcompression:none, snappy, gzip, and, lzoから選べる
partitionBy:Hiveパーティションのようにカラム=バリュー形式でパーティション化されたディレクトリにデータを保存
mode:ファイルやテーブルが既に存在してる場合の振る舞い。overwrite,append,ignore,error(デフォ)
repartition(numPartitions, *cols)[source]:パーティションの再配置、カッコ内はパーティションする単位を数字かカラムで選ぶ、カラムが優先
最後の方のsink処理をコメントアウト
# datasink4 = glueContext.write_dynamic_frame.from_options(frame = dropnullfields3, connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out1"}, format = "parquet", transformation_ctx = "datasink4")
修正したコードです
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
## @type: DataSource
## @args: [database = "se2", table_name = "se2_in1", transformation_ctx = "datasource0"]
## @return: datasource0
## @inputs: []
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "se2", table_name = "se2_in1", transformation_ctx = "datasource0")
## @type: ApplyMapping
## @args: [mapping = [("deviceid", "string", "deviceid", "string"), ("uuid", "long", "uuid", "long"), ("appid", "long", "appid", "long"), ("country", "string", "country", "string")], transformation_ctx = "applymapping1"]
## @return: applymapping1
## @inputs: [frame = datasource0]
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("deviceid", "string", "deviceid", "string"), ("uuid", "long", "uuid", "long"), ("appid", "long", "appid", "long"), ("country", "string", "country", "string"), ("year", "string", "year", "string"), ("month", "string", "month", "string"), ("day", "string", "day", "string"), ("hour", "string", "hour", "string")], transformation_ctx = "applymapping1")
## @type: ResolveChoice
## @args: [choice = "make_struct", transformation_ctx = "resolvechoice2"]
## @return: resolvechoice2
## @inputs: [frame = applymapping1]
resolvechoice2 = ResolveChoice.apply(frame = applymapping1, choice = "make_struct", transformation_ctx = "resolvechoice2")
## @type: DropNullFields
## @args: [transformation_ctx = "dropnullfields3"]
## @return: dropnullfields3
## @inputs: [frame = resolvechoice2]
dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3")
### add
df = dropnullfields3.toDF()
partitionby=['year','month','day','hour']
output='s3://test-glue00/se2/out3/'
codec='snappy'
df.repartition(*partitionby).write.partitionBy(partitionby).mode("append").parquet(output,compression=codec)
### add
## @type: DataSink
## @args: [connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out3"}, format = "parquet", transformation_ctx = "datasink4"]
## @return: datasink4
## @inputs: [frame = dropnullfields3]
# datasink4 = glueContext.write_dynamic_frame.from_options(frame = dropnullfields3, connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out3"}, format = "parquet", transformation_ctx = "datasink4")
job.commit()
ジョブ実行と確認
ジョブ実行
対象ジョブにチェックを入れ、ActionからRun jobをクリックしジョブ実行します
出力が指定したyaerやmonthでパーティション分割されている。
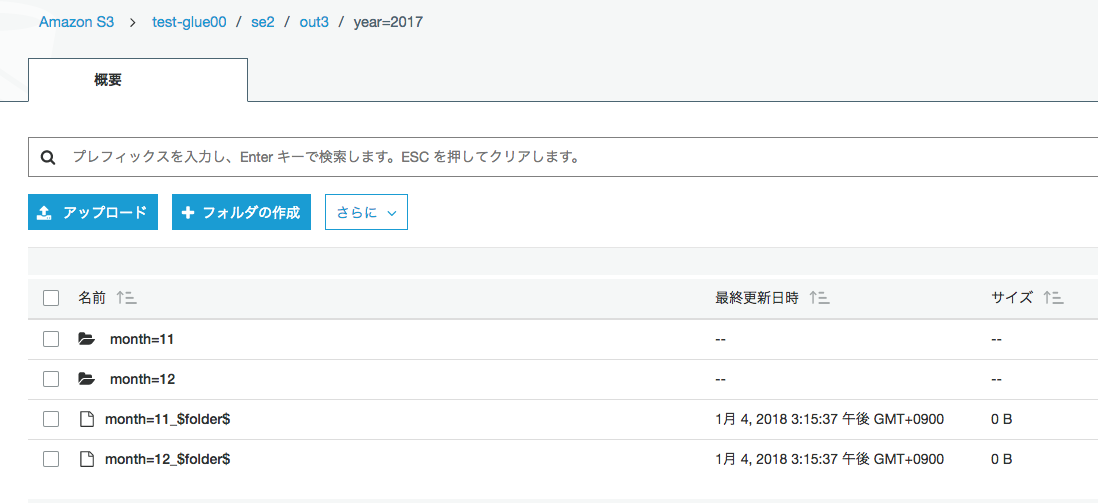
コマンドで確認
s3のparquetファイルを確認
ローカルにダウンロードし、parquet-toolsで内容確認
# aws s3 ls s3://test-glue00/se2/out3/year=2017/month=11/day=14/hour=14/
2018-01-04 15:15:41 926 part-00149-21f4b84d-3fb2-4095-bf1c-cad2f6a58e63.snappy.parquet
# aws s3 cp s3://test-glue00/se2/out3/year=2017/month=11/day=14/hour=14/part-00149-21f4b84d-3fb2-4095-bf1c-cad2f6a58e63.snappy.parquet .
download: s3://test-glue00/se2/out3/year=2017/month=11/day=14/hour=14/part-00149-21f4b84d-3fb2-4095-bf1c-cad2f6a58e63.snappy.parquet to ./part-00149-21f4b84d-3fb2-4095-bf1c-cad2f6a58e63.snappy.parquet
# ls
part-00149-21f4b84d-3fb2-4095-bf1c-cad2f6a58e63.snappy.parquet
# java -jar /root/parquet/parquet-mr/parquet-tools/target/parquet-tools-1.6.0rc7.jar head part-00149-21f4b84d-3fb2-4095-bf1c-cad2f6a58e63.snappy.parquet
deviceid = iphone
uuid = 11123
appid = 9
country = FR
出力データのクローラー作成、実行、Athenaで確認
se2_out3でクローラー作成
GlueのCrawlersをクリックし、"Add crawler"をクリック
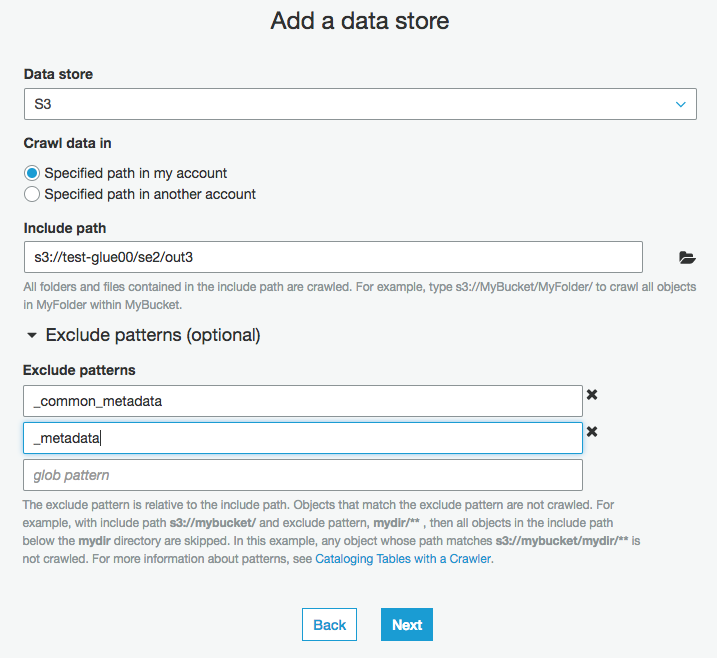
S3の出力パスを入力
形式の違うデータが混在しているとテーブルが複数できてしまうので、不要なものがあれば、excludeで除外する。
今回は、_common_metadataと_metadataを除外してる
そのまま"Next"をクリック
IAM roleに”test-glue"を選択
そのまま"Next"をクリック
Databaseを選択(今回はse2)
Prefixを入力(今回はse2_)
クローラー実行
1つのテーブルとして認識している

スキーマも、yearやmonthなどで分割したパーティションを認識している
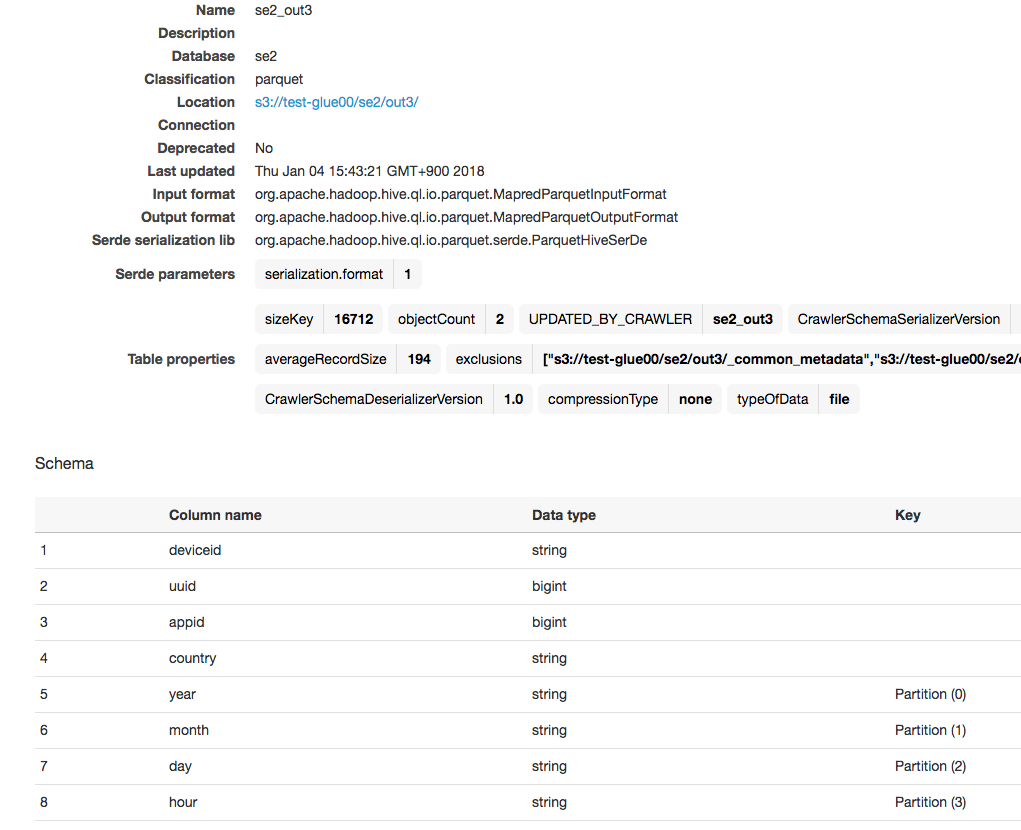
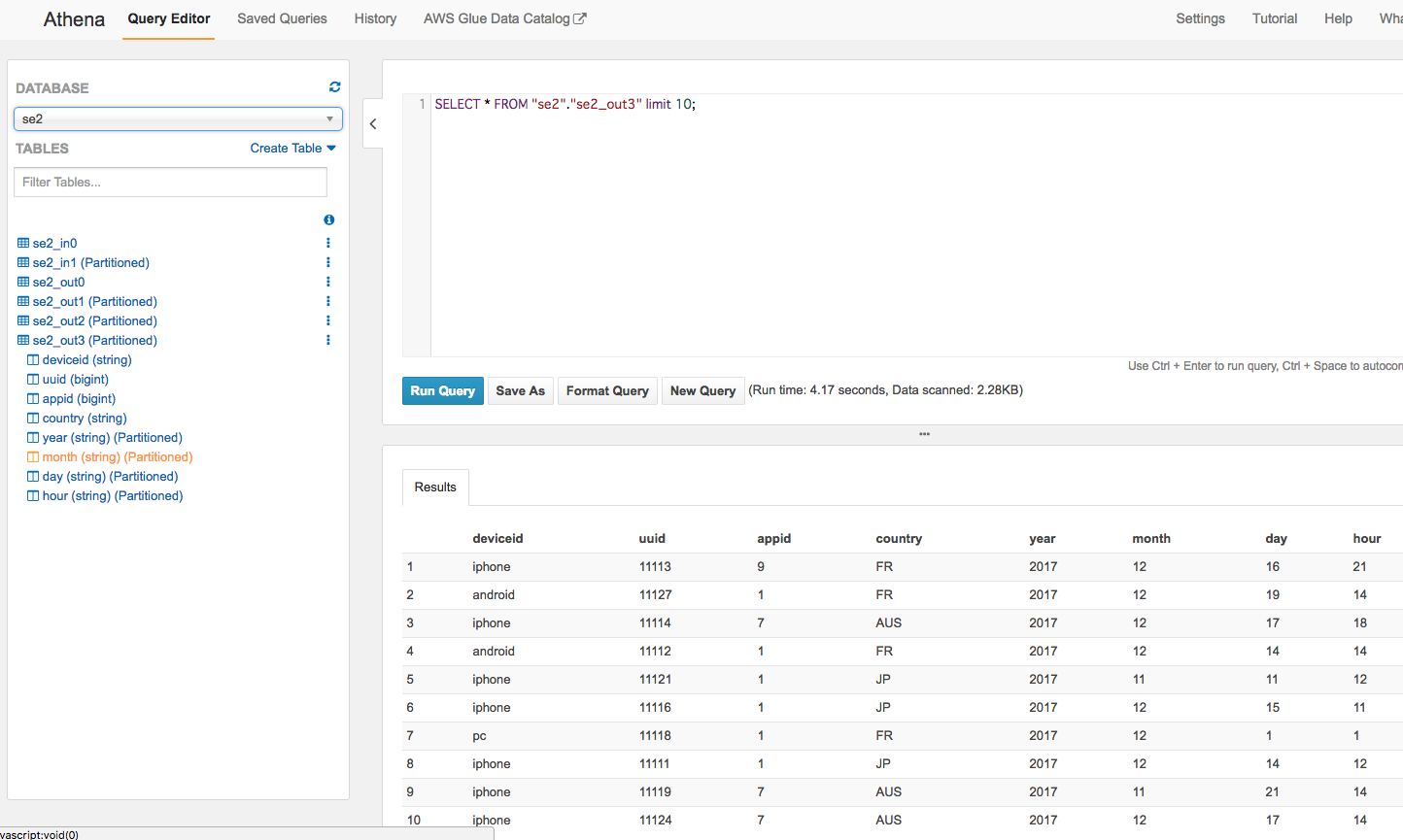
Athenaから確認
左メニューからse2_out3のスキーマ情報確認、クエリ実行
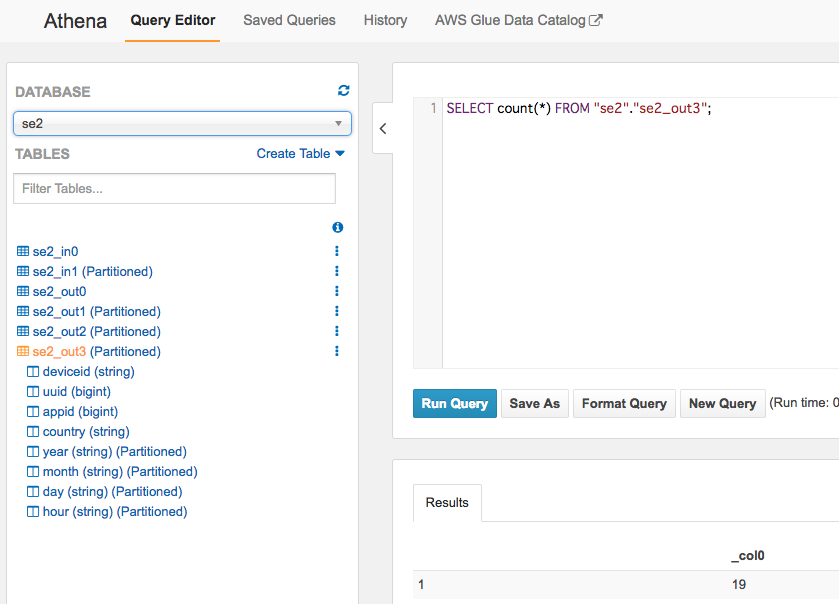
件数も19件で合っている
別のカラムでパーティション切る
タイムスタンプ以外のカラムでももちろんパーティションを切れます。
例えばappidというカラムがあるので、アプリごとに集計をするようなケースが多いならappidも含めてパーティション分割する
他にもdeviceidとかでデバイスごとに集計したり
一時的な調査にも役立つかも
出力に"out4"ディレクトリ作成
①と同様のジョブをse2_job5で作成
PySparkに以下3点修正したジョブ作成
25行目を以下のように修正します
GUIでジョブを作った場合、入力データのパーティションはカラムとして含めてくれません。
入力のパーティションのカラムをapplyの対象として追加します
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("deviceid", "string", "deviceid", "string"), ("uuid", "long", "uuid", "long"), ("appid", "long", "appid", "long"), ("country", "string", "country", "string")], transformation_ctx = "applymapping1")
↓
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("deviceid", "string", "deviceid", "string"), ("uuid", "long", "uuid", "long"), ("appid", "long", "appid", "long"), ("country", "string", "country", "string"), ("year", "string", "year", "string"), ("month", "string", "month", "string"), ("day", "string", "day", "string"), ("hour", "string", "hour", "string")], transformation_ctx = "applymapping1")
35行目の"dropnullfields3"の後に以下を追加
df = dropnullfields3.toDF()
partitionby=['appid','year','month','day','hour']
output='s3://test-glue00/se2/out4/'
codec='snappy'
df.repartition(*partitionby).write.partitionBy(partitionby).mode("append").parquet(output,compression=codec)
最後の方のsink処理をコメントアウト
# datasink4 = glueContext.write_dynamic_frame.from_options(frame = dropnullfields3, connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out1"}, format = "parquet", transformation_ctx = "datasink4")
ジョブ実行
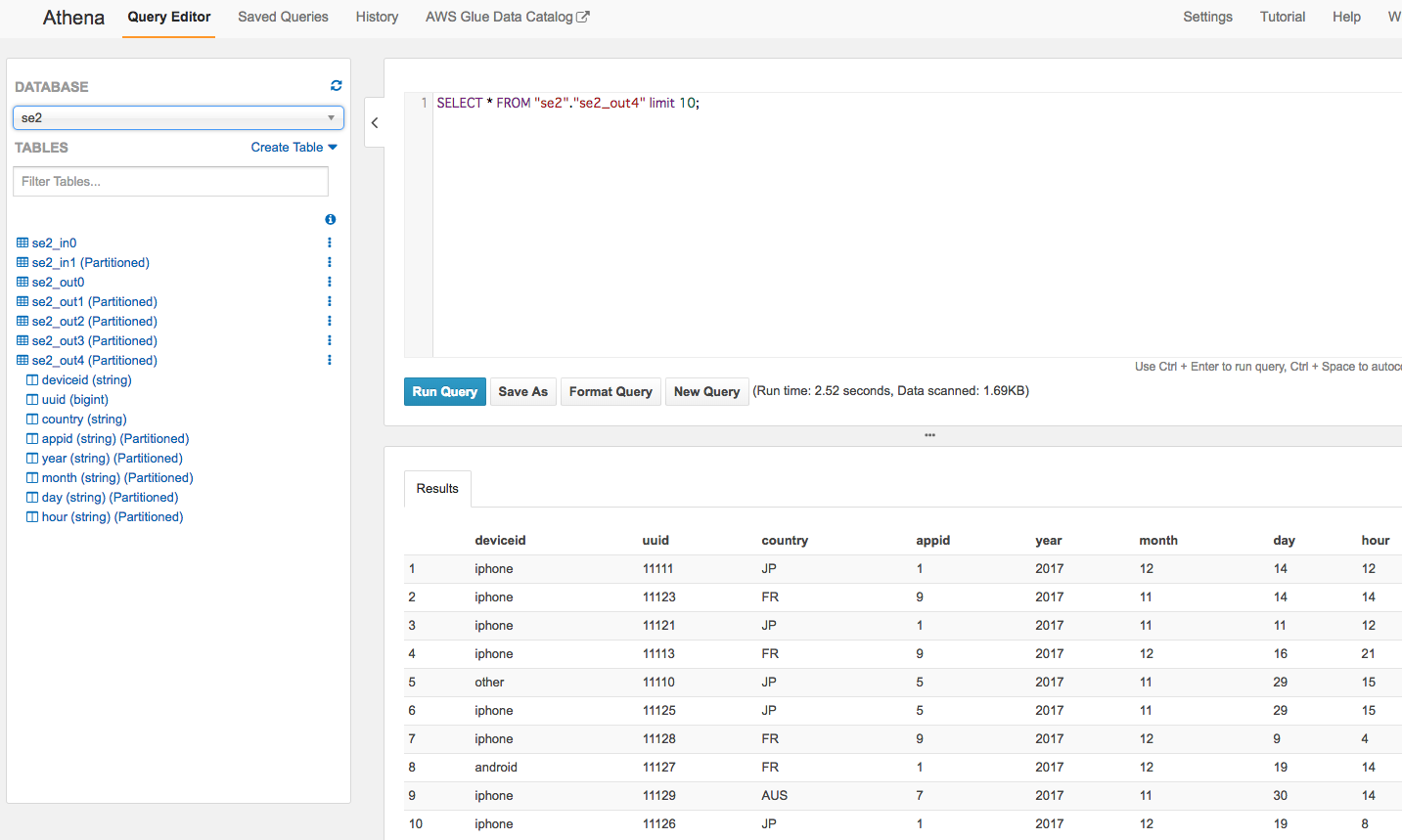
appidごとにパーティション別れてます
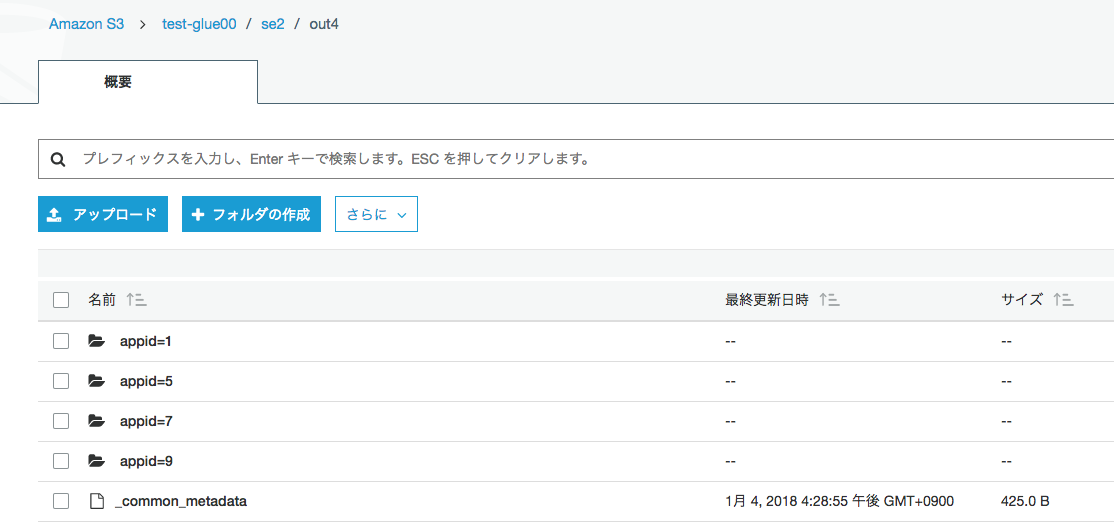
クローラー作成と実行
手順はさっきと同じなので省きます
テーブルが作成され
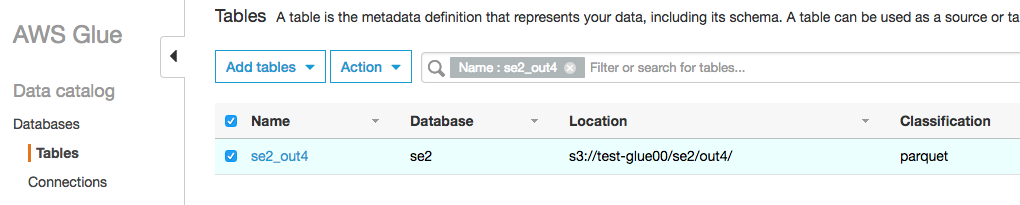
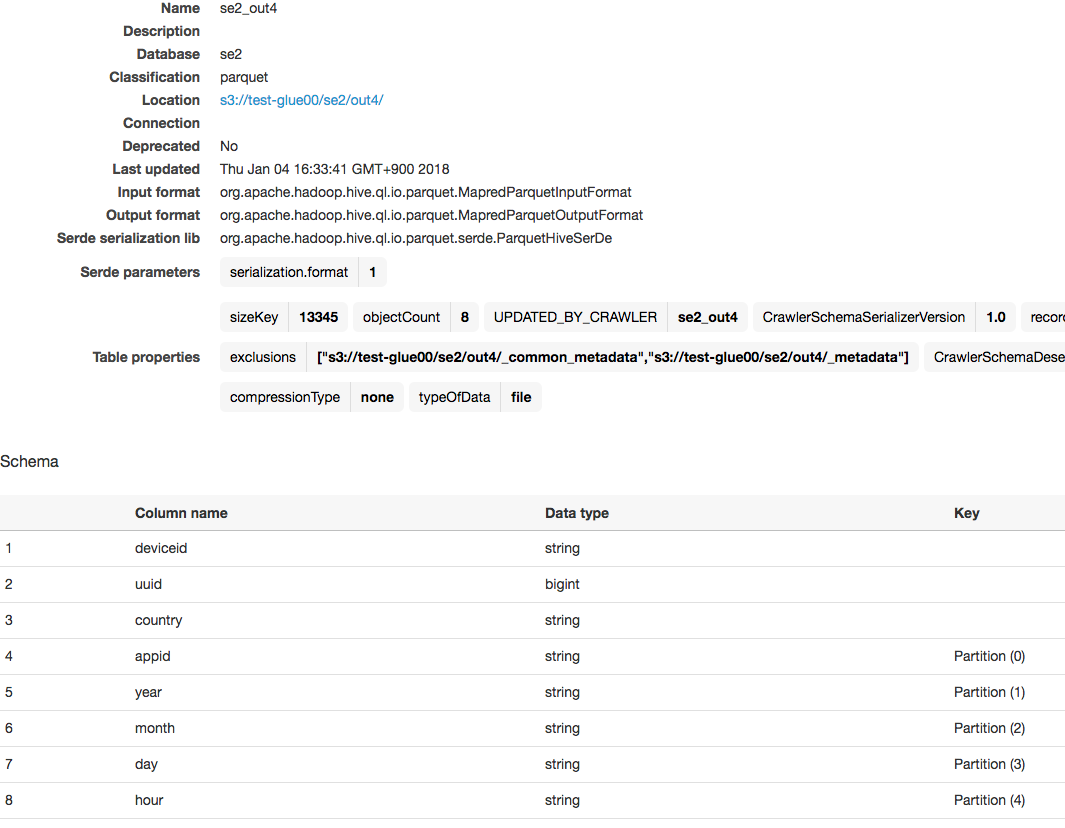
スキーマはcountryがパーティションに追加されています
Athenaから確認
左側メニューでスキーマ確認と、クエリ実行
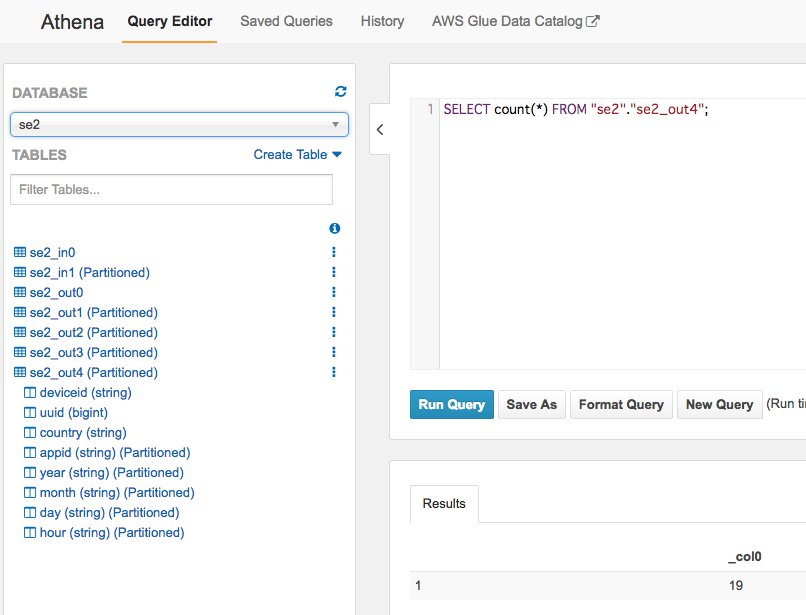
件数も同じく19件
その他
todo
To Be Continue
よくありそうな変換処理ケースを今後書いていければと思います。
こちらも是非
Spark API
https://spark.apache.org/docs/latest/sql-programming-guide.html
Glueの使い方まとめ
https://qiita.com/pioho07/items/32f76a16cbf49f9f712f