概要
GlueがデータソースにDynamoDBをサポートしました。試してみます。
手順は、DDBに権限のあるロールを作り、DDBをクロールするクローラーを作ってクローリングしテーブルを作り、GlueジョブでDDBのデータをETLしてS3に出力する
ジョブ名
se2_job10
クローラー名
se2_in7
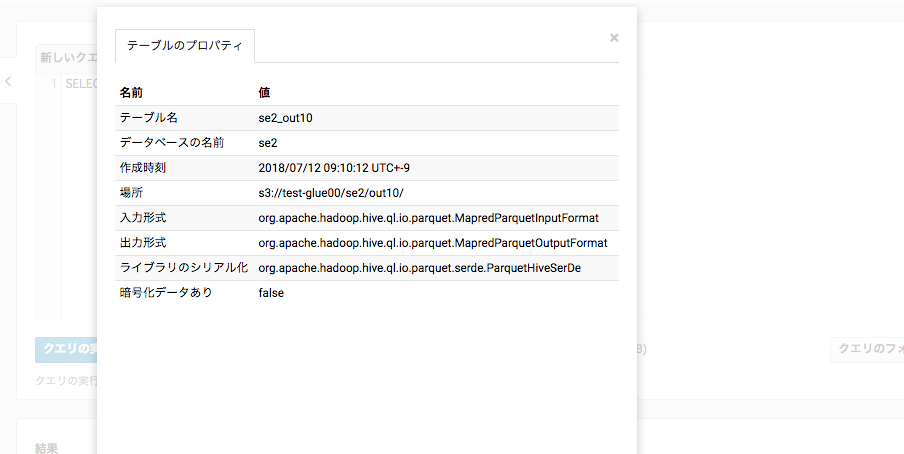
se2_out10
全体の流れ
- 前準備
- IAMポリシー作成しロールに追加
- クローラー作成と実行
- ジョブ作成と実行
前準備
ソースデータ(19件)
※データの内容は以下がDynamoDBのse2_ddb1というテーブルにあります
deviceid,uuid,appid,country,year,month,day,hour
iphone,11111,001,JP,2017,12,14,12
android,11112,001,FR,2017,12,14,14
iphone,11113,009,FR,2017,12,16,21
iphone,11114,007,AUS,2017,12,17,18
other,11115,005,JP,2017,12,29,15
iphone,11116,001,JP,2017,12,15,11
pc,11118,001,FR,2017,12,01,01
pc,11117,009,FR,2017,12,02,18
iphone,11119,007,AUS,2017,11,21,14
other,11110,005,JP,2017,11,29,15
iphone,11121,001,JP,2017,11,11,12
android,11122,001,FR,2017,11,30,20
iphone,11123,009,FR,2017,11,14,14
iphone,11124,007,AUS,2017,12,17,14
iphone,11125,005,JP,2017,11,29,15
iphone,11126,001,JP,2017,12,19,08
android,11127,001,FR,2017,12,19,14
iphone,11128,009,FR,2017,12,09,04
iphone,11129,007,AUS,2017,11,30,14
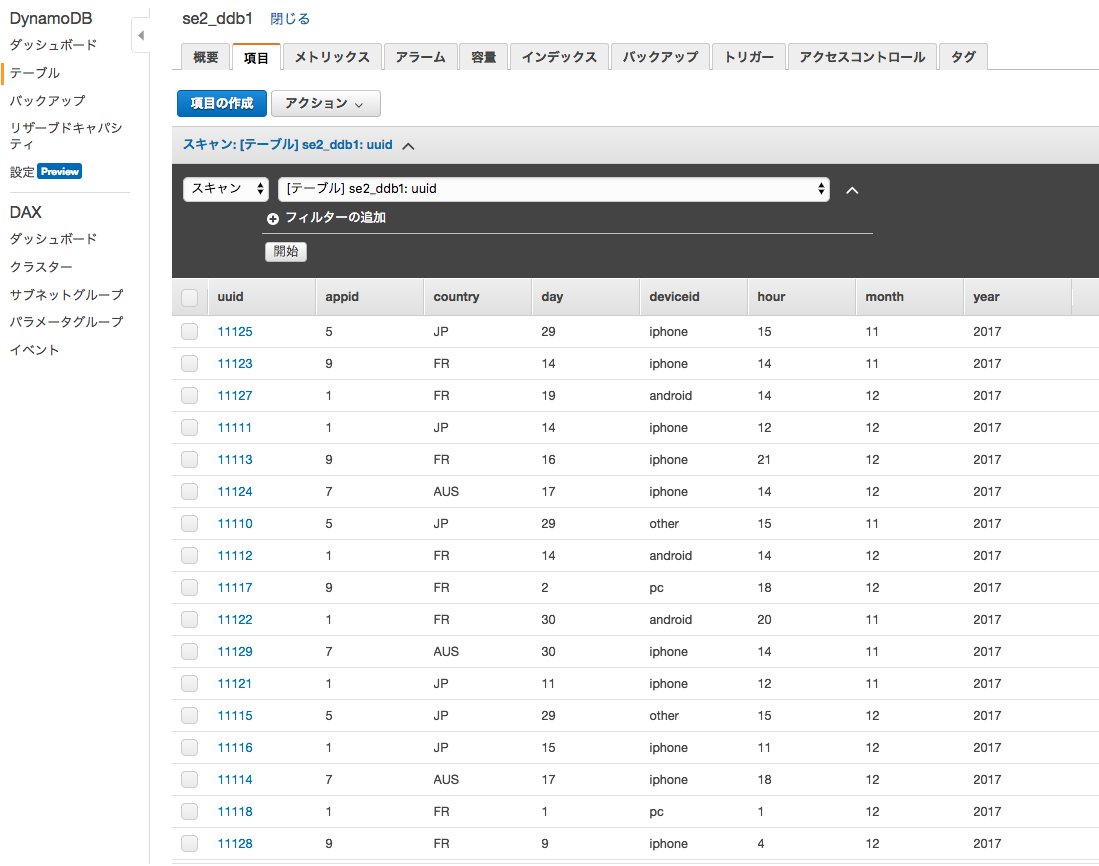
DynamoDBで確認するとこう
IAMポリシー作成しロールに追加
"se2_glueddbtest"というポリシーを作成
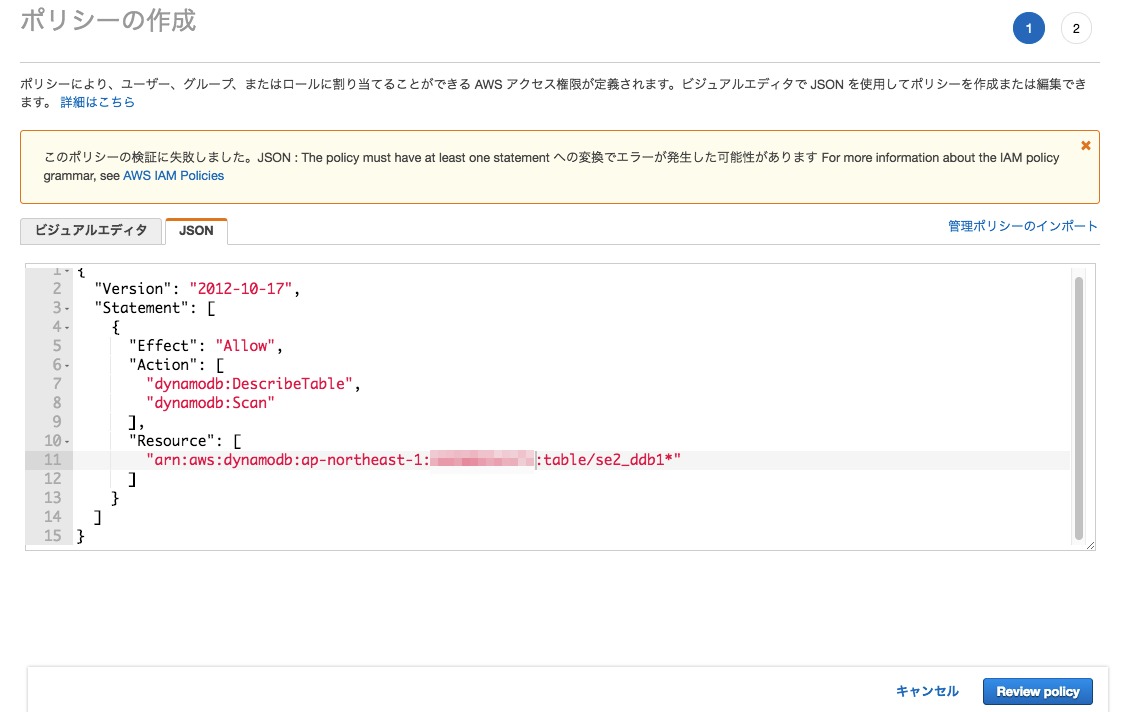
※ 以下参考
https://docs.aws.amazon.com/glue/latest/dg/console-crawlers.html
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"dynamodb:DescribeTable",
"dynamodb:Scan"
],
"Resource": [
"arn:aws:dynamodb:region:account-id:table/table-name*"
]
}
]
}
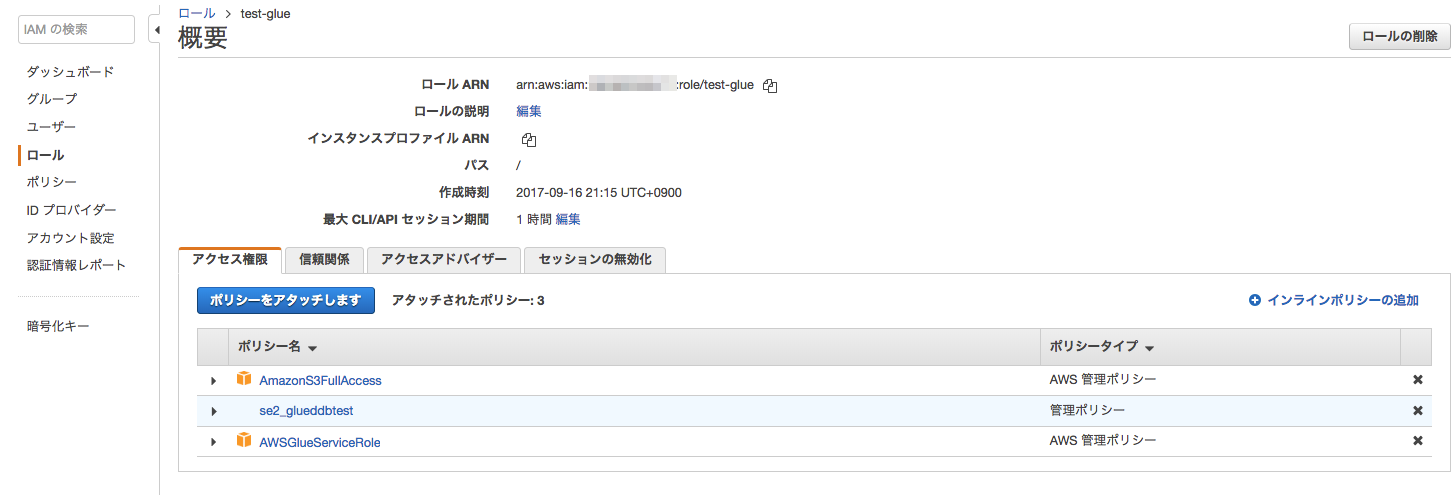
作成したポリシーをIAMロールにアタッチ
クローラーの作成と実行
以下の手順で、DynamoDBをクロールするクローラーを作成します。
Glueの画面からCrawlersをクリックし"Add Crawler"をクリック
Crawler nameに"se2_in7"を入力
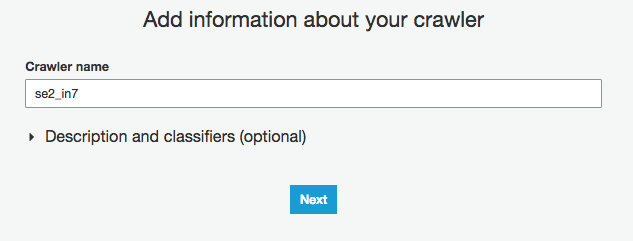
Choose a data store に "DynamoDBを選択
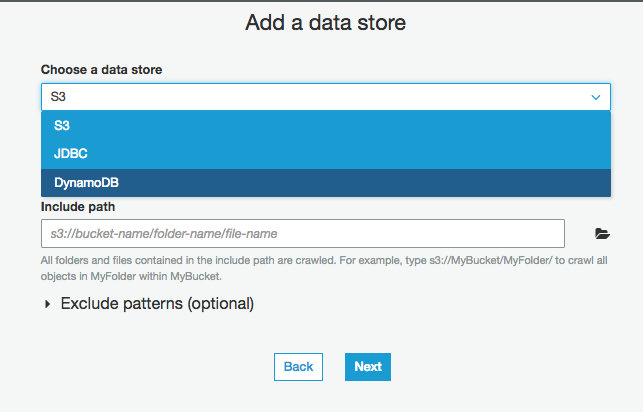
Table name には DynamoDBのテーブル"se2_ddb1"を選択

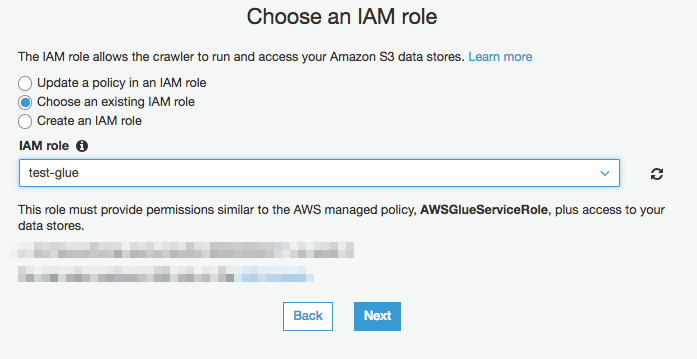
IAM role を"test-glue"を選択
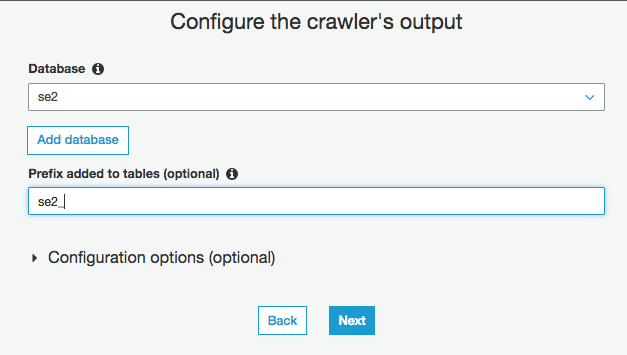
Databaseに"se2"、prefix に "se2_"を入力し、最後に "Finish" をクリック
クローラーの実行
"se2_in7"にチェックを入れ、"Run Crawler"をクリックしクローラーを実行する
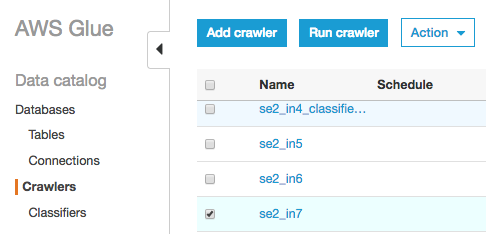
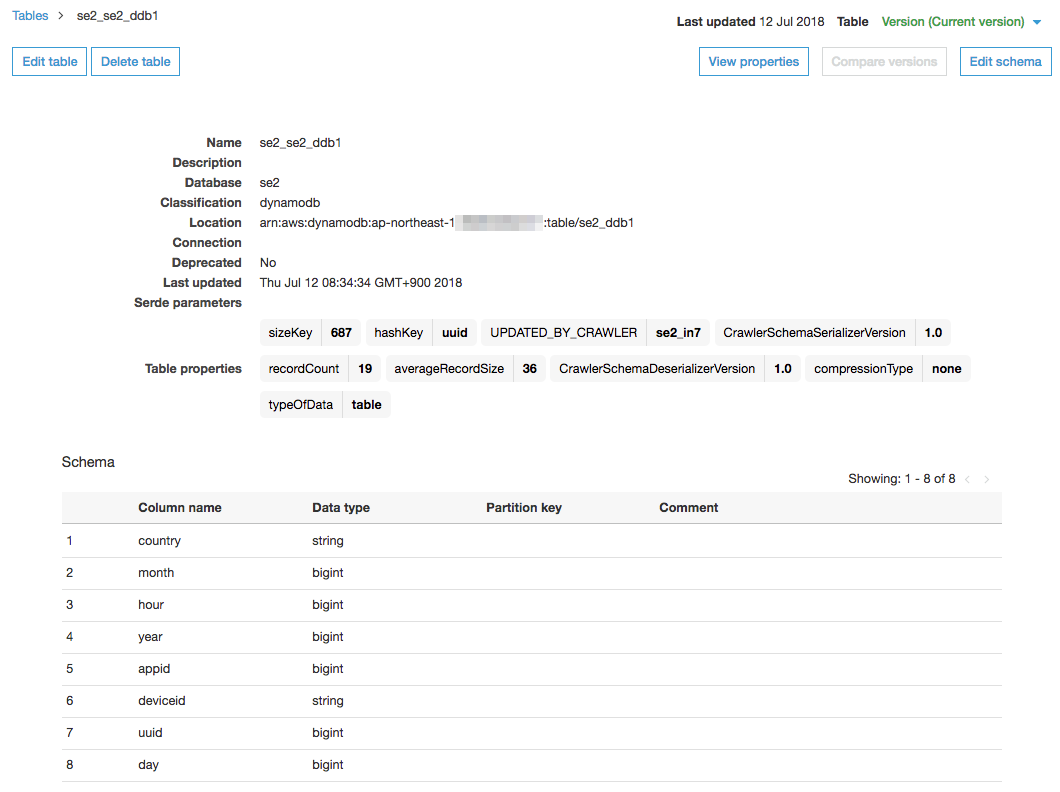
テーブルの確認
"se2_se2_ddb1"のテーブルができていることを確認する

Classificationがdynamodb
Locationがarn:aws:dynamodb:ap-northeast-1:xxxxxxxxxxxx:table/se2_ddb1
を確認する
スキーマがDynamoDBのテーブルと同じであることを確認する
ジョブ作成
Glueの画面からJobをクリックし、"Add job"をクリック
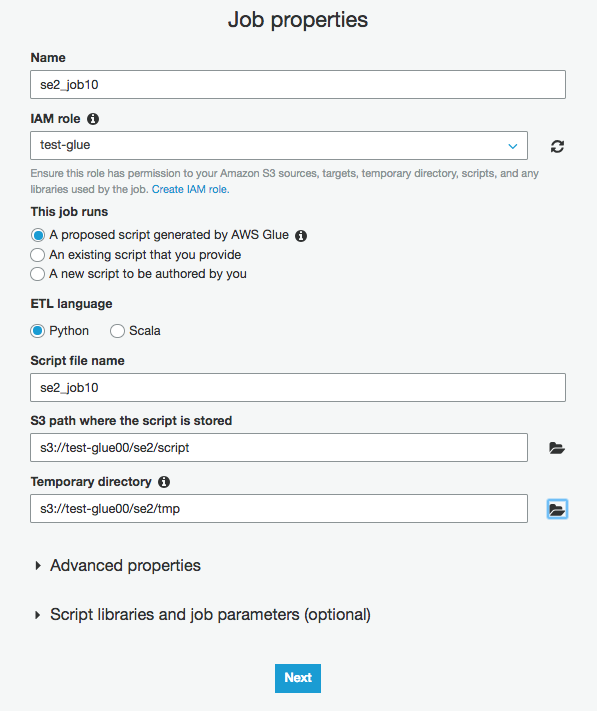
Name に "se2_job10" を入力し、IAM role に "test-glueを選択し、"Next"をクリック
Data source に "se2_se2_ddb1"を選択し"Next"をクリック
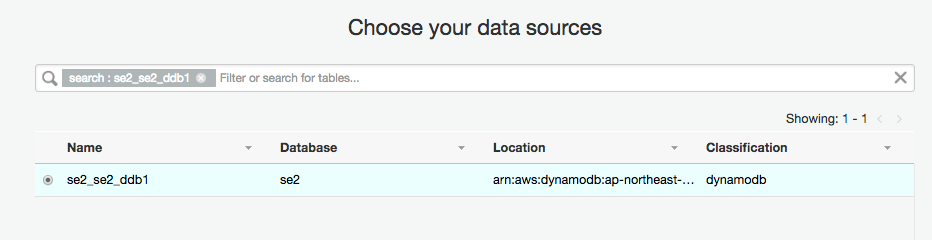
Create Table in your targetにチェックを入れ、Data storeに"S3"、Formatに"Parquet"、Target pathに"s3://test-glue00/se2/out10"を選択
そのまま"Next"

次の画面で"Save.."をクリックしジョブが作成され、その次の画面で"Run Job"をクリックする

ジョブ実行中画面
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
## @type: DataSource
## @args: [database = "se2", table_name = "se2_se2_ddb1", transformation_ctx = "datasource0"]
## @return: datasource0
## @inputs: []
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "se2", table_name = "se2_se2_ddb1", transformation_ctx = "datasource0")
## @type: ApplyMapping
## @args: [mapping = [("country", "string", "country", "string"), ("month", "long", "month", "long"), ("hour", "long", "hour", "long"), ("year", "long", "year", "long"), ("appid", "long", "appid", "long"), ("deviceid", "string", "deviceid", "string"), ("uuid", "long", "uuid", "long"), ("day", "long", "day", "long")], transformation_ctx = "applymapping1"]
## @return: applymapping1
## @inputs: [frame = datasource0]
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("country", "string", "country", "string"), ("month", "long", "month", "long"), ("hour", "long", "hour", "long"), ("year", "long", "year", "long"), ("appid", "long", "appid", "long"), ("deviceid", "string", "deviceid", "string"), ("uuid", "long", "uuid", "long"), ("day", "long", "day", "long")], transformation_ctx = "applymapping1")
## @type: ResolveChoice
## @args: [choice = "make_struct", transformation_ctx = "resolvechoice2"]
## @return: resolvechoice2
## @inputs: [frame = applymapping1]
resolvechoice2 = ResolveChoice.apply(frame = applymapping1, choice = "make_struct", transformation_ctx = "resolvechoice2")
## @type: DropNullFields
## @args: [transformation_ctx = "dropnullfields3"]
## @return: dropnullfields3
## @inputs: [frame = resolvechoice2]
dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3")
## @type: DataSink
## @args: [connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out10"}, format = "parquet", transformation_ctx = "datasink4"]
## @return: datasink4
## @inputs: [frame = dropnullfields3]
datasink4 = glueContext.write_dynamic_frame.from_options(frame = dropnullfields3, connection_type = "s3", connection_options = {"path": "s3://test-glue00/se2/out10"}, format = "parquet", transformation_ctx = "datasink4")
job.commit()
Athenaから確認
DynamoDBと同じデータがクエリできている

件数も19件で合っている
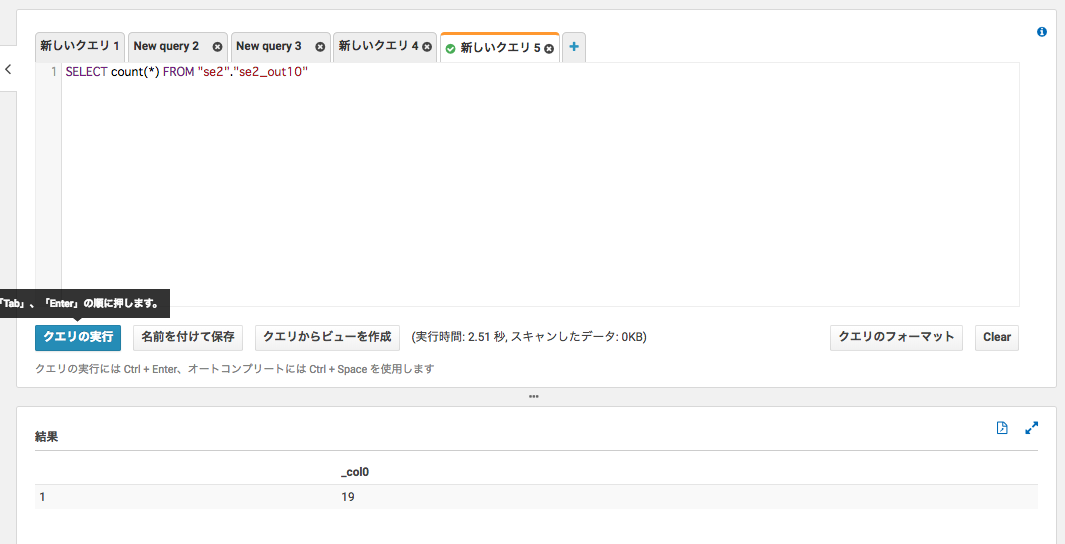
フォーマットもparquet
その他
DynamoDBのRCUについて
GlueによるDynamoDBへのReadにも、DynamoDBのRCUを消費します。
- "dynamodb.input.tableName":(必須)読み取る元のDynamoDBテーブル。
- "dynamodb.throughput.read.percent":(オプション)使用する予約済み容量ユニット(RCU)のパーセンテージ。 デフォルトは "0.5"に設定されています。 許容可能な値は、 "0.1"から "1.5"までです
こちらも是非
Glueマニュアル
https://docs.aws.amazon.com/glue/latest/dg/aws-glue-programming-etl-partitions.html
Glueの使い方まとめ
https://qiita.com/pioho07/items/32f76a16cbf49f9f712f