メモ書き
get-table
テーブルtmp_logsの情報を get-table API で取得
$ aws glue get-table --database-name default --name tmp_logs --region ap-northeast-1
{
"Table": {
"Name": "tmp_logs",
"DatabaseName": "default",
"Owner": "owner",
"CreateTime": "2020-04-28T15:18:26+09:00",
"UpdateTime": "2020-04-28T15:18:26+09:00",
"LastAccessTime": "2020-04-28T15:18:26+09:00",
"Retention": 0,
"StorageDescriptor": {
"Columns": [
{
"Name": "host",
"Type": "string"
},
{
"Name": "user",
"Type": "string"
},
{
"Name": "method",
"Type": "string"
},
{
"Name": "path",
"Type": "string"
},
{
"Name": "code",
"Type": "int"
},
{
"Name": "size",
"Type": "int"
},
{
"Name": "referer",
"Type": "string"
},
{
"Name": "agent",
"Type": "string"
},
{
"Name": "time",
"Type": "string"
}
],
"Location": "s3://20200204sample/logs/",
"InputFormat": "org.apache.hadoop.mapred.TextInputFormat",
"OutputFormat": "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat",
"Compressed": true,
"NumberOfBuckets": -1,
"SerdeInfo": {
"SerializationLibrary": "org.openx.data.jsonserde.JsonSerDe",
"Parameters": {
"paths": "agent,code,host,method,path,referer,size,time,user"
}
},
"BucketColumns": [],
"SortColumns": [],
"Parameters": {
"CrawlerSchemaDeserializerVersion": "1.0",
"CrawlerSchemaSerializerVersion": "1.0",
"UPDATED_BY_CRAWLER": "tmp",
"averageRecordSize": "152",
"classification": "json",
"compressionType": "gzip",
"objectCount": "7",
"recordCount": "19",
"sizeKey": "1148",
"typeOfData": "file"
},
"StoredAsSubDirectories": false
},
"PartitionKeys": [],
"TableType": "EXTERNAL_TABLE",
"Parameters": {
"CrawlerSchemaDeserializerVersion": "1.0",
"CrawlerSchemaSerializerVersion": "1.0",
"UPDATED_BY_CRAWLER": "tmp",
"averageRecordSize": "152",
"classification": "json",
"compressionType": "gzip",
"objectCount": "7",
"recordCount": "19",
"sizeKey": "1148",
"typeOfData": "file"
},
"CreatedBy": "arn:aws:sts::xxxxxxxxxxxx:assumed-role/test-glue/AWS-Crawler",
"IsRegisteredWithLakeFormation": false
}
}
TableInput object
以下のドキュメントの --table-input の TableInput object の JSONファイルの構文に合わせて、上記で得た情報を転記する
転記した上で"Location"を"s3://20200204sample/logs123/"に修正する。
$ cat tmp2.json
{
"Name": "tmp_logs",
"Owner": "owner",
"Retention": 0,
"StorageDescriptor": {
"Columns": [
{
"Name": "host",
"Type": "string"
},
{
"Name": "user",
"Type": "string"
},
{
"Name": "method",
"Type": "string"
},
{
"Name": "path",
"Type": "string"
},
{
"Name": "code",
"Type": "int"
},
{
"Name": "size",
"Type": "int"
},
{
"Name": "referer",
"Type": "string"
},
{
"Name": "agent",
"Type": "string"
},
{
"Name": "time",
"Type": "string"
}
],
"Location": "s3://20200204sample/logs123/",
"InputFormat": "org.apache.hadoop.mapred.TextInputFormat",
"OutputFormat": "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat",
"Compressed": true,
"NumberOfBuckets": -1,
"SerdeInfo": {
"SerializationLibrary": "org.openx.data.jsonserde.JsonSerDe",
"Parameters": {"paths": "agent,code,host,method,path,referer,size,time,user"
}
},
"BucketColumns": [],
"SortColumns": [],
"Parameters": {
"CrawlerSchemaDeserializerVersion": "1.0",
"CrawlerSchemaSerializerVersion": "1.0",
"UPDATED_BY_CRAWLER": "tmp",
"averageRecordSize": "152",
"classification": "json",
"compressionType": "gzip",
"objectCount": "7",
"recordCount": "19",
"sizeKey": "1148",
"typeOfData": "file"
},
"StoredAsSubDirectories": false
},
"PartitionKeys": [],
"TableType": "EXTERNAL_TABLE",
"Parameters": {
"CrawlerSchemaDeserializerVersion": "1.0",
"CrawlerSchemaSerializerVersion": "1.0",
"UPDATED_BY_CRAWLER": "tmp",
"averageRecordSize": "152",
"classification": "json",
"compressionType": "gzip",
"objectCount": "7",
"recordCount": "19",
"sizeKey": "1148",
"typeOfData": "file"
}
}
update-table
注意点としては、TableInput Object(↑のJSONファイル)の内容に空白の項目があると空白でテーブルがアップデートされちゃいます。
つまり今回修正したい"Location"を"s3://20200204sample/logs123/"だけの内容のJSONファイルでupdate-tableすると、Location以外は空白のテーブルにアップデートされちゃいます。
$ aws glue update-table --database-name default --table-input file://tmp2.json --region ap-northeast-1
update後に get-table
$ aws glue get-table --database-name default --name tmp_logs --region ap-northeast-1
{
"Table": {
"Name": "tmp_logs",
"DatabaseName": "default",
"Owner": "owner",
"CreateTime": "2020-04-28T15:18:26+09:00",
"UpdateTime": "2020-06-10T08:47:52+09:00",
"Retention": 0,
"StorageDescriptor": {
"Columns": [
{
"Name": "host",
"Type": "string"
},
{
"Name": "user",
"Type": "string"
},
{
"Name": "method",
"Type": "string"
},
{
"Name": "path",
"Type": "string"
},
{
"Name": "code",
"Type": "int"
},
{
"Name": "size",
"Type": "int"
},
{
"Name": "referer",
"Type": "string"
},
{
"Name": "agent",
"Type": "string"
},
{
"Name": "time",
"Type": "string"
}
],
"Location": "s3://20200204sample/logs123/",
"InputFormat": "org.apache.hadoop.mapred.TextInputFormat",
"OutputFormat": "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat",
"Compressed": true,
"NumberOfBuckets": -1,
"SerdeInfo": {
"SerializationLibrary": "org.openx.data.jsonserde.JsonSerDe",
"Parameters": {
"paths": "agent,code,host,method,path,referer,size,time,user"
}
},
"BucketColumns": [],
"SortColumns": [],
"Parameters": {
"CrawlerSchemaDeserializerVersion": "1.0",
"CrawlerSchemaSerializerVersion": "1.0",
"UPDATED_BY_CRAWLER": "tmp",
"averageRecordSize": "152",
"classification": "json",
"compressionType": "gzip",
"objectCount": "7",
"recordCount": "19",
"sizeKey": "1148",
"typeOfData": "file"
},
"StoredAsSubDirectories": false
},
"PartitionKeys": [],
"TableType": "EXTERNAL_TABLE",
"Parameters": {
"CrawlerSchemaDeserializerVersion": "1.0",
"CrawlerSchemaSerializerVersion": "1.0",
"UPDATED_BY_CRAWLER": "tmp",
"averageRecordSize": "152",
"classification": "json",
"compressionType": "gzip",
"objectCount": "7",
"recordCount": "19",
"sizeKey": "1148",
"typeOfData": "file"
},
"IsRegisteredWithLakeFormation": false
}
}
前のテーブルとUpdate後のテーブルの差分
get-tableした結果をエディタでdiff表示
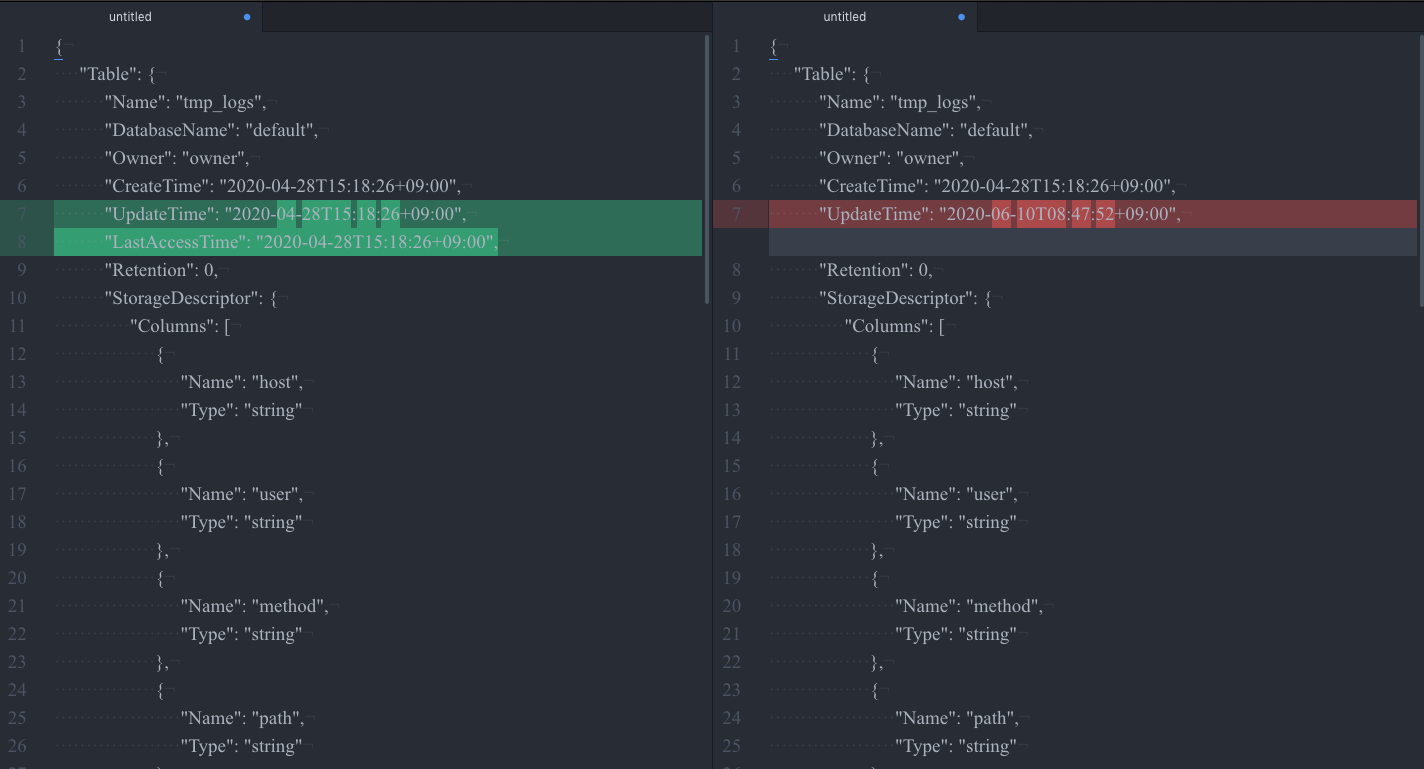
UpdateTime、LastAccessTime はそれぞれ日付が異なるので差分が出ている
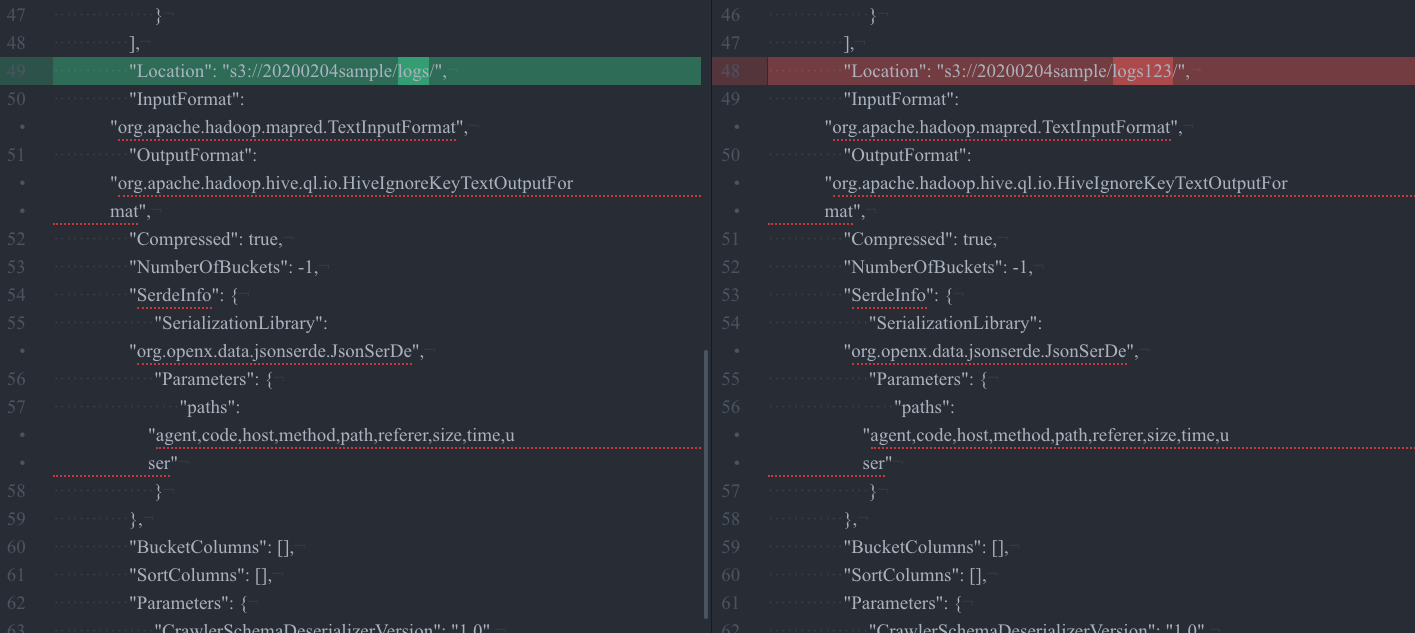
修正したLocationは異なるので差分が出ている
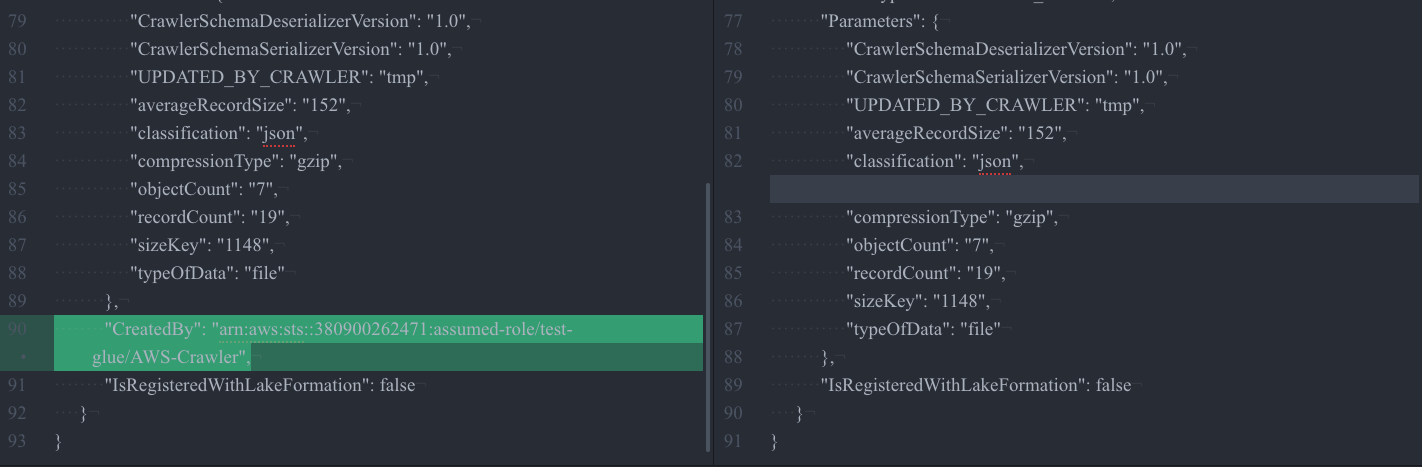
古いテーブルはGlue Crawlerで行ったためCreatedByの表示があり、新しいテーブルはそれがなくなっており差分が出ている
こちらも是非
Glueの使い方まとめ
https://qiita.com/pioho07/items/32f76a16cbf49f9f712f