Glue Data Catalogのテーブルに対して直接Spark SQLできるようになりました
公式ドキュメントはこちら
入力データはこちら
cvlog
deviceid,uuid,appid,country,year,month,day,hour
iphone,11111,001,JP,2017,12,14,12
android,11112,001,FR,2017,12,14,14
iphone,11113,009,FR,2017,12,16,21
iphone,11114,007,AUS,2017,12,17,18
other,11115,005,JP,2017,12,29,15
iphone,11116,001,JP,2017,12,15,11
pc,11118,001,FR,2017,12,01,01
pc,11117,009,FR,2017,12,02,18
iphone,11119,007,AUS,2017,11,21,14
other,11110,005,JP,2017,11,29,15
iphone,11121,001,JP,2017,11,11,12
android,11122,001,FR,2017,11,30,20
iphone,11123,009,FR,2017,11,14,14
iphone,11124,007,AUS,2017,12,17,14
iphone,11125,005,JP,2017,11,29,15
iphone,11126,001,JP,2017,12,19,08
android,11127,001,FR,2017,12,19,14
iphone,11128,009,FR,2017,12,09,04
iphone,11129,007,AUS,2017,11,30,14
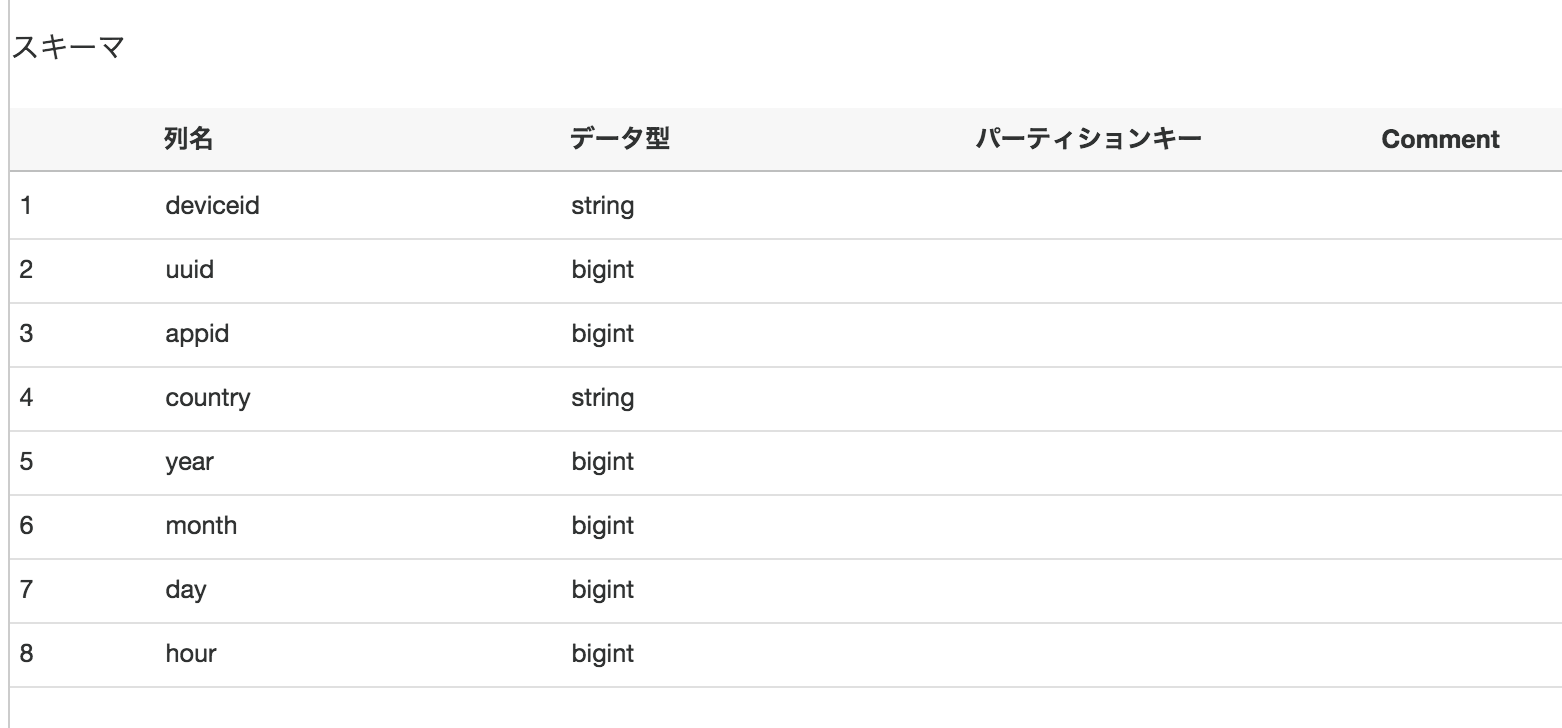
テーブル情報
データベース:se2
テーブル:se2_in0

ジョブ作成
ジョブ名:se2_job22

ジョブパラメーターのキーに"--enable-glue-datacatalog"、バリューに何も入れないを入力する。これで本機能が有効化されます
※DevEndpointの場合も同様らしいがこの設定箇所が見つからない・・

以下のコードを貼り付け実行
se2_job22
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql.functions import input_file_name
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
spark.sql("use se2")
spark.sql("select * from se2_in0").show()
job.commit()
確認
CWLで表示表示されていることを確認

今までだと以下のようなコードになってたところよりシンプルな記述にすることができます。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql.functions import input_file_name
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
dynamicframe1 = glueContext.create_dynamic_frame.from_catalog(database = "se2", table_name = "se2_in0", transformation_ctx = "datasource0")
df = datasource0.toDF()
df.createOrReplaceTempView('sample_data')
df = spark.sql("select * from sample_data")
df.show()
job.commit()
こちらも是非
Glueの使い方まとめ
https://qiita.com/pioho07/items/32f76a16cbf49f9f712f