クローラーオプション Grouping behavior for S3 data
クローラー作成画面にこんなオプションが追加されました。
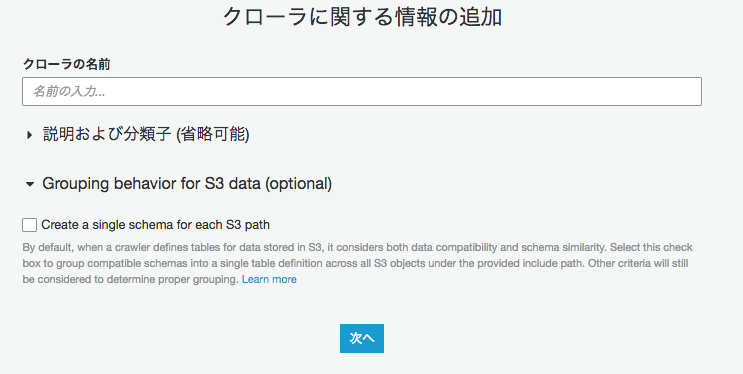
これはクローラー実行時のオプションで以下のような効果がります。
オプションなし(デフォルト)
クローラが S3 に格納されたデータのテーブルを定義するとき、データの互換性とスキーマの類似性の両方を考慮します。
データの互換性の考慮事項には、データが同じ形式(JSONなど)、同じ圧縮形式(GZIPなど)、S3 パスの構造、およびその他のデータ属性であるかどうかが含まれます。
スキーマの類似度は、別々の S3 オブジェクトのスキーマがどれほど似ているかを示す指標です。
オプションあり
可能であれば、CombineCompatibleSchemasを共通テーブル定義に設定することができます。このオプションを使用すると、クローラは引き続きデータの互換性を考慮しますが、指定されたインクルードパスで S3 オブジェクトを評価する際の特定のスキーマの類似性は無視されます。
今回使うGlueのリソース名
クローラー名
se2_in9
データ
入力:in9
全体の流れ
- 前準備
- オプションなしでクローリング
- オプションありでクローリング
- まとめ
前準備
今回使うサンプルログファイル
2つのcsvファイルを使う
deviceid,uuid,appid
iphone,11111,001
android,11112,001
iphone,11113,009
iphone,11114,007
aaid,bbid,ccid
ueue,11115,002
piopio,11116,002
hoge,11113,004
hoge,11112,007
ディレクトリ構成
スキーマのことなるデータ①②を以下のように配置
$ aws s3 ls s3://test-glue00/se2/in9/
PRE year=2017/
PRE year=2018/
2018-08-12 13:13:01 0
$ aws s3 ls s3://test-glue00/se2/in9/year=2017/
2018-08-12 13:52:15 0
2018-08-12 13:57:22 89 cvlog1.csv
$ aws s3 ls s3://test-glue00/se2/in9/year=2018/
2018-08-12 13:52:24 0
2018-08-12 13:57:36 136 cvlog2.csv
オプションなしでクローリング(デフォルト)
それぞれ別々のスキーマを作りたいならデフォルト
2つのデータのスキーマの類似度が低いため、"se2_year_2017"と"se2_year_2018"の2つのテーブルが作成されている
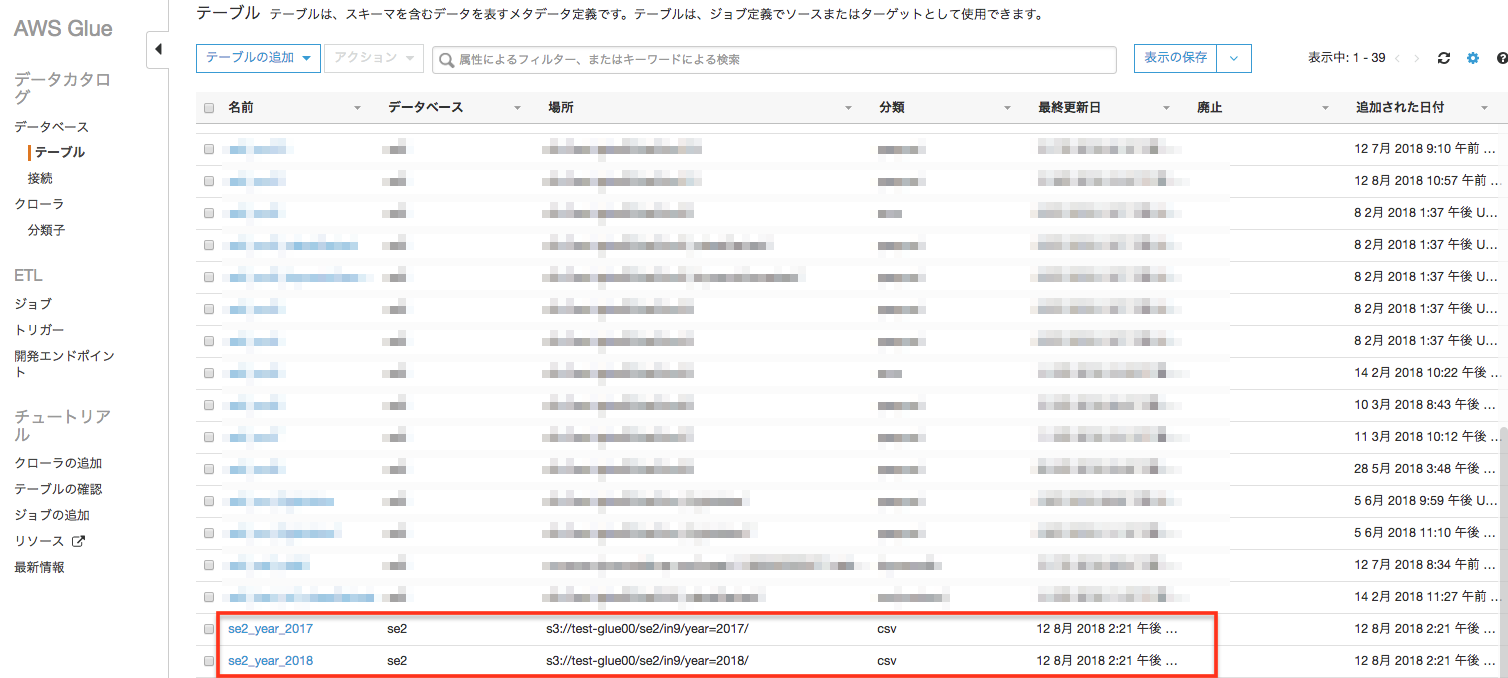
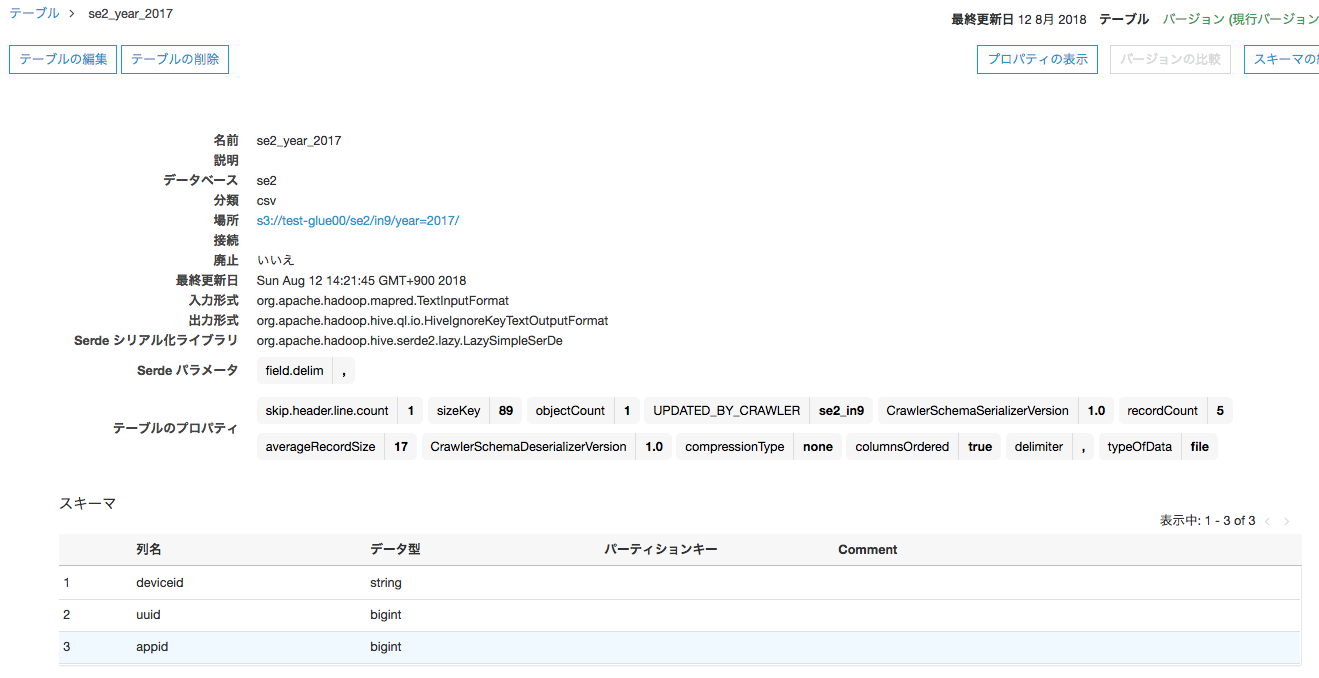
①のデータの"se2_year_2017"テーブル
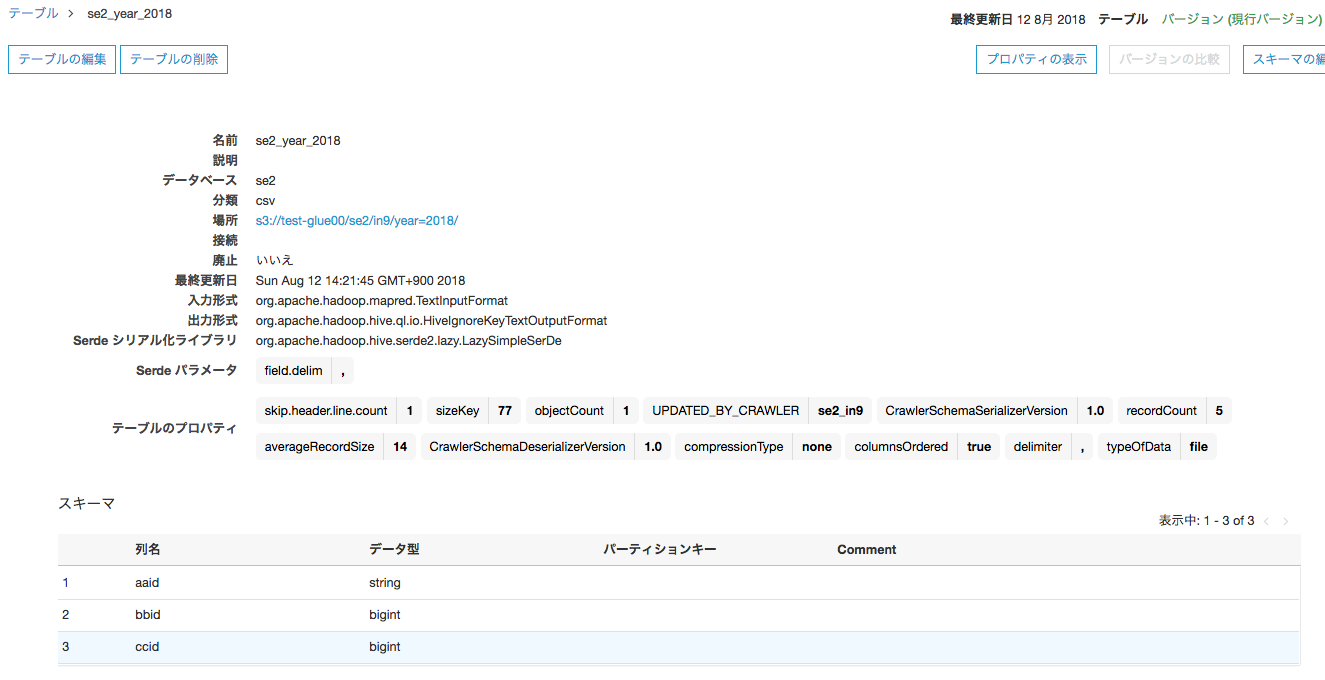
②のデータの"se2_year_2018"テーブル
オプションありでクローリング
オプション有効にする
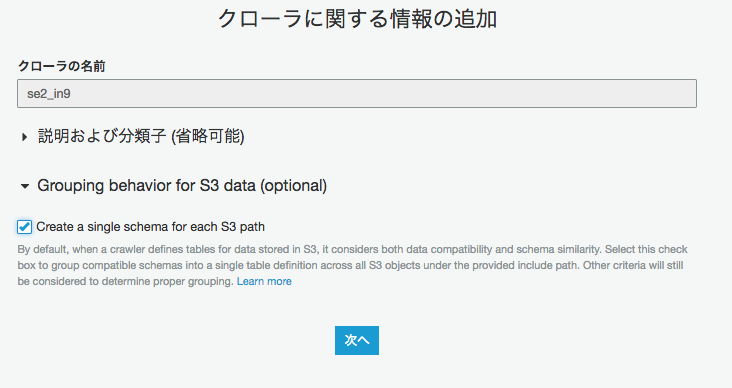
クローリングを実行
スキーマの類似性を無視してスキーマが1つとしてテーブルが作成される
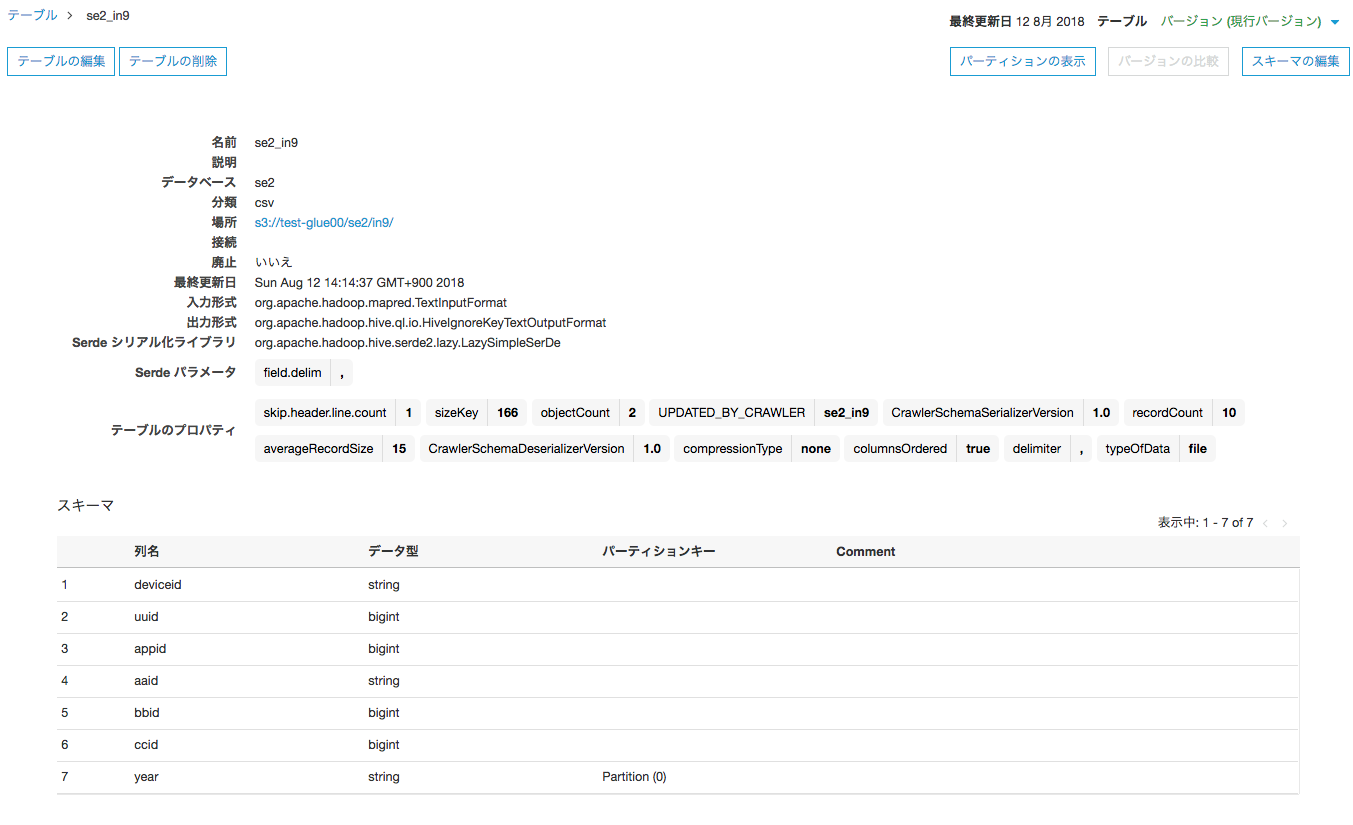
-
ディレクトリの途中にデータが存在してたりするとパーティションが認識されず複数のテーブルができてしまいます(これは今まで通り)。
例えば、se2/in9/xxx.csvが追加で存在すると、"se2_cvlog2_csv"、"se2_year_2017"、"se2_year_2018"の3つのテーブルが出来上がります -
形式の異なるデータが1つでもあると複数のテーブルができてしまいます。
例えば、se2/in9/year=2019/test.json が追加で含まれていると、"se2_year_2017"、"se2_year_2018"、"se2_year_2019"の3つのテーブルが出来上がります。
まとめ
JSONなどのデータの形式やGZIPなどの圧縮形式が同じであれば、あるS3パス配下のデータは多少異なるカラムがあってもスキーマを結合してしまいたい場合にいいのかも。
こちらも是非
AWS Glue コンソールでのクローラの設定
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/crawler-configuration.html
Glueの使い方まとめ
https://qiita.com/pioho07/items/32f76a16cbf49f9f712f